Pretraining Recurrent Networks without Recurrence
Pith reviewed 2026-06-28 02:06 UTC · model grok-4.3
The pith
Supervised Memory Training reduces RNN pretraining to supervised one-step memory transitions using Transformer labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
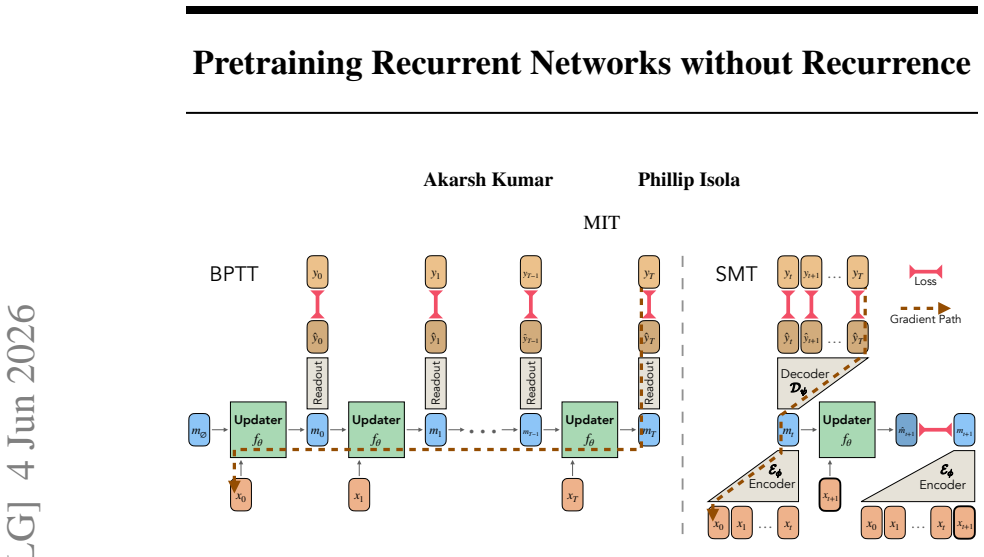
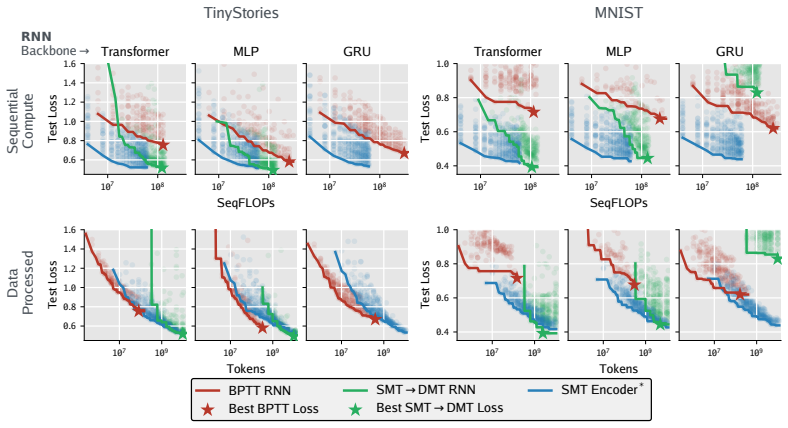
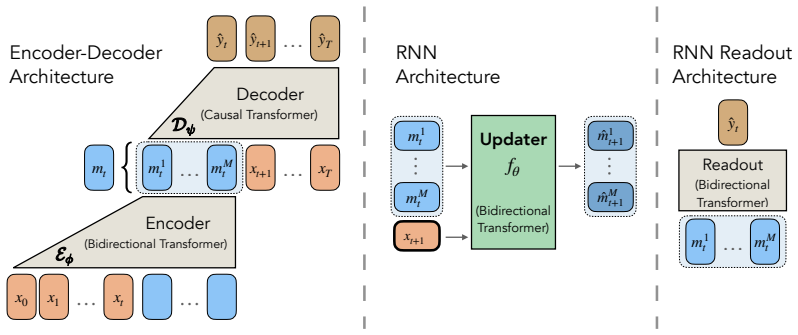
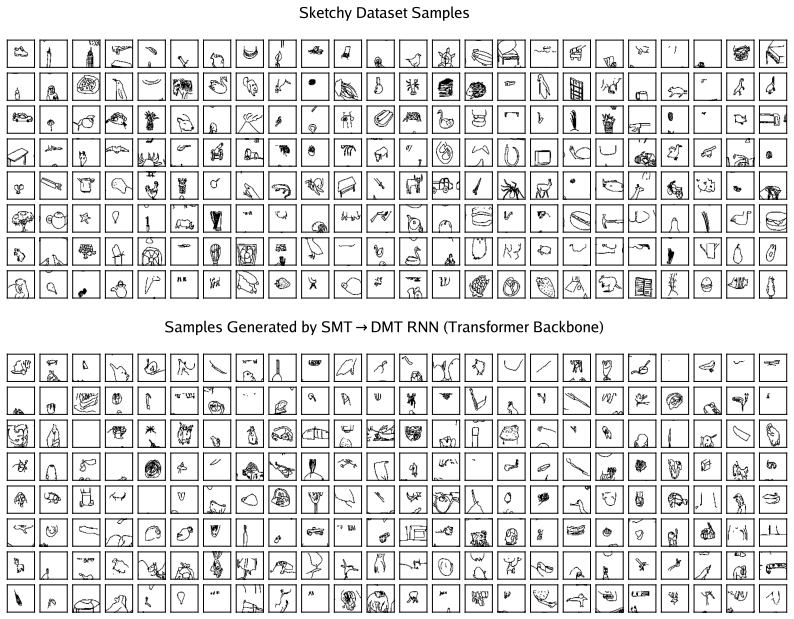
By training a Transformer encoder on a predictive state objective to produce memory labels, SMT reduces RNN training to supervised learning on pairs (m_t, x_{t+1}) mapping to m_{t+1}, enabling time-parallel training of nonlinear RNNs with stable O(1) length gradient paths between any tokens without unrolling the network, and outperforming BPTT on language and pixel sequence modeling.
What carries the argument
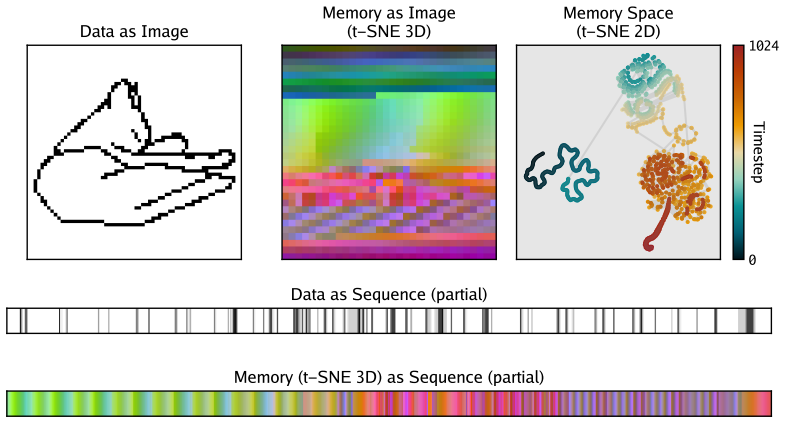
The predictive state objective that trains the Transformer encoder to retain only past information necessary to predict the future, generating memory labels for supervised RNN training.
If this is right
- RNN training becomes fully parallelizable in time without sequential unrolling.
- Gradient paths between tokens have constant length independent of sequence length.
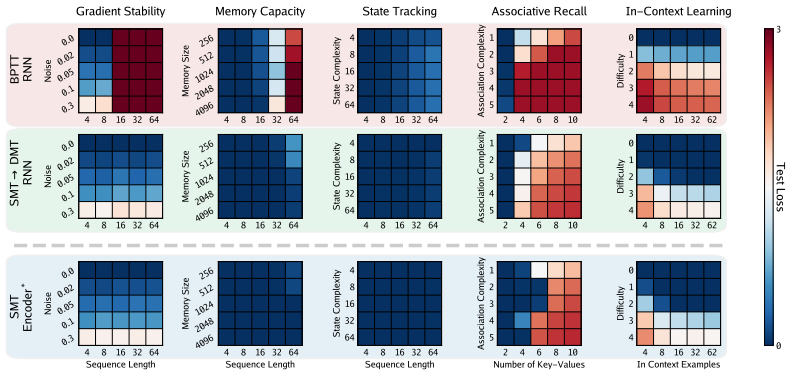
- Various RNN architectures can be pretrained on language modeling and pixel sequences more effectively than with BPTT.
- Memory content selection is decoupled from the memory update rule.
Where Pith is reading between the lines
- The approach might apply to training other sequential models that currently rely on recurrence.
- Combining SMT with larger-scale predictive encoders could improve label quality for complex temporal tasks.
- It opens the possibility of hybrid models where Transformers generate targets for recurrent components at scale.
Load-bearing premise
The memory states generated by the Transformer encoder on the predictive state objective are sufficient for the RNN to learn effective long-range associations when trained via supervised one-step transitions.
What would settle it
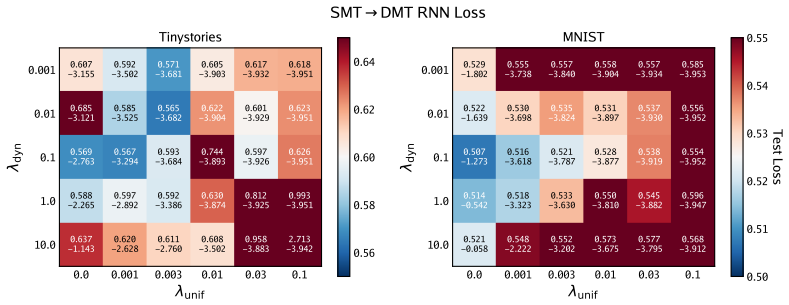
An experiment where an RNN trained via SMT on a long-sequence task requiring dependencies across many steps shows no improvement over BPTT or fails to learn those associations would falsify the central claim.
Figures


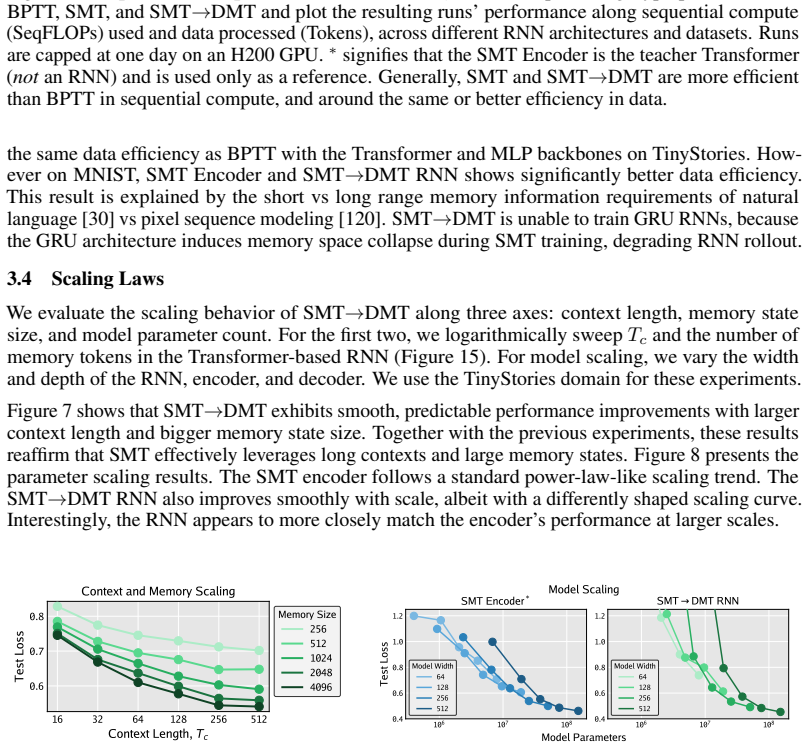


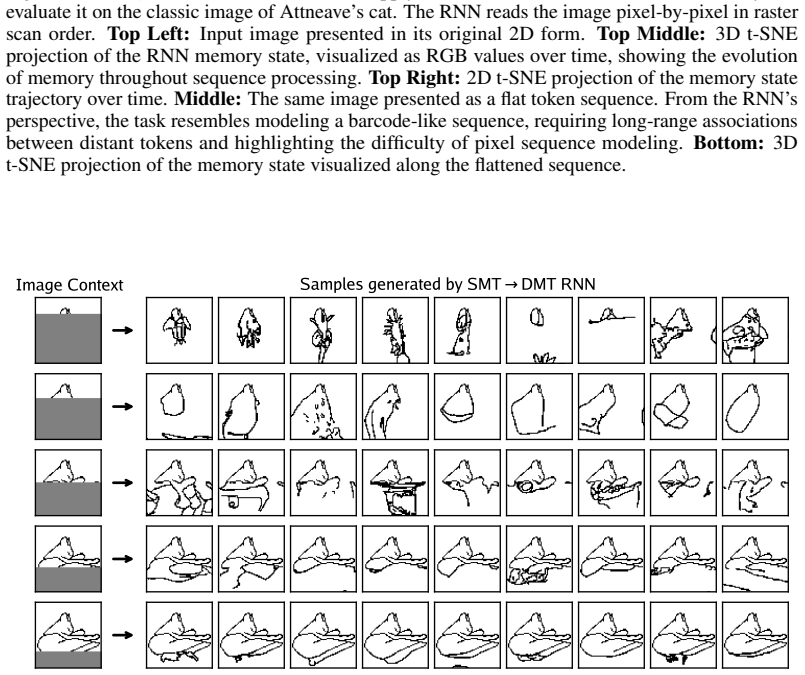
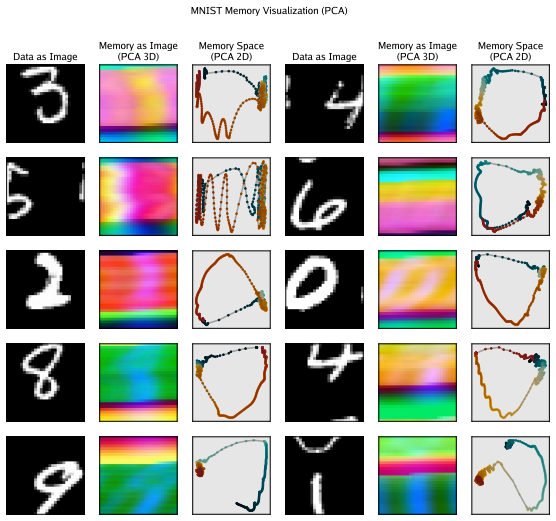


read the original abstract
Training recurrent neural networks (RNNs) requires assigning credit across long sequences of computations. Standard backpropagation through time (BPTT) addresses this problem poorly: it is sequential in time, limiting parallelism, and suffers from vanishing or exploding gradients, making long-range associations difficult to learn. We propose Supervised Memory Training (SMT), a method for training nonlinear RNNs that sidesteps recurrent credit propagation entirely by reducing RNN training to supervised learning on one-step memory transition labels $(m_t, x_{t+1}) \rightarrow m_{t+1}$. SMT acquires these memory labels by training a Transformer-based encoder on a predictive state objective--retaining only information from the past necessary to predict the future. By decoupling what to remember from how to update memory, SMT enables time-parallel RNN training with a stable $O(1)$ length gradient path between any two tokens--without ever unrolling the RNN. We find that SMT outperforms BPTT when pretraining various RNN architectures on tasks like language modeling and pixel sequence modeling. SMT enables nonlinear RNNs to better capture long-range dependencies and train in parallel, potentially unlocking the scaling of models that build temporal abstractions of past experience.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Supervised Memory Training (SMT) to pretrain nonlinear RNNs without recurrence or BPTT. A Transformer encoder is first trained on a predictive-state objective to produce memory labels m_t that retain only information from the past needed to predict the future; the RNN is then trained via supervised one-step transitions (m_t, x_{t+1}) o m_{t+1}. This is claimed to yield time-parallel training, a stable O(1)-length gradient path between any tokens, and better long-range dependency capture than BPTT on language modeling and pixel-sequence tasks.
Significance. If the empirical claims hold, SMT would decouple memory-label generation from recurrent dynamics and remove the need to unroll RNNs, potentially allowing nonlinear RNNs to scale on long sequences where BPTT fails. No machine-checked proofs, reproducible code, or parameter-free derivations are presented, so the significance rests entirely on the (currently undetailed) experimental results.
major comments (2)
- [Abstract] Abstract: the central empirical claim that SMT 'outperforms BPTT' on language modeling and pixel sequence modeling is stated without any quantitative results, baselines, ablation studies, or experimental protocol, rendering the claim impossible to evaluate.
- [Abstract] Abstract: the load-bearing assumption that Transformer-generated labels m_t produced by the predictive-state objective contain sufficient long-range state for an RNN trained only on one-step supervised transitions to maintain and propagate that information over hundreds of steps receives no supporting analysis, derivation, or ablation.
minor comments (1)
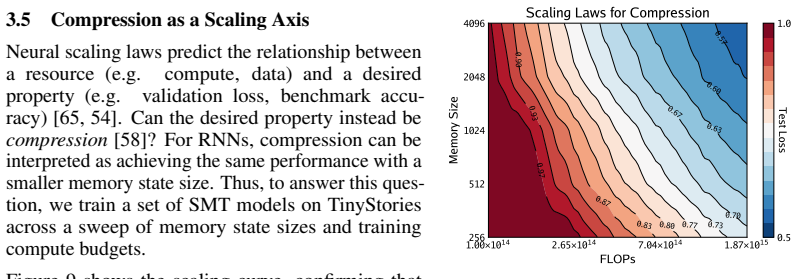
- The transition from the predictive-state loss to the supervised memory labels is described at a high level; an explicit equation relating the two objectives would clarify the method.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the abstract requires strengthening to make the empirical claims and underlying assumptions more self-contained and evaluable. We will revise the abstract accordingly while preserving the manuscript's core contributions.
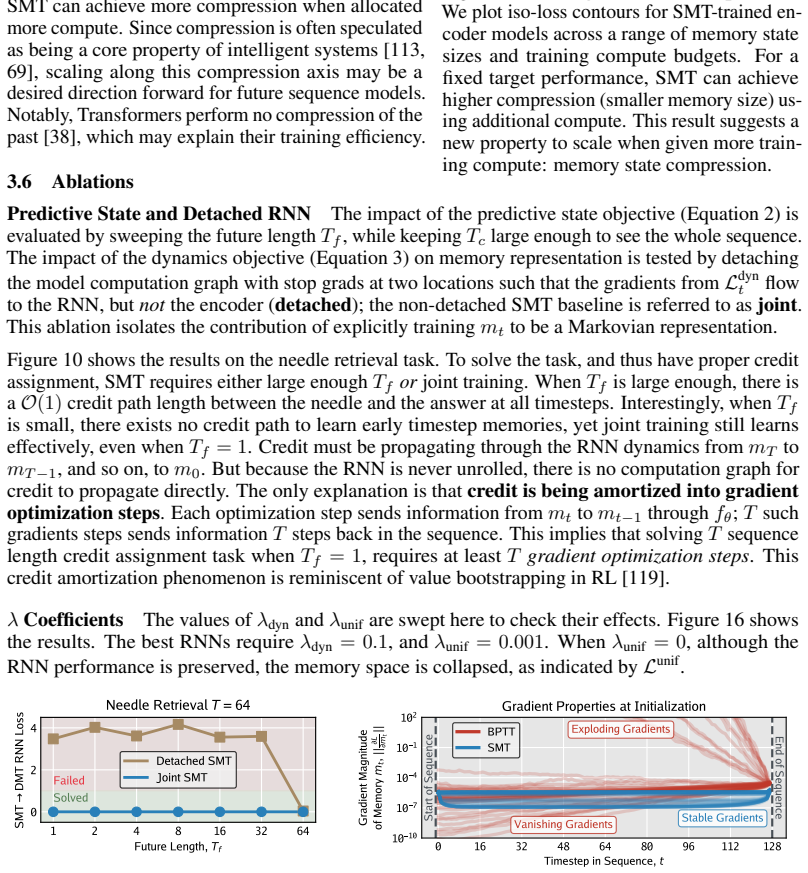
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that SMT 'outperforms BPTT' on language modeling and pixel sequence modeling is stated without any quantitative results, baselines, ablation studies, or experimental protocol, rendering the claim impossible to evaluate.
Authors: We agree that the abstract would benefit from quantitative support. In the revised version we will incorporate specific metrics (e.g., perplexity reductions on language modeling and accuracy gains on long pixel sequences), explicit baselines, and a concise statement of the experimental protocol so that the performance claim can be evaluated directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that Transformer-generated labels m_t produced by the predictive-state objective contain sufficient long-range state for an RNN trained only on one-step supervised transitions to maintain and propagate that information over hundreds of steps receives no supporting analysis, derivation, or ablation.
Authors: The predictive-state objective is constructed precisely so that each m_t retains only the information required to predict future tokens; the one-step supervised transitions then train the RNN to reproduce this mapping. The main text provides empirical ablations demonstrating improved long-range dependency capture relative to BPTT. Nevertheless, we acknowledge that the abstract itself offers no explicit justification or ablation summary. We will add a short clause in the abstract explaining the objective's design and will expand the discussion of label sufficiency in the revision. revision: yes
Circularity Check
No circularity; empirical method with independent label generation step
full rationale
The paper presents SMT as an empirical training procedure: a Transformer is trained separately on a predictive-state objective to produce memory labels m_t, after which an RNN is trained via supervised one-step transitions on those fixed labels. No equations, derivations, or self-citations are shown that reduce the claimed O(1) gradient path or performance gains to quantities fitted inside the RNN itself or to prior author results. The central performance claims rest on experimental comparisons to BPTT rather than any tautological reduction, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A Transformer encoder trained on a predictive state objective retains only information from the past necessary to predict the future.
invented entities (1)
-
Supervised Memory Training (SMT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. arXiv preprint arXiv:2211.15661, 2022
Pith/arXiv arXiv 2022
-
[2]
Validity of the single processor approach to achieving large scale computing capabilities
Gene M Amdahl. Validity of the single processor approach to achieving large scale computing capabilities. In Proceedings of the April 18-20, 1967, spring joint computer conference, pages 483–485, 1967
1967
-
[3]
An evolutionary algorithm that constructs recurrent neural networks
Peter J Angeline, Gregory M Saunders, and Jordan B Pollack. An evolutionary algorithm that constructs recurrent neural networks. IEEE transactions on Neural Networks, 5(1):54–65, 1994
1994
-
[4]
Unitary evolution recurrent neural networks
Martin Arjovsky, Amar Shah, and Yoshua Bengio. Unitary evolution recurrent neural networks. In International conference on machine learning, pages 1120–1128. PMLR, 2016
2016
-
[5]
Some informational aspects of visual perception
Fred Attneave. Some informational aspects of visual perception. Psychological review, 61(3): 183, 1954
1954
-
[6]
Neural machine translation by jointly learning to align and translate, 2016
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate, 2016. URLhttps://arxiv.org/abs/1409.0473
Pith/arXiv arXiv 2016
-
[7]
An empirical evaluation of generic convo- lutional and recurrent networks for sequence modeling
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. An empirical evaluation of generic convo- lutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271, 2018
Pith/arXiv arXiv 2018
-
[8]
Deep equilibrium models
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. Advances in neural information processing systems, 32, 2019
2019
-
[9]
xlstm: Ex- tended long short-term memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xlstm: Ex- tended long short-term memory. Advances in Neural Information Processing Systems, 37: 107547–107603, 2024
2024
-
[10]
Scheduled sampling for sequence prediction with recurrent neural networks, 2015
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks, 2015. URL https://arxiv.org/abs/ 1506.03099
Pith/arXiv arXiv 2015
-
[11]
Learning long-term dependencies with gradient descent is difficult
Yoshua Bengio, Patrice Simard, and Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE transactions on neural networks, 5(2):157–166, 1994
1994
-
[12]
A brief history of intelligence: evolution, AI, and the five breakthroughs that made our brains
Max S Bennett. A brief history of intelligence: evolution, AI, and the five breakthroughs that made our brains. HarperCollins, 2023
2023
-
[13]
Prefix sums and their applications
Guy E Blelloch. Prefix sums and their applications. 1990
1990
-
[14]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877– 1901, 2020. 12
1901
-
[15]
Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022
2022
-
[16]
Yingfa Chen, Zhen Leng Thai, Zihan Zhou, Zhu Zhang, Xingyu Shen, Shuo Wang, Chaojun Xiao, Xu Han, and Zhiyuan Liu. Hybrid linear attention done right: Efficient distillation and effective architectures for extremely long contexts, 2026. URL https://arxiv.org/abs/ 2601.22156
arXiv 2026
-
[17]
On the properties of neural machine translation: Encoder–decoder approaches
Kyunghyun Cho, Bart Van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder–decoder approaches. In Proceedings of SSST-8, eighth workshop on syntax, semantics and structure in statistical translation, pages 103–111, 2014
2014
-
[18]
Empirical evaluation of gated recurrent neural networks on sequence modeling
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014
Pith/arXiv arXiv 2014
-
[19]
Hierarchical multiscale recurrent neural networks
Junyoung Chung, Sungjin Ahn, and Yoshua Bengio. Hierarchical multiscale recurrent neural networks. arXiv preprint arXiv:1609.01704, 2016
Pith/arXiv arXiv 2016
-
[20]
A taxonomy of problems with fast parallel algorithms
Stephen A Cook. A taxonomy of problems with fast parallel algorithms. Information and control, 64(1-3):2–22, 1985
1985
-
[21]
Transformer-xl: Attentive language models beyond a fixed-length context
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell, Quoc Le, and Ruslan Salakhutdi- nov. Transformer-xl: Attentive language models beyond a fixed-length context. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 2978–2988, 2019
2019
-
[22]
Deeppcr: Parallelizing sequential operations in neural networks
Federico Danieli, Miguel Sarabia, Xavier Suau Cuadros, Pau Rodriguez, and Luca Zap- pella. Deeppcr: Parallelizing sequential operations in neural networks. Advances in Neural Information Processing Systems, 36:47598–47625, 2023
2023
-
[23]
Pararnn: Unlocking parallel training of nonlinear rnns for large language models, 2025
Federico Danieli, Pau Rodriguez, Miguel Sarabia, Xavier Suau, and Luca Zappella. Pararnn: Unlocking parallel training of nonlinear rnns for large language models, 2025. URL https: //arxiv.org/abs/2510.21450
arXiv 2025
-
[24]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. arXiv preprint arXiv:2405.21060, 2024
Pith/arXiv arXiv 2024
-
[25]
Practical learning of predictive state representations
Carlton Downey, Ahmed Hefny, and Geoffrey Gordon. Practical learning of predictive state representations. arXiv preprint arXiv:1702.04121, 2017
Pith/arXiv arXiv 2017
-
[26]
Predictive state recurrent neural networks, 2017
Carlton Downey, Ahmed Hefny, Boyue Li, Byron Boots, and Geoffrey Gordon. Predictive state recurrent neural networks, 2017. URLhttps://arxiv.org/abs/1705.09353
Pith/arXiv arXiv 2017
-
[27]
Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english? arXiv preprint arXiv:2305.07759, 2023
Pith/arXiv arXiv 2023
-
[28]
Finding structure in time
Jeffrey L Elman. Finding structure in time. Cognitive science, 14(2):179–211, 1990
1990
-
[29]
Addressing some limitations of transformers with feedback memory
Angela Fan, Thibaut Lavril, Edouard Grave, Armand Joulin, and Sainbayar Sukhbaatar. Addressing some limitations of transformers with feedback memory. arXiv preprint arXiv:2002.09402, 2020
arXiv 2002
-
[30]
What is wrong with perplexity for long-context language modeling?, 2025
Lizhe Fang, Yifei Wang, Zhaoyang Liu, Chenheng Zhang, Stefanie Jegelka, Jinyang Gao, Bolin Ding, and Yisen Wang. What is wrong with perplexity for long-context language modeling?, 2025. URLhttps://arxiv.org/abs/2410.23771
arXiv 2025
-
[31]
Were rnns all we needed? arXiv preprint arXiv:2410.01201, 2024
Leo Feng, Frederick Tung, Mohamed Osama Ahmed, Yoshua Bengio, and Hossein Hajimir- sadeghi. Were rnns all we needed? arXiv preprint arXiv:2410.01201, 2024
arXiv 2024
-
[32]
Neural thickets: Diverse task experts are dense around pretrained weights
Yulu Gan and Phillip Isola. Neural thickets: Diverse task experts are dense around pretrained weights. arXiv preprint arXiv:2603.12228, 2026. 13
arXiv 2026
-
[33]
Scaling up test-time compute with latent reasoning: A recurrent depth approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171, 2025
Pith/arXiv arXiv 2025
-
[34]
Looped transformers as programmable computers
Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. InInternational Conference on Machine Learning, pages 11398–11442. PMLR, 2023
2023
-
[35]
Towards scal- able and stable parallelization of nonlinear rnns
Xavier Gonzalez, Andrew Warrington, Jimmy T Smith, and Scott W Linderman. Towards scal- able and stable parallelization of nonlinear rnns. Advances in Neural Information Processing Systems, 37:5817–5849, 2024
2024
-
[36]
Predictability enables parallelization of nonlinear state space models
Xavier Gonzalez, Leo Kozachkov, David M Zoltowski, Kenneth L Clarkson, and Scott W Linderman. Predictability enables parallelization of nonlinear state space models. arXiv preprint arXiv:2508.16817, 2025
arXiv 2025
-
[37]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014
Pith/arXiv arXiv 2014
-
[38]
On the tradeoffs of state space models and transformers, 2025
Albert Gu. On the tradeoffs of state space models and transformers, 2025. URL https: //goombalab.github.io/blog/2025/tradeoffs/
2025
-
[39]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[40]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2021
Pith/arXiv arXiv 2021
-
[41]
Long timescale credit assignment in neuralnetworks with external memory, 2017
Steven Stenberg Hansen. Long timescale credit assignment in neuralnetworks with external memory, 2017. URLhttps://arxiv.org/abs/1701.03866
Pith/arXiv arXiv 2017
-
[42]
Training large language models to reason in a continuous latent space, 2025
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space, 2025. URL https://arxiv.org/abs/2412.06769
Pith/arXiv arXiv 2025
-
[43]
Effective distillation to hybrid xlstm architectures, 2026
Lukas Hauzenberger, Niklas Schmidinger, Thomas Schmied, Anamaria-Roberta Hartl, David Stap, Pieter-Jan Hoedt, Maximilian Beck, Sebastian Böck, Günter Klambauer, and Sepp Hochreiter. Effective distillation to hybrid xlstm architectures, 2026. URL https://arxiv. org/abs/2603.15590
arXiv 2026
-
[44]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[45]
Psychology press, 1949
Donald Olding Hebb.The organization of behavior: A neuropsychological theory. Psychology press, 1949
1949
-
[46]
Recurrent predictive state policy networks, 2018
Ahmed Hefny, Zita Marinho, Wen Sun, Siddhartha Srinivasa, and Geoffrey Gordon. Recurrent predictive state policy networks, 2018. URLhttps://arxiv.org/abs/1803.01489
Pith/arXiv arXiv 2018
-
[47]
Orthogonal recurrent neural networks with scaled cayley transform
Kyle Helfrich, Devin Willmott, and Qiang Ye. Orthogonal recurrent neural networks with scaled cayley transform. In International Conference on Machine Learning, pages 1969–1978. PMLR, 2018
1969
-
[48]
Hierarchical recurrent neural networks for long-term depen- dencies
Salah Hihi and Yoshua Bengio. Hierarchical recurrent neural networks for long-term depen- dencies. Advances in neural information processing systems, 8, 1995
1995
-
[49]
Data parallel algorithms
W Daniel Hillis and Guy L Steele Jr. Data parallel algorithms. Communications of the ACM, 29(12):1170–1183, 1986
1986
-
[50]
Parallel models of associative memory: updated edition
Geoffrey E Hinton and James A Anderson. Parallel models of associative memory: updated edition. Psychology press, 2014. 14
2014
-
[51]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[52]
Long short-term memory
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9 (8):1735–1780, 1997
1997
-
[53]
Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001
Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, Jürgen Schmidhuber, et al. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001
2001
-
[54]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 10, 2022
Pith/arXiv arXiv 2022
-
[55]
The hardware lottery
Sara Hooker. The hardware lottery. Communications of the ACM, 64(12):58–65, 2021
2021
-
[56]
Neural networks and physical systems with emergent collective computational abilities
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554–2558, 1982
1982
-
[57]
Multilayer feedforward networks are universal approximators
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989
1989
-
[58]
Universal artificial intelligence: Sequential decisions based on algorithmic probability, volume 300
Marcus Hutter. Universal artificial intelligence: Sequential decisions based on algorithmic probability, volume 300. Springer, 2005
2005
-
[59]
Block-recurrent dynamics in vision transformers
Mozes Jacobs, Thomas Fel, Richard Hakim, Alessandra Brondetta, Demba Ba, and T Andy Keller. Block-recurrent dynamics in vision transformers. arXiv preprint arXiv:2512.19941, 2025
arXiv 2025
-
[60]
echo state
Herbert Jaeger. The “echo state” approach to analysing and training recurrent neural networks- with an erratum note. Bonn, Germany: German national research center for information technology gmd technical report, 148(34):13, 2001
2001
-
[61]
Less is more: Recursive reasoning with tiny networks, 2025
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks, 2025. URLhttps://arxiv.org/abs/2510.04871
Pith/arXiv arXiv 2025
-
[62]
Planning and acting in partially observable stochastic domains
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains. Artificial intelligence, 101(1-2):99–134, 1998
1998
-
[63]
Training recurrent neural networks via forward propagation through time
Anil Kag and Venkatesh Saligrama. Training recurrent neural networks via forward propagation through time. In International Conference on Machine Learning, pages 5189–5200. PMLR, 2021
2021
-
[64]
Principles of neural science, 2000
Eric R Kandel. Principles of neural science, 2000
2000
-
[65]
Scaling laws for neural language models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[66]
Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, and Noah A. Smith. Finetuning pretrained transformers into rnns, 2021. URLhttps://arxiv.org/abs/2103.13076
arXiv 2021
-
[67]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[68]
General-purpose in-context learning by meta-learning transformers
Louis Kirsch, James Harrison, Jascha Sohl-Dickstein, and Luke Metz. General-purpose in-context learning by meta-learning transformers. arXiv preprint arXiv:2212.04458, 2022
arXiv 2022
-
[69]
Three approaches to the quantitative definition of information
Andrei Nikolaevic Kolmogorov. Three approaches to the quantitative definition of information. International journal of computer mathematics, 2(1-4):157–168, 1968
1968
-
[70]
Professor forcing: A new algorithm for training recurrent networks
Alex M Lamb, Anirudh Goyal ALIAS PARTH GOY AL, Ying Zhang, Saizheng Zhang, Aaron C Courville, and Yoshua Bengio. Professor forcing: A new algorithm for training recurrent networks. Advances in neural information processing systems, 29, 2016. 15
2016
-
[71]
The MNIST database of handwritten digits, 1998
Yann LeCun and Corinna Cortes. The MNIST database of handwritten digits, 1998. URL http://yann.lecun.com/exdb/mnist/
1998
-
[72]
Li, Zifan Carl Guo, and Jacob Andreas
Belinda Z. Li, Zifan Carl Guo, and Jacob Andreas. (how) do language models track state?,
-
[73]
URLhttps://arxiv.org/abs/2503.02854
-
[74]
Noprop: Training neural networks without full back-propagation or full forward-propagation
Qinyu Li, Yee Whye Teh, and Razvan Pascanu. Noprop: Training neural networks without full back-propagation or full forward-propagation. arXiv preprint arXiv:2503.24322, 2025
arXiv 2025
-
[75]
Parallelizing non-linear sequential models over the sequence length, 2024
Yi Heng Lim, Qi Zhu, Joshua Selfridge, and Muhammad Firmansyah Kasim. Parallelizing non-linear sequential models over the sequence length, 2024. URL https://arxiv.org/ abs/2309.12252
arXiv 2024
-
[76]
Predictive representations of state
Michael Littman and Richard S Sutton. Predictive representations of state. Advances in neural information processing systems, 14, 2001
2001
-
[77]
Transform- ers learn shortcuts to automata
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transform- ers learn shortcuts to automata. arXiv preprint arXiv:2210.10749, 2022
arXiv 2022
-
[78]
Yuxi Liu, Konpat Preechakul, Kananart Kuwaranancharoen, and Yutong Bai. The serial scaling hypothesis. arXiv preprint arXiv:2507.12549, 2025
Pith/arXiv arXiv 2025
-
[79]
Reservoir computing approaches to recurrent neural network training
Mantas Lukoševiˇcius and Herbert Jaeger. Reservoir computing approaches to recurrent neural network training. Computer science review, 3(3):127–149, 2009
2009
-
[80]
Parallelizing linear recurrent neural nets over sequence length,
Eric Martin and Chris Cundy. Parallelizing linear recurrent neural nets over sequence length,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.