Pomona: Continuous Code Quality Improvement via Small, Automated Changes at Bloomberg
Pith reviewed 2026-06-27 23:53 UTC · model grok-4.3
The pith
Pomona uses scanning and repair skills to generate tiny pull requests that fix code issues and merge quickly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
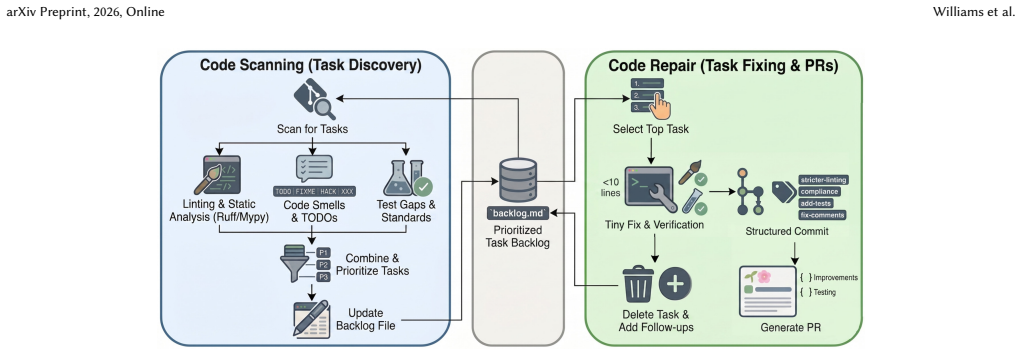
Pomona automates a Kaizen-style loop in which a Scanning skill identifies and prioritizes improvement tasks and a Repair skill produces tiny pull requests; the one-month deployment showed 15 of 17 generated PRs merged at a median time-to-close under two hours, and eight of ten surveyed engineers expressed a desire to adopt the tool for its small diff sizes and code-quality focus.
What carries the argument
The human-in-the-loop cycle of a Scanning skill that builds a structured backlog of tasks and a Repair skill that emits ~10-line diffs for incremental fixes.
If this is right
- Small, low-risk changes allow continuous technical-debt reduction without large disruptions.
- Quick merge times and focused diffs preserve engineer trust and productivity.
- A structured backlog helps teams address quality issues in priority order.
- The design keeps humans in control while automating routine maintenance.
Where Pith is reading between the lines
- The same scanning-plus-repair pattern could be tested in teams with different languages or codebases.
- Longer deployments might reveal whether the rate of new issues stays ahead of the fixes produced.
- Adding more skill types could expand the range of improvements handled automatically.
Load-bearing premise
Results from a single team over one month and surveys of ten engineers will generalize to other teams and longer periods.
What would settle it
A second deployment in a different team in which fewer than half the generated PRs merge or the median close time exceeds one day.
Figures

read the original abstract
In this short experience paper, we present Pomona, a lightweight agentic tool that utilises agent skills for continuous automated code quality improvement. Inspired by the philosophy of Kaizen(TM), Pomona automates a cycle of discovery and incremental repair: a Scanning skill identifies improvement tasks (e.g., linting violations, technical debt markers, and test gaps) and prioritises them in a structured backlog, while a Repair skill generates tiny pull requests (PRs) targeting ~10 lines of diff. This human-in-the-loop design enables frequent, low-risk improvements while maintaining engineer trust and productivity and reducing technical debt. We evaluated Pomona through a one-month deployment in a team and a questionnaire distributed to 10 senior engineers. Our preliminary results are promising: 15 of 17 generated PRs were successfully merged with a median time-to-close of under 2 hours. Furthermore, 8/10 of surveyed engineers expressed a desire to adopt Pomona, praising small diff sizes and Pomona's focus on improving code quality. We conclude by discussing actionable insights for researchers and practitioners on strategies for effective agentic deployment in industry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Pomona, a lightweight agentic tool inspired by Kaizen that uses a Scanning skill to identify code quality tasks (linting, technical debt, test gaps) and a Repair skill to generate small (~10-line) pull requests. It reports results from a one-month deployment in a single team (15 of 17 PRs merged, median time-to-close under 2 hours) and a questionnaire to 10 senior engineers (8/10 expressed desire to adopt), framing the outcomes as preliminary evidence that the human-in-the-loop design supports frequent, low-risk improvements.
Significance. If the small-diff, human-in-the-loop approach can be shown to scale, it would provide a practical template for deploying agentic tools in industry to incrementally reduce technical debt without disrupting engineer productivity. The emphasis on tiny, reviewable changes and explicit trust-preserving design is a concrete contribution to the literature on automated code improvement.
major comments (2)
- [Evaluation / Deployment section] Evaluation / Deployment section: The central effectiveness claim (15/17 merged PRs, 8/10 adoption desire) rests on a single-team, one-month deployment with N=17 PRs and N=10 survey responses. No baseline merge rates for the team, no denominator for total PR volume during the period, no false-positive rate for the Scanning skill, and no longitudinal code-quality metrics are supplied, so the reported percentages cannot be shown to be stable or transferable beyond this setting.
- [Abstract and questionnaire description] Abstract and § on questionnaire: The survey reports only positive desire-to-adopt figures without describing question wording, sampling method, response rate, or any negative or neutral feedback; this limits the ability to interpret the 80 % figure as representative engineer acceptance.
minor comments (2)
- [Deployment description] The manuscript should specify the exact size and composition of the deployment team and the total number of PRs opened by the team during the one-month window to contextualize the 17 generated PRs.
- [Results] Provide a brief breakdown (table or list) of the categories of improvements attempted by the Repair skill and any cases where generated PRs were rejected or required substantial revision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our experience paper. We agree the evaluation is preliminary and will revise to better contextualize limitations while providing additional details on the questionnaire where possible.
read point-by-point responses
-
Referee: [Evaluation / Deployment section] Evaluation / Deployment section: The central effectiveness claim (15/17 merged PRs, 8/10 adoption desire) rests on a single-team, one-month deployment with N=17 PRs and N=10 survey responses. No baseline merge rates for the team, no denominator for total PR volume during the period, no false-positive rate for the Scanning skill, and no longitudinal code-quality metrics are supplied, so the reported percentages cannot be shown to be stable or transferable beyond this setting.
Authors: We agree the deployment was limited to one team and one month, yielding a small sample. As an experience report, the aim was to document initial industrial observations rather than a controlled study with baselines. We will revise the Evaluation section to explicitly note the lack of baselines, total PR volume, false-positive rates, and longitudinal metrics, and to stress that results are preliminary and not claimed to be generalizable. We cannot supply the missing quantitative baselines because they were not collected during the focused deployment of Pomona-generated PRs. revision: partial
-
Referee: [Abstract and questionnaire description] Abstract and § on questionnaire: The survey reports only positive desire-to-adopt figures without describing question wording, sampling method, response rate, or any negative or neutral feedback; this limits the ability to interpret the 80 % figure as representative engineer acceptance.
Authors: We will revise the abstract and questionnaire section to describe the sampling method (distributed to the 10 senior engineers who had reviewed Pomona PRs), the response rate (100%), and the question wording. The questionnaire focused on desire to adopt and perceived benefits of small diffs; we will note that all responses on adoption desire were positive with no negative or neutral feedback recorded. This will improve interpretability of the 8/10 result. revision: yes
- We cannot provide baseline merge rates, total PR volume during the period, false-positive rates for the Scanning skill, or longitudinal code-quality metrics, as these were not measured in the deployment.
Circularity Check
No circularity: paper reports direct empirical observations from deployment with no derivations or fitted models.
full rationale
The paper is an experience report describing a one-month deployment and survey results. It contains no equations, no parameter fitting, no predictions derived from models, and no self-citation chains supporting uniqueness theorems or ansatzes. All claims (e.g., 15/17 PRs merged) are presented as raw observed counts from the deployment, not as outputs of any derivation that reduces to inputs by construction. This matches the default case of a self-contained empirical description with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. 2026. EvoSkill: Automated Skill Discovery for Multi-Agent Systems. arXiv:2603.02766 [cs.AI] https://arxiv.org/abs/2603.02766
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Joel Becker, Nate Rush, Elizabeth Barnes, and David Rein. 2025. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. doi:10.48550/arXiv.2507.09089 arXiv:2507.09089 [cs]
-
[3]
Inc. Github. 2026. About agent skills. https://docs.github.com/en/copilot/ concepts/agents/about-agent-skills. Accessed: April 30, 2026. arXiv Preprint, 2026, Online Williams et al
2026
-
[4]
Jingzhi Gong, Ruizhen Gu, Zhiwei Fei, Yazhuo Cao, Lukas Twist, Alina Geiger, Shuo Han, Dominik Sobania, Federica Sarro, and Jie M. Zhang. 2026. Skill- MOO: Multi-Objective Optimization of Agent Skills for Software Engineering. arXiv:2604.09297 [cs.SE] https://arxiv.org/abs/2604.09297
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [5]
-
[6]
Hao He, Courtney Miller, Shyam Agarwal, Christian Kästner, and Bogdan Vasilescu. 2026. Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity in Open-Source Projects. arXiv:2511.04427 [cs.SE] doi:10.1145/3793302.3793349
-
[7]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Pan, Guilin Qi, Haofen Wang, and Huajun Chen
Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Xin Xu, Tongtong Wu, Kun Wang, Yang Liu, Zhen Bi, Jungang Lou, Yuchen Eleanor Jiang, Hangcheng Zhu, Gang Yu, Haiwen Hong, Longtao Huang, Hui Xue, Chenxi Wang, Yijun Wang, Zifei Shan, Xi Chen, Zhaopeng Tu, Feiyu Xiong, X...
-
[9]
arXiv:2603.04448 [cs.AI] https://arxiv.org/abs/2603.04448
SkillNet: Create, Evaluate, and Connect AI Skills. arXiv:2603.04448 [cs.AI] https://arxiv.org/abs/2603.04448
-
[10]
Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, Ying Zhang, and Leo Yu Zhang. 2026. Malicious Agent Skills in the Wild: A Large-Scale Security Empirical Study. arXiv:2602.06547 [cs.CR] https://arxiv.org/abs/2602. 06547
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Yi Liu, Weizhe Wang, Ruitao Feng, Yao Zhang, Guangquan Xu, Gelei Deng, Yuekang Li, and Leo Zhang. 2026. Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale. arXiv:2601.10338 [cs.CR] https://arxiv.org/ abs/2601.10338
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Anthropic PBC. 2026. Skills | Agent Skills. https://platform.claude.com/docs/en/ agents-and-tools/agent-skills/overview. Accessed: April 30, 2026
2026
-
[13]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. https: //arxiv.org/abs/2302.06590v1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Haifeng Ruan, View Profile, Yuntong Zhang, View Profile, Abhik Roychoudhury, and View Profile. 2025. SpecRover: Code Intent Extraction via LLMs. InPro- ceedings of the IEEE/ACM 47th International Conference on Software Engineering. 963–974. doi:10.1109/ICSE55347.2025.00080
-
[15]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
2025
-
[16]
David Williams et al. 2026. Pomona Supplementary Materials Repository. https: //figshare.com/s/09a23c22550f3e3967b2. Accessed: April 30, 2026
2026
-
[17]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: agent-computer interfaces enable automated software engineering. InProceedings of the 38th International Conference on Neural Information Processing Systems (NIPS ’24, Vol. 37). Curran Associates Inc., Red Hook, NY, USA, 50528–50652
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.