DxPTA: An Architecture Design Space Exploration with Optical Dataflow-guided Strategy for HW/SW Co-Design of Photonic Transformer Accelerators
Pith reviewed 2026-06-28 08:10 UTC · model grok-4.3
The pith
DxPTA identifies PTA architecture parameters from coherent optical dataflow, analyzes their impact, and uses the results to run a constraint-aware search that finds suitable designs for transformer models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By grounding PTA parameter selection in coherent optical dataflow analysis and then applying the resulting significance ranking inside a constraint-aware search procedure, DxPTA produces photonic transformer accelerator architectures that simultaneously satisfy area, power, energy, and latency bounds for multiple transformer models, and does so more than fifteen times faster than exhaustive enumeration.
What carries the argument
The constraint-aware architecture search algorithm that ranks and prunes PTA design choices according to the impact analysis derived from coherent optical dataflow.
If this is right
- PTA architectures can be generated automatically for any new transformer model once its workload characteristics are supplied.
- Design time for photonic accelerators shrinks from days of manual tuning to minutes of automated search.
- The same parameter-analysis step can be reused when additional constraints such as thermal limits or fabrication yield are added.
- Hardware/software partitioning decisions become repeatable across different transformer sizes rather than ad-hoc.
Where Pith is reading between the lines
- The same dataflow-guided ranking could be applied to other photonic linear-algebra accelerators beyond transformers.
- If the optical dataflow model is extended to include crosstalk or wavelength-dependent loss, the search could incorporate those effects without changing the overall procedure.
- The reported 15.2x speedup suggests that larger design spaces, such as those arising from multi-chip photonic systems, become searchable with modest compute.
Load-bearing premise
The impact and significance ranking of PTA architecture parameters obtained from coherent optical dataflow analysis is accurate enough that the search procedure will locate a valid design whenever one exists.
What would settle it
Run the exhaustive enumeration on the same design space and constraints; if it returns a design that satisfies all limits yet DxPTA misses it, the method fails.
Figures





read the original abstract
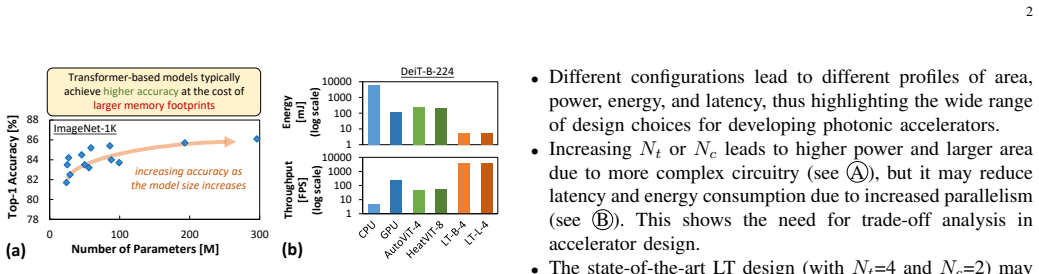
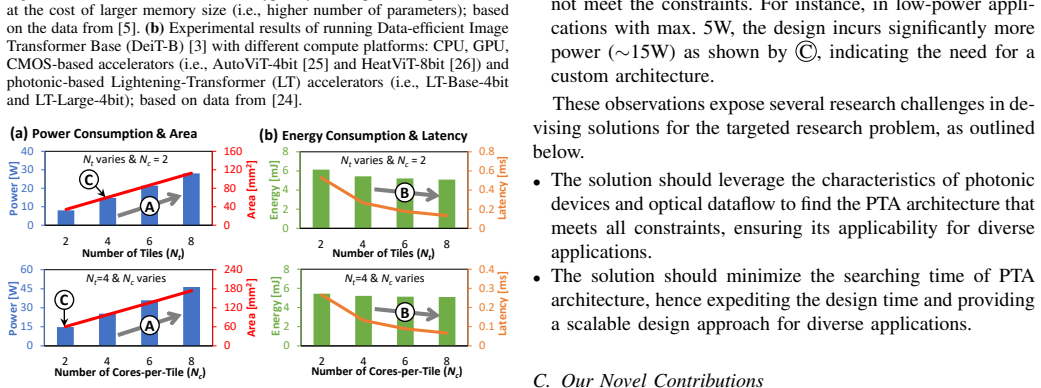
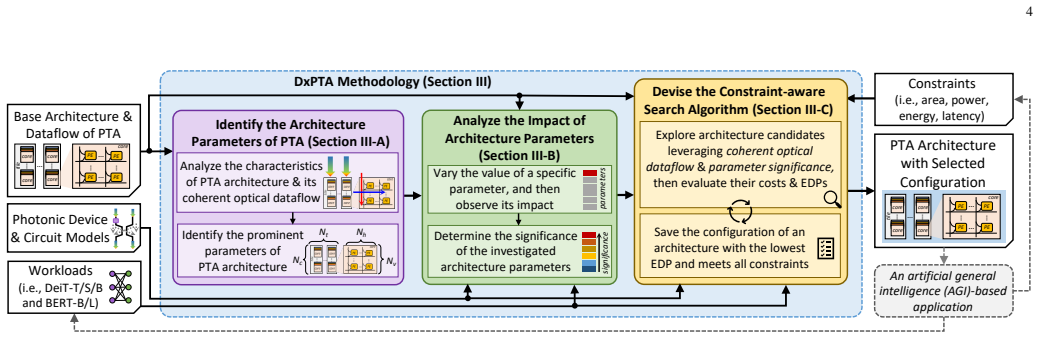
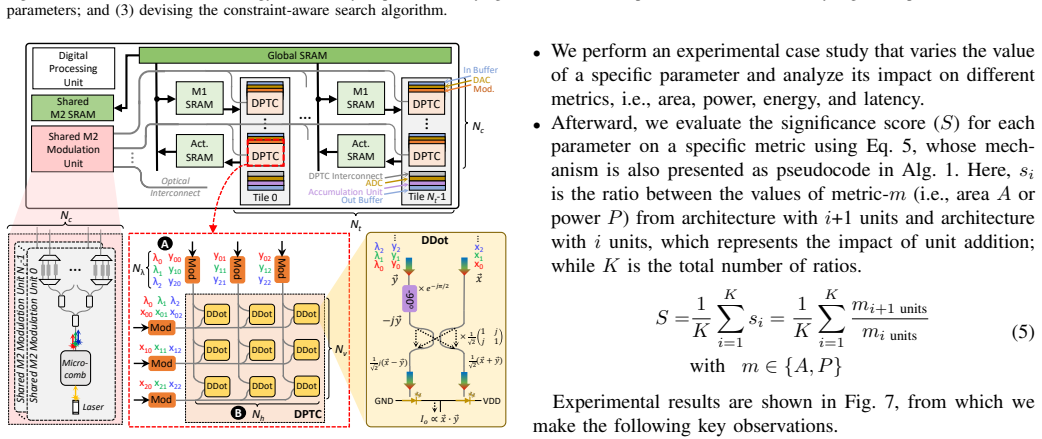
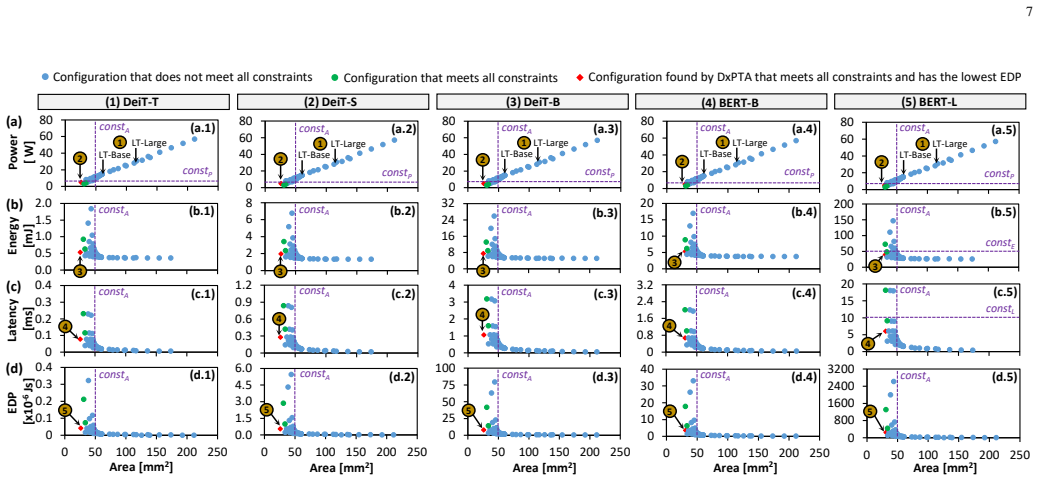
Transformer-based networks have emerged as prominent AI models with state-of-the-art performance, which potentially pave the way toward artificial general intelligence (AGI). However, their large sizes still hinder their efficient implementation, thus highlighting the need for alternate solutions to enable their energy-efficient acceleration. Recently, state-of-the-art works propose photonic transformer accelerators (PTAs) with significant speedup and energy efficiency improvements over the conventional electronic accelerators. However, their PTA architectures are developed without considering the application constraints (e.g., area, power, energy, and latency). Moreover, their manual design approach also requires huge design time to determine a suitable architecture for the targeted application, hence making this approach not scalable. To address these limitations, we propose DxPTA, a novel design space exploration methodology for enabling efficient hardware/software co-design of the appropriate PTA architecture that meets all constraints. It is achieved by (1) identifying the PTA architecture parameters based on the coherent optical dataflow; (2) analyzing the impact/significance of the parameters; and (3) leveraging this analysis for devising a constraint-aware architecture search algorithm. Experimental results show that, our DxPTA can find the appropriate PTA architectures for different transformer-based models (i.e., DeiT-T/S/B and BERT-B/L). It achieves up to 26mm^2 area, 4.8W power, 39mJ energy, and 6ms latency, for constraints of 50mm^2 area, 5W power, 50mJ energy, and 10ms latency; with 15.2x faster searching time than the exhaustive approach. These results demonstrate the potential of DxPTA methodology for enabling efficient PTA designs for diverse AGI-based applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DxPTA, a design space exploration (DSE) methodology for photonic transformer accelerators (PTAs) that identifies architecture parameters from coherent optical dataflow, analyzes their impact and significance, and uses this to construct a constraint-aware search algorithm for HW/SW co-design. It reports that the method finds suitable PTA architectures for DeiT-T/S/B and BERT-B/L models that satisfy area (≤50 mm²), power (≤5 W), energy (≤50 mJ), and latency (≤10 ms) constraints, achieving up to 26 mm², 4.8 W, 39 mJ, and 6 ms respectively, while providing 15.2× faster search than exhaustive enumeration.
Significance. If the parameter-impact analysis is shown to be complete and the derived search is proven to reliably locate feasible points without systematic omissions, the work would provide a scalable alternative to manual PTA design, directly addressing the scalability bottleneck for constraint-driven photonic accelerators targeting transformer models. The reported constraint satisfaction and search speedup would be a concrete contribution to HW/SW co-design in the photonic-accelerator literature.
major comments (3)
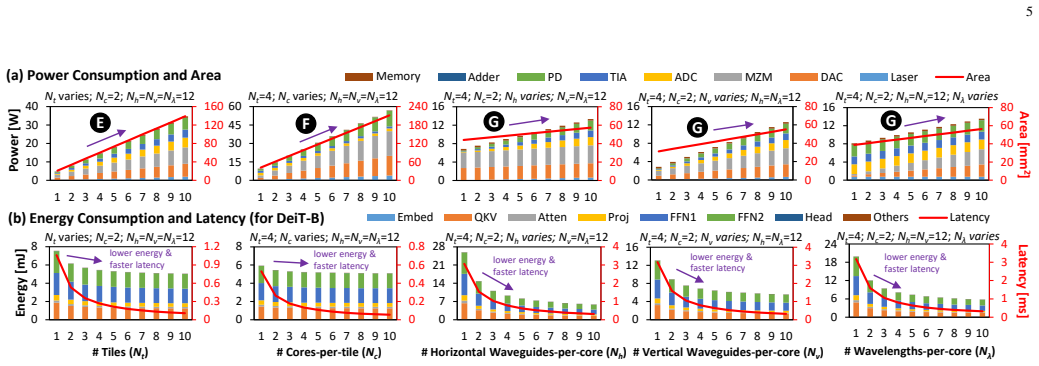
- [§3–4] §3–4 (Parameter identification and impact/significance analysis): The central claim that the optical-dataflow-guided analysis yields a search algorithm capable of reliably meeting all four constraints without overlooking superior designs rests on the assumption that first-order parameter impacts are sufficient; no evidence is provided that higher-order couplings (e.g., between waveguide count, modulator density, and thermal tuning across batch sizes) have been quantified or bounded, leaving open the possibility that the reported 26 mm² / 4.8 W / 39 mJ / 6 ms points are not the best feasible solutions.
- [§5] §5 (Constraint-aware search algorithm): The manuscript states that the search meets the stated bounds for the five evaluated models, yet provides no formal argument or exhaustive cross-check that every feasible architecture satisfying the four constraints is either found or provably dominated by the returned solution; the 15.2× speedup claim is therefore only relative to exhaustive search and does not establish optimality or completeness of the pruned space.
- [§6] §6 (Experimental results): Validation is limited to comparison against exhaustive search; no additional baselines (e.g., random search, Bayesian optimization, or prior PTA DSE methods) are reported, making it impossible to assess whether the observed speed/quality trade-off is competitive or merely an artifact of the chosen pruning heuristic.
minor comments (2)
- [§3] Notation for optical parameters (e.g., waveguide count, modulator density) should be introduced once with consistent symbols and units before being used in the impact tables.
- [§6] Figure captions for the search-time and constraint-satisfaction plots should explicitly state the number of evaluated architectures and the exact constraint vector used in each experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3–4] §3–4 (Parameter identification and impact/significance analysis): The central claim that the optical-dataflow-guided analysis yields a search algorithm capable of reliably meeting all four constraints without overlooking superior designs rests on the assumption that first-order parameter impacts are sufficient; no evidence is provided that higher-order couplings (e.g., between waveguide count, modulator density, and thermal tuning across batch sizes) have been quantified or bounded, leaving open the possibility that the reported 26 mm² / 4.8 W / 39 mJ / 6 ms points are not the best feasible solutions.
Authors: We acknowledge that §§3–4 focus on first-order impacts derived from coherent optical dataflow analysis. Higher-order couplings (e.g., waveguide-modulator-thermal interactions across batch sizes) were not quantified or bounded. We will add a limitations discussion in the revised manuscript noting this assumption and its implications, while retaining the empirical evidence that the identified architectures satisfy all constraints. revision: partial
-
Referee: [§5] §5 (Constraint-aware search algorithm): The manuscript states that the search meets the stated bounds for the five evaluated models, yet provides no formal argument or exhaustive cross-check that every feasible architecture satisfying the four constraints is either found or provably dominated by the returned solution; the 15.2× speedup claim is therefore only relative to exhaustive search and does not establish optimality or completeness of the pruned space.
Authors: DxPTA employs a heuristic search guided by the significance analysis; we make no claim of formal optimality or completeness. The 15.2× speedup is presented strictly relative to exhaustive enumeration. We will revise §5 to explicitly state the heuristic character and that feasible solutions are found in the evaluated cases without a guarantee of global optimality. revision: partial
-
Referee: [§6] §6 (Experimental results): Validation is limited to comparison against exhaustive search; no additional baselines (e.g., random search, Bayesian optimization, or prior PTA DSE methods) are reported, making it impossible to assess whether the observed speed/quality trade-off is competitive or merely an artifact of the chosen pruning heuristic.
Authors: We agree that additional baselines are needed for a stronger evaluation. We will extend §6 with comparisons to random search and Bayesian optimization under identical constraints and design space to demonstrate the relative effectiveness of the dataflow-guided pruning. revision: yes
Circularity Check
No significant circularity detected in DxPTA derivation
full rationale
The paper presents a three-step methodology: (1) identify PTA architecture parameters from coherent optical dataflow, (2) analyze parameter impact/significance, and (3) leverage the analysis for a constraint-aware search algorithm. No equations, fitted parameters, or self-citations are described that reduce by construction to the inputs (e.g., no self-definitional loops where a prediction is the fit itself, no uniqueness theorems imported from prior author work, and no ansatz smuggled via citation). The reported results (architectures meeting area/power/energy/latency bounds for DeiT/BERT models) are outcomes of the search process rather than tautological renamings or forced predictions. This is a standard empirical DSE flow whose central claims remain independent of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coherent optical dataflow provides a reliable basis for determining the significance of architecture parameters in PTAs
Reference graph
Works this paper leans on
-
[1]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez et al., “Attention is all you need,”Advances in Neural Information Processing Systems (NIPS), vol. 30, no. 1, pp. 261–272, 2017. 0.01 0.1 1 10 100 DeiT-T DeiT-S DeiT-B BERT-B BERT-L Search Time Normalized to Exhaustive DeiT-T (log scale) Exhaustive DxPTA faster faster faster faster fas...
2017
-
[2]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[3]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,” inInternational Conference on Machine Learning (ICML). PMLR, 2021, pp. 10 347–10 357
2021
-
[4]
Transformers in vision: A survey,
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,”ACM Computing Surveys (CSUR), vol. 54, no. 10s, pp. 1–41, 2022
2022
-
[5]
A survey on vision transformer,
K. Han, Y . Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y . Tang, A. Xiao, C. Xu, Y . Xu, Z. Yang, Y . Zhang, and D. Tao, “A survey on vision transformer,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 45, no. 1, pp. 87–110, 2023
2023
-
[6]
A. Mumuni and F. Mumuni, “Large language models for artificial general intelligence (agi): A survey of foundational principles and approaches,”arXiv preprint arXiv:2501.03151, 2025
-
[7]
Artificial general intelligence: Advancements, challenges, and future directions in agi research,
G. Yenduri, R. Murugan, P. Kumar Reddy Maddikunta, S. Bhattacharya, D. Sudheer, and B. Bhushan Savarala, “Artificial general intelligence: Advancements, challenges, and future directions in agi research,”IEEE Access, vol. 13, pp. 134 325–134 356, 2025
2025
-
[8]
Hardware accelerator for multi-head attention and position-wise feed-forward in the trans- former,
S. Lu, M. Wang, S. Liang, J. Lin, and Z. Wang, “Hardware accelerator for multi-head attention and position-wise feed-forward in the trans- former,” in2020 IEEE 33rd International System-on-Chip Conference (SOCC). IEEE, 2020, pp. 84–89
2020
-
[9]
Accelerating framework of transformer by hardware design and model compression co-optimization,
P. Qi, E. H.-M. Sha, Q. Zhuge, H. Peng, S. Huang, Z. Kong, Y . Song, and B. Li, “Accelerating framework of transformer by hardware design and model compression co-optimization,” in2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), 2021, pp. 1–9
2021
-
[10]
Spatten: Efficient sparse attention architecture with cascade token and head pruning,
H. Wang, Z. Zhang, and S. Han, “Spatten: Efficient sparse attention architecture with cascade token and head pruning,” in2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2021, pp. 97–110
2021
-
[11]
Vaqf: Fully automatic software-hardware co-design frame- work for low-bit vision transformer,
M. Sun, H. Ma, G. Kang, Y . Jiang, T. Chen, X. Ma, Z. Wang, and Y . Wang, “Vaqf: Fully automatic software-hardware co-design frame- work for low-bit vision transformer,”arXiv preprint arXiv:2201.06618, 2022. 8
-
[12]
Transpim: A memory- based acceleration via software-hardware co-design for transformer,
M. Zhou, W. Xu, J. Kang, and T. Rosing, “Transpim: A memory- based acceleration via software-hardware co-design for transformer,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2022, pp. 1071–1085
2022
-
[13]
Tpu v4: An optically reconfigurable supercom- puter for machine learning with hardware support for embeddings,
N. Jouppi, G. Kurian, S. Li, P. Ma, R. Nagarajan, L. Nai, N. Patil, S. Subramanian, A. Swing, B. Towles, C. Young, X. Zhou, Z. Zhou, and D. A. Patterson, “Tpu v4: An optically reconfigurable supercom- puter for machine learning with hardware support for embeddings,” in Proceedings of the 50th Annual International Symposium on Computer Architecture (ISCA), 2023
2023
-
[14]
Vitcod: Vision transformer acceleration via dedicated algorithm and accelerator co-design,
H. You, Z. Sun, H. Shi, Z. Yu, Y . Zhao, Y . Zhang, C. Li, B. Li, and Y . Lin, “Vitcod: Vision transformer acceleration via dedicated algorithm and accelerator co-design,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2023, pp. 273–286
2023
-
[15]
A survey on silicon photonics for deep learning,
F. P. Sunny, E. Taheri, M. Nikdast, and S. Pasricha, “A survey on silicon photonics for deep learning,”ACM Journal of Emerging Technologies in Computing System (JETC), vol. 17, no. 4, pp. 1–57, 2021
2021
-
[16]
Albireo: Energy- efficient acceleration of convolutional neural networks via silicon pho- tonics,
K. Shiflett, A. Karanth, R. Bunescu, and A. Louri, “Albireo: Energy- efficient acceleration of convolutional neural networks via silicon pho- tonics,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 860–873
2021
-
[17]
Photonics for artificial intelligence and neuromorphic computing,
B. J. Shastri, A. N. Tait, T. Ferreira de Lima, W. H. Pernice, H. Bhaskaran, C. D. Wright, and P. R. Prucnal, “Photonics for artificial intelligence and neuromorphic computing,”Nature Photonics, vol. 15, no. 2, pp. 102–114, 2021
2021
-
[18]
Light in ai: toward efficient neurocomputing with optical neural networks—a tutorial,
J. Gu, C. Feng, H. Zhu, R. T. Chen, and D. Z. Pan, “Light in ai: toward efficient neurocomputing with optical neural networks—a tutorial,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 69, no. 6, pp. 2581–2585, 2022
2022
-
[19]
Simphony: A device-circuit-architecture cross-layer modeling and simulation frame- work for heterogeneous electronic-photonic ai system,
Z. Yin, M. Zhang, N. Gangi, R. Huang, J. Zhang, and J. Gu, “Simphony: A device-circuit-architecture cross-layer modeling and simulation frame- work for heterogeneous electronic-photonic ai system,” in2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 2025, pp. 1–7
2025
-
[20]
Deep learning with coherent nanophotonic circuits,
Y . Shen, N. C. Harris, S. Skirlo, M. Prabhu, T. Baehr-Jones, M. Hochberg, X. Sun, S. Zhao, H. Larochelle, D. Englundet al., “Deep learning with coherent nanophotonic circuits,”Nature photonics, vol. 11, no. 7, pp. 441–446, 2017
2017
-
[21]
Neuromorphic photonic networks using silicon photonic weight banks,
A. N. Tait, T. F. De Lima, E. Zhou, A. X. Wu, M. A. Nahmias, B. J. Shastri, and P. R. Prucnal, “Neuromorphic photonic networks using silicon photonic weight banks,”Scientific Reports, vol. 7, no. 1, p. 7430, 2017
2017
-
[22]
Crosslight: A cross- layer optimized silicon photonic neural network accelerator,
F. Sunny, A. Mirza, M. Nikdast, and S. Pasricha, “Crosslight: A cross- layer optimized silicon photonic neural network accelerator,” in2021 58th ACM/IEEE design automation conference (DAC). IEEE, 2021, pp. 1069–1074
2021
-
[23]
Parallel convolutional processing using an integrated photonic tensor core,
J. Feldmann, N. Youngblood, M. Karpov, H. Gehring, X. Li, M. Stap- pers, M. Le Gallo, X. Fu, A. Lukashchuk, A. S. Rajaet al., “Parallel convolutional processing using an integrated photonic tensor core,” Nature, vol. 589, no. 7840, pp. 52–58, 2021
2021
-
[24]
Lightening-transformer: A dynamically- operated optically-interconnected photonic transformer accelerator,
H. Zhu, J. Gu, H. Wang, Z. Jiang, Z. Zhang, R. Tang, C. Feng, S. Han, R. T. Chen, and D. Z. Pan, “Lightening-transformer: A dynamically- operated optically-interconnected photonic transformer accelerator,” in 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2024, pp. 686–703
2024
-
[25]
Auto-vit-acc: An fpga-aware automatic acceleration framework for vision transformer with mixed-scheme quantization,
Z. Li, M. Sun, A. Lu, H. Ma, G. Yuan, Y . Xie, H. Tang, Y . Li, M. Leeser, Z. Wanget al., “Auto-vit-acc: An fpga-aware automatic acceleration framework for vision transformer with mixed-scheme quantization,” in 2022 32nd International Conference on Field-Programmable Logic and Applications (FPL). IEEE, 2022, pp. 109–116
2022
-
[26]
Heatvit: Hardware-efficient adaptive token pruning for vision transformers,
P. Dong, M. Sun, A. Lu, Y . Xie, K. Liu, Z. Kong, X. Meng, Z. Li, X. Lin, Z. Fang, and Y . Wang, “Heatvit: Hardware-efficient adaptive token pruning for vision transformers,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2023, pp. 442–455
2023
-
[27]
Sprint: A high-performance, energy- efficient, and scalable chiplet-based accelerator with photonic intercon- nects for cnn inference,
Y . Li, A. Louri, and A. Karanth, “Sprint: A high-performance, energy- efficient, and scalable chiplet-based accelerator with photonic intercon- nects for cnn inference,”IEEE Transactions on Parallel and Distributed Systems (TPDS), vol. 33, no. 10, pp. 2332–2345, 2022
2022
-
[28]
Spacx: Silicon photonics-based scalable chiplet accelerator for dnn inference,
——, “Spacx: Silicon photonics-based scalable chiplet accelerator for dnn inference,” in2022 IEEE International Symposium on High- Performance Computer Architecture (HPCA), 2022, pp. 831–845
2022
-
[29]
Tron: Transformer neural network acceleration with non-coherent silicon photonics,
S. Afifi, F. Sunny, M. Nikdast, and S. Pasricha, “Tron: Transformer neural network acceleration with non-coherent silicon photonics,” in Great Lakes Symposium on VLSI (GSVLSI) 2023, 2023, pp. 15–21
2023
-
[30]
A light-speed large language model accelerator with optical stochastic computing,
S. Afifi, O. Alo, I. Thakkar, and S. Pasricha, “A light-speed large language model accelerator with optical stochastic computing,” inGreat Lakes Symposium on VLSI (GLSVLSI) 2025, 2025, pp. 922–928
2025
-
[31]
Astra: A stochastic transformer neural network accelerator with silicon photonics,
——, “Astra: A stochastic transformer neural network accelerator with silicon photonics,”ACM Transactions on Embedded Computing Systems (TECS), 2025
2025
-
[32]
Merit: A sustainable dnn accelerator design with photonic phase-change memory,
Y . Li, A. Louri, and A. Karanth, “Merit: A sustainable dnn accelerator design with photonic phase-change memory,”IEEE Transactions on Sustainable Computing (TSUSC), vol. 10, no. 4, pp. 705–716, 2025
2025
-
[33]
Hyatten: Hybrid photonic-digital architec- ture for accelerating attention mechanism,
H. Li, D. Chen, and T. Mitra, “Hyatten: Hybrid photonic-digital architec- ture for accelerating attention mechanism,” in2025 Design, Automation & Test in Europe Conference (DATE), 2025, pp. 1–7
2025
-
[34]
P-dac: Power-efficient photonic accelerators for llm inference,
W.-T. Chang, C.-F. Wu, and Y .-C. Lo, “P-dac: Power-efficient photonic accelerators for llm inference,” in2025 62nd ACM/IEEE Design Au- tomation Conference (DAC), 2025, pp. 1–7
2025
-
[35]
En- lighten: Lighten the transformer, enable efficient optical acceleration,
H. Zhu, Z. Zhou, S. Ning, X. Wu, R. Chen, Y . Wan, and D. Pan, “En- lighten: Lighten the transformer, enable efficient optical acceleration,” arXiv preprint arXiv:2510.01673, 2025
-
[36]
Drmap: A generic dram data mapping policy for energy-efficient processing of convolu- tional neural networks,
R. V . W. Putra, M. A. Hanif, and M. Shafique, “Drmap: A generic dram data mapping policy for energy-efficient processing of convolu- tional neural networks,” in2020 57th ACM/IEEE Design Automation Conference (DAC), 2020, pp. 1–6
2020
-
[37]
Romanet: Fine-grained reuse-driven off-chip memory access management and data organization for deep neural network acceler- ators,
——, “Romanet: Fine-grained reuse-driven off-chip memory access management and data organization for deep neural network acceler- ators,”IEEE Transactions on Very Large Scale Integration Systems (TVLSI), vol. 29, no. 4, pp. 702–715, 2021
2021
-
[38]
——, “Pendram: Enabling high-performance and energy-efficient pro- cessing of deep neural networks through a generalized dram data mapping policy,”arXiv preprint arXiv:2408.02412, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.