Explain Like I'm 5 or Whatever I Choose: Evaluating the Interactive Potential of Language Model Responses
Pith reviewed 2026-06-27 22:35 UTC · model grok-4.3
The pith
Language models rarely adjust the complexity of their responses in the direction requested when asked to generate multiple versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
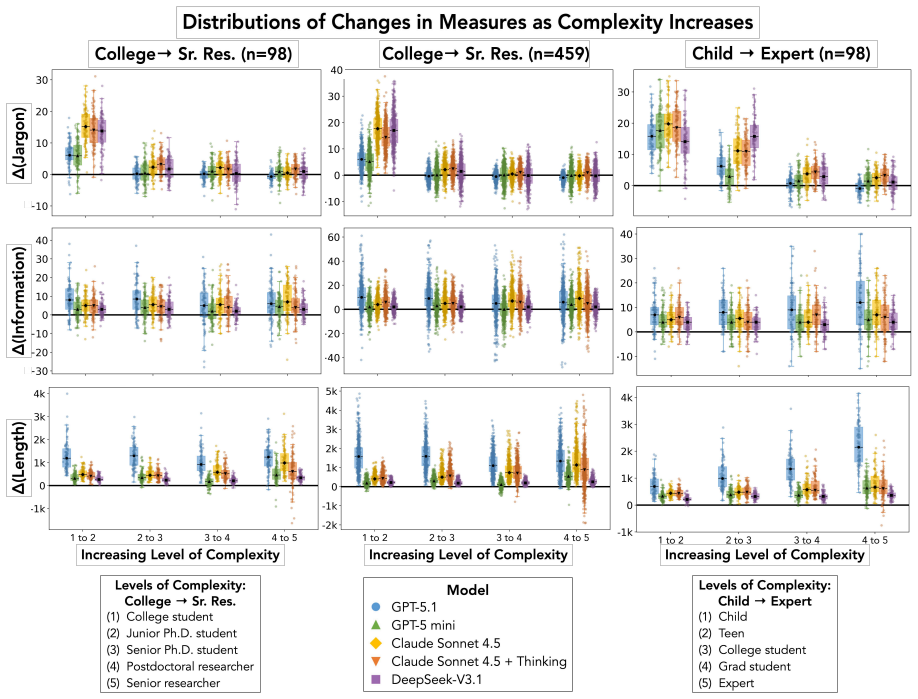
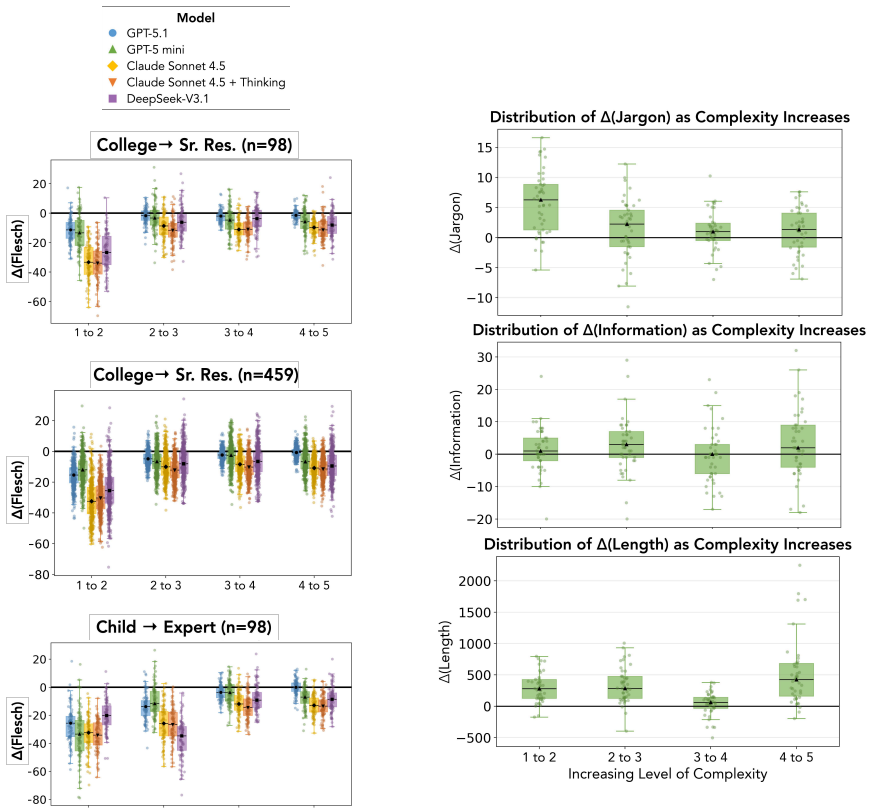
While models vary complexity across responses, most changes remain inconsistent, with the best performing model only shifting reliable complexity measures in the correct direction 46% of the time.
What carries the argument
An evaluation framework that requests five responses per query at specified language complexity levels and measures directional consistency against linguistic complexity metrics.
If this is right
- Evaluations of LLMs must move beyond single static responses to include interface-specific criteria such as controllable variation.
- Prompting for different complexity levels does not produce predictable or reliable shifts in current models.
- The observed inconsistency holds when sample size is increased and when alternative complexity levels are used.
- Scientific queries expose particular difficulty in achieving consistent complexity control.
Where Pith is reading between the lines
- Interfaces allowing users to select explanation depth directly would require models with stronger controllable-generation abilities than those tested here.
- The low consistency rate suggests models do not maintain an internal representation of complexity that aligns well with standard linguistic measures.
- The same framework could be applied to other user-controllable axes such as formality or amount of technical detail to test generality of the limitation.
- Interface designers may need fallback mechanisms, such as post-generation editing, when models fail to deliver the requested complexity level.
Load-bearing premise
The formative study with 16 participants validly identifies language complexity as an appropriate and measurable interpretable axis for testing interactive potential in direct manipulation interfaces.
What would settle it
A follow-up experiment in which human judges rate whether each generated response actually matches its requested complexity level, then check whether the automatic metrics and the 46% figure align with those human ratings.
Figures








read the original abstract
Evaluations of large language models (LLMs) in scientific information seeking tasks have become increasingly use-centric, such as conducting live or multi-turn evaluations with real users. These evaluations still assume a single, static chat interface, but as models are integrated into new interfaces, evaluations must shift to incorporate interface-specific criteria. We propose a new evaluation framework based on a formative study with $16$ participants that tests models' ability to generate multiple responses to one query that differ along an interpretable axis of language (language complexity), inspired by direct manipulation interfaces from human-centered design literature. We evaluate GPT-5.1, GPT-5 mini, Claude Sonnet 4.5 + Thinking, and DeepSeek-V3.1 by generating 5 responses at different levels of language complexity for $98$ scientific queries. While models vary complexity across responses, most changes remain inconsistent, with the best performing model (Claude Sonnet 4.5) only shifting reliable complexity measures in the correct direction $46\%$ of the time. Our findings hold with increased sample size and alternative complexity levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a new evaluation framework for LLMs in scientific information-seeking tasks that incorporates interface-specific criteria from direct-manipulation interfaces. Drawing on a formative study with 16 participants, the framework tests models' ability to produce multiple responses to the same query that differ controllably along the axis of language complexity. Four models (GPT-5.1, GPT-5 mini, Claude Sonnet 4.5 + Thinking, DeepSeek-V3.1) are evaluated on 98 scientific queries by generating five responses at different complexity levels; the central empirical result is that complexity varies but shifts are inconsistent, with the best model (Claude Sonnet 4.5) moving reliable complexity measures in the intended direction only 46% of the time. The authors state that the findings are robust to increased sample size and alternative complexity levels.
Significance. If the central empirical result holds, the work supplies concrete evidence that current LLMs do not reliably support user-controlled variation along an interpretable linguistic axis, which bears on the design of future interactive interfaces. The evaluation supplies a reusable testbed (98 queries, four models, five-level generation) and reports a quantitative benchmark (46% directional success) that can be compared against future models. The explicit grounding in a human formative study and the robustness checks are positive features of the empirical design.
major comments (2)
- [Formative Study] Formative Study section: The claim that language complexity constitutes a valid, measurable, and generalizable interpretable axis for the evaluation framework rests on the 16-participant formative study. The manuscript provides no details on participant demographics, recruitment, exclusion criteria, how complexity preferences were elicited or quantified in that study, or any statistical validation linking the human judgments to the automated complexity measures later applied to the 98 queries. Because the 46% figure is interpreted as evidence of limited interactive potential only if this axis is appropriate and reliably measurable, the absence of these details makes the central claim difficult to evaluate.
- [Evaluation / Results] Evaluation / Results section: The phrase 'reliable complexity measures' used to compute the 46% directional-success rate is not defined; it is unclear which automated metrics were retained, how 'correct direction' was operationalized across the five requested levels, what statistical test or threshold determined reliability, or whether any queries or responses were excluded. These omissions directly affect the interpretability of the headline quantitative result.
minor comments (2)
- [Abstract] Abstract and §4: Model names (GPT-5.1, GPT-5 mini) appear to be non-standard or future designations; clarify their exact versions or release dates so readers can reproduce the evaluation.
- [Results] The statement that findings 'hold with increased sample size' is reported without the actual larger N or the corresponding percentages; adding these numbers would strengthen the robustness claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate planned revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Formative Study] Formative Study section: The claim that language complexity constitutes a valid, measurable, and generalizable interpretable axis for the evaluation framework rests on the 16-participant formative study. The manuscript provides no details on participant demographics, recruitment, exclusion criteria, how complexity preferences were elicited or quantified in that study, or any statistical validation linking the human judgments to the automated complexity measures later applied to the 98 queries. Because the 46% figure is interpreted as evidence of limited interactive potential only if this axis is appropriate and reliably measurable, the absence of these details makes the central claim difficult to evaluate.
Authors: We agree that the Formative Study section lacks sufficient methodological detail to allow readers to assess the validity of language complexity as the chosen axis. The study was designed as a small-scale formative exercise to surface user needs in direct-manipulation interfaces rather than a comprehensive validation. We will revise the section to report recruitment (university mailing lists and research participant pools), available demographics (age 22–45, varied STEM and non-STEM backgrounds), elicitation procedure (paired comparison of sample responses plus Likert-scale preference ratings), and observed alignment between participant preferences and the two automated metrics later retained. We will also note the absence of formal exclusion criteria and the primarily qualitative nature of the study. revision: yes
-
Referee: [Evaluation / Results] Evaluation / Results section: The phrase 'reliable complexity measures' used to compute the 46% directional-success rate is not defined; it is unclear which automated metrics were retained, how 'correct direction' was operationalized across the five requested levels, what statistical test or threshold determined reliability, or whether any queries or responses were excluded. These omissions directly affect the interpretability of the headline quantitative result.
Authors: We acknowledge that the operational definitions are underspecified. 'Reliable complexity measures' refers to the two automated metrics retained after the formative study: Flesch-Kincaid grade level and type-token ratio. 'Correct direction' is operationalized as a strictly increasing sequence across the five requested levels (i.e., metric value at level k+1 > metric value at level k for at least three of the four consecutive pairs). The 46% figure is the proportion of (query, model) pairs meeting this criterion; no queries or responses were excluded. We will add an explicit subsection under Evaluation that states the metrics, the monotonicity criterion, and the exact computation, along with supplementary results using alternative thresholds. revision: yes
Circularity Check
No circularity: purely empirical evaluation without derivations or self-referential steps
full rationale
The paper conducts a formative user study (n=16) to identify language complexity as an interpretable axis, then empirically measures model outputs on 98 queries for consistency in shifting that axis. No equations, fitted parameters renamed as predictions, self-citations forming load-bearing premises, or ansatzes appear in the described chain. The framework is constructed from independent data collection and automated metrics applied to generated responses; findings (e.g., 46% success rate) are direct observations rather than reductions to inputs by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language complexity is an interpretable and quantifiable axis suitable for direct manipulation in interactive interfaces
Reference graph
Works this paper leans on
-
[1]
Liao, Zhehui and Antoniak, Maria and Cheong, Inyoung and Cheng, Evie Yu-Yen and Lee, Ai-Heng and Lo, Kyle and Chang, Joseph Chee and Zhang, Amy X , booktitle =
-
[2]
Nature , pages=
Synthesizing scientific literature with retrieval-augmented language models , author =. Nature , pages=. 2026 , doi =
2026
-
[3]
Journal of Clinical Nursing , year =
Mudd, Alexandra and Conroy, Tiffany and Voldbjerg, Siri Lygum and Goldschmied, Anita and Feo, Rebecca and Schuwirth, Lambert , title =. Journal of Clinical Nursing , year =. doi:https://doi.org/10.1111/jocn.17818 , url =
-
[4]
2023 , eprint=
Scientists' Perspectives on the Potential for Generative AI in their Fields , author=. 2023 , eprint=
2023
-
[5]
ELI -Why: Evaluating the Pedagogical Utility of Language Model Explanations
Joshi, Brihi and He, Keyu and Ramnath, Sahana and Sabouri, Sadra and Zhou, Kaitlyn and Chattopadhyay, Souti and Swayamdipta, Swabha and Ren, Xiang. ELI -Why: Evaluating the Pedagogical Utility of Language Model Explanations. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1306
-
[6]
Fok, Raymond and Chang, Joseph Chee and August, Tal and Zhang, Amy X. and Weld, Daniel S. , title =. 2024 , isbn =. doi:10.1145/3654777.3676397 , booktitle =
-
[7]
and Bragg, Jonathan and Head, Andrew and Lo, Kyle and Downey, Doug and Weld, Daniel S
Chang, Joseph Chee and Zhang, Amy X. and Bragg, Jonathan and Head, Andrew and Lo, Kyle and Downey, Doug and Weld, Daniel S. , title =. 2023 , isbn =. doi:10.1145/3544548.3580847 , booktitle =
-
[8]
Zamfirescu-Pereira, J.D. and Wong, Richmond Y. and Hartmann, Bjoern and Yang, Qian , title =. Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems , articleno =. 2023 , isbn =. doi:10.1145/3544548.3581388 , abstract =
-
[9]
Nicholas, David and Williams, Peter and Rowlands, Ian and Jamali, Hamid R. , title =. 2010 , issue_date =. doi:10.1177/0165551510371883 , journal =
-
[10]
Digital reading spaces: How expert readers handle books, the Web and electronic paper , volume=. First Monday , author=. doi:10.5210/fm.v15i4.2762 , number=
-
[12]
Hedlin, Elias and Estling, Ludwig and Wong, Jacqueline and Demmans Epp, Carrie and Viberg, Olga , title =. 2025 , isbn =. doi:10.1145/3706468.3706483 , booktitle =
-
[13]
Fok, Raymond and Kambhamettu, Hita and Soldaini, Luca and Bragg, Jonathan and Lo, Kyle and Hearst, Marti and Head, Andrew and Weld, Daniel S , title =. 2023 , isbn =. doi:10.1145/3581641.3584034 , booktitle =
-
[14]
Hohman, Fred and Conlen, Matthew and Heer, Jeffrey and Chau, Duen Horng , title=. Distill , year=. doi:10.23915/distill.00028 , url=
-
[15]
and Reinecke, Katharina , title =
August, Tal and Lo, Kyle and Smith, Noah A. and Reinecke, Katharina , title =. 2024 , isbn =. doi:10.1145/3613904.3642289 , booktitle =
-
[16]
and Head, Andrew and Lo, Kyle , title =
August, Tal and Wang, Lucy Lu and Bragg, Jonathan and Hearst, Marti A. and Head, Andrew and Lo, Kyle , title =. 2023 , issue_date =. doi:10.1145/3589955 , journal =
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Automated Lay Language Summarization of Biomedical Scientific Reviews , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i1.16089 , number=
-
[18]
EMNLP: System Demonstrations
ACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific Concepts , author =. EMNLP: System Demonstrations. 2022
2022
-
[19]
Jonathan Bragg and Mike D'Arcy and Nishant Balepur and Dan Bareket and Bhavana Dalvi Mishra and Sergey Feldman and Dany Haddad and Jena D. Hwang and Peter Jansen and Varsha Kishore and Bodhisattwa Prasad Majumder and Aakanksha Naik and Sigal Rahamimov and Kyle Richardson and Amanpreet Singh and Harshit Surana and Aryeh Tiktinsky and Rosni Vasu and Guy Wie...
2026
-
[20]
Communications of the ACM (CACM) , year =
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces , author =. Communications of the ACM (CACM) , year =
-
[21]
Personalized Jargon Identification for Enhanced Interdisciplinary Communication
Guo, Yue and Chang, Joseph Chee and Antoniak, Maria and Bransom, Erin and Cohen, Trevor and Wang, Lucy and August, Tal. Personalized Jargon Identification for Enhanced Interdisciplinary Communication. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Lo...
-
[22]
and Kinney, Rodney and Weld, Daniel S and Downey, Doug and Feldman, Sergey
Singh, Amanpreet and Chang, Joseph Chee and Haddad, Dany and Naik, Aakanksha and Hwang, Jena D. and Kinney, Rodney and Weld, Daniel S and Downey, Doug and Feldman, Sergey. Ai2 Scholar QA : Organized Literature Synthesis with Attribution. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstration...
-
[23]
Communications Medicine , year=
Rust, Paul and Frings, Julian and Meister, Sven and Fehring, Leonard , title=. Communications Medicine , year=. doi:10.1038/s43856-025-00927-2 , url=
-
[24]
Sharon Whitfield and Melissa A. Hofmann , title =. Public Services Quarterly , volume =. 2023 , publisher =. doi:10.1080/15228959.2023.2224125 , URL =
-
[25]
International Journal of Advanced Computer Science and Applications(IJACSA), Special Issue on Natural Language Processing 2014 , doi =
Matthew Shardlow , title =. International Journal of Advanced Computer Science and Applications(IJACSA), Special Issue on Natural Language Processing 2014 , doi =. 2014 , publisher =
2014
-
[26]
Elaborative Simplification: Content Addition and Explanation Generation in Text Simplification
Srikanth, Neha and Li, Junyi Jessy. Elaborative Simplification: Content Addition and Explanation Generation in Text Simplification. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.455
-
[27]
Generating Scientific Definitions with Controllable Complexity
August, Tal and Reinecke, Katharina and Smith, Noah A. Generating Scientific Definitions with Controllable Complexity. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.569
-
[28]
Towards Generating Personalized Hospitalization Summaries
Acharya, Sabita and Di Eugenio, Barbara and Boyd, Andrew and Cameron, Richard and Dunn Lopez, Karen and Martyn-Nemeth, Pamela and Dickens, Carolyn and Ardati, Amer. Towards Generating Personalized Hospitalization Summaries. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Student Research ...
-
[29]
Head, Andrew and Lo, Kyle and Kang, Dongyeop and Fok, Raymond and Skjonsberg, Sam and Weld, Daniel S. and Hearst, Marti A. , title =. 2021 , isbn =. doi:10.1145/3411764.3445648 , booktitle =
-
[30]
SimplifyMyText: An LLM-Based System for Inclusive Plain Language Text Simplification , year =
F\". SimplifyMyText: An LLM-Based System for Inclusive Plain Language Text Simplification , year =. Advances in Information Retrieval: 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6–10, 2025, Proceedings, Part IV , pages =
2025
-
[31]
The benefits, risks and bounds of personalizing the alignment of large language models to individuals
Kirk, Hannah Rose and Vidgen, Bertie and R \"o ttger, Paul and Hale, Scott A. The benefits, risks and bounds of personalizing the alignment of large language models to individuals. Nature Machine Intelligence
-
[32]
Wu, Ning and Gong, Ming and Shou, Linjun and Liang, Shining and Jiang, Daxin , title =. 2023 , isbn =. doi:10.1007/978-3-031-44693-1_54 , booktitle =
-
[33]
Min, Bryan and Chen, Allen and Cao, Yining and Xia, Haijun , title =. 2025 , isbn =. doi:10.1145/3706598.3714164 , booktitle =
-
[34]
Shyam and Xu, Qian and Bellur, Saraswathi , title =
Sundar, S. Shyam and Xu, Qian and Bellur, Saraswathi , title =. 2010 , isbn =. doi:10.1145/1753326.1753666 , booktitle =
-
[35]
Clearer Governmental Communication: Text Simplification with C hat GPT Evaluated by Quantitative and Qualitative Research
Beks van Raaij, Nadine and Kolkman, Daan and Podoynitsyna, Ksenia. Clearer Governmental Communication: Text Simplification with C hat GPT Evaluated by Quantitative and Qualitative Research. Proceedings of the Workshop on DeTermIt! Evaluating Text Difficulty in a Multilingual Context @ LREC-COLING 2024. 2024
2024
-
[36]
2026 , eprint=
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
EnterpriseBench Corecraft: Training Generalizable Agents on High-Fidelity RL Environments , author=. 2026 , eprint=
2026
-
[38]
2026 , url=
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , booktitle=. 2026 , url=
2026
-
[39]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[40]
Flesch or Fumble? Evaluating Readability Standard Alignment of Instruction-Tuned Language Models
Imperial, Joseph Marvin and Tayyar Madabushi, Harish. Flesch or Fumble? Evaluating Readability Standard Alignment of Instruction-Tuned Language Models. Proceedings of the Third Workshop on Natural Language Generation, Evaluation, and Metrics (GEM). 2023
2023
-
[41]
Evaluating the Evaluators: Are readability metrics good measures of readability?
Cachola, Isabel and Khashabi, Daniel and Dredze, Mark. Evaluating the Evaluators: Are readability metrics good measures of readability?. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1225
-
[42]
Flesch-Kincaid is Not a Text Simplification Evaluation Metric
Tanprasert, Teerapaun and Kauchak, David. Flesch-Kincaid is Not a Text Simplification Evaluation Metric. Proceedings of the First Workshop on Natural Language Generation, Evaluation, and Metrics (GEM). 2021. doi:10.18653/v1/2021.gem-1.1
-
[43]
Alghamdi, Tal August, Avinash Bhat, Madiha Zahrah Choksi, Senjuti Dutta, Jin L.C
Lee, Mina and Gero, Katy Ilonka and Chung, John Joon Young and Shum, Simon Buckingham and Raheja, Vipul and Shen, Hua and Venugopalan, Subhashini and Wambsganss, Thiemo and Zhou, David and Alghamdi, Emad A. and August, Tal and Bhat, Avinash and Choksi, Madiha Zahrah and Dutta, Senjuti and Guo, Jin L.C. and Hoque, Md Naimul and Kim, Yewon and Knight, Simon...
-
[44]
2026 , eprint=
From Words to Widgets for Controllable LLM Generation , author=. 2026 , eprint=
2026
-
[45]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , articleno =
Joshi, Nikhita and Vogel, Daniel , title =. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , articleno =. 2026 , isbn =. doi:10.1145/3772318.3790786 , abstract =
-
[46]
Qualitative Research in Sport, Exercise and Health , volume =
Virginia Braun and Victoria Clarke , title =. Qualitative Research in Sport, Exercise and Health , volume =. 2019 , publisher =. doi:10.1080/2159676X.2019.1628806 , URL =
-
[47]
Science Journal for Kids and Teens , author=
Science Journal for Kids and Teens , url=. Science Journal for Kids and Teens , author=
-
[48]
Matejka, Justin and Fitzmaurice, George , title =. 2017 , isbn =. doi:10.1145/3025453.3025912 , booktitle =
-
[49]
APPLS : Evaluating Evaluation Metrics for Plain Language Summarization
Guo, Yue and August, Tal and Leroy, Gondy and Cohen, Trevor and Wang, Lucy Lu. APPLS : Evaluating Evaluation Metrics for Plain Language Summarization. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.519
-
[50]
A new readability yardstick. , volume=. Journal of Applied Psychology , author=. 1948 , pages=. doi:https://doi.org/10.1037/h0057532 , number=
-
[51]
Cochrane Evidence Synthesis and Methods , author=
ChatGPT‐4o Compared With Human Researchers in Writing Plain‐Language Summaries for Cochrane Reviews: A Blinded, Randomized Non‐Inferiority Controlled Trial , volume=. Cochrane Evidence Synthesis and Methods , author=. 2025 , month=. doi:https://doi.org/10.1002/cesm.70037 , number=
-
[52]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Fast and Accurate Prediction of Sentence Specificity , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2015 , month=. doi:10.1609/aaai.v29i1.9517 , abstractNote=
-
[53]
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.1...
-
[54]
1995 , url=
Readability revisited : the new Dale-Chall readability formula , author=. 1995 , url=
1995
-
[55]
Kim, Taewook and Agarwal, Dhruv and Ackerman, Jordan and Saha, Manaswi , title =. 2025 , issue_date =. doi:10.1145/3757660 , journal =
-
[56]
Adar, Eytan and Gearig, Carolyn and Balasubramanian, Ayshwarya and Hullman, Jessica , title =. 2017 , isbn =. doi:10.1145/3025453.3025631 , booktitle =
-
[57]
The Thirteenth International Conference on Learning Representations , year=
Context Steering: Controllable Personalization at Inference Time , author=. The Thirteenth International Conference on Learning Representations , year=
-
[58]
Zaidi, Ali and Karahalios, Karrie , title =. 2025 , isbn =. doi:10.1145/3715336.3735778 , booktitle =
-
[59]
Length Controlled Generation for Black-box LLM s
Gu, Yuxuan and Wang, Wenjie and Feng, Xiaocheng and Zhong, Weihong and Zhu, Kun and Huang, Lei and Liu, Ting and Qin, Bing and Chua, Tat-Seng. Length Controlled Generation for Black-box LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.825
-
[60]
Brevity is the soul of sustainability: Characterizing LLM response lengths
Poddar, Soham and Koley, Paramita and Misra, Janardan and Ganguly, Niloy and Ghosh, Saptarshi. Brevity is the soul of sustainability: Characterizing LLM response lengths. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1125
-
[61]
An Empirical Study of LLM Reasoning Ability Under Strict Output Length Constraint
Sun, Yi and Wang, Han and Li, Jiaqiang and Liu, Jiacheng and Li, Xiangyu and Wen, Hao and Yuan, Yizhen and Zheng, Huiwen and Liang, Yan and Li, Yuanchun and Liu, Yunxin. An Empirical Study of LLM Reasoning Ability Under Strict Output Length Constraint. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.186...
-
[62]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[63]
The Innovation 7(6), 101253 (2026) https://doi.org/10.1016/j.xinn.2025.101253
Jiawei Gu and Xuhui Jiang and Zhichao Shi and Hexiang Tan and Xuehao Zhai and Chengjin Xu and Wei Li and Yinghan Shen and Shengjie Ma and Honghao Liu and Saizhuo Wang and Kun Zhang and Zhouchi Lin and Bowen Zhang and Lionel Ni and Wen Gao and Yuanzhuo Wang and Jian Guo , keywords =. A survey on LLM-as-a-judge , journal =. 2026 , issn =. doi:https://doi.or...
-
[64]
How Reliable is Multilingual LLM -as-a-Judge?
Fu, Xiyan and Liu, Wei. How Reliable is Multilingual LLM -as-a-Judge?. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.587
-
[65]
Calderon, Nitay and Reichart, Roi and Dror, Rotem. The Alternative Annotator Test for LLM -as-a-Judge: How to Statistically Justify Replacing Human Annotators with LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.782
-
[66]
From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan. From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge. Proceedings of the 2025 Conference on Empirical Methods ...
-
[67]
Concise Answers to Complex Questions: Summarization of Long-form Answers
Potluri, Abhilash and Xu, Fangyuan and Choi, Eunsol. Concise Answers to Complex Questions: Summarization of Long-form Answers. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.541
-
[68]
A Long Way to Go: Investigating Length Correlations in
Prasann Singhal and Tanya Goyal and Jiacheng Xu and Greg Durrett , booktitle=. A Long Way to Go: Investigating Length Correlations in. 2024 , url=
2024
-
[69]
and Hohman, Fred and Chau, Duen Horng
Wang, Zijie J. and Hohman, Fred and Chau, Duen Horng. W iz M ap: Scalable Interactive Visualization for Exploring Large Machine Learning Embeddings. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2023. doi:10.18653/v1/2023.acl-demo.50
-
[70]
The coding manual for qualitative researchers , ISBN=
Saldaña, Johnny , year=. The coding manual for qualitative researchers , ISBN=
-
[71]
McDonald, Nora and Schoenebeck, Sarita and Forte, Andrea , title =. 2019 , issue_date =. doi:10.1145/3359174 , journal =
-
[72]
Retrieval augmentation of large language models for lay language generation , journal =
Yue Guo and Wei Qiu and Gondy Leroy and Sheng Wang and Trevor Cohen , keywords =. Retrieval augmentation of large language models for lay language generation , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.jbi.2023.104580 , url =
-
[73]
Ren, Shaolei and Tomlinson, Bill and Black, Rebecca W. and Torrance, Andrew W. , year=. Reconciling the contrasting narratives on the environmental impact of large language models , volume=. Scientific Reports , publisher=. doi:10.1038/s41598-024-76682-6 , number=
-
[74]
Desislavov, Radosvet and Martínez-Plumed, Fernando and Hernández-Orallo, José , year=. Trends in AI inference energy consumption: Beyond the performance-vs-parameter laws of deep learning , volume=. doi:https://doi.org/10.1016/j.suscom.2023.100857 , journal=
-
[75]
An Audit on the Perspectives and Challenges of Hallucinations in NLP
Venkit, Pranav Narayanan and Chakravorti, Tatiana and Gupta, Vipul and Biggs, Heidi and Srinath, Mukund and Goswami, Koustava and Rajtmajer, Sarah and Wilson, Shomir. An Audit on the Perspectives and Challenges of Hallucinations in NLP. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp...
-
[76]
Vera and Xiao, Ziang , title =
Sharma, Nikhil and Liao, Q. Vera and Xiao, Ziang , title =. 2024 , isbn =. doi:10.1145/3613904.3642459 , booktitle =
-
[77]
Veracity Bias and Beyond: Uncovering LLM s' Hidden Beliefs in Problem-Solving Reasoning
Zhou, Yue and Di Eugenio, Barbara. Veracity Bias and Beyond: Uncovering LLM s' Hidden Beliefs in Problem-Solving Reasoning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1034
-
[78]
Elaborative Simplification as Implicit Questions Under Discussion
Wu, Yating and Sheffield, William and Mahowald, Kyle and Li, Junyi Jessy. Elaborative Simplification as Implicit Questions Under Discussion. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.336
-
[79]
I nfo L oss QA : Characterizing and Recovering Information Loss in Text Simplification
Trienes, Jan and Joseph, Sebastian and Schl. I nfo L oss QA : Characterizing and Recovering Information Loss in Text Simplification. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.234
-
[80]
Tan, Hexiang and Sun, Fei and Yang, Wanli and Wang, Yuanzhuo and Cao, Qi and Cheng, Xueqi. Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts When Knowledge Conflicts?. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.337
-
[81]
Merging Generated and Retrieved Knowledge for Open-Domain QA
Zhang, Yunxiang and Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu. Merging Generated and Retrieved Knowledge for Open-Domain QA. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.286
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.