FP8 is All You Need (Part 1): Debunking Hardware FP64 as the HPC Holy Grail
Pith reviewed 2026-06-29 00:41 UTC · model grok-4.3
The pith
FP8 tensor throughput with Ozaki Scheme II recovers full FP64 accuracy at memory-roof speeds on B300 GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
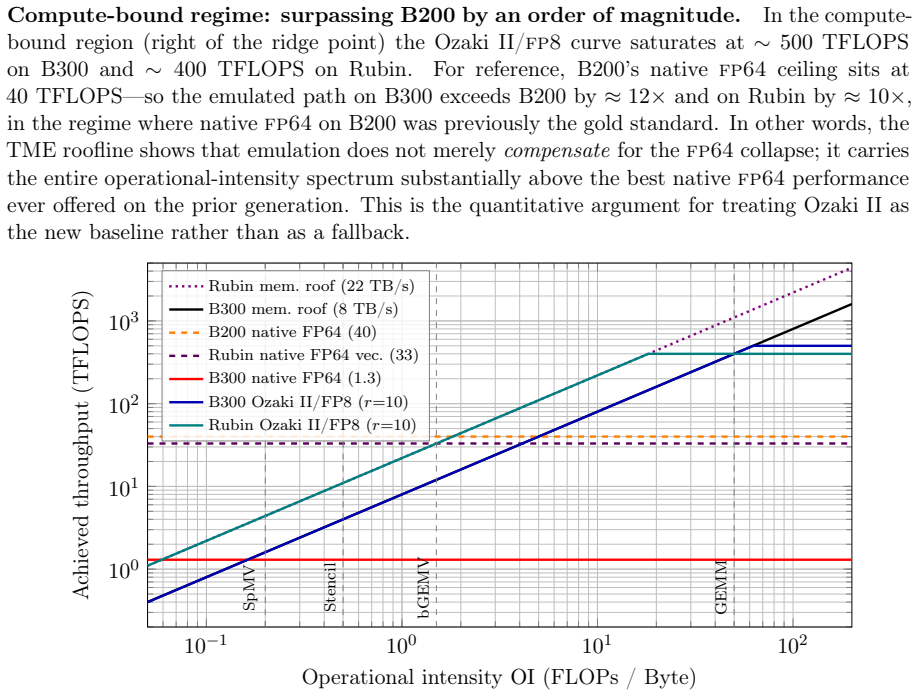
On AI-optimised GPUs of the B300 generation and beyond, abundant FP8 tensor throughput combined with the Chinese Remainder Theorem-based Ozaki Scheme II recovers memory-roof execution at full FP64 accuracy across the canonical HPC kernel spectrum, projecting effective FP64 rates of 500 TFLOPS on B300 while matching memory bandwidth limits in bandwidth-bound cases.
What carries the argument
Ozaki Scheme II, a Chinese Remainder Theorem-based reconstruction method that emulates FP64 using FP8 tensor operations, with register-level fusion to achieve beta approaching 1 in the TME model.
If this is right
- B300 native FP64 at 1.3 TFLOPS is replaced by emulated rates up to 500 TFLOPS in compute-bound regimes.
- Performance matches or exceeds H100 native FP64 on all workloads studied.
- Combined with Kulisch fixed-point methods for FFTs, every kernel class reaches the memory roof at full FP64.
- Native FP64 silicon is no longer required for production HPC workloads.
Where Pith is reading between the lines
- Future GPU designs may allocate more silicon to tensor units rather than dedicated FP64 pipelines.
- The same emulation approach could be tested on other low-precision formats or non-GPU accelerators.
- Real hardware runs would be required to validate whether the TME model parameters hold under production conditions.
Load-bearing premise
The TME model parameters guarantee that reconstruction overhead remains negligible and full FP64 accuracy holds for every surveyed kernel.
What would settle it
Measure actual throughput and accuracy of Ozaki II on B300 hardware for kernels such as GEMM and SpMV to check whether full FP64 results are obtained near the projected 500 TFLOPS or memory roof.
Figures
read the original abstract
Conventional HPC dogma holds that native hardware FP64 silicon is the irreducible foundation of scientific computing -- the "holy grail" of double-precision simulation. This paper argues the dogma is wrong: on AI-optimised GPUs of the B300 generation and beyond, abundant FP8 tensor throughput combined with the Chinese Remainder Theorem-based Ozaki Scheme II recovers memory-roof execution at full FP64 accuracy across the canonical HPC kernel spectrum. NVIDIA's Blackwell Ultra (B300) collapses native FP64 to ~1.3 TFLOPS -- a 31x regression from the B200 -- rendering even memory-bound kernels (SpMV, GEMV, stencils) compute-bound. We make four contributions. First, a unified analytic model, the Tensor-Memory Equilibrium (TME) model, augmenting the Roofline with a compute multiplier alpha, a bandwidth multiplier beta, and a reconstruction latency gamma. Second, we identify register-level fusion as the mechanism driving beta -> 1, making emulation essentially free behind the memory wall. Third, we project that Ozaki II vaults emulated FP64 from the ~1 TFLOPS native floor to ~500 TFLOPS (B300) and ~400 TFLOPS (Rubin R200), exceeding even B200's native FP64 ceiling by over an order of magnitude in the compute-bound regime while matching the memory roof in the bandwidth-bound regime. Fourth, against an H100 baseline, Ozaki II matches or exceeds H100 on every workload studied, versus the up-to-50x regression that B300 native FP64 imposes. Combined with a companion FFT analysis (Kulisch fixed-point reconstruction on the surviving INT32 pipe) and FP32+Kahan reductions reported in the companion Part(2) paper, every surveyed kernel class on B300 reaches the memory roof at full FP64. The evidence supports the title's claim: FP8, with Ozaki II and Kulisch escape routes, is all one needs for production HPC; native FP64 silicon is no longer the holy grail it has been taken to be.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on AI-optimized GPUs such as NVIDIA Blackwell Ultra (B300), abundant FP8 tensor throughput combined with the Chinese Remainder Theorem-based Ozaki Scheme II can recover memory-roof execution at full FP64 accuracy for canonical HPC kernels including SpMV, GEMV, and stencils. It introduces the Tensor-Memory Equilibrium (TME) analytic model augmenting Roofline with multipliers alpha (compute), beta (bandwidth), and gamma (reconstruction latency), asserts that register-level fusion drives beta to 1, and projects ~500 TFLOPS effective FP64 on B300 (exceeding B200 native FP64) while matching or exceeding H100 baselines, concluding that native FP64 silicon is no longer required.
Significance. If the TME projections and accuracy claims hold with supporting analysis, the result would challenge the necessity of dedicated FP64 hardware in future HPC systems and shift design priorities toward lower-precision tensor units with emulation techniques, with potential impact on both architecture and software stacks for scientific computing.
major comments (3)
- [Abstract] Abstract: the TME model defines free parameters alpha, beta, and gamma (with beta asserted to reach exactly 1 via register-level fusion) but supplies no register-pressure analysis, instruction schedule, or first-principles derivation showing that multiple FP8 GEMMs plus CRT reconstruction fit without spilling or extra memory traffic for the surveyed kernels; the ~500 TFLOPS projection on B300 is obtained by direct multiplication of the native FP8 rate by these unverified factors.
- [Abstract] Abstract: the claim of 'full FP64 accuracy' for Ozaki Scheme II across the kernel spectrum is stated without cross-validation against native FP64 references or explicit bounds on rounding/overflow in the reconstruction steps, yet this premise is required for the central assertion that emulation recovers exact memory-roof execution.
- [Abstract] Abstract: the performance comparison to H100 and the claim that Ozaki II 'matches or exceeds H100 on every workload' while native B300 FP64 imposes up to 50x regression rest on the same unverified TME parameters; no sensitivity analysis or alternative parameter values are provided to test robustness.
minor comments (1)
- [Abstract] The abstract introduces the TME model and Ozaki Scheme II without a forward reference to the section containing their formal definitions or the precise equations for alpha, beta, and gamma.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the presentation of the TME model and the supporting claims. We address each major comment below and will incorporate additional analysis to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the TME model defines free parameters alpha, beta, and gamma (with beta asserted to reach exactly 1 via register-level fusion) but supplies no register-pressure analysis, instruction schedule, or first-principles derivation showing that multiple FP8 GEMMs plus CRT reconstruction fit without spilling or extra memory traffic for the surveyed kernels; the ~500 TFLOPS projection on B300 is obtained by direct multiplication of the native FP8 rate by these unverified factors.
Authors: We agree that the abstract does not contain the requested register-pressure analysis or instruction schedule. The TME model in the manuscript body parameterizes beta from the architectural register file size and the number of intermediate values generated by Ozaki II, but a detailed first-principles derivation confirming no register spilling for SpMV, GEMV, and stencils is absent. We will add this analysis (including register usage estimates and a high-level schedule) in a new subsection or appendix of the revised manuscript to verify that beta reaches 1 without extra memory traffic. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'full FP64 accuracy' for Ozaki Scheme II across the kernel spectrum is stated without cross-validation against native FP64 references or explicit bounds on rounding/overflow in the reconstruction steps, yet this premise is required for the central assertion that emulation recovers exact memory-roof execution.
Authors: The manuscript asserts full FP64 accuracy on the basis of the exact arithmetic properties of CRT reconstruction within the representable range. However, the abstract and main text do not include explicit cross-validation against native FP64 or derived bounds on reconstruction overflow for the target kernels. We will expand the accuracy section with direct numerical comparisons and explicit overflow bounds in the revision. revision: yes
-
Referee: [Abstract] Abstract: the performance comparison to H100 and the claim that Ozaki II 'matches or exceeds H100 on every workload' while native B300 FP64 imposes up to 50x regression rest on the same unverified TME parameters; no sensitivity analysis or alternative parameter values are provided to test robustness.
Authors: The H100 comparisons and the 50x regression claim are obtained by substituting the B300 and H100 architectural parameters into the TME equations. We acknowledge the absence of sensitivity analysis on alpha, beta, and gamma. The revised manuscript will include a sensitivity study that varies these parameters over plausible ranges and reports the resulting performance envelopes, thereby testing robustness of the workload comparisons. revision: yes
Circularity Check
TME model projections of ~500 TFLOPS reduce to assumed multipliers alpha/beta/gamma by construction
specific steps
-
fitted input called prediction
[Abstract]
"a unified analytic model, the Tensor-Memory Equilibrium (TME) model, augmenting the Roofline with a compute multiplier alpha, a bandwidth multiplier beta, and a reconstruction latency gamma. ... we project that Ozaki II vaults emulated FP64 from the ~1 TFLOPS native floor to ~500 TFLOPS (B300) and ~400 TFLOPS (Rubin R200)"
The ~500 TFLOPS figure is obtained by plugging the TME parameters (particularly beta set to 1 via the register-fusion claim) into the model; the projection is therefore the direct numerical output of those assumed multipliers rather than an independent result.
full rationale
The abstract presents the TME model (with alpha, beta, gamma) as the basis for projecting emulated FP64 performance to ~500 TFLOPS on B300, asserting beta->1 via register-level fusion. This matches the fitted_input_called_prediction pattern because the headline performance numbers are generated directly from the model's own parameters rather than from independent derivation, external benchmarks, or first-principles register analysis shown in the text. No other circular patterns (self-citation chains, self-definitional equations, or ansatz smuggling) are exhibited in the provided sections. The central claim therefore has partial circularity but retains some independent modeling content.
Axiom & Free-Parameter Ledger
free parameters (3)
- alpha
- beta
- gamma
axioms (2)
- standard math Chinese Remainder Theorem enables exact FP64 reconstruction from FP8 operations
- domain assumption Register-level fusion drives beta to 1 making emulation free behind the memory wall
invented entities (1)
-
Tensor-Memory Equilibrium (TME) model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amestoy, Iain S
Patrick R. Amestoy, Iain S. Duff, Jean-Yves L’Excellent, and Jacko Koster. A fully asyn- chronousmultifrontalsolverusingdistributeddynamicscheduling.SIAM Journal on Matrix 24 Analysis and Applications, 23(1):15–41, 2001
2001
-
[2]
Higham, and Enrique S
Hartwig Anzt, Jack Dongarra, Goran Flegar, Nicholas J. Higham, and Enrique S. Quintana- Ortí. Adaptive precision in block-Jacobi preconditioning for iterative sparse linear system solvers.Concurrency and Computation: Practice and Experience, 31(6):e4460, 2019
2019
-
[3]
Booth, Alex J.˜W
George H. Booth, Alex J.˜W. Thom, and Ali Alavi. Fermion Monte Carlo without fixed nodes: A game of life, death, and annihilation in Slater determinant space.Journal of Chemical Physics, 131:054106, 2009
2009
-
[4]
Clark, Ronald Babich, Kipton Barros, Richard C
Michael A. Clark, Ronald Babich, Kipton Barros, Richard C. Brower, and Claudio Rebbi. Solving lattice QCD systems of equations using mixed precision solvers on GPUs.Computer Physics Communications, 181(9):1517–1528, 2010
2010
-
[5]
Fifteen years of FP64 segmentation, and why the Blackwell ultra breaks the pattern
Nicolas Dickenmann. Fifteen years of FP64 segmentation, and why the Blackwell ultra breaks the pattern. Blog post, 2026
2026
-
[6]
Harvey L. Garner. The residue number system.IRE Transactions on Electronic Computers, EC-8(2):140–147, 1959
1959
-
[7]
SPTCStencil: Unleashing sparse tensor cores for stencil computation via strided swap, 2025
Qiqi Gu, Chenpeng Wu, Heng Shi, and Jianguo Yao. SPTCStencil: Unleashing sparse tensor cores for stencil computation via strided swap, 2025. arXiv:2506.22035
-
[8]
Azzam Haidar, Stanimire Tomov, Jack Dongarra, and Nicholas J. Higham. Harnessing GPU tensor cores for fast FP16 arithmetic to speed up mixed-precision iterative refinement solvers. InSC18: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 603–613, 2018
2018
-
[9]
Microbenchmarking NVIDIA’s Blackwell architecture: An in-depth architectural analysis, 2025
Aaron Jarmusch and Sunita Chandrasekaran. Microbenchmarking NVIDIA’s Blackwell architecture: An in-depth architectural analysis, 2025
2025
-
[10]
Kalamkar, Karthikeyan Vaidyanathan, Mikhail Smelyanskiy, Karthikeyan Pamnany, Victor W
Bálint Joo, Dhiraj D. Kalamkar, Karthikeyan Vaidyanathan, Mikhail Smelyanskiy, Karthikeyan Pamnany, Victor W. Lee, Pradeep Dubey, and William Watson. Lattice QCD on Intel Xeon Phi coprocessors.ISC High Performance, 2013
2013
-
[11]
Pracniques: Further remarks on reducing truncation errors.Communica- tions of the ACM, 8(1):40, 1965
William Kahan. Pracniques: Further remarks on reducing truncation errors.Communica- tions of the ACM, 8(1):40, 1965
1965
-
[12]
Knuth.The Art of Computer Programming, Volume 2: Seminumerical Algo- rithms
Donald E. Knuth.The Art of Computer Programming, Volume 2: Seminumerical Algo- rithms. Addison-Wesley, 3rd edition, 1997
1997
-
[13]
U. W. Kulisch. Mathematical foundation of computer arithmetic.IEEE Transactions on Computers, C-26(7):610–621, 1977
1977
-
[14]
Kulischand W.L
U.W. Kulischand W.L. Miranker. Thearithmeticof thedigital computer: Anew approach. SIAM Review, 28(1):1–40, 1986
1986
-
[15]
Toward accelerated stencil computation by adapting tensor core unit on GPU
Xueying Liu et al. Toward accelerated stencil computation by adapting tensor core unit on GPU. InProceedings of the 36th ACM International Conference on Supercomputing, 2022
2022
-
[16]
Lockwood
Glenn K. Lockwood. NVIDIA Rubin: Architecture notes and performance specifications. Glenn’s Digital Garden, 2026.https://www.glennklockwood.com/garden/processors/ R200, accessed May 2026
2026
-
[17]
Nvidia unpacks Vera Rubin rack system at CES
Tobias Mann. Nvidia unpacks Vera Rubin rack system at CES. The Register, January 2026. Documents Rubin FP64 vector regression from45to33TFLOPS. 25
2026
-
[18]
Stefano Markidis, Steven Wei Der Chien, Erwin Laure, Ivy Bo Peng, and Jeffrey S. Vetter. NVIDIAtensorcoreprogrammability, performance&precision. In2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 522–531, 2018
2018
-
[19]
FP8 is all you need (part 2): Efficient Ozaki–Bailey style FFT through tensor-core Garner reformulation and Kulisch escape route
Satoshi Matsuoka. FP8 is all you need (part 2): Efficient Ozaki–Bailey style FFT through tensor-core Garner reformulation and Kulisch escape route. Companion manuscript, 2026. In preparation
2026
-
[20]
DGEMM without FP64 arithmetic: Using FP64 emulation and FP8 tensor cores with Ozaki scheme, 2025
Daichi Mukunoki. DGEMM without FP64 arithmetic: Using FP64 emulation and FP8 tensor cores with Ozaki scheme, 2025
2025
-
[21]
DGEMMusing tensor cores, and its accurate and reproducible versions
DaichiMukunoki, KatsuhisaOzaki, TakeshiOgita, andToshiyukiImamura. DGEMMusing tensor cores, and its accurate and reproducible versions. InHigh Performance Computing – ISC High Performance 2020, pages 230–248. Springer, 2020
2020
-
[22]
Doudna: NERSC’s next-generation supercomputer based on NVIDIA Vera Rubin
NERSC. Doudna: NERSC’s next-generation supercomputer based on NVIDIA Vera Rubin. National Energy Research Scientific Computing Center, 2026
2026
-
[23]
NVIDIA Corporation.NVIDIA Blackwell Architecture Technical Brief, 2024
2024
-
[24]
Individual Blackwell Ultra GPU specifications, October 2025
NVIDIA Corporation.NVIDIA Blackwell Ultra GPU Datasheet, 2025. Individual Blackwell Ultra GPU specifications, October 2025
2025
-
[25]
NVIDIA HPC-Benchmarks 25.04: Ozaki-I HPL on blackwell tensor cores
NVIDIA Corporation. NVIDIA HPC-Benchmarks 25.04: Ozaki-I HPL on blackwell tensor cores. NVIDIA Developer Documentation, 2025
2025
-
[26]
Unlocking tensor core performance with floating-point emulation in cuBLAS
NVIDIA Corporation. Unlocking tensor core performance with floating-point emulation in cuBLAS. NVIDIA Developer Blog, 2025
2025
-
[27]
Blue Lion supercomputer will run on NVIDIA Vera Rubin
NVIDIA Corporation. Blue Lion supercomputer will run on NVIDIA Vera Rubin. NVIDIA Blog, 2026
2026
-
[28]
Emulated DGEMM
NVIDIA Corporation. Inside the NVIDIA Vera Rubin platform: Six new chips, one AI supercomputer. NVIDIA Developer Blog, 2026. Lists “Emulated DGEMM” as an official column in Rubin specifications
2026
-
[29]
DGEMM on integer matrix multi- plication unit
Hiroyuki Ootomo, Katsuhisa Ozaki, and Rio Yokota. DGEMM on integer matrix multi- plication unit. The International Journal of High Performance Computing Applications, 2024
2024
-
[30]
Katsuhisa Ozaki, Takeshi Ogita, Shin’ichi Oishi, and Siegfried M. Rump. Error-free trans- formations of matrix multiplication by using fast routines of matrix multiplication and its applications.Numerical Algorithms, 59(1):95–118, 2012
2012
-
[31]
Ozaki Scheme II: A GEMM- oriented emulation of floating-point matrix multiplication using an integer modular tech- nique, 2025
Katsuhisa Ozaki, Yuki Uchino, and Toshiyuki Imamura. Ozaki Scheme II: A GEMM- oriented emulation of floating-point matrix multiplication using an integer modular tech- nique, 2025
2025
-
[32]
Error analysis of matrix multipli- cation emulation using Ozaki-II scheme, 2026
Katsuhisa Ozaki, Yuki Uchino, and Toshiyuki Imamura. Error analysis of matrix multipli- cation emulation using Ozaki-II scheme, 2026. Preprint
2026
-
[33]
A. Schwarz, A. Anders, C. Brower, H. Bayraktar, J. Gunnels, K. Clark, R. G. Xu, S. Ro- driguez, S. Cayrols, P. Tabaszewski, et al. Guaranteed DGEMM accuracy while using reduced precision tensor cores through extensions of the Ozaki scheme. InProceedings of the Supercomputing Asia and International Conference on High Performance Computing in Asia Pacific R...
-
[34]
The mixed-precision path to FP64 on AI-centric accelerators (MFP64 whitepaper)
Rick Stevens et al. The mixed-precision path to FP64 on AI-centric accelerators (MFP64 whitepaper). Technical report, U.S. Department of Energy, 2025
2025
-
[35]
GEMMul8: GEMM emulation using INT8/FP8 matrix engines based on the Ozaki Scheme II
Yuki Uchino. GEMMul8: GEMM emulation using INT8/FP8 matrix engines based on the Ozaki Scheme II. GitHub repository, RIKEN-RCCS, 2025
2025
-
[36]
Performance enhancement of the Ozaki scheme on integer matrix multiplication unit.The International Journal of High Performance Computing Applications, 2025
Yuki Uchino, Katsuhisa Ozaki, and Toshiyuki Imamura. Performance enhancement of the Ozaki scheme on integer matrix multiplication unit.The International Journal of High Performance Computing Applications, 2025
2025
-
[37]
Double-precision matrix multipli- cation emulation via Ozaki-II scheme with FP8 quantization, 2026
Yuki Uchino, Katsuhisa Ozaki, and Toshiyuki Imamura. Double-precision matrix multipli- cation emulation via Ozaki-II scheme with FP8 quantization, 2026
2026
-
[38]
Likun Wang et al. SparStencil: Retargeting sparse tensor cores to scientific stencil compu- tations via structured sparsity transformation. InProceedings of the International Confer- ence for High Performance Computing, Networking, Storage and Analysis (SC ’25), 2025. arXiv:2506.22969
-
[39]
Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
2009
-
[40]
NVIDIA says it’s not abandoning 64-bit computing
Alex Woodie. NVIDIA says it’s not abandoning 64-bit computing. HPCwire, December 2025
2025
-
[41]
AMD hints at big FP64 increases in MI430X GPU as Ozaki underwhelms
Alex Woodie. AMD hints at big FP64 increases in MI430X GPU as Ozaki underwhelms. HPCwire, March 2026
2026
-
[42]
stored” to “actual
Alex Woodie. Genesis mission will lean heavily on Ozaki scheme for FP64 capability. HPCwire, February 2026. A Garner’s Algorithm: Detailed Derivation Equation (7) is the iterative formulation of Garner’s algorithm. We expand it here for the case r= 3to make the dependence pattern explicit. LetC∈Zwith0≤C < m 1m2m3, and letC (i) =Cmodm i. We seek mixed-radi...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.