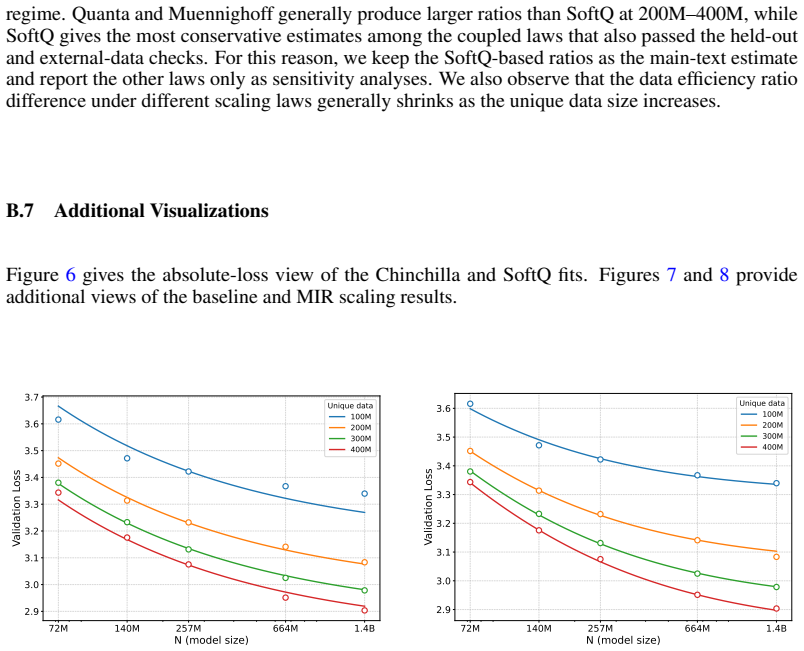
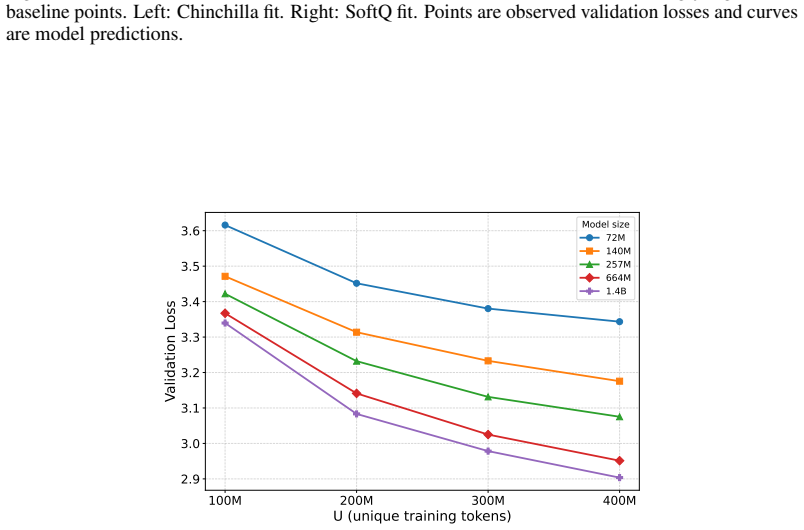
Data-Constrained Language Model Pretraining: Improved Regularization and Scaling Laws
Pith reviewed 2026-06-27 22:21 UTC · model grok-4.3
The pith
Masked-input regularization added to weight decay improves language model validation loss under data constraints, with gains equivalent to 1.3 times more unique data according to the SoftQ scaling law.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
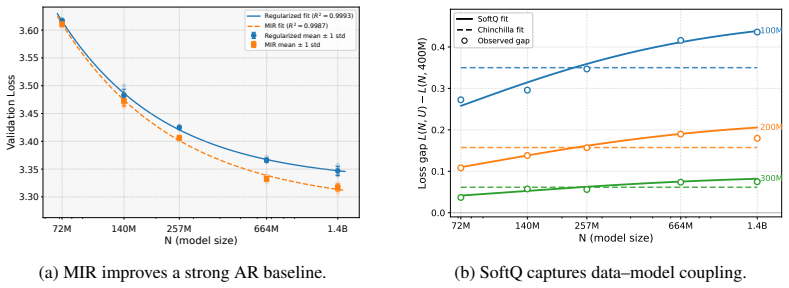
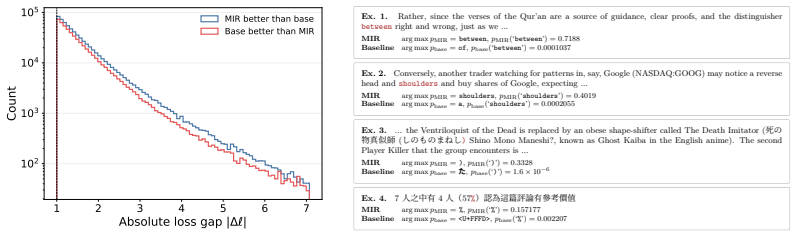
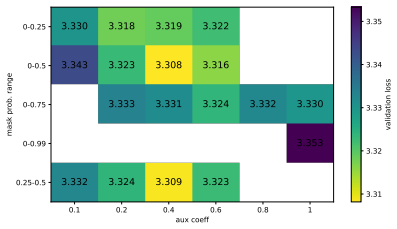
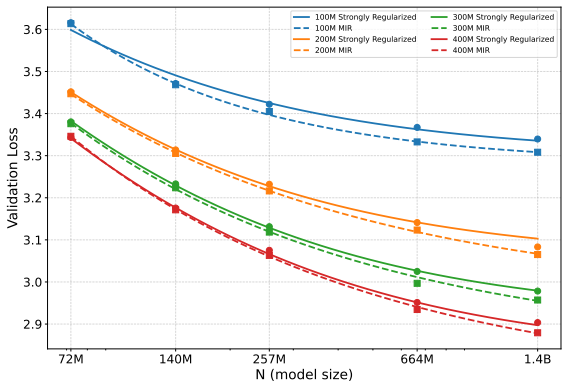
Across 72M to 1.4B parameter models, masked-input regularization added on top of strong weight decay improves validation loss over autoregressive strong-weight-decay-only models, with downstream gains at 1.4B. SoftQ, a scaling law that couples model size and data size to capture their interaction under repeated data, fits data-constrained experiments substantially better than classical alternatives such as the Chinchilla law, and estimates MIR's gains as equivalent to roughly 1.3 times as much unique training data.
What carries the argument
Masked-input regularization (MIR), an auxiliary next-token prediction loss on randomly masked inputs, together with the SoftQ scaling law that couples model size and repeated data size.
If this is right
- MIR added to strong weight decay reduces validation loss relative to weight decay alone across the tested range of model sizes.
- At 1.4B parameters MIR produces measurable gains on downstream tasks.
- SoftQ provides a substantially better fit to data-constrained pretraining runs than additive scaling laws that decouple model size from data repetition.
- The regularization improvement can be read as equivalent to training on 1.3 times as much unique data.
Where Pith is reading between the lines
- Regularization methods originally developed for diffusion models can transfer to standard autoregressive training without requiring architecture changes or extra inference cost.
- Coupled scaling laws may help practitioners decide how many epochs to run when the supply of unique text is fixed.
- The same regularization and scaling approach could be tested in other data-scarce domains such as code or multimodal training.
Load-bearing premise
The functional form of SoftQ correctly captures the interaction between model size and repeated data passes rather than merely fitting the specific experimental conditions tested.
What would settle it
Measuring whether the performance lift from MIR on a new model size or repetition count exactly matches the 1.3 times unique-data multiplier predicted by the SoftQ fit on the original experiments.
Figures

read the original abstract
Classical scaling laws for language model pretraining balance model size against training dataset size under a fixed compute budget, assuming abundant data and a single pass over the corpus. As training compute grows faster than the supply of natural language data, pretraining is likely to enter a data-constrained, compute-rich regime where models train for multiple epochs over a finite dataset. We study data-constrained pretraining along two axes, regularization and scaling. For regularization, we study masked-input regularization (MIR), an auxiliary next-token prediction loss on randomly masked inputs. MIR tests whether the random masking central to diffusion language models can benefit autoregressive pretraining without architectural changes or inference overhead. Across 72M to 1.4B parameter models, we find that MIR added on top of strong weight decay improves validation loss over autoregressive strong-weight-decay-only models, with downstream gains at 1.4B. For scaling, we propose SoftQ, a scaling law that couples model size and data size to capture their interaction under repeated data. Classical alternatives such as the Chinchilla law use an additive form that decouples these terms, making them misspecified in the data-constrained regime. We find that SoftQ fits data-constrained experiments substantially better than these alternatives, and estimates MIR's gains as equivalent to roughly 1.3 times as much unique training data. We release our code at https://github.com/yixinw-lab/dc_pretrain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines data-constrained language model pretraining in the regime of repeated passes over finite data. It introduces masked-input regularization (MIR), an auxiliary next-token loss on randomly masked inputs, and reports that MIR on top of strong weight decay improves validation loss over weight-decay-only baselines across 72M–1.4B models, with downstream gains at 1.4B. It further proposes the SoftQ scaling law, which couples model size N and effective data D under repetition, and claims that SoftQ fits the data-constrained experiments substantially better than additive alternatives such as the Chinchilla law, with MIR gains estimated as equivalent to roughly 1.3× unique training data. Code is released.
Significance. If the empirical claims hold after addressing experimental reporting and validation details, the work is significant for the emerging data-limited pretraining regime. The code release is a clear strength that supports reproducibility. The reported downstream gains at 1.4B and the proposed functional form for repeated-data scaling could inform practical regularization and compute allocation decisions.
major comments (3)
- [Abstract / scaling laws] Abstract and scaling-law section: SoftQ parameters are fitted directly to the same data-constrained runs used to assert superior fit and to derive the 1.3× data-equivalence claim for MIR; this renders the validation of the functional form partially circular, as the claimed advantage over additive forms is not tested on held-out repetition regimes or larger scales.
- [MIR experiments] Experimental results (MIR section): the central claim of consistent validation-loss improvement and downstream gains rests on comparisons whose statistical support is not detailed—no run counts, error bars, significance tests, or exact data-exclusion rules are provided, making it impossible to assess whether the reported gains are robust or load-bearing.
- [scaling laws / SoftQ fit] Scaling-law validation: the claim that SoftQ correctly captures the N–D interaction under repetition (rather than providing extra degrees of freedom that fit the tested 72M–1.4B, limited-epoch regime) is not supported by out-of-distribution tests or comparison against other flexible functional forms; the 1.3× equivalence therefore inherits the same limitation.
minor comments (3)
- [scaling laws] Notation for effective data D under repetition should be defined explicitly before the SoftQ equation to avoid ambiguity with the classical D term.
- [figures] Figure captions for loss curves should state the number of independent runs and whether shaded regions represent standard error or min/max.
- [code release] The GitHub link is given but the manuscript does not specify which exact scripts reproduce the SoftQ parameter fits and the 1.3× calculation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We agree that additional statistical reporting and independent validation of the scaling law are required to support the claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / scaling laws] Abstract and scaling-law section: SoftQ parameters are fitted directly to the same data-constrained runs used to assert superior fit and to derive the 1.3× data-equivalence claim for MIR; this renders the validation of the functional form partially circular, as the claimed advantage over additive forms is not tested on held-out repetition regimes or larger scales.
Authors: We agree the current validation is partially circular because SoftQ parameters are fit to the same runs used to evaluate fit quality and the MIR equivalence claim. The functional form itself was derived from modeling the interaction between model size and effective data under repetition (rather than chosen purely for flexibility). In revision we will add held-out repetition schedules, cross-validation across different epoch counts, and explicit comparisons against other flexible functional forms with similar parameter counts to test whether the advantage holds out of sample. revision: yes
-
Referee: [MIR experiments] Experimental results (MIR section): the central claim of consistent validation-loss improvement and downstream gains rests on comparisons whose statistical support is not detailed—no run counts, error bars, significance tests, or exact data-exclusion rules are provided, making it impossible to assess whether the reported gains are robust or load-bearing.
Authors: The referee correctly notes that the manuscript omits run counts, error bars, significance tests, and precise data-exclusion criteria. We will revise the experimental section to report the number of independent random seeds, include error bars or shaded regions on all loss curves, state the exact data filtering rules, and add statistical significance tests for the reported validation and downstream improvements. revision: yes
-
Referee: [scaling laws / SoftQ fit] Scaling-law validation: the claim that SoftQ correctly captures the N–D interaction under repetition (rather than providing extra degrees of freedom that fit the tested 72M–1.4B, limited-epoch regime) is not supported by out-of-distribution tests or comparison against other flexible functional forms; the 1.3× equivalence therefore inherits the same limitation.
Authors: We acknowledge the absence of out-of-distribution tests at scales or repetition regimes beyond the reported 72M–1.4B range. In the revision we will (i) compare SoftQ against additional flexible functional forms with comparable degrees of freedom and (ii) expand the limitations paragraph to explicitly discuss the tested regime. The form remains motivated by the multiplicative interaction between model capacity and repeated data rather than being an arbitrary fit; the 1.3× claim will be presented with the corresponding caveats. revision: partial
Circularity Check
SoftQ parameters fitted to data-constrained runs; 1.3x data equivalence derived directly from that fit
specific steps
-
fitted input called prediction
[Abstract]
"We find that SoftQ fits data-constrained experiments substantially better than these alternatives, and estimates MIR's gains as equivalent to roughly 1.3 times as much unique training data."
SoftQ functional parameters are obtained by fitting to the identical data-constrained experimental points; the 1.3x equivalence is then computed from those same fitted parameters, so the reported gain is a direct algebraic consequence of the fit rather than a separate prediction or external validation.
full rationale
The paper proposes SoftQ as a coupled scaling law, fits its parameters to the same 72M–1.4B data-constrained experiments used to demonstrate superior fit over Chinchilla-style additive forms, and then extracts the MIR gain as 'roughly 1.3 times as much unique training data' from those fitted parameters. This reduces the claimed equivalence and the superiority claim to a direct output of the fit on the target data rather than an independent derivation or out-of-sample prediction. No other circular steps (self-citation chains, self-definitional terms, or imported uniqueness theorems) are present; the regularization results on MIR appear independent of the scaling-law fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- SoftQ scaling law parameters
axioms (1)
- domain assumption The interaction between model size and data repetition in the data-constrained regime is captured by a coupled functional form rather than an additive one.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.04071 , year=
What Makes Diffusion Language Models Super Data Learners? , author=. arXiv preprint arXiv:2510.04071 , year=
-
[2]
arXiv preprint arXiv:2604.03444 , year=
Olmo hybrid: From theory to practice and back , author=. arXiv preprint arXiv:2604.03444 , year=
-
[3]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[5]
Lewis, Mike and Liu, Yinhan and Goyal, Naman and Ghazvininejad, Marjan and Mohamed, Abdelrahman and Levy, Omer and Stoyanov, Veselin and Zettlemoyer, Luke. BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguisti...
-
[6]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[7]
Token Drop mechanism for Neural Machine Translation
Zhang, Huaao and Qiu, Shigui and Duan, Xiangyu and Zhang, Min. Token Drop mechanism for Neural Machine Translation. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.379
-
[8]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Mask-Enhanced Autoregressive Prediction: Pay Less Attention to Learn More , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[9]
arXiv preprint arXiv:1712.00409 , year=
Deep learning scaling is predictable, empirically , author=. arXiv preprint arXiv:1712.00409 , year=
-
[10]
International Conference on Learning Representations , year=
A Constructive Prediction of the Generalization Error Across Scales , author=. International Conference on Learning Representations , year=
-
[11]
arXiv preprint arXiv:2010.14701 , year=
Scaling laws for autoregressive generative modeling , author=. arXiv preprint arXiv:2010.14701 , year=
Pith/arXiv arXiv 2010
-
[12]
arXiv preprint arXiv:2603.18534 , year=
Data-efficient pre-training by scaling synthetic megadocs , author=. arXiv preprint arXiv:2603.18534 , year=
-
[13]
arXiv preprint arXiv:2512.23422 , year=
Entropy-Guided Token Dropout: Training Autoregressive Language Models with Limited Domain Data , author=. arXiv preprint arXiv:2512.23422 , year=
-
[14]
arXiv preprint arXiv:2211.04325 , year=
Will we run out of data? Limits of LLM scaling based on human-generated data , author=. arXiv preprint arXiv:2211.04325 , year=
-
[15]
Jaime Sevilla and Edu Roldán , year=
-
[16]
Learning Mechanics , url =
On neural scaling and the quanta hypothesis , author =. Learning Mechanics , url =
-
[17]
2026 , howpublished =
2026
-
[18]
and Carmon, Yair and Dave, Achal and Schmidt, Ludwig and Shankar, Vaishaal , booktitle =
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and Garg, Saurabh and Xin, Rui and Muennighoff, Niklas and Heckel, Reinhard and Mercat, Jean and Chen, Mayee and Gururangan, Suchin and Wortsman, Mitchell and Albalak, Alon and Bitton, Yona...
-
[19]
2024 , eprint=
StarCoder 2 and The Stack v2: The Next Generation , author=. 2024 , eprint=
2024
-
[20]
Shengding Hu and Yuge Tu and Xu Han and Ganqu Cui and Chaoqun He and Weilin Zhao and Xiang Long and Zhi Zheng and Yewei Fang and Yuxiang Huang and Xinrong Zhang and Zhen Leng Thai and Chongyi Wang and Yuan Yao and Chenyang Zhao and Jie Zhou and Jie Cai and Zhongwu Zhai and Ning Ding and Chao Jia and Guoyang Zeng and dahai li and Zhiyuan Liu and Maosong Su...
2024
-
[21]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[22]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[23]
Scaling Data-Constrained Language Models , url =
Muennighoff, Niklas and Rush, Alexander and Barak, Boaz and Le Scao, Teven and Tazi, Nouamane and Piktus, Aleksandra and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin A , booktitle =. Scaling Data-Constrained Language Models , url =
-
[24]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[25]
arXiv preprint arXiv:2501.00656 , year=
2 OLMo 2 Furious , author=. arXiv preprint arXiv:2501.00656 , year=
-
[26]
arXiv preprint arXiv:2512.13961 , year=
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
-
[27]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[28]
arXiv preprint arXiv:2602.10604 , year=
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters , author=. arXiv preprint arXiv:2602.10604 , year=
-
[29]
arXiv preprint arXiv:2203.15556 , volume=
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , volume=
-
[30]
arXiv preprint arXiv:2001.08361 , year=
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[31]
The Fourteenth International Conference on Learning Representations , year=
Pre-training under infinite compute , author=. The Fourteenth International Conference on Learning Representations , year=
-
[32]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Diffusion Beats Autoregressive in Data-Constrained Settings , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[33]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[34]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[35]
arXiv preprint arXiv:2511.03276 , year=
Diffusion language models are super data learners , author=. arXiv preprint arXiv:2511.03276 , year=
-
[36]
2018 , month = jun, url =
Improving Language Understanding by Generative Pre-Training , author =. 2018 , month = jun, url =
2018
-
[37]
Forty-first International Conference on Machine Learning , year=
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=. Forty-first International Conference on Machine Learning , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
arXiv preprint arXiv:2002.05202 , year=
Glu variants improve transformer , author=. arXiv preprint arXiv:2002.05202 , year=
Pith/arXiv arXiv 2002
-
[40]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[41]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Large Language Diffusion Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[42]
arXiv preprint arXiv:2602.10314 , year=
Stop Training for the Worst: Progressive Unmasking Accelerates Masked Diffusion Training , author=. arXiv preprint arXiv:2602.10314 , year=
-
[43]
XLNet: Generalized Autoregressive Pretraining for Language Understanding , url =
Yang, Zhilin and Dai, Zihang and Yang, Yiming and Carbonell, Jaime and Salakhutdinov, Russ R and Le, Quoc V , booktitle =. XLNet: Generalized Autoregressive Pretraining for Language Understanding , url =
-
[44]
The Thirteenth International Conference on Learning Representations , year=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[45]
arXiv preprint arXiv:2512.15745 , year=
Llada2.0: Scaling up diffusion language models to 100b , author=. arXiv preprint arXiv:2512.15745 , year=
-
[46]
arXiv preprint arXiv:2602.08676 , year=
LLaDA2.: Speeding Up Text Diffusion via Token Editing , author=. arXiv preprint arXiv:2602.08676 , year=
-
[47]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.