AEGIS: A Backup Reflex for Physical AI
Pith reviewed 2026-06-28 00:52 UTC · model grok-4.3
The pith
A selective escalation method using activation probes on weak robot policies recovers 10.1% of lost trajectories by switching to stronger policies only at flagged high-risk steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
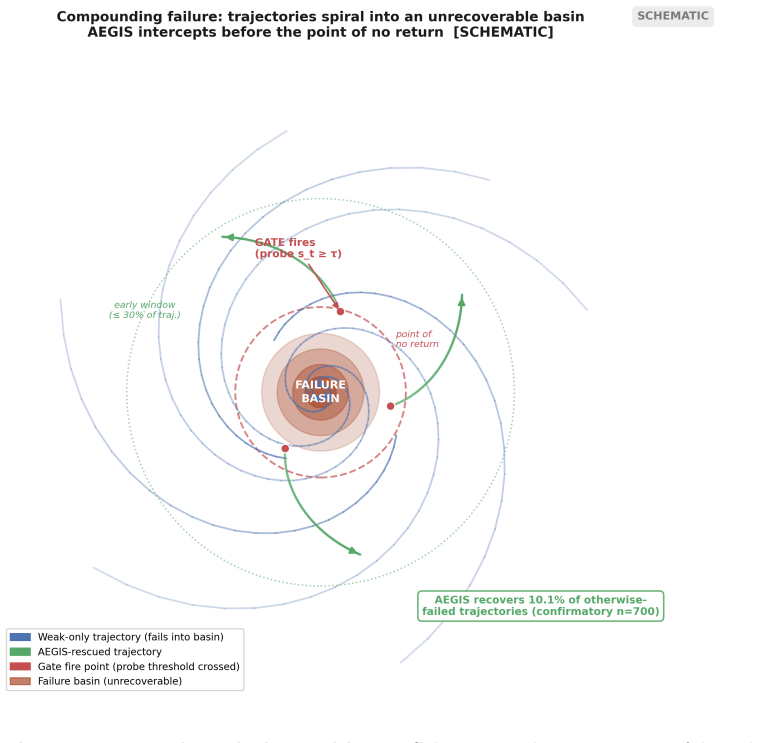
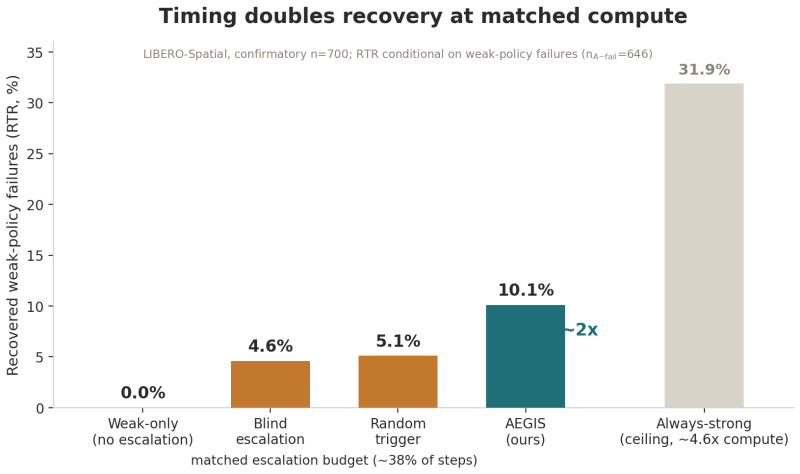
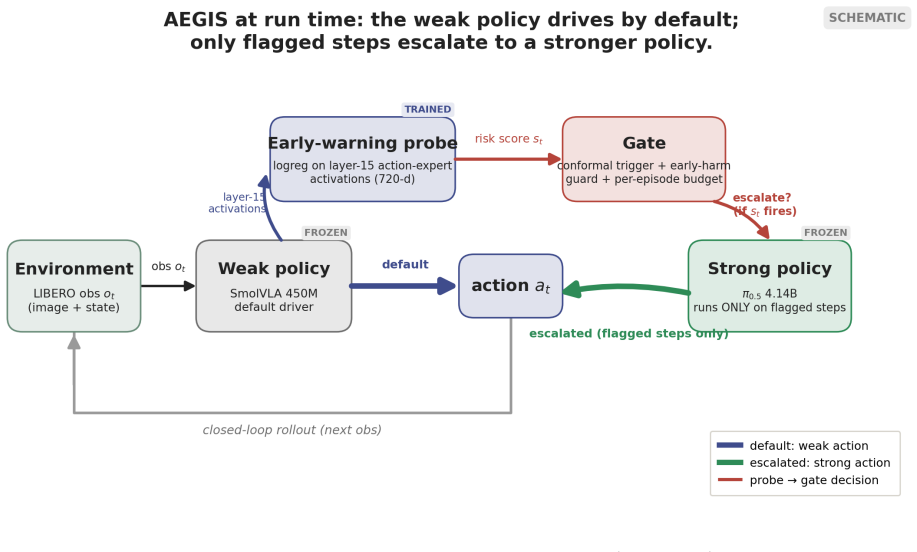
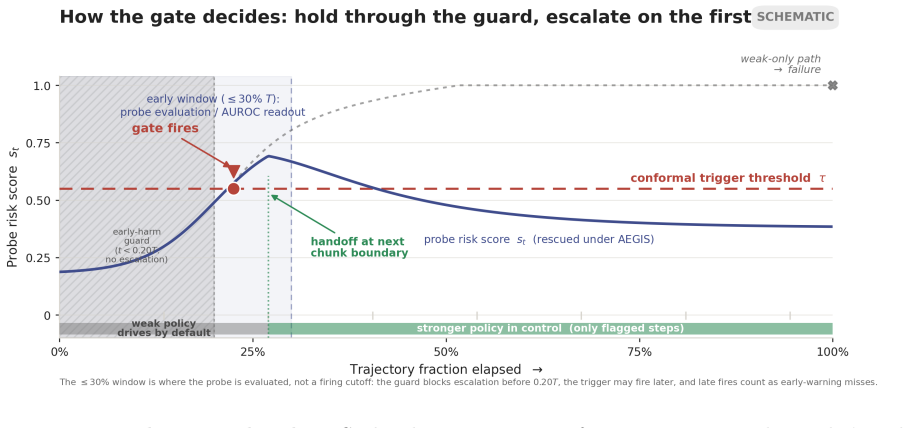
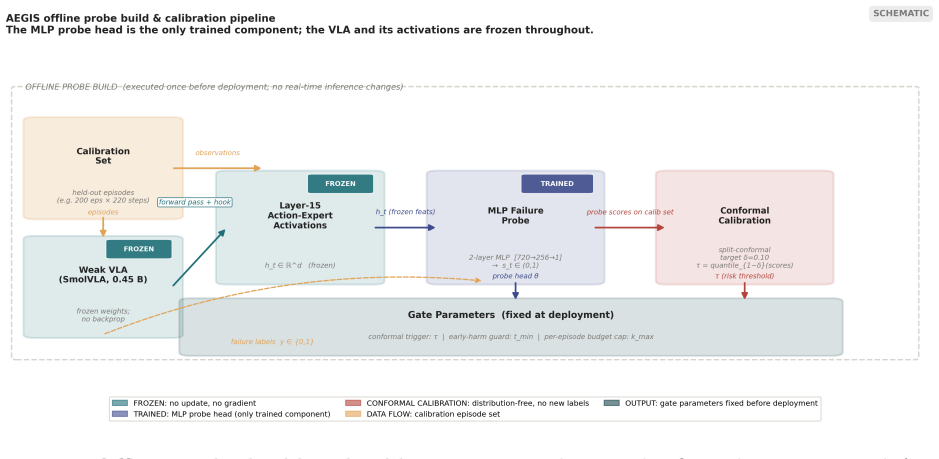
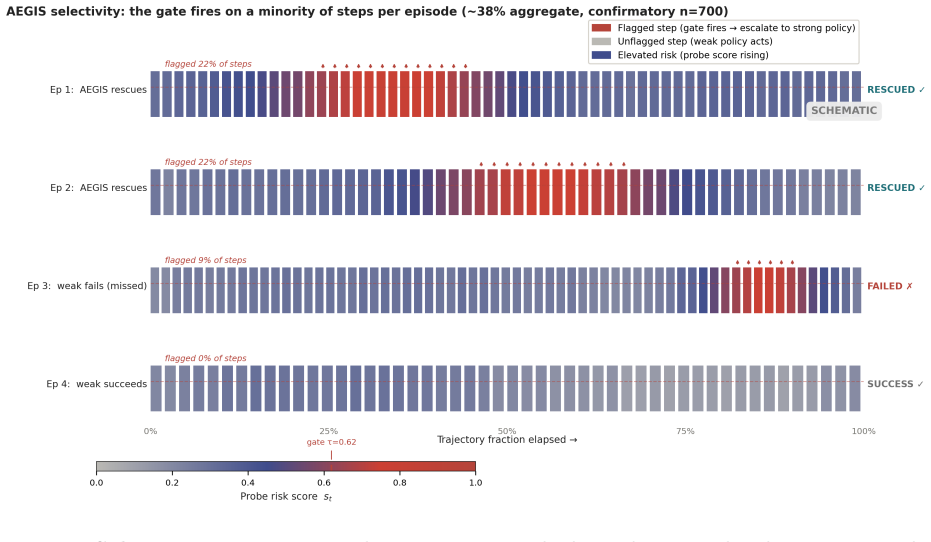
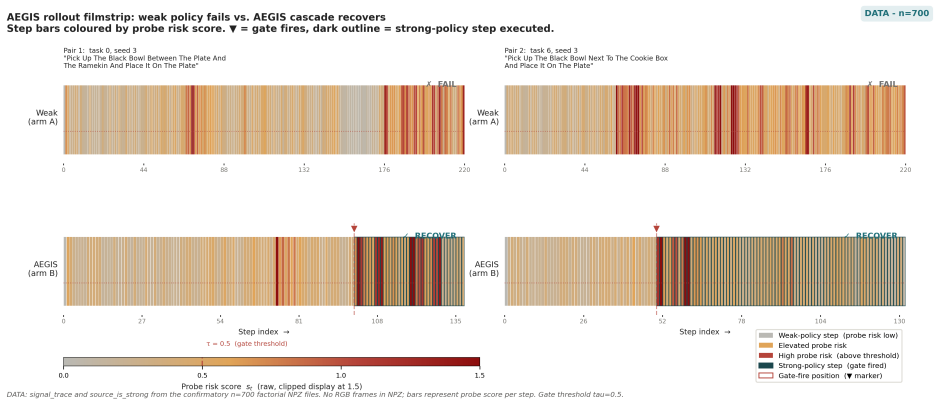
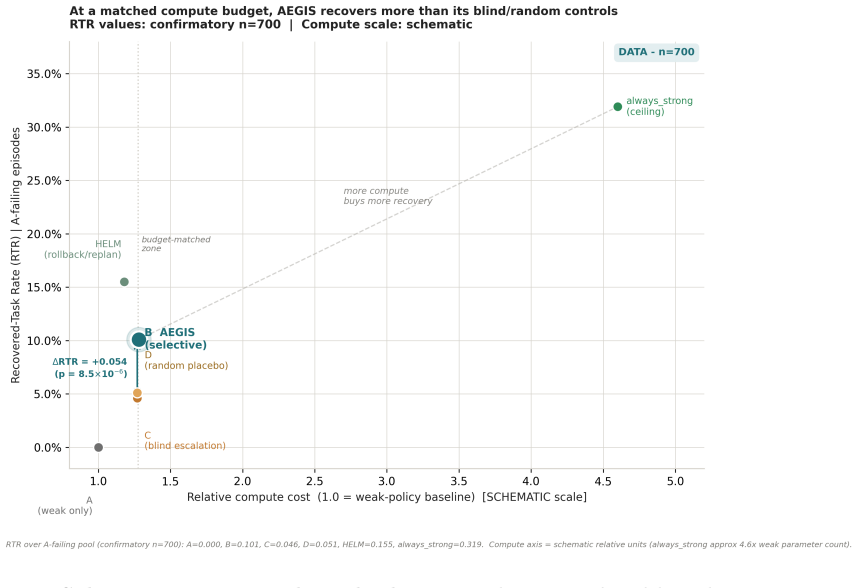
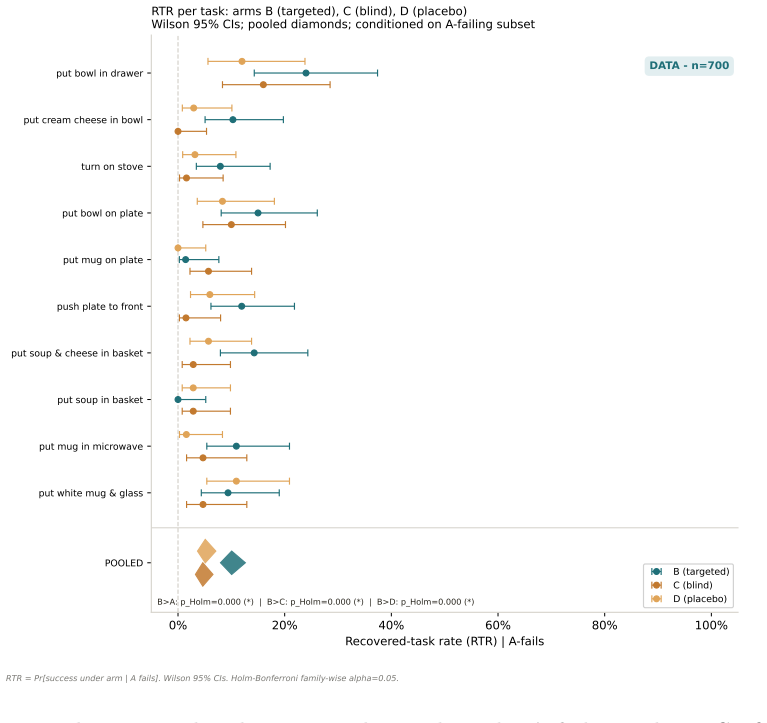
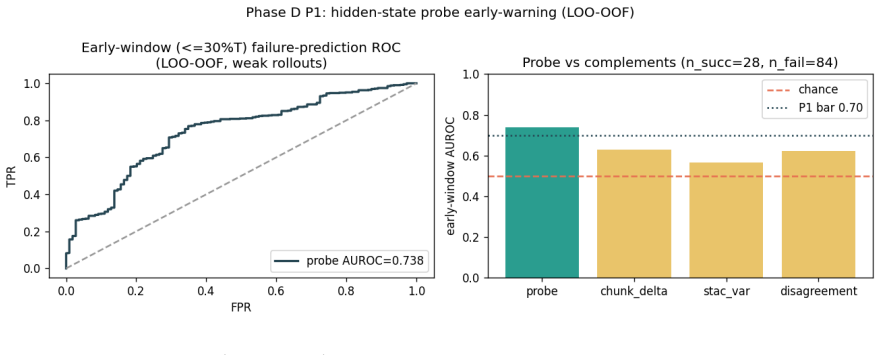
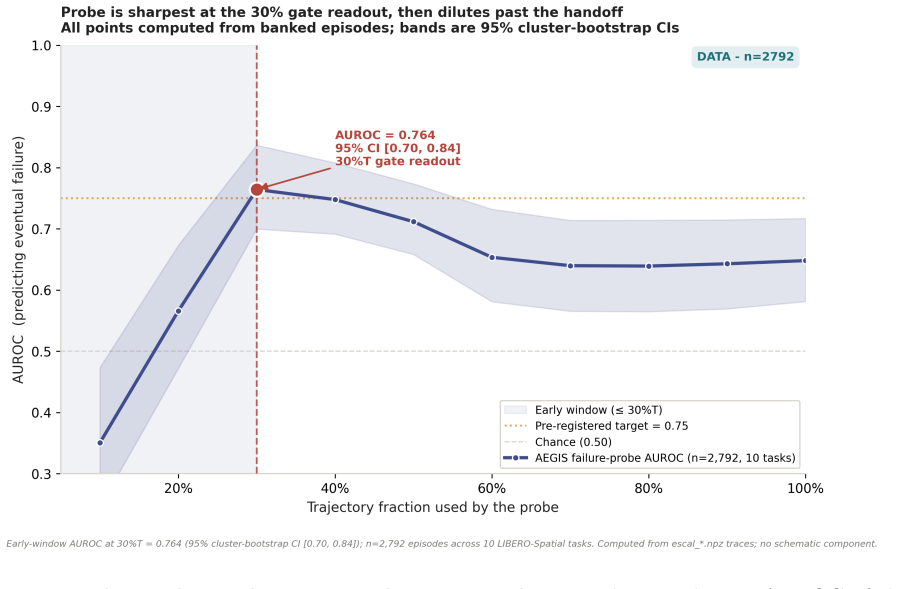
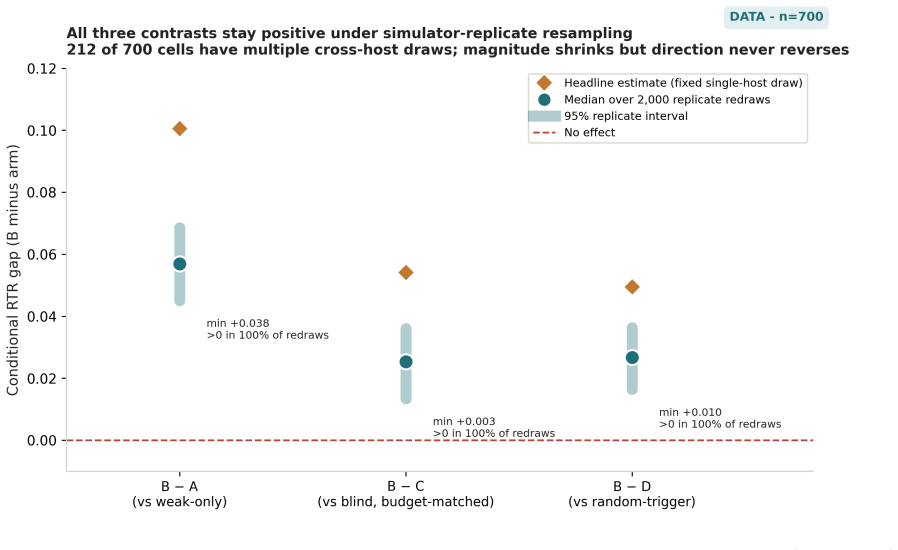
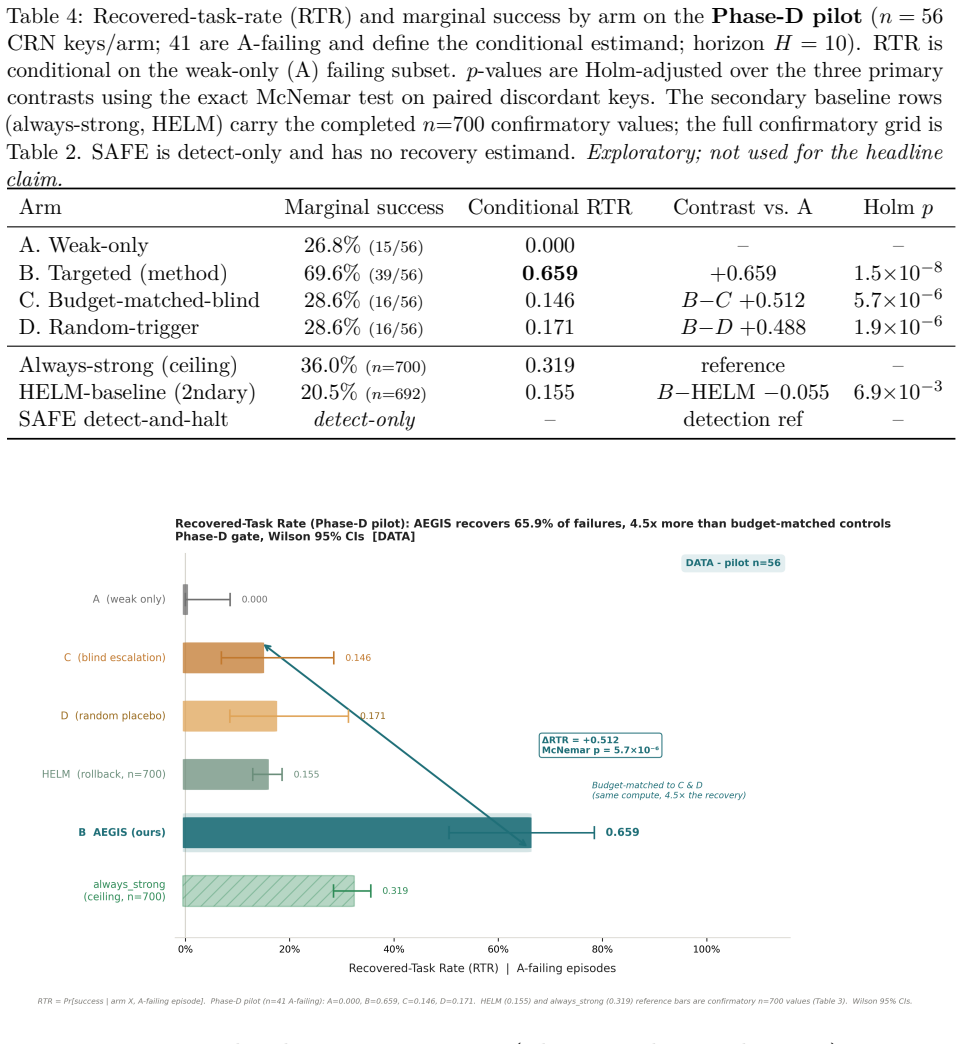
AEGIS (Activation-probe Early-warning, Gated Inference Switching) places a probe on the activations of a frozen weak policy to detect high-risk steps with usable lead time and gates inference switching to a stronger separate policy only on those steps. On LIBERO-Spatial the method recovers 10.1 percent of trajectories the weak policy loses, versus 4.6 percent for budget-matched blind escalation and 5.1 percent for a random-trigger placebo, with significance under one-sided exact paired McNemar tests (Holm-Bonferroni adjusted) and an early-window AUROC of 0.764 read from the first 30 percent of steps.
What carries the argument
The activation probe on frozen weak-policy activations that flags high-risk steps to gate selective handoff to a stronger policy.
If this is right
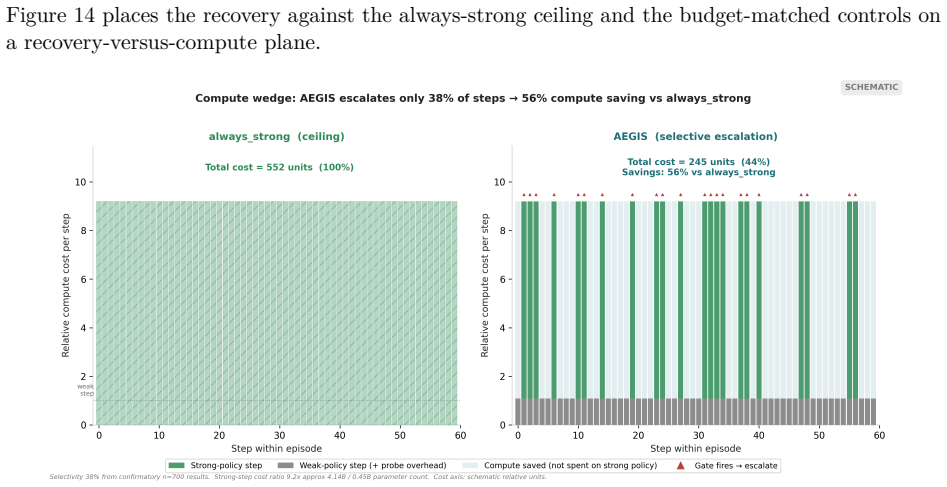
- The stronger policy need run on only 38 percent of steps, so the performance gain comes from timing rather than total compute.
- No retraining of either base policy is required; only the probe is trained on activation data from the weak policy.
- The conditional recovered-task-rate estimand isolates the benefit of timely handoff from overall policy strength.
- The method preserves the weak policy's behavior on the majority of steps while protecting against the subset that would otherwise cause irrecoverable failure.
Where Pith is reading between the lines
- If the probe transfers across robot embodiments or task distributions, AEGIS could function as a modular safety reflex for any base policy.
- The same early-warning idea might extend to non-robot domains where model outputs degrade gradually, such as long-horizon planning sequences.
- Replacing the fixed stronger policy with a family of increasingly capable models could allow graduated escalation based on probe score.
Load-bearing premise
The probe can detect high-risk steps with enough lead time for the stronger policy to intervene before the state becomes irrecoverable.
What would settle it
A replication in which the probe's early-window AUROC on the first 30 percent of steps falls below 0.65 and the paired recovery-rate difference versus blind escalation loses significance under the pre-registered McNemar tests.
Figures
read the original abstract
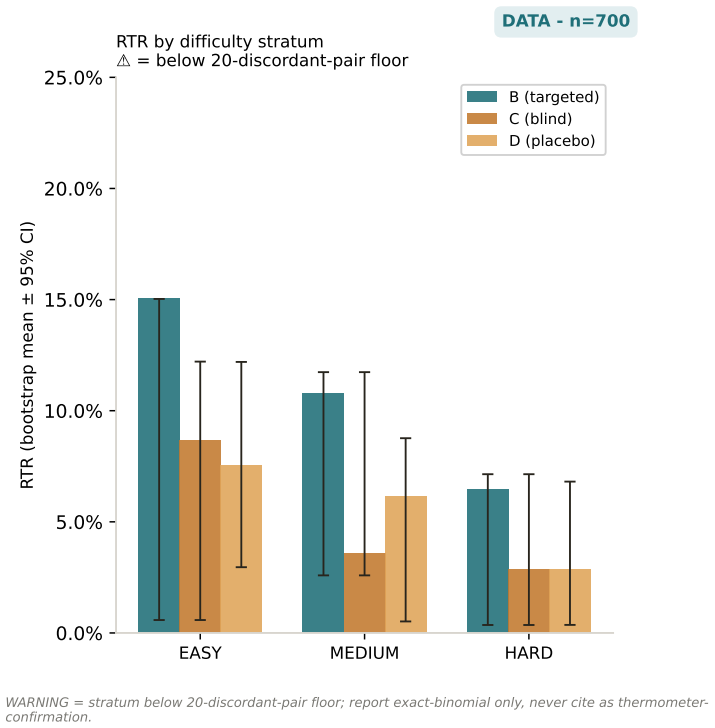
Long-horizon robot manipulation tends to fail gradually: one bad step degrades the state, and the policy spirals into a basin from which it cannot recover. The failure is often visible before it happens. We introduce AEGIS (Activation-probe Early-warning, Gated Inference Switching), a selective escalation method that uses a lightweight probe on a weak policy's frozen activations to detect high-risk steps while there is still time to act. When the probe flags a step, control switches to a stronger separate policy, but only for the steps that need it. On LIBERO-Spatial, AEGIS recovers 10.1% of the trajectories the weak policy alone loses, versus 4.6% for budget-matched blind escalation and 5.1% for a random-trigger placebo. These gains are significant under one-sided exact paired McNemar tests with Holm-Bonferroni adjustment over three pre-registered contrasts: +5.4pp over blind escalation, p=8.5e-6; +5.0pp over random triggering, p=1.0e-4; paired-trajectory bootstrap CIs exclude zero. AEGIS activates the stronger policy on only 38% of steps, so the lever is timing rather than compute. The probe clears its precondition with an early-window AUROC of 0.764, 95% CI [0.70, 0.84], read from the weak-policy path over the first 30% of trajectory steps before any handoff. We pre-register the full analysis plan, including a conditional recovered-task-rate estimand and explicit kill criteria, and confirm the result on 700 common-random-number episodes per arm, with nA-fail=646.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AEGIS, a selective escalation method for long-horizon robot manipulation that deploys a lightweight probe on the frozen activations of a weak policy to detect high-risk steps and switch control to a stronger policy only when needed. On LIBERO-Spatial it reports recovering 10.1% of trajectories lost by the weak policy (versus 4.6% for budget-matched blind escalation and 5.1% for a random-trigger placebo), with the differences declared significant under one-sided exact paired McNemar tests (Holm-Bonferroni adjusted) and paired-trajectory bootstrap CIs that exclude zero; the probe activates on 38% of steps and achieves an early-window AUROC of 0.764 on the first 30% of weak-policy trajectory steps.
Significance. If the reported recovery rates and statistical controls hold, the work supplies concrete evidence that timing-based selective escalation can improve reliability of physical AI systems without incurring the full cost of the stronger policy on every step. The pre-registered analysis plan, exact paired tests, explicit placebo and budget-matched controls, and bootstrap CIs are positive features that raise the evidentiary bar for the empirical claim.
major comments (1)
- [Methods] Methods section: the manuscript does not supply the training procedure for the activation probe, the weak and strong policies, the data splits, or the raw episode logs; without these details it is impossible to verify the pre-registered separation between probe training and evaluation or the absence of post-hoc exclusions, directly undermining confidence in the reported McNemar p-values and recovered-task-rate estimand.
minor comments (1)
- [Abstract] Abstract: the notation 'nA-fail=646' is not defined; it should be expanded to 'number of episodes in which the weak policy fails' for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater methodological transparency. We agree that the current manuscript is insufficiently detailed on these points and will revise accordingly to support verification of the pre-registered analysis.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript does not supply the training procedure for the activation probe, the weak and strong policies, the data splits, or the raw episode logs; without these details it is impossible to verify the pre-registered separation between probe training and evaluation or the absence of post-hoc exclusions, directly undermining confidence in the reported McNemar p-values and recovered-task-rate estimand.
Authors: We accept the criticism. The revised manuscript will add a dedicated subsection detailing (i) the exact training procedure, loss, optimizer, and hyperparameters for the activation probe, (ii) the training regimes and checkpoints for the weak and strong policies, (iii) the train/validation/test splits with explicit confirmation that probe training data were strictly separated from evaluation episodes, and (iv) the pre-registration identifier together with a statement that the registered analysis plan was followed without post-hoc exclusions. Raw episode logs (state, actions, probe scores, and success flags) will be deposited in a public repository with a DOI and linked in the paper. These additions will allow independent verification of the McNemar tests and the conditional recovered-task-rate estimand. revision: yes
Circularity Check
No circularity: purely empirical benchmark results with no derivations
full rationale
The paper reports direct empirical measurements of recovery rates, AUROC, and statistical tests on the fixed LIBERO-Spatial benchmark using pre-registered analysis, controls, and 700 episodes per arm. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains are present or load-bearing. The central claims are falsifiable experimental outcomes, not reductions to inputs by construction. This matches the default expectation of no significant circularity for an empirical methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying the McNemar test and paired bootstrap confidence intervals hold for the trajectory-level comparisons
Reference graph
Works this paper leans on
-
[1]
Unpacking Failure Modes of Generative Policies: Runtime Monitoring of Consistency and Progress, 2024
Christopher Agia, Rohan Sinha, Jingyun Yang, Zi-ang Cao, Rika Antonova, Marco Pavone, and Jeannette Bohg. Unpacking Failure Modes of Generative Policies: Runtime Monitoring of Consistency and Progress, 2024. URLhttps://arxiv.org/abs/2410.04640
arXiv 2024
-
[2]
Understanding Intermediate Layers Using Linear Classifier Probes, 2016
Guillaume Alain and Yoshua Bengio. Understanding Intermediate Layers Using Linear Classifier Probes, 2016. URLhttps://arxiv.org/abs/1610.01644
Pith/arXiv arXiv 2016
-
[3]
Angelopoulos and Stephen Bates
Anastasios N. Angelopoulos and Stephen Bates. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification, 2021. URLhttps://arxiv.org/abs/2107. 07511
2021
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A Visio...
Pith/arXiv arXiv 2024
-
[5]
RynnVLA-002: A Unified Vision-Language-Action and World Model, 2025
Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. RynnVLA-002: A Unified Vision-Language-Action and World Model, 2025. URLhttps://arxiv.org/abs/2511.17502
Pith/arXiv arXiv 2025
-
[6]
AURA: Action-Gated Memory for Robot Policies at Constant VRAM, 2026
Josef Chen. AURA: Action-Gated Memory for Robot Policies at Constant VRAM, 2026. URL https://arxiv.org/abs/2606.02775
Pith/arXiv arXiv 2026
-
[7]
Memory-Bound but Not Bandwidth-Limited: The Physical AI Inference Gap in Batch-1 LLM Decode, 2026
Josef Chen. Memory-Bound but Not Bandwidth-Limited: The Physical AI Inference Gap in Batch-1 LLM Decode, 2026. URLhttps://arxiv.org/abs/2605.30571
Pith/arXiv arXiv 2026
-
[8]
Lingling Chen, Zongyao Lyu, and William J. Beksi. ReconVLA: An Uncertainty-Guided and Failure-Aware Vision-Language-Action Framework for Robotic Control, 2026. URLhttps: //arxiv.org/abs/2604.16677
Pith/arXiv arXiv 2026
-
[9]
Tibshirani.An Introduction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman and Hall/CRC, New York, 1993. URLhttps://doi.org/10.1201/9780429246593
-
[10]
Johannes A. Gaus, Jhon P.F. Charaja, and Daniel Haeufle. Confidence-Gated Robot Autonomy: When Does Uncertainty Actually Help?, 2026. URLhttps://arxiv.org/abs/2605.18045
Pith/arXiv arXiv 2026
-
[11]
SAFE: Multitask Failure Detection for Vision-Language-Action Models,
Qiao Gu, Yuanliang Ju, Shengxiang Sun, Igor Gilitschenski, Haruki Nishimura, Masha Itkina, and Florian Shkurti. SAFE: Multitask Failure Detection for Vision-Language-Action Models,
-
[12]
URLhttps://arxiv.org/abs/2506.09937
-
[13]
Sture Holm. A Simple Sequentially Rejective Multiple Test Procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979. URLhttps://www.jstor.org/stable/4615733
arXiv 1979
-
[14]
Ulas Berk Karli, Ziyao Shangguan, and Tesca Fitzgerald. INSIGHT: INference-time Sequence Introspection for Generating Help Triggers in Vision-Language-Action Models, 2025. URL https://arxiv.org/abs/2510.01389
Pith/arXiv arXiv 2025
-
[15]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success, 2025
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success, 2025. URLhttps://arxiv.org/abs/2502.19645. 28
Pith/arXiv arXiv 2025
-
[16]
Huanyu Li, Kun Lei, Sheng Zang, Kaizhe Hu, Yongyuan Liang, Bo An, Xiaoli Li, and Huazhe Xu. Failure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation, 2026. URLhttps://arxiv.org/abs/2601.07821
arXiv 2026
-
[17]
FailSafe: Reasoning and Recovery from Failures in Vision-Language-Action Models, 2025
Zijun Lin, Jiafei Duan, Haoquan Fang, Dieter Fox, Ranjay Krishna, Cheston Tan, and Bihan Wen. FailSafe: Reasoning and Recovery from Failures in Vision-Language-Action Models, 2025. URLhttps://arxiv.org/abs/2510.01642
arXiv 2025
-
[18]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning, 2023. URLhttps: //arxiv.org/abs/2306.03310
Pith/arXiv arXiv 2023
-
[19]
Note on the Sampling Error of the Difference between Correlated Propor- tions or Percentages.Psychometrika, 12(2):153–157, 1947
Quinn McNemar. Note on the Sampling Error of the Difference between Correlated Propor- tions or Percentages.Psychometrika, 12(2):153–157, 1947. URLhttps://doi.org/10.1007/ BF02295996
1947
-
[20]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots, 2025
NVIDIA, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang ...
Pith/arXiv arXiv 2025
-
[21]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch...
Pith/arXiv arXiv 2025
- [22]
-
[23]
Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. InProceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), 2011. URL https://arxiv.org/abs/1011.0686
Pith/arXiv arXiv 2011
-
[24]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics, 2025
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics, 2025. URLhttps://arxiv.org/abs/2506.01844
Pith/arXiv arXiv 2025
-
[25]
Pre-VLA: Preemptive Runtime Verification for Reliable Vision- Language-Action and World-Model Rollouts, 2026
Zhen Sun, Yongjian Guo, Haoran Sun, Luqiao Wang, Wei Lu, Jiachi Ji, Shengzhe Ji, Junwu Xiong, and Zhijun Meng. Pre-VLA: Preemptive Runtime Verification for Reliable Vision- Language-Action and World-Model Rollouts, 2026. URL https://arxiv.org/abs/2605. 22446. 29
2026
-
[26]
Emanuel Todorov, Tom Erez, and Yuval Tassa. MuJoCo: A Physics Engine for Model-Based Control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5026–5033, 2012. URLhttps://doi.org/10.1109/IROS.2012.6386109
-
[27]
Rakshith Vasudev, Melisa Russak, Dan Bikel, and Waseem Alshikh. The Intervention Paradox: Accurate Failure Prediction in Agents Does Not Imply Effective Failure Prevention, 2026. URL https://arxiv.org/abs/2602.03338
arXiv 2026
-
[28]
Chen Xu, Tony Khuong Nguyen, Emma Dixon, Christopher Rodriguez, Patrick Miller, Robert Lee, Paarth Shah, Rares Ambrus, Haruki Nishimura, and Masha Itkina. Can We Detect Failures Without Failure Data? Uncertainty-Aware Runtime Failure Detection for Imitation Learning Policies, 2025. URLhttps://arxiv.org/abs/2503.08558
arXiv 2025
-
[29]
Yifan Yang, Zhixiang Duan, Tianshi Xie, Fuyu Cao, Pinxi Shen, Peili Song, Piaopiao Jin, Guokang Sun, Shaoqing Xu, Yangwei You, and Jingtai Liu. FPC-VLA: A Vision-Language- Action Framework with a Supervisor for Failure Prediction and Correction, 2025. URL https://arxiv.org/abs/2509.04018
arXiv 2025
-
[30]
LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies, 2026
Yue Yang, Shuo Cheng, Yu Fang, Homanga Bharadhwaj, Mingyu Ding, Gedas Bertasius, and Daniel Szafir. LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies, 2026. URLhttps://arxiv.org/abs/2602.21531
arXiv 2026
-
[31]
HELM: Harness-Enhanced Long-horizon Memory for Vision-Language-Action Manipulation, 2026
Zijian Zeng, Fei Ding, Huiming Yang, and Xianwei Li. HELM: Harness-Enhanced Long-horizon Memory for Vision-Language-Action Manipulation, 2026. URLhttps://arxiv.org/abs/2604. 18791. 30
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.