STRIPS-WM: Learning Grounded Propositional STRIPS-style World Models from Images
Pith reviewed 2026-06-27 22:09 UTC · model grok-4.3
The pith
STRIPS-WM learns latent binary predicates and propositional operators from image transitions to support classical planning from new start and goal images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
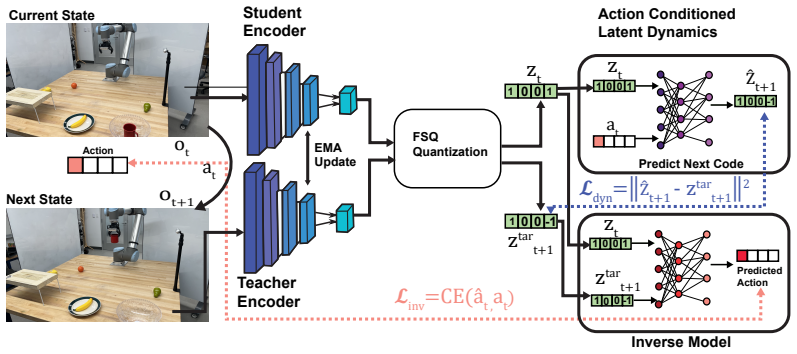
STRIPS-WM induces a finite abstract transition graph from images, learns latent binary predicates and one grounded propositional operator per action label that form a symbolic action model with sparse preconditions and add/delete effects, then distills the predicates into a visual encoder that enables classical planning directly from novel start and goal images.
What carries the argument
The grounded propositional STRIPS-style world model consisting of latent binary predicates and learned operators extracted from visual transitions.
If this is right
- Classical planners operate directly on image inputs without requiring visual rollouts or latent-space search.
- The learned operators produce sparse, interpretable preconditions and effects for each action label.
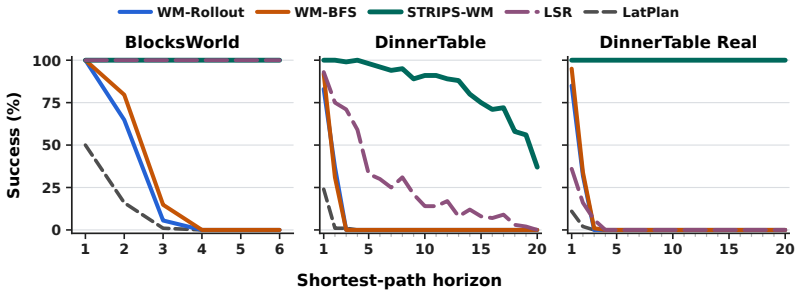
- Planning performance improves over tested visual, latent-graph, and latent-symbolic methods on rearrangement tasks.
Where Pith is reading between the lines
- The predicates might transfer to new scenes if the visual encoder generalizes beyond the training distribution.
- The method could reduce reliance on manually designed symbolic models when deploying planners in visual robotics settings.
- Similar induction of abstract graphs and predicates might apply to other high-dimensional observation spaces such as point clouds.
Load-bearing premise
A finite abstract transition graph can be reliably induced from raw image transitions such that the resulting latent binary predicates capture action applicability and effects well enough for classical planning on unseen images.
What would settle it
Running the learned planner on held-out image pairs from the rearrangement tasks and finding that success rates fall below those of the visual rollout baseline would show the induced model does not support the claimed planning improvement.
Figures


read the original abstract
Robots performing long-horizon visual manipulation observe high-dimensional images, but successful plans depend on action-relevant facts: what can be done now and what changes afterward. A useful planning representation should discard irrelevant visual details while preserving action applicability and effects. Classical task planners exploit this structure through symbolic operators with preconditions and effects, but obtaining such representations from raw visual experience remains challenging. We study a visual task-planning setting in which a robot receives only image transitions: the current image, executed high-level action, and the resulting image. At test time, given a start image and a goal image, the robot must produce a sequence of high-level actions that reaches the goal. To address this problem, we introduce STRIPS-WM, a framework for learning image-grounded STRIPS-style world models directly from visual transitions. STRIPS-WM first induces a finite abstract transition graph from images, then learns latent binary predicates and one grounded propositional operator per action label. The learned operators form a symbolic action model with sparse preconditions and add/delete effects. Finally, the learned predicates are distilled into a visual encoder, enabling classical planning directly from novel start and goal images. Experiments on visual rearrangement tasks show that STRIPS-WM improves image-to-plan success over the tested visual rollout, latent graph-search and latent-symbolic baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STRIPS-WM, a framework for learning image-grounded STRIPS-style world models from visual transitions. It first induces a finite abstract transition graph from images, then learns latent binary predicates and one grounded propositional operator per action label with sparse preconditions and add/delete effects. These predicates are distilled into a visual encoder to enable classical planning directly from novel start and goal images. Experiments on visual rearrangement tasks are claimed to show improved image-to-plan success over visual rollout, latent graph-search, and latent-symbolic baselines.
Significance. If the central empirical claim holds, the work would demonstrate a viable pipeline for inducing symbolic planning operators directly from raw image transitions, bridging high-dimensional visual input with classical task planning in robotics. The explicit grounding of predicates and operators, together with the use of an off-the-shelf planner at test time, would be a concrete contribution to visual task planning.
major comments (2)
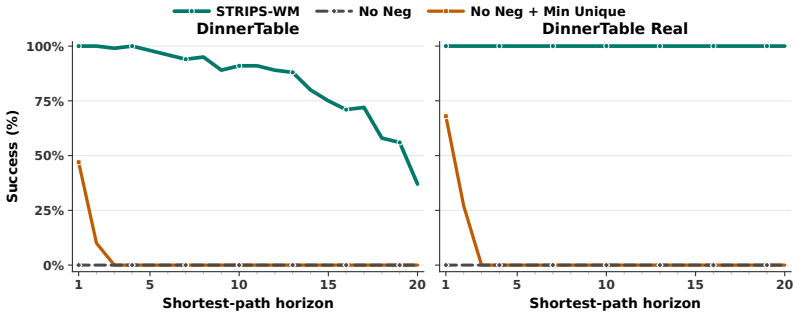
- [Abstract, §3] Abstract and §3 (method overview): the induction procedure for the finite abstract transition graph is described only at a high level; no information is given on the clustering criterion, embedding function, or termination condition. Because the subsequent predicate-learning step relies on action applicability and effects being consistent within each abstract state, the absence of these details leaves open the possibility that state aliasing or combinatorial blow-up will invalidate the downstream classical planning step on unseen images.
- [Abstract] Abstract (experiments paragraph): the claim that STRIPS-WM improves image-to-plan success is stated without any quantitative results, baseline implementation details, dataset description, number of trials, or statistical tests. This information is load-bearing for the central empirical claim and cannot be assessed from the provided text.
minor comments (1)
- Notation for the latent predicates and operators is introduced without an explicit table or running example that shows how a concrete image transition maps to a precondition/effect tuple.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method overview): the induction procedure for the finite abstract transition graph is described only at a high level; no information is given on the clustering criterion, embedding function, or termination condition. Because the subsequent predicate-learning step relies on action applicability and effects being consistent within each abstract state, the absence of these details leaves open the possibility that state aliasing or combinatorial blow-up will invalidate the downstream classical planning step on unseen images.
Authors: We agree the abstract and high-level overview in §3 are concise. The full details of the induction procedure (including the embedding function, clustering criterion, and termination condition) appear in Section 3.1 of the manuscript. To improve accessibility we will expand the method overview paragraph to restate these elements explicitly and add a short discussion of how predicate learning enforces consistency, thereby addressing concerns about aliasing and blow-up. The empirical results in Section 5 provide evidence that the learned model supports successful planning on unseen images. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): the claim that STRIPS-WM improves image-to-plan success is stated without any quantitative results, baseline implementation details, dataset description, number of trials, or statistical tests. This information is load-bearing for the central empirical claim and cannot be assessed from the provided text.
Authors: Abstracts conventionally summarize results at a qualitative level for brevity. All requested quantitative details, baseline implementations, dataset description, trial counts, and statistical tests are reported in full in Section 5. We do not believe it is necessary or conventional to embed these specifics in the abstract itself, but we are happy to add a single sentence with key success-rate numbers if the editor prefers. revision: no
Circularity Check
No circularity: data-driven induction and learning pipeline with independent empirical validation
full rationale
The paper presents STRIPS-WM as a sequence of learning steps (induce abstract transition graph from image transitions, learn latent predicates and grounded operators, distill to visual encoder) evaluated via image-to-plan success on rearrangement tasks against baselines. No equations, fitted parameters renamed as predictions, or self-citation chains are described that would reduce the claimed operators or planning performance to the inputs by construction. The approach is explicitly positioned as learning from raw visual experience, with success measured externally on held-out images, satisfying the criteria for a self-contained, non-circular derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ghallab, D
M. Ghallab, D. Nau, and P. Traverso.Automated Planning: theory and practice. Elsevier, 2004
2004
-
[2]
Levine, C
S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research, 17(39):1–40, 2016
2016
-
[3]
G. Konidaris, L. P. Kaelbling, and T. Lozano-Perez. From Skills to Symbols: Learning Symbolic Representations for Abstract High-Level Planning.Journal of Artificial Intelligence Research, 61:215–289, Jan. 2018. ISSN 1076-9757. doi:10.1613/jair.5575. URL https://www.jair. org/index.php/jair/article/view/11175
-
[4]
R. E. Fikes and N. J. Nilsson. Strips: A new approach to the application of theorem proving to problem solving.Artificial intelligence, 2(3-4):189–208, 1971
1971
-
[5]
Yen-Chen, M
L. Yen-Chen, M. Bauza, and P. Isola. Experience-embedded visual foresight. InConference on Robot Learning, pages 1015–1024. PMLR, 2020
2020
-
[6]
Ichter and M
B. Ichter and M. Pavone. Robot motion planning in learned latent spaces.IEEE Robotics and Automation Letters, 4(3):2407–2414, 2019
2019
-
[7]
C. Paxton, Y . Barnoy, K. Katyal, R. Arora, and G. D. Hager. Visual Robot Task Planning. In2019 International Conference on Robotics and Automation (ICRA), pages 8832–8838, May 2019. doi:10.1109/ICRA.2019.8793736. URL https://ieeexplore.ieee.org/ document/8793736/
-
[8]
D. Driess, J.-S. Ha, and M. Toussaint. Deep Visual Reasoning: Learning to Predict Action Sequences for Task and Motion Planning from an Initial Scene Image. InRobotics: Science and Systems XVI. Robotics: Science and Systems Foundation, July 2020. ISBN 978-0-9923747-6-1. doi:10.15607/RSS.2020.XVI.003. URL http://www.roboticsproceedings.org/rss16/ p003.pdf
-
[9]
M. Lippi, P. Poklukar, M. C. Welle, A. Varava, H. Yin, A. Marino, and D. Kragic. Enabling Visual Action Planning for Object Manipulation Through Latent Space Roadmap.IEEE Transactions on Robotics, 39(1):57–75, Feb. 2023. ISSN 1941-0468. doi:10.1109/TRO.2022.3188163. URL https://ieeexplore.ieee.org/document/9833914/
-
[10]
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning Latent Dynamics for Planning from Pixels, June 2019. URL http://arxiv.org/abs/1811.04551. arXiv:1811.04551 [cs]
Pith/arXiv arXiv 2019
-
[11]
Hafner, K.-H
D. Hafner, K.-H. Lee, I. Fischer, and P. Abbeel. Deep hierarchical planning from pixels. Advances in Neural Information Processing Systems, 35:26091–26104, 2022
2022
-
[12]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. In6th Annual Conference on Robot Learning, 2022. URL https: //openreview.net/forum?id=3RBY8fKjHeu
2022
-
[13]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=D5RNACOZEI
2025
-
[14]
In: 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp
C. Chamzas, M. Lippi, M. C. Welle, A. Varava, L. E. Kavraki, and D. Kragic. Comparing reconstruction-and contrastive-based models for visual task planning. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 12550–12557, Oct. 2022. doi:10.1109/ IROS47612.2022.9981533. URL https://doi.org/10.1109/IROS47612.2022.9981533
-
[15]
A. Srinivas, A. Jabri, P. Abbeel, S. Levine, and C. Finn. Universal planning networks, 2018. URLhttps://arxiv.org/abs/1804.00645. 9
Pith/arXiv arXiv 2018
-
[16]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. G. Rabbat, Y . LeCun, and N. Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InCVPR, pages 15619–15629, 2023. URLhttps://doi.org/10.1109/CVPR52729.2023.01499
-
[17]
T. Kipf, E. van der Pol, and M. Welling. Contrastive learning of structured world models, 2020. URLhttps://arxiv.org/abs/1911.12247
arXiv 2020
-
[18]
Laskin, A
M. Laskin, A. Srinivas, and P. Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. InInternational conference on machine learning, pages 5639–5650. PMLR, 2020
2020
-
[19]
G. Konidaris, L. Kaelbling, and T. Lozano-Perez. Constructing Symbolic Representations for High-Level Planning.Proceedings of the AAAI Conference on Artificial Intelligence, 28(1), June 2014. ISSN 2374-3468. doi:10.1609/aaai.v28i1.9004. URL https://ojs.aaai.org/ index.php/AAAI/article/view/9004
-
[20]
Design and evaluation of a hair combing system using a general-purpose robotic arm
T. Silver, R. Chitnis, J. Tenenbaum, L. P. Kaelbling, and T. Lozano-P´erez. Learning Symbolic Operators for Task and Motion Planning. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3182–3189, Sept. 2021. doi:10.1109/IROS51168. 2021.9635941. URL https://ieeexplore.ieee.org/document/9635941/. ISSN: 2153- 0866
-
[21]
Silver, A
T. Silver, A. Athalye, J. B. Tenenbaum, T. Lozano-P ´erez, and L. P. Kaelbling. Learning Neuro-Symbolic Skills for Bilevel Planning. InProceedings of The 6th Conference on Robot Learning, pages 701–714. PMLR, Mar. 2023. URL https://proceedings.mlr.press/ v205/silver23a.html
2023
-
[22]
R. Chitnis, T. Silver, J. B. Tenenbaum, T. Lozano-P´erez, and L. P. Kaelbling. Learning Neuro- Symbolic Relational Transition Models for Bilevel Planning. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4166–4173, Oct. 2022. doi:10.1109/ IROS47612.2022.9981440. URL https://ieeexplore.ieee.org/document/9981440/. ISS...
arXiv 2022
-
[23]
N. Shah, J. Nagpal, P. Verma, and S. Srivastava. From reals to logic and back: Inventing symbolic vocabularies, actions and models for planning from raw data.arXiv preprint arXiv:2402.11871, 2:A14, 2024
arXiv 2024
-
[24]
M. Asai, H. Kajino, A. Fukunaga, and C. Muise. Classical planning in deep latent space.J. Artif. Int. Res., 74, Sept. 2022. ISSN 1076-9757. doi:10.1613/jair.1.13768. URL https: //doi.org/10.1613/jair.1.13768
-
[25]
Perron and F
L. Perron and F. Didier. Cp-sat, 2025. URL https://developers.google.com/ optimization/cp/cp_solver/
2025
-
[26]
B. Bonet and H. Geffner. Learning first-order symbolic representations for planning from the structure of the state space, 2020. URLhttps://arxiv.org/abs/1909.05546
arXiv 2020
-
[27]
Aineto and E
D. Aineto and E. Scala. Action model learning with guarantees. InProceedings of the 21st International Conference on Principles of Knowledge Representation and Reasoning, KR ’24,
-
[28]
ISBN 978-1-956792-05-8. doi:10.24963/kr.2024/75. URL https://doi.org/10. 24963/kr.2024/75
-
[29]
A. Ajith and C. Chamzas. Learning discrete abstractions for visual rearrangement tasks using vision-guided graph coloring, 2026. URLhttps://arxiv.org/abs/2509.14460
arXiv 2026
-
[30]
Bagatella, M
M. Bagatella, M. Olˇs´ak, M. Rol´ınek, and G. Martius. Planning from pixels in environments with combinatorially hard search spaces.Advances in Neural Information Processing Systems, 34:24707–24718, 2021. 10 Appendix A Architecture and Implementation Details This section gives additional implementation details for the three learned components ofS T R I P ...
2021
-
[31]
predicate vectors ˆxˆs∈ {0,1} m for allˆs∈ ˆS, and
-
[32]
grounded propositionalS T R I P Soperators{ˆωa}a∈A over thesempredicates, such that:
-
[33]
every observed edge(ˆs, a,ˆs′)∈ ˆEsatisfies the preconditions ofˆωa at ˆxˆs
-
[34]
every observed edge(ˆs, a,ˆs′)∈ ˆEsatisfies τˆωa(ˆxˆs) = ˆxˆs′
-
[35]
every trusted missing pair(ˆs, a)∈ ˆNis inapplicable in ˆxˆs
-
[36]
18 Proof
every selected distinctness constraint is satisfied. 18 Proof. For the forward direction, suppose the formulation is feasible in the exact regime. By Proposi- tion 7, the induced operators are well-formed grounded propositionalS T R I P Soperators. By Lemma 4, every observed edge satisfies the learned preconditions. By Corollary 3, every observed edge is ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.