The Effect of Training Task Diversity on In-Context Learning through the Lens of Low-Dimensional Subspaces
Pith reviewed 2026-06-27 21:02 UTC · model grok-4.3
The pith
Modeling training task vectors as a mixture of low-rank Gaussians explains how subspace diversity shortens the ICL plateau and produces apparent out-of-distribution generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
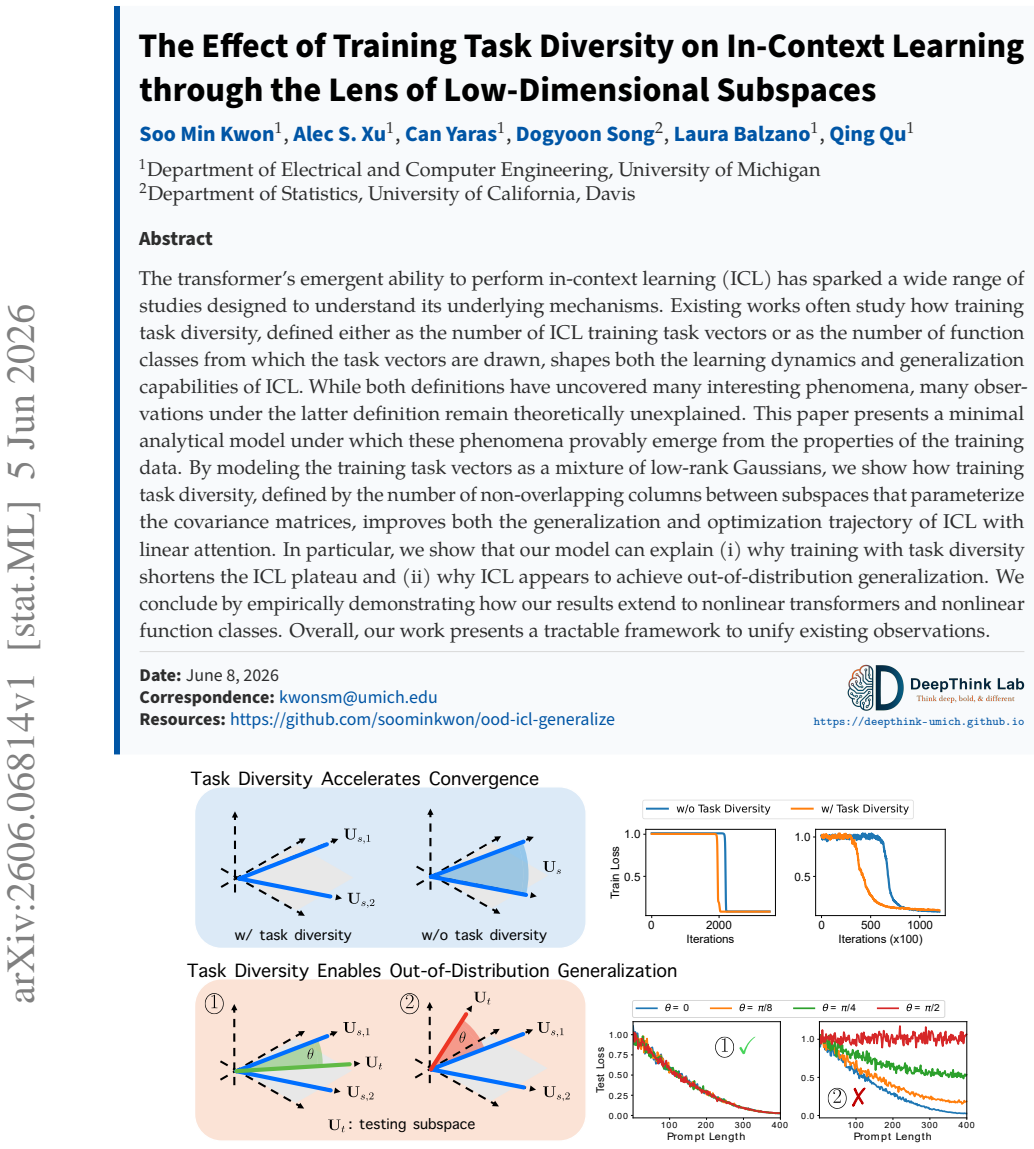
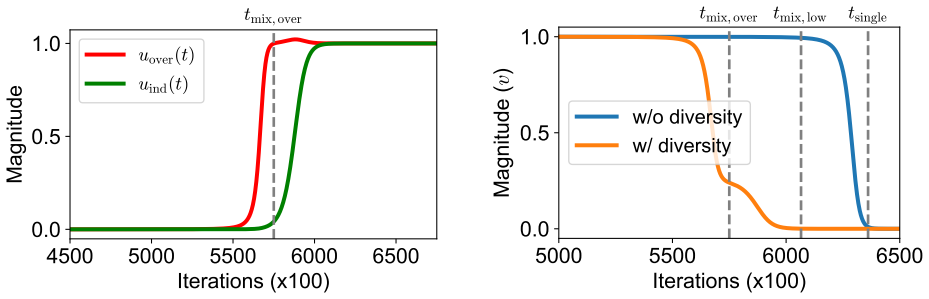
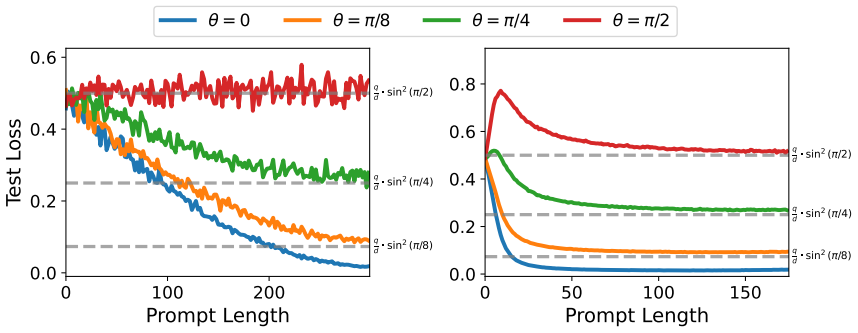
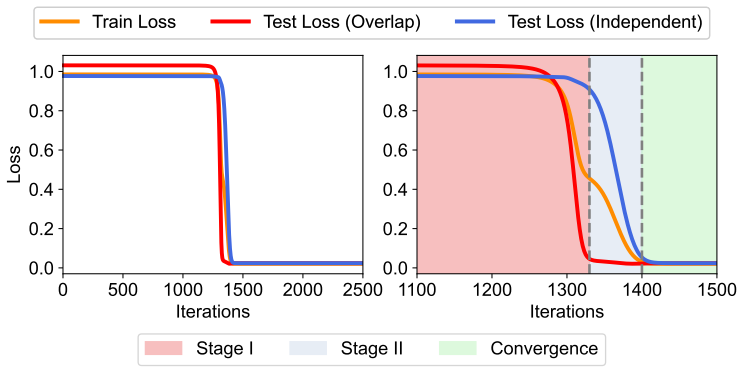
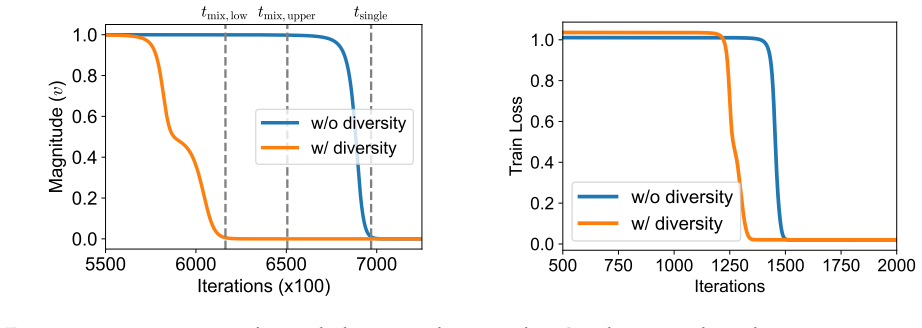
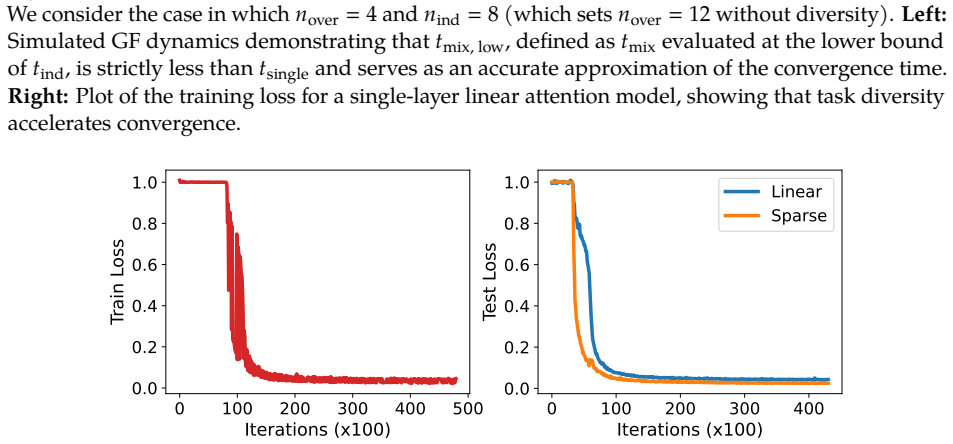
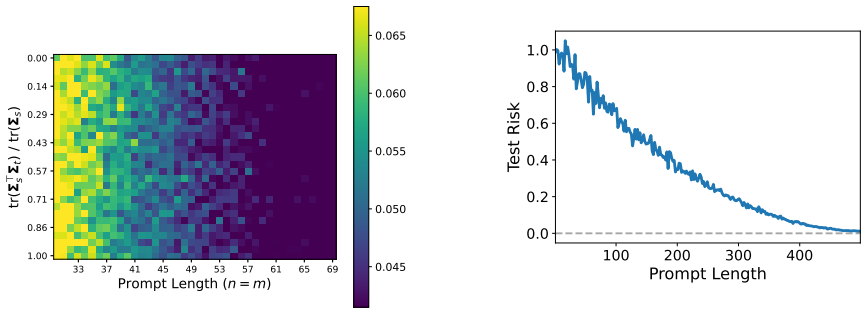
By representing training task vectors as samples from a mixture of low-rank Gaussians whose covariances are set by subspaces, the number of non-overlapping columns between those subspaces determines how task diversity affects the optimization and generalization of in-context learning using linear attention. This setup provably leads to faster escape from the ICL plateau when diversity increases and produces apparent out-of-distribution generalization.
What carries the argument
Mixture of low-rank Gaussians for task vectors, with diversity given by the count of non-overlapping columns between the subspaces that parameterize the covariance matrices.
If this is right
- Higher task diversity, measured by subspace non-overlap, shortens the plateau phase in the optimization trajectory of linear attention for ICL.
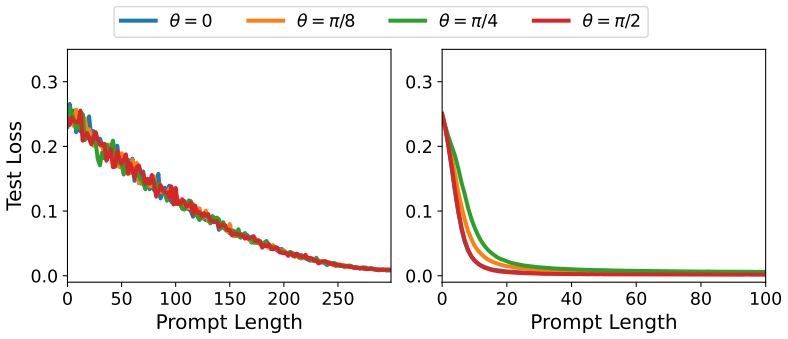
- The same diversity measure produces the appearance of out-of-distribution generalization even though the underlying mechanism stays inside the training distribution.
- The low-rank Gaussian mixture model unifies phenomena previously studied under two different definitions of task diversity.
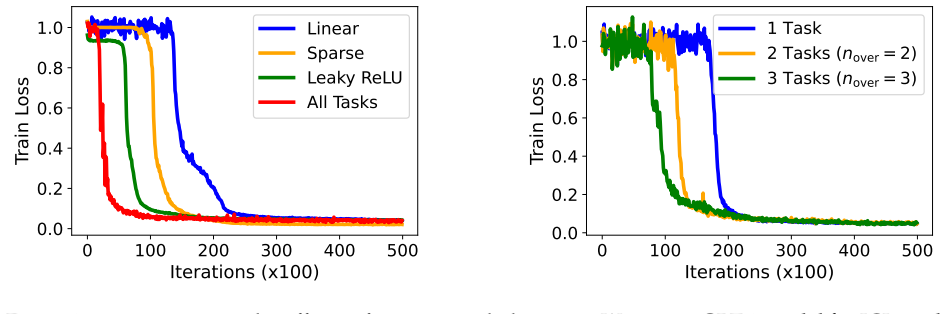
- The same qualitative effects appear when the analysis is extended empirically to nonlinear transformers and nonlinear function classes.
Where Pith is reading between the lines
- The subspace-overlap metric could be used to design or filter pre-training corpora so that the number of non-overlapping directions is deliberately maximized.
- If the model captures the essential geometry, then random sampling of tasks is likely suboptimal and structured sampling that controls subspace overlap could improve sample efficiency.
- The same low-rank mixture lens might be applied to other emergent transformer behaviors whose training dynamics currently lack simple explanations.
Load-bearing premise
The distribution of training task vectors can be accurately captured by a mixture of low-rank Gaussians whose covariance matrices are set by subspaces.
What would settle it
Train a linear attention model on task vectors whose generating subspaces have more overlap and observe that the ICL plateau length does not increase or that out-of-distribution behavior disappears.
Figures

read the original abstract
The transformer's emergent ability to perform in-context learning (ICL) has sparked a wide range of studies designed to understand its underlying mechanisms. Existing works often study how training task diversity, defined either as the number of ICL training task vectors or as the number of function classes from which the task vectors are drawn, shapes both the learning dynamics and generalization capabilities of ICL. While both definitions have uncovered many interesting phenomena, many observations under the latter definition remain theoretically unexplained. This paper presents a minimal analytical model under which these phenomena provably emerge from the properties of the training data. By modeling the training task vectors as a mixture of low-rank Gaussians, we show how training task diversity, defined by the number of non-overlapping columns between subspaces that parameterize the covariance matrices, improves both the generalization and optimization trajectory of ICL with linear attention. In particular, we show that our model can explain (i) why training with task diversity shortens the ICL plateau and (ii) why ICL appears to achieve out-of-distribution generalization. We conclude by empirically demonstrating how our results extend to nonlinear transformers and nonlinear function classes. Overall, our work presents a tractable framework to unify existing observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modeling ICL training task vectors as a mixture of low-rank Gaussians, with diversity quantified by the number of non-overlapping columns between the subspaces parameterizing their covariance matrices, yields a minimal analytical model from which two phenomena provably emerge for linear attention: (i) increased task diversity shortens the ICL plateau and (ii) ICL exhibits apparent out-of-distribution generalization. The model is presented as explaining these effects directly from training-data properties, with empirical extension to nonlinear transformers and function classes.
Significance. If the generative assumptions are representative, the work supplies a tractable, low-dimensional subspace framework that analytically unifies several previously observed but theoretically unexplained effects of task diversity on ICL optimization trajectories and generalization. The explicit derivation under a mixture-of-low-rank-Gaussians model and the empirical checks on nonlinear cases are strengths that could make the framework useful for further theoretical study of linear attention.
major comments (2)
- [Abstract / modeling section] Abstract and modeling section: the central explanatory claim—that the shortened plateau and apparent OOD generalization 'provably emerge from the properties of the training data'—rests entirely on the unverified generative assumption that real ICL task vectors are well-approximated by a mixture of low-rank Gaussians whose diversity is captured by non-overlapping subspace columns. No section provides a direct empirical check (e.g., covariance estimation or subspace overlap statistics) on standard ICL training distributions to support that this structure is operative rather than an ad-hoc modeling choice.
- [Analytical derivations] The analytical results on plateau length and OOD generalization are derived under the specific mixture-of-low-rank-Gaussians model for linear attention. If the true task covariances deviate from this structure (as the skeptic note suggests is possible), the link between the derived quantities and observed transformer behavior is weakened; the manuscript does not contain a sensitivity analysis or alternative generative models to test robustness of the two main phenomena.
minor comments (2)
- [Modeling section] Notation for the subspace overlap count and the mixture weights should be introduced with a single, self-contained definition early in the modeling section to avoid later ambiguity.
- [Empirical section] The empirical extension to nonlinear transformers would benefit from an explicit statement of the architecture, depth, and training hyperparameters used, so that the claimed qualitative agreement can be reproduced.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. Below, we provide point-by-point responses to the major comments, clarifying the scope and intent of our theoretical model.
read point-by-point responses
-
Referee: [Abstract / modeling section] Abstract and modeling section: the central explanatory claim—that the shortened plateau and apparent OOD generalization 'provably emerge from the properties of the training data'—rests entirely on the unverified generative assumption that real ICL task vectors are well-approximated by a mixture of low-rank Gaussians whose diversity is captured by non-overlapping subspace columns. No section provides a direct empirical check (e.g., covariance estimation or subspace overlap statistics) on standard ICL training distributions to support that this structure is operative rather than an ad-hoc modeling choice.
Authors: We thank the referee for this observation. Our claim is specifically that the described phenomena provably emerge from the properties of the training data *under the proposed minimal analytical model*. The model is not presented as a verified description of real ICL task distributions but as a tractable framework that isolates the effect of subspace diversity on ICL dynamics for linear attention. The low-rank Gaussian mixture assumption is motivated by the prevalence of low-dimensional structures in ICL analyses in the literature. While we agree that direct empirical checks on standard datasets would provide additional support, such verification falls outside the theoretical focus of this work. Our empirical contributions instead demonstrate that the qualitative predictions hold when extending to nonlinear transformers and function classes. revision: no
-
Referee: [Analytical derivations] The analytical results on plateau length and OOD generalization are derived under the specific mixture-of-low-rank-Gaussians model for linear attention. If the true task covariances deviate from this structure (as the skeptic note suggests is possible), the link between the derived quantities and observed transformer behavior is weakened; the manuscript does not contain a sensitivity analysis or alternative generative models to test robustness of the two main phenomena.
Authors: The derivations are performed under this specific model to enable analytical tractability and explicit connections between subspace overlap and the ICL phenomena. We selected the mixture-of-low-rank-Gaussians structure precisely because it permits closed-form analysis of the optimization trajectory and generalization. Regarding robustness, the manuscript includes empirical validation on nonlinear attention mechanisms and nonlinear function classes, which serves as an initial check that the effects are not artifacts of the linear setting. A comprehensive sensitivity analysis across multiple alternative generative models would be a substantial undertaking and is not included; however, the minimal nature of the model is intended to highlight the core mechanism rather than to exhaustively model all possible task distributions. revision: no
Circularity Check
Analytical model derives ICL effects from posited generative assumptions without reduction to inputs by construction.
full rationale
The paper posits a mixture-of-low-rank-Gaussians model for task vectors and defines diversity via non-overlapping subspace columns, then mathematically derives shortened ICL plateau and apparent OOD generalization as consequences under linear attention. This is a standard forward derivation from stated assumptions rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or claims in the provided text reduce the output phenomena to the modeling choice by tautology; the results are conditional on the model. The assumption itself may be strong or unverified against real data, but that is a question of external validity, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training task vectors follow a mixture of low-rank Gaussians whose covariances are parameterized by subspaces
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning,
Libin Zhu and Chaoyue Liu and Adityanarayanan Radhakrishnan and Mikhail Belkin , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[2]
The Impact of Initialization on Lo
Soufiane Hayou and Nikhil Ghosh and Bin Yu , booktitle=. The Impact of Initialization on Lo. 2024 , url=
2024
-
[3]
Soufiane Hayou and Nikhil Ghosh and Bin Yu , booktitle=. Lo. 2024 , url=
2024
-
[4]
Submitted to The Thirteenth International Conference on Learning Representations , year=
Efficient Learning with Sine-Activated Low-Rank Matrices , author=. Submitted to The Thirteenth International Conference on Learning Representations , year=
-
[5]
The Twelfth International Conference on Learning Representations , year=
Benign Oscillation of Stochastic Gradient Descent with Large Learning Rate , author=. The Twelfth International Conference on Learning Representations , year=
-
[6]
arXiv preprint arXiv:2310.17513 , year=
The expressive power of low-rank adaptation , author=. arXiv preprint arXiv:2310.17513 , year=
-
[7]
Transactions on Machine Learning Research , issn=
Task Diversity Shortens the In-Context Learning Plateau , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[8]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Fine-grained Analysis of In-context Linear Estimation: Data, Architecture, and Beyond , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[9]
Statistics & Probability Letters , volume=
Multiplying a Gaussian matrix by a Gaussian vector , author=. Statistics & Probability Letters , volume=. 2017 , publisher=
2017
-
[10]
Technical University of Denmark , volume=
The matrix cookbook , author=. Technical University of Denmark , volume=
-
[11]
Journal of Machine Learning Research , volume=
Trained transformers learn linear models in-context , author=. Journal of Machine Learning Research , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Pretrained transformer efficiently learns low-dimensional target functions in-context , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
In-Context Learning with Representations: Contextual Generalization of Trained Transformers , url =
Yang, Tong and Huang, Yu and Liang, Yingbin and Chi, Yuejie , booktitle =. In-Context Learning with Representations: Contextual Generalization of Trained Transformers , url =
-
[14]
Forty-second International Conference on Machine Learning , year =
Training Dynamics of In-Context Learning in Linear Attention , author=. Forty-second International Conference on Machine Learning , year =
-
[15]
The Thirteenth International Conference on Learning Representations , year=
Can In-context Learning Really Generalize to Out-of-distribution Tasks? , author=. The Thirteenth International Conference on Learning Representations , year=
-
[16]
Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in
Angelica Chen and Ravid Shwartz-Ziv and Kyunghyun Cho and Matthew L Leavitt and Naomi Saphra , booktitle=. Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in. 2024 , url=
2024
-
[17]
Abrupt Learning in Transformers: A Case Study on Matrix Completion , volume =
Gopalani, Pulkit and Lubana, Ekdeep Singh and Hu, Wei , booktitle =. Abrupt Learning in Transformers: A Case Study on Matrix Completion , volume =
-
[18]
Yue M. Lu and Mary Letey and Jacob A. Zavatone-Veth and Anindita Maiti and Cengiz Pehlevan , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.2502599122 , abstract =
-
[19]
The Twelfth International Conference on Learning Representations , year=
Linear attention is (maybe) all you need (to understand Transformer optimization) , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
International Conference on Machine Learning , pages=
Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[21]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[22]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[23]
Patti and Jayson Lynch and Avi Shporer and Nakul Verma and Eugene Wu and Gilbert Strang , title =
Iddo Drori and Sarah Zhang and Reece Shuttleworth and Leonard Tang and Albert Lu and Elizabeth Ke and Kevin Liu and Linda Chen and Sunny Tran and Newman Cheng and Roman Wang and Nikhil Singh and Taylor L. Patti and Jayson Lynch and Avi Shporer and Nakul Verma and Eugene Wu and Gilbert Strang , title =. Proceedings of the National Academy of Sciences , vol...
-
[24]
Proceedings of the 40th International Conference on Machine Learning , pages =
Transformers as Algorithms: Generalization and Stability in In-context Learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[25]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
-
[26]
What Can Transformers Learn In-Context?
Shivam Garg and Dimitris Tsipras and Percy Liang and Gregory Valiant , booktitle=. What Can Transformers Learn In-Context?. 2022 , url=
2022
-
[27]
Advances in Neural Information Processing Systems , volume=
Transformers learn to implement preconditioned gradient descent for in-context learning , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
The Twelfth International Conference on Learning Representations , year=
One Step of Gradient Descent is Provably the Optimal In-Context Learner with One Layer of Linear Self-Attention , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
International Conference on Machine Learning , pages=
Transformers learn in-context by gradient descent , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[30]
Advances in neural information processing systems , volume=
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression , author=. Advances in neural information processing systems , volume=
-
[31]
The Eleventh International Conference on Learning Representations , year=
What learning algorithm is in-context learning? investigations with linear models , author=. The Eleventh International Conference on Learning Representations , year=
-
[32]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[33]
arXiv preprint arXiv:2311.00871 , year=
Pretraining data mixtures enable narrow model selection capabilities in transformer models , author=. arXiv preprint arXiv:2311.00871 , year=
-
[34]
arXiv preprint arXiv:2305.16704 , year=
A closer look at in-context learning under distribution shifts , author=. arXiv preprint arXiv:2305.16704 , year=
-
[35]
NeurIPS 2024 Workshop on Compositional Learning: Perspectives, Methods, and Paths Forward , year=
Transformers Can Learn Meta-skills for Task Generalization in In-Context Learning , author=. NeurIPS 2024 Workshop on Compositional Learning: Perspectives, Methods, and Paths Forward , year=
2024
-
[36]
International Conference on Machine Learning , pages=
How Do Nonlinear Transformers Learn and Generalize in In-Context Learning? , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[37]
International Conference on Machine Learning , pages=
In-context Convergence of Transformers , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[38]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Revisiting the equivalence of in-context learning and gradient descent: The impact of data distribution , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[39]
The 61st Annual Meeting Of The Association For Computational Linguistics , year=
What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning , author=. The 61st Annual Meeting Of The Association For Computational Linguistics , year=
-
[40]
The Twelfth International Conference on Learning Representations , year=
In-Context Learning Learns Label Relationships but Is Not Conventional Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[41]
Advances in Neural Information Processing Systems , volume=
In-context learning of a linear transformer block: benefits of the mlp component and one-step gd initialization , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[43]
Forty-first International Conference on Machine Learning , year=
Can Looped Transformers Learn to Implement Multi-step Gradient Descent for In-context Learning? , author=. Forty-first International Conference on Machine Learning , year=
-
[44]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[45]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
Efficient Low-Dimensional Compression of Overparameterized Models , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , volume =
2024
-
[46]
IEEE Signal Processing Magazine , title =
Vidal, Ren. IEEE Signal Processing Magazine , title =. 2011 , number =
2011
-
[47]
Advances in neural information processing systems , volume=
Transformers as statisticians: Provable in-context learning with in-context algorithm selection , author=. Advances in neural information processing systems , volume=
-
[48]
Transformers Meet In-Context Learning: A Universal Approximation Theory , author=
-
[49]
arXiv preprint arXiv:2409.02426 , year=
Diffusion Models Learn Low-Dimensional Distributions via Subspace Clustering , author=. arXiv preprint arXiv:2409.02426 , year=
-
[50]
arXiv preprint arXiv:2501.02364 , year=
Understanding How Nonlinear Layers Create Linearly Separable Features for Low-Dimensional Data , author=. arXiv preprint arXiv:2501.02364 , year=
-
[51]
Forty-second International Conference on Machine Learning , year=
Test-Time Training Provably Improves Transformers as In-context Learners , author=. Forty-second International Conference on Machine Learning , year=
-
[52]
Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages =
Provable Benefits of Task-Specific Prompts for In-context Learning , author =. Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages =. 2025 , editor =
2025
-
[53]
The Twelfth International Conference on Learning Representations , year=
How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression? , author=. The Twelfth International Conference on Learning Representations , year=
-
[54]
Forty-first International Conference on Machine Learning , year=
A Global Geometric Analysis of Maximal Coding Rate Reduction , author=. Forty-first International Conference on Machine Learning , year=
-
[55]
The Thirteenth International Conference on Learning Representations , year=
Learning Dynamics of Deep Matrix Factorization Beyond the Edge of Stability , author=. The Thirteenth International Conference on Learning Representations , year=
-
[56]
arXiv preprint arXiv:2503.19859 , year=
An Overview of Low-Rank Structures in the Training and Adaptation of Large Models , author=. arXiv preprint arXiv:2503.19859 , year=
-
[57]
Wang, Zengzhi and Xie, Qiming and Feng, Yi and Ding, Zixiang and Yang, Zinong and Xia, Rui , booktitle=. Is
-
[58]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Improving In-Context Learning with Prediction Feedback for Sentiment Analysis , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[59]
Transactions of the Association for Computational Linguistics , volume=
Retrieval-style In-context Learning for Few-shot Hierarchical Text Classification , author=. Transactions of the Association for Computational Linguistics , volume=
-
[60]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
In-context Examples Selection for Machine Translation , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[61]
arXiv preprint arXiv:2211.09102 , year=
Prompting palm for translation: Assessing strategies and performance , author=. arXiv preprint arXiv:2211.09102 , year=
-
[62]
Forty-second International Conference on Machine Learning , year=
When can in-context learning generalize out of task distribution? , author=. Forty-second International Conference on Machine Learning , year=
-
[63]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Evaluating In-Context Learning of Libraries for Code Generation , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[64]
ACM Transactions on Software Engineering and Methodology , year=
Large language model-aware in-context learning for code generation , author=. ACM Transactions on Software Engineering and Methodology , year=
-
[65]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[66]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Automated program repair in the era of large pre-trained language models , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
2023
-
[67]
Acta Applicandae Mathematica , volume=
Riemannian geometry of Grassmann manifolds with a view on algorithmic computation , author=. Acta Applicandae Mathematica , volume=. 2004 , publisher=
2004
-
[68]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[69]
2020 , journal=
Scaling Laws for Neural Language Models , author=. 2020 , journal=
2020
-
[70]
Thirty-seventh Conference on Neural Information Processing Systems , year=
On the spectral bias of two-layer linear networks , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[71]
The 29th International Conference on Artificial Intelligence and Statistics , year=
Out-of-Distribution Generalization of In-Context Learning: A Low-Dimensional Subspace Perspective , author=. The 29th International Conference on Artificial Intelligence and Statistics , year=
-
[72]
2022 , journal=
Saddle-to-Saddle Dynamics in Deep Linear Networks: Small Initialization Training, Symmetry, and Sparsity , author=. 2022 , journal=
2022
-
[73]
The Thirteenth International Conference on Learning Representations , year=
From Lazy to Rich: Exact Learning Dynamics in Deep Linear Networks , author=. The Thirteenth International Conference on Learning Representations , year=
-
[74]
International Conference on Learning Representations , year=
The Implicit Bias of Depth: How Incremental Learning Drives Generalization , author=. International Conference on Learning Representations , year=
-
[75]
Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction , url =
St\". Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction , url =. Advances in Neural Information Processing Systems , editor =
-
[76]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
Efficient Low-Dimensional Compression of Overparameterized Models , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , editor =
2024
-
[77]
International Conference on Learning Representations , year=
Towards Resolving the Implicit Bias of Gradient Descent for Matrix Factorization: Greedy Low-Rank Learning , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.