AdaGRPO: A Capability-Aware Adaptive Enhancement for Flow-based GRPO
Pith reviewed 2026-06-27 22:52 UTC · model grok-4.3
The pith
AdaGRPO corrects capability-blind spots in GRPO for flow-based text-to-image models through adaptive prompt selection and advantage fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
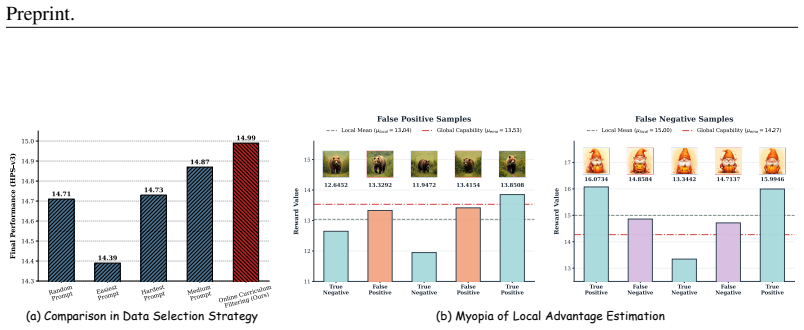
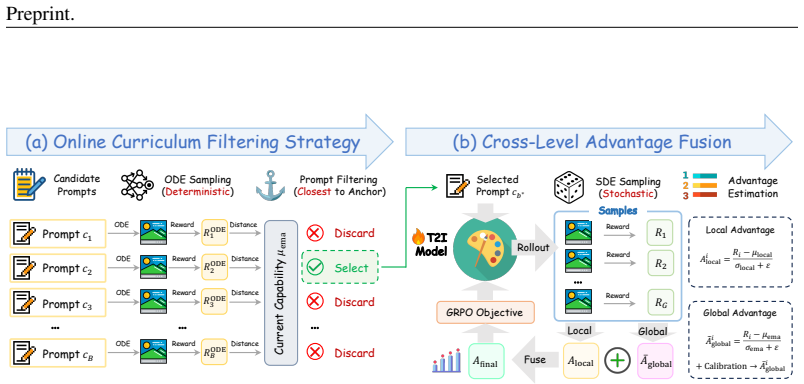
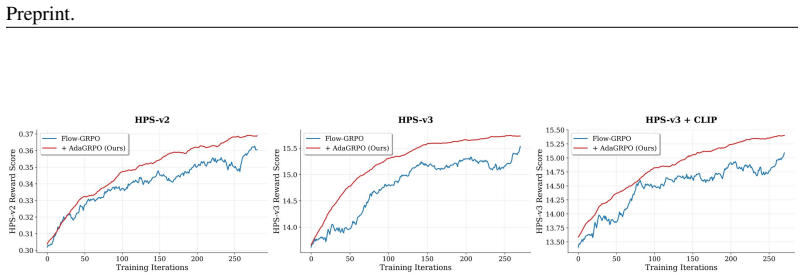
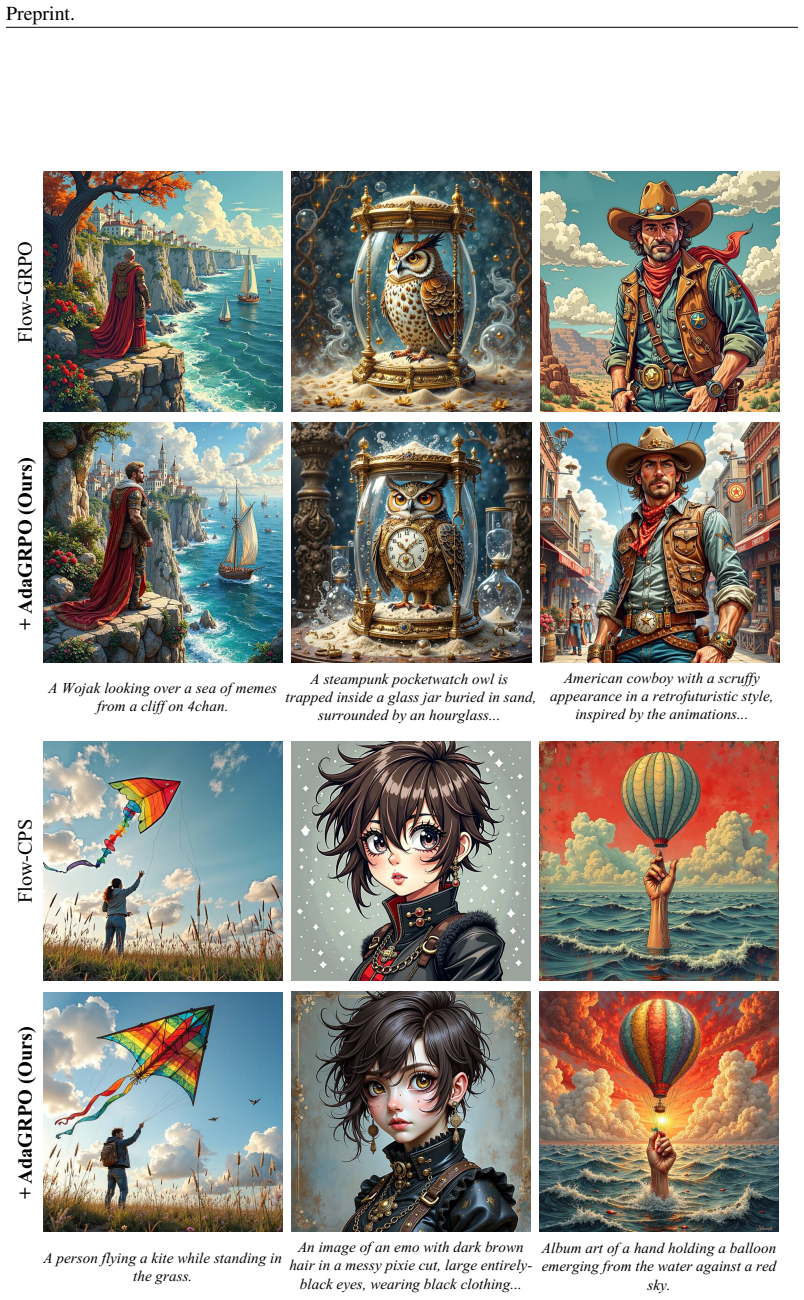
AdaGRPO is a capability-aware RL algorithm for flow models that uses an Online Curriculum Filtering Strategy to dynamically select prompts matching the model's proficiency and a Cross-Level Advantage Fusion to combine intra-group and global advantages, serving as a lightweight plug-in that boosts performance and stabilizes training when added to existing flow-based GRPO frameworks.
What carries the argument
The combination of Online Curriculum Filtering Strategy, which tracks model proficiency to select boundary-matching prompts, and Cross-Level Advantage Fusion, which integrates fine-grained intra-group with macro-level global advantages for unbiased evaluation.
If this is right
- Consistent performance improvements in text-to-image flow model alignment.
- Significantly more stable GRPO training dynamics.
- Easy integration into frameworks like Flow-GRPO, DanceGRPO, and Flow-CPS.
- Addresses both prompt selection and advantage estimation issues in flow model RL.
Where Pith is reading between the lines
- Similar capability-aware adaptations could benefit RL alignment in other generative architectures.
- The global advantage component may help identify when local statistics mislead about true progress.
- Dynamic filtering might reduce overall training compute by avoiding mismatched data.
Load-bearing premise
Dynamically tracking the model's proficiency and combining intra-group with global advantages produces unbiased improvements without adding new biases or instability to the reinforcement learning process.
What would settle it
Comparative training runs on standard text-to-image preference benchmarks showing that AdaGRPO versions do not outperform or stabilize better than standard GRPO baselines.
Figures












read the original abstract
Group Relative Policy Optimization (GRPO) has demonstrated remarkable success in aligning text-to-image (T2I) flow models with human preferences. However, we have identified that the learning loop of current flow-based GRPO is fundamentally decoupled from the learner's current capability, suffering from critical blind spots at both prompt selection and advantage estimation: (i) Existing methods sample prompts randomly, overlooking the substantial impact of data selection on reinforcement learning (RL) efficacy--a factor proven crucial in GRPO for large language models; (ii) They evaluate sample quality solely relying on intra-group statistics, lacking a global perspective to accurately measure true policy improvement. To address these issues, we propose Adaptive GRPO (AdaGRPO), a novel capability-aware RL algorithm tailored for flow models. Specifically, AdaGRPO consists of two principal components: (i) Online Curriculum Filtering Strategy: Dynamically tracks the model's proficiency and adaptively selects prompts that best match its current learning boundary; (ii) Cross-Level Advantage Fusion: Synergistically integrates fine-grained intra-group advantages with macro-level global advantages, providing a comprehensive and unbiased policy evaluation. As a lightweight, plug-and-play module, AdaGRPO can be seamlessly integrated with existing frameworks such as Flow-GRPO, DanceGRPO, and Flow-CPS. Extensive experiments demonstrate that AdaGRPO consistently drives performance gains while significantly stabilizes GRPO training for flow models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaGRPO as a capability-aware enhancement to Group Relative Policy Optimization (GRPO) for aligning flow-based text-to-image models. It identifies two blind spots in existing flow-based GRPO: random prompt sampling that ignores learner proficiency and advantage estimation based solely on intra-group statistics without a global view. AdaGRPO introduces an Online Curriculum Filtering Strategy to dynamically select boundary-matching prompts and Cross-Level Advantage Fusion to combine intra-group and global advantages. The method is presented as a lightweight, plug-and-play module compatible with frameworks such as Flow-GRPO, DanceGRPO, and Flow-CPS, with experiments claimed to demonstrate consistent performance gains and improved training stability.
Significance. If the claimed results hold, the work could improve sample efficiency and stability in RL fine-tuning of flow models by making the training loop adaptive to current model capability. The two proposed mechanisms directly target known issues in prompt selection and advantage estimation that affect RL efficacy, and the plug-and-play design would allow easy adoption in existing pipelines for preference alignment in generative models.
minor comments (1)
- [Abstract] Abstract: the claim of 'extensive experiments demonstrate that AdaGRPO consistently drives performance gains while significantly stabilizes GRPO training' is stated without any quantitative metrics, baselines, ablation results, or protocol details, which weakens the ability to evaluate the central empirical claim from the summary alone.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work on AdaGRPO and for recommending minor revision. The referee's summary correctly identifies the core issues addressed and the plug-and-play nature of the proposed method. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or mathematical claims. The method is introduced descriptively as two components (online curriculum filtering and cross-level advantage fusion) without any reduction of predictions to inputs by construction, self-citation chains, or ansatz smuggling. Performance and stability claims are presented as experimental outcomes rather than derived results that collapse to the inputs. This is a standard non-finding for a methods paper lacking visible derivation structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jiazi Bu, Pengyang Ling, Yujie Zhou, Pan Zhang, Tong Wu, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Hiflow: Training-free high-resolution image generation with flow-aligned guidance.arXiv preprint arXiv:2504.06232,
-
[3]
Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Tianyi Wei, Xiaohang Zhan, Jiaqi Wang, Tong Wu, Xingang Pan, et al. From sparse to dense: Multi-view grpo for flow models via augmented condition space.arXiv preprint arXiv:2603.12648,
-
[4]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Dynamic-TreeRPO: Breaking the Independent Trajectory Bottleneck with Structured Sampling
Xiaolong Fu, Lichen Ma, Zipeng Guo, Gaojing Zhou, Chongxiao Wang, ShiPing Dong, Shizhe Zhou, Ximan Liu, Jingling Fu, Tan Lit Sin, et al. Dynamic-treerpo: Breaking the independent trajectory bottleneck with structured sampling.arXiv preprint arXiv:2509.23352,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang. Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025a. Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured branching in diffusion model...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Yixiu Mao, Yun Qu, Qi Wang, Heming Zou, and Xiangyang Ji. Dynamics-predictive sampling for active rl finetuning of large reasoning models.arXiv preprint arXiv:2603.10887,
-
[13]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation.arXiv preprint arXiv:2407.02371,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Liang Peng, Boxi Wu, Haoran Cheng, Yibo Zhao, and Xiaofei He. Sudo: Enhancing text-to- image diffusion models with self-supervised direct preference optimization.arXiv preprint arXiv:2504.14534,
-
[15]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Bots: A unified framework for bayesian online task selection in llm reinforcement finetuning
Qianli Shen, Daoyuan Chen, Yilun Huang, Zhenqing Ling, Yaliang Li, Bolin Ding, and Jingren Zhou. Bots: A unified framework for bayesian online task selection in llm reinforcement finetuning. arXiv preprint arXiv:2510.26374,
-
[19]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020a. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. Petru Soviany, Radu T...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[20]
Longcat-video technical report.arXiv preprint arXiv:2510.22200,
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report.arXiv preprint arXiv:2510.22200,
-
[21]
HunyuanVideo 1.5 Technical Report
URL https: //arxiv.org/abs/2511.18870. Georgios Tzannetos, Bárbara Gomes Ribeiro, Parameswaran Kamalaruban, and Adish Singla. Proxi- mal curriculum for reinforcement learning agents.arXiv preprint arXiv:2304.12877,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Feng Wang and Zihao Yu. Coefficients-preserving sampling for reinforcement learning with flow matching.arXiv preprint arXiv:2509.05952,
-
[24]
Yibin Wang, Zhimin Li, Yuhang Zang, Jiazi Bu, Yujie Zhou, Yi Xin, Junjun He, Chunyu Wang, Qinglin Lu, Cheng Jin, et al. Unigenbench++: A unified semantic evaluation benchmark for text-to-image generation.arXiv preprint arXiv:2510.18701, 2025a. Yibin Wang, Zhimin Li, Yuhang Zang, Yujie Zhou, Jiazi Bu, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Pre...
-
[25]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Xiaojiang Zhang, Jinghui Wang, Zifei Cheng, Wenhao Zhuang, Zheng Lin, Minglei Zhang, Shaojie Wang, Yinghan Cui, Chao Wang, Junyi Peng, et al. Srpo: A cross-domain implementation of large-scale reinforcement learning on llm.arXiv preprint arXiv:2504.14286,
-
[30]
Haizhong Zheng, Yang Zhou, Brian R Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts.arXiv preprint arXiv:2506.02177, 2025a. Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and ...
-
[31]
Generate a game concept setting diagram: a huge turtle carries a small castle on its back, which serves as a mobile base for players and travels through the fantasy forest
F LIMITATION ANDDISCUSSION While AdaGRPO demonstrates superior performance and training stability, it faces certain constraints. Similar to dynamic data sampling strategies in LLM alignment (Yu et al., 2025; Bae et al., 2026), our online prompt filtering mechanism inevitably introduces some computational overhead. However, given the relatively modest VRAM...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.