Humans' ALMANAC: A Human Collaboration Dataset of Action-Level Mental Model Annotations for Agent Collaboration
Pith reviewed 2026-06-28 01:16 UTC · model grok-4.3
The pith
ALMANAC supplies 2,987 human collaboration actions each labeled with self-reasoning, partner intent, and team goals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
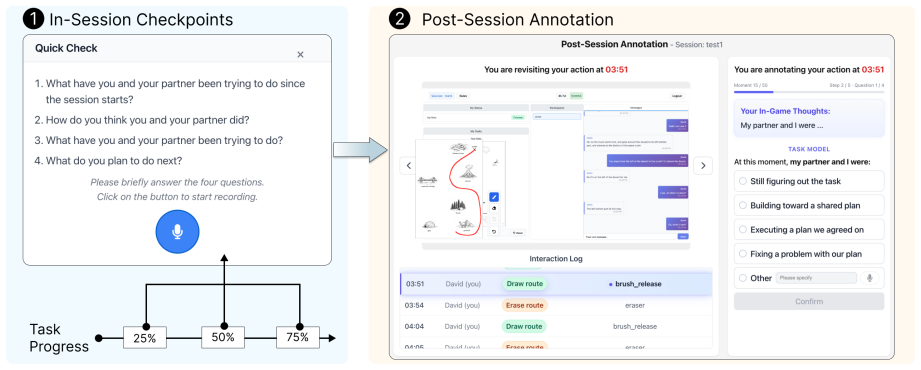
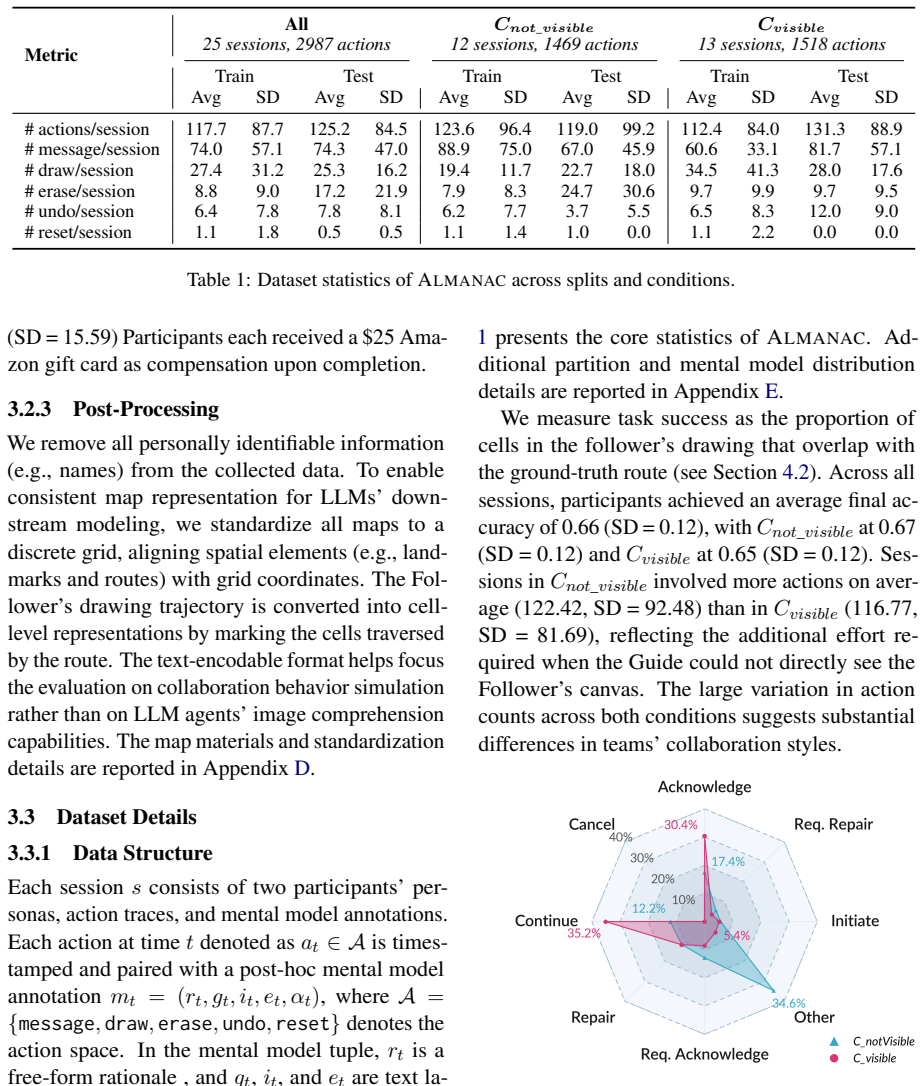
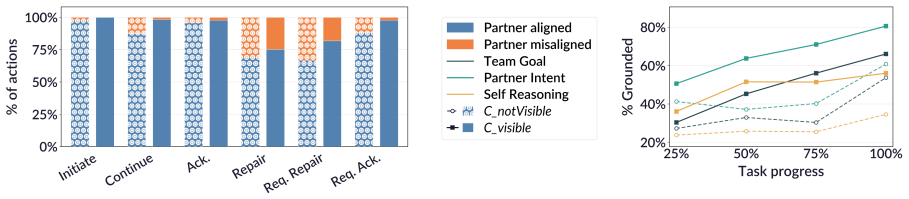
ALMANAC is a dataset of Action-Level Mental model ANnotations for Agent Collaboration built from the Map Task that contains 2,987 collaboration actions, each paired with theory-informed mental model annotations recording the participants' self-reasoning, perceived partner intent, and perceived team goal. Benchmarking six LLMs on the data demonstrates its utility for evaluating models' ability to simulate human collaborative behaviors and infer their underlying mental models.
What carries the argument
The ALMANAC dataset of theory-informed mental model annotations (self-reasoning, perceived partner intent, perceived team goal) paired with each of the 2,987 Map Task collaboration actions.
If this is right
- LLMs can be benchmarked on predicting humans' next-turn behavior directly from the annotated actions.
- Models can be tested for their ability to infer the three mental-model components from observed collaboration turns.
- The dataset supplies a concrete signal for moving agents from task-completion optimization toward process-level collaborative competence.
- Researchers gain an authentic human baseline against which to measure whether agents align on shared goals and partner intent.
Where Pith is reading between the lines
- The same annotation protocol could be applied to other dyadic tasks to test whether mental-model patterns generalize beyond route-finding.
- If models improve on ALMANAC, they might sustain longer multi-turn collaborations without explicit goal reminders.
- The dataset could support training objectives that penalize divergence between a model's inferred partner model and the human annotations.
- Patterns in how humans update their annotations across turns might reveal timing regularities that current agents ignore.
Load-bearing premise
The theory-informed annotations accurately capture participants' actual mental models of self-reasoning, partner intent, and team goals during the Map Task collaboration.
What would settle it
A follow-up study in which original participants review the annotations for their own actions and report systematic mismatches with what they actually thought at the time, or an experiment showing that LLMs fine-tuned on ALMANAC produce no measurable gain in next-turn prediction accuracy over untuned baselines.
Figures

read the original abstract
Recent advances in LLM agents have enabled complex cognitive capabilities, such as multi-step reasoning, planning, and tool use, that increasingly position these agents as human collaborators. Effective collaboration, however, requires collaborators to continuously maintain and align mental models of their own reasoning,partners' intentions, and shared goals during the collaborative process. Today's agents rarely develop such capabilities since they are primarily optimized for task completion, and the community lacks authentic human collaboration data with action-level mental model annotations that could guide agents toward process-level collaborative competence. To bridge this gap, we present ALMANAC, a dataset of Action-Level Mental model ANnotations for Agent Collaboration built from the Map Task, a classic dyadic routing task from social science. ALMANAC contains 2,987 collaboration actions, each paired with theory-informed mental model annotations that record the participants' self-reasoning, perceived partner intent, and perceived team goal. We benchmark six LLMs on predicting humans' next-turn behavior and mental models. Our results demonstrate ALMANAC's utility in evaluating models' ability to simulate human collaborative behaviors and infer their underlying mental models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ALMANAC, a dataset of 2,987 action-level annotations collected from dyadic Map Task collaborations. Each action is paired with theory-informed labels for self-reasoning, perceived partner intent, and perceived team goals. The authors benchmark six LLMs on next-turn behavior prediction and mental-model inference, claiming the results demonstrate the dataset's utility for evaluating models' ability to simulate human collaborative behaviors and infer underlying mental models.
Significance. If the annotations are shown to be faithful to participants' actual mental models, ALMANAC would provide a rare resource of process-level human collaboration data that could support development of agents capable of maintaining aligned mental models rather than optimizing solely for task completion. The benchmarking protocol offers a concrete evaluation framework that the community could extend.
major comments (1)
- [§3 and §5] §3 (ALMANAC Dataset Construction) and §5 (Benchmarking Experiments): the manuscript reports the annotation scheme and the 2,987 instances but supplies no inter-rater agreement statistics, participant self-validation, or correlation with observable behavior (e.g., route deviations). Because the headline utility claim rests on these annotations serving as accurate proxies for mental models, the absence of such checks is load-bearing; benchmark scores on mental-model inference cannot be interpreted as measuring the intended capability without them.
minor comments (1)
- [Abstract] The abstract states the dataset size and benchmarking setup but does not preview any quantitative results (e.g., accuracy numbers or statistical comparisons), making it difficult for readers to gauge the strength of the utility demonstration at first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [§3 and §5] §3 (ALMANAC Dataset Construction) and §5 (Benchmarking Experiments): the manuscript reports the annotation scheme and the 2,987 instances but supplies no inter-rater agreement statistics, participant self-validation, or correlation with observable behavior (e.g., route deviations). Because the headline utility claim rests on these annotations serving as accurate proxies for mental models, the absence of such checks is load-bearing; benchmark scores on mental-model inference cannot be interpreted as measuring the intended capability without them.
Authors: The annotations in ALMANAC are collected directly from participants as self-reports of their self-reasoning, perceived partner intent, and perceived team goals immediately following each action. As participant-provided data rather than external labels, inter-rater agreement statistics do not apply. Self-validation is inherent to the collection method. We agree that correlation with observable behaviors (e.g., route deviations) would strengthen claims about the annotations as faithful proxies and will add such an analysis in the revision. revision: partial
Circularity Check
No circularity: dataset paper with no derivations or self-referential reductions.
full rationale
The paper introduces ALMANAC as a new annotated dataset from the Map Task and reports LLM benchmarks on next-turn prediction and mental-model inference. No equations, fitted parameters, or derivation chains appear in the provided text. Annotations are described as 'theory-informed' without any self-citation that bears the central claim or reduces the utility result to the input annotations by construction. Benchmarking evaluates external models against the fixed dataset, creating no self-definitional or fitted-input circularity. The absence of any load-bearing self-citation chain or renaming of known results keeps the score at 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mental models of self-reasoning, partner intent, and team goals can be validly annotated from collaboration transcripts using social science theory.
Reference graph
Works this paper leans on
-
[1]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Generative agent simulations of 1,000 people. arXiv preprint arXiv:2411.10109. Christian Poelitz, Finale Doshi-Velez, and Siân Lind- ley. 2026. A benchmark to assess common ground in human-ai collaboration.arXiv preprint arXiv:2602.21337. Kevin Pu, Daniel Lazaro, Ian Arawjo, Haijun Xia, Ziang Xiao, Tovi Grossman, and Yan Chen. 2025. Assis- tance or disrup...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents.ArXiv, abs/2307.13854. Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and 1 others. 2024. Sotopia: Interactive evaluation for so- cial intelligence in language agents. InInternational Conferenc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
grid_size
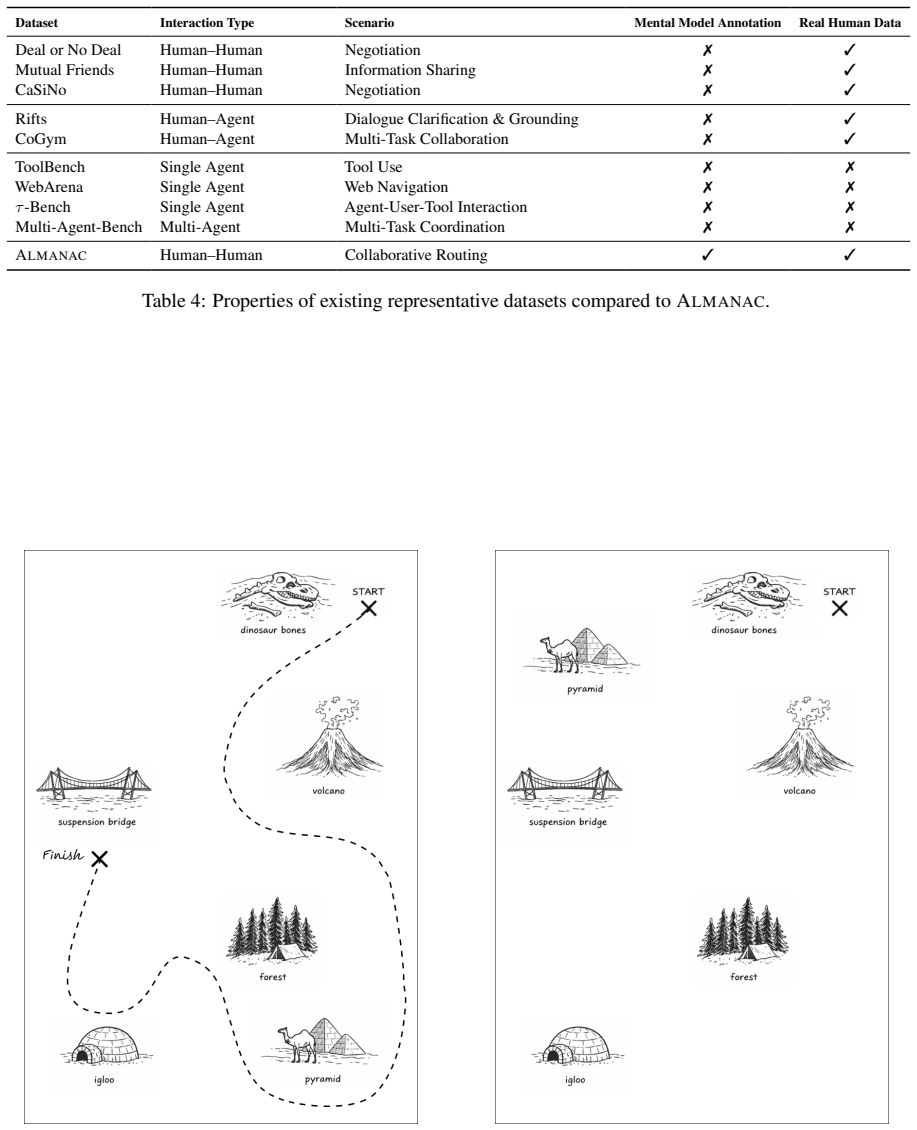
MultiAgentBench : Evaluating the collabora- tion and competition of LLM agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8580–8622, Vienna, Austria. Association for Computational Linguistics. A Properties of Current Collaboration Datasets Table 4 presents representative collab...
2017
-
[7]
The prediction should reflect the follower’s subjective understanding at that moment, not the objective ground truth of the task
why they took or understood the current action in that way. The prediction should reflect the follower’s subjective understanding at that moment, not the objective ground truth of the task. <Game Rules> - The follower and the guide cannot directly see each other’s maps. - One landmark on the follower’s map is misplaced compared with the guide’s map. Howev...
-
[8]
Still figuring out what we needed to do
team_goal What the follower thought the team was trying to do at that moment. Choose exactly one label: - "Still figuring out what we needed to do" - "Working toward a shared understanding" - "Clear on what to do and working on it" - "Something was unclear and we were working it out" - "Other"
-
[9]
Understood the situation and we were on the same page
partner_intent What the follower thought the guide was trying to do or understood at that moment. Choose exactly one label: - "Understood the situation and we were on the same page" - "Probably understood our situation but I was not fully sure" - "Is waiting for more information to understand the situation" - "Misunderstood and we were not aligned" - "Gav...
-
[10]
Executing a plan we already agreed on
self_reasoning What the follower thought they themselves were trying to do at that moment. Choose exactly one label: - "Executing a plan we already agreed on" - "Exploring on my own to gather information" - "Confirming the situation with my partner" - "Grounding by sharing or requesting information to align" - "Repairing a mistake or misunderstanding" - "...
-
[11]
type": "blocked
rationale A short free-form explanation, written from the follower’s perspective, describing what the team, the guide, and the follower were trying to do at that action moment. The rationale should sound like the participant’s own retrospective explanation, not an external analysis. <Map Interpretation> Discrete grid, 0-based [row, col]. Origin top-left [...
-
[12]
what the team was trying to do
-
[13]
what they thought the guide was trying to do
-
[14]
what they themselves were trying to do
-
[15]
The prediction should reflect the guide’s subjective understanding at that moment, not the objective ground truth of the task
why they took or understood the current action in that way. The prediction should reflect the guide’s subjective understanding at that moment, not the objective ground truth of the task. <Game Rules> - The follower and the guide cannot directly see each other’s maps. - One landmark on the follower’s map is misplaced compared with the guide’s map. However,...
-
[16]
Still figuring out what we needed to do
team_goal What the guide thought the team was trying to do at that moment. Choose exactly one label: - "Still figuring out what we needed to do" - "Working toward a shared understanding" - "Clear on what to do and working on it" - "Something was unclear and we were working it out" - "Other"
-
[17]
Understood the situation and we were on the same page
partner_intent What the guide thought the guide was trying to do or understood at that moment. Choose exactly one label: - "Understood the situation and we were on the same page" - "Probably understood our situation but I was not fully sure" - "Is waiting for more information to understand the situation" - "Misunderstood and we were not aligned" - "Gave n...
-
[18]
Executing a plan we already agreed on
self_reasoning What the guide thought they themselves were trying to do at that moment. Choose exactly one label: - "Executing a plan we already agreed on" - "Exploring on my own to gather information" - "Confirming the situation with my partner" - "Grounding by sharing or requesting information to align" - "Repairing a mistake or misunderstanding" - "Wai...
-
[19]
type": "blocked
rationale A short free-form explanation, written from the follower’s perspective, describing what the team, the guide, and the follower were trying to do at that action moment. The rationale should sound like the participant’s own retrospective explanation, not an external analysis. <Map Interpretation> Discrete grid, 0-based [row, col]. Origin top-left [...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.