Diagnosing Visual Ignorance in Vision-Language Models
Pith reviewed 2026-06-27 22:49 UTC · model grok-4.3
The pith
Vision-language models often produce correct answers even when visual input is destroyed, due to reliance on language priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
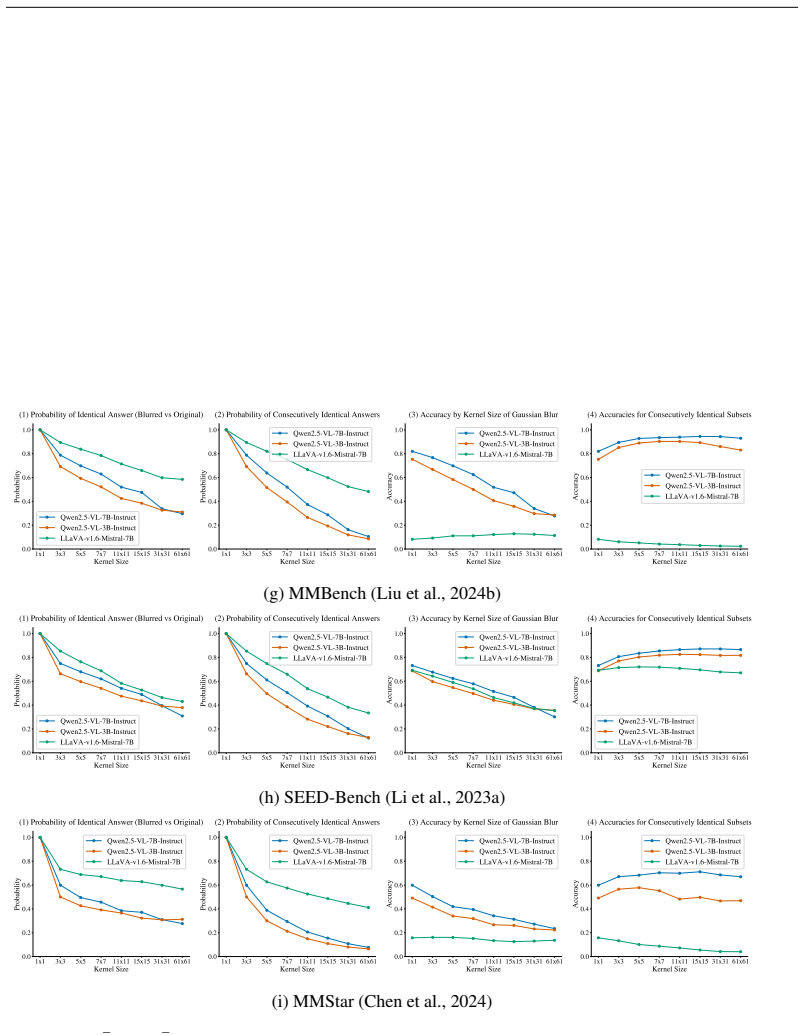
Counterfactual layer replacement combined with supervised probing reveals a multi-stage bottleneck in the language decoder: intermediate layers often fail to retrieve visual information, and later layers suppress remaining visual signals in favor of language priors. The progressive visual decay metric, based on multi-step Gaussian blurring, demonstrates that a substantial fraction of examples across twelve VQA benchmarks and three VLMs remain answerable under severe visual obfuscation.
What carries the argument
Multi-stage bottleneck in the language decoder, traced via counterfactual layer replacement and MLP probing, where visual semantics are outcompeted by language-prior semantics.
If this is right
- Current visual question-answering benchmarks can reward visual ignorance rather than true multimodal understanding.
- Model internals exhibit systematic suppression of visual signals at later decoder layers.
- Training distributions should incorporate structurally isolated data to enforce visual grounding.
- Evaluation protocols need redesign to isolate genuine cross-modal capabilities.
Where Pith is reading between the lines
- Similar language-prior issues may affect other multimodal tasks beyond VQA.
- Layer replacement techniques could diagnose biases in different model architectures.
- Redesigning benchmarks with counterfactual examples might lead to more robust VLMs.
- Addressing this could improve reliability in real-world applications where visual evidence is critical.
Load-bearing premise
The counterfactual interventions and blurring metric accurately measure language-prior reliance without the methods themselves altering the model's behavior in unintended ways.
What would settle it
Finding that answer invariance under visual decay correlates poorly with actual visual dependence, or that probing shows no suppression of visual signals, would challenge the routing failure claim.
Figures
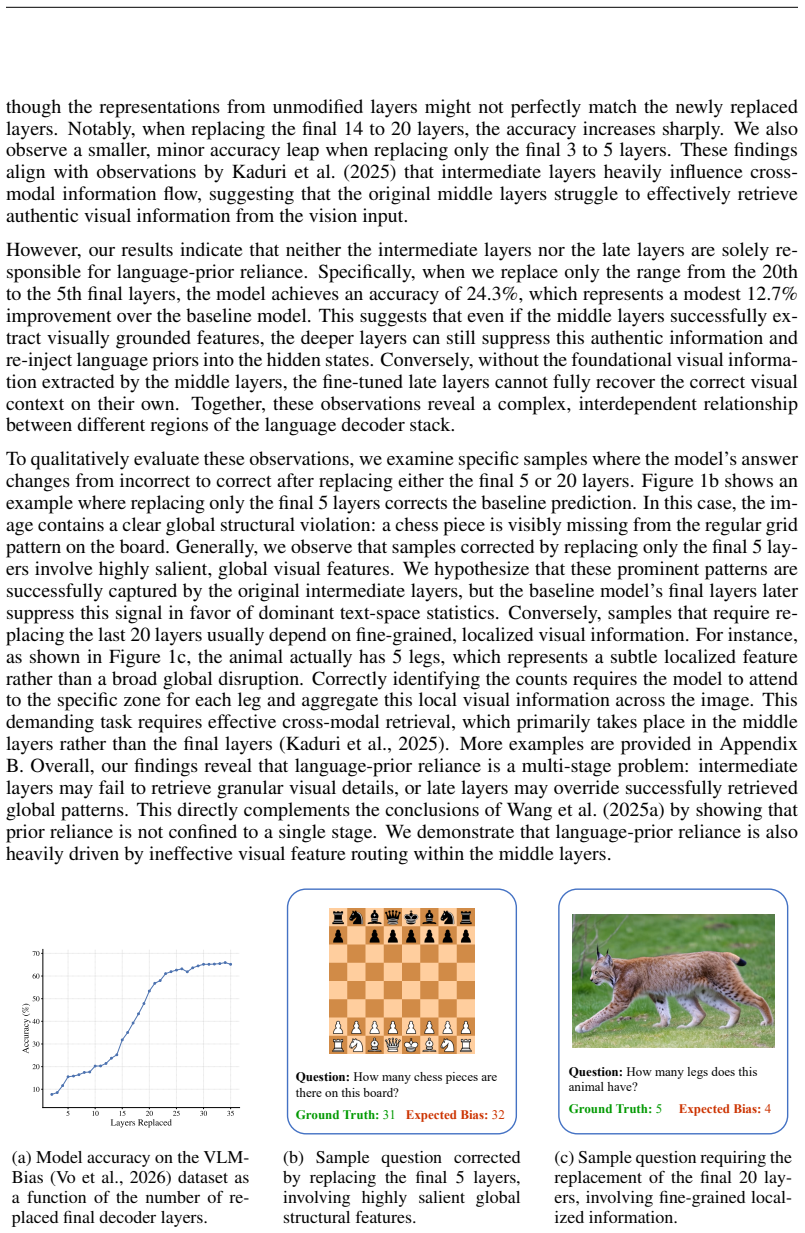
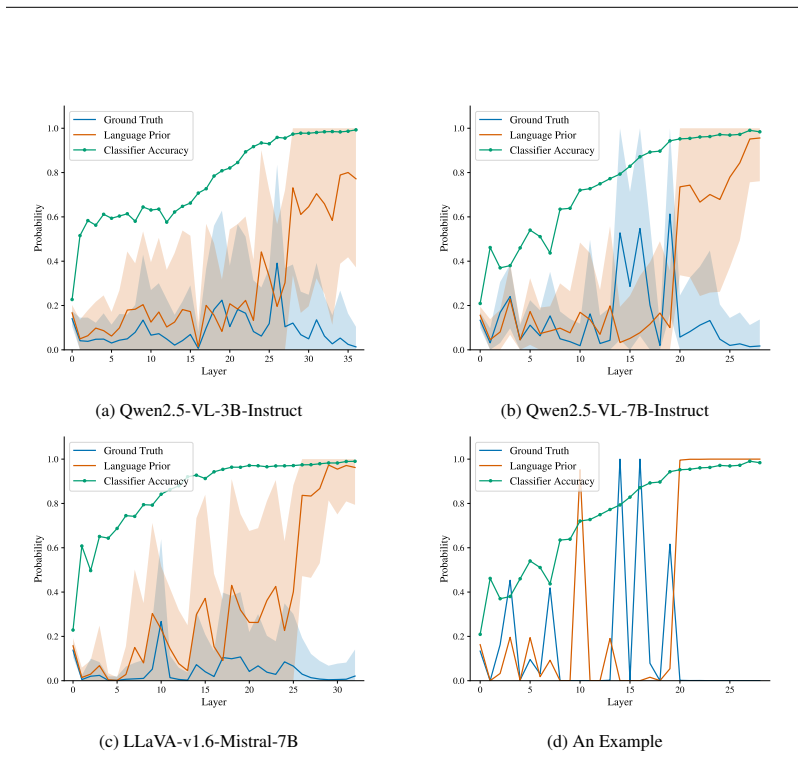

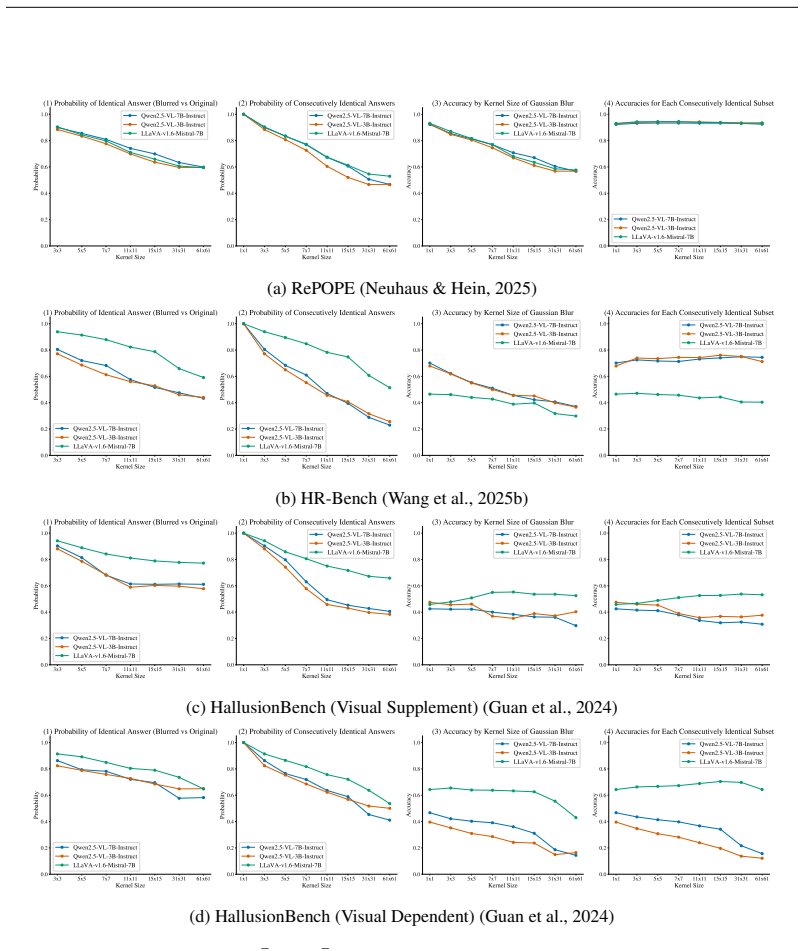




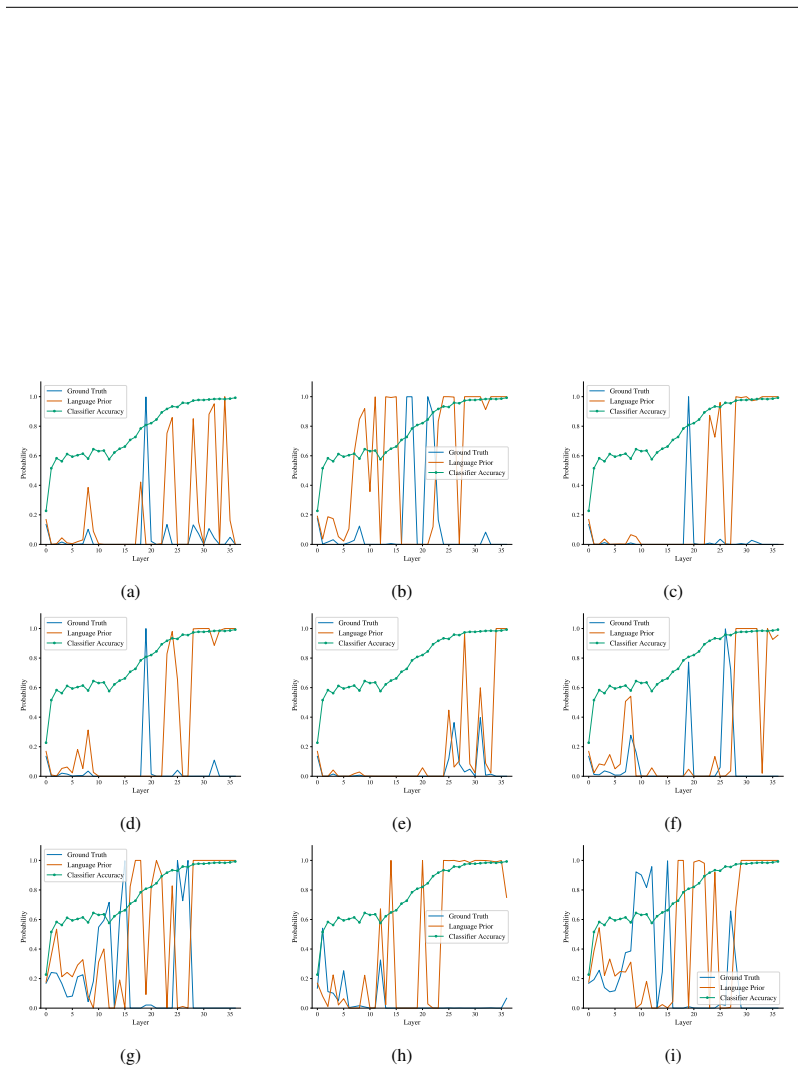
read the original abstract
Vision-Language Models (VLMs) frequently rely on language priors, producing confident answers that are weakly grounded in visual evidence. While this behavior is widely observed, its internal mechanisms and its impact on benchmark evaluation remain insufficiently understood. In this work, we study language-prior reliance from both mechanistic and behavioral perspectives. Internally, we combine counterfactual layer replacement with supervised layer-wise MLP probing to trace how ground-truth visual semantics and language-prior semantics compete across the language decoder. Our analysis reveals a multi-stage bottleneck: intermediate layers often fail to effectively retrieve visual information, while later layers can further suppress surviving visual signals in favor of text-space biases. Externally, we introduce a progressive visual decay metric based on multi-step Gaussian blurring, which identifies instances whose answers remain invariant even as visual content is increasingly destroyed. Across twelve visual question-answering benchmarks and three representative VLMs, we find that a substantial fraction of examples remain answerable under severe or total visual obfuscation, indicating that current benchmarks can inadvertently reward visual ignorance. These findings demonstrate that language-prior reliance is a systematic routing failure affecting both model internals and benchmark validity. Finally, we outline critical pathways for future research, highlighting the necessity of designing training distributions and evaluation protocols built on structurally isolated or counterfactual data to enforce genuine cross-modal grounding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that language-prior reliance in VLMs constitutes a systematic routing failure. Mechanistically, counterfactual layer replacement combined with supervised layer-wise MLP probing reveals a multi-stage bottleneck in the language decoder where intermediate layers fail to retrieve visual semantics and later layers suppress surviving visual signals in favor of text biases. Behaviorally, a progressive visual decay metric based on multi-step Gaussian blurring identifies a substantial fraction of examples across twelve VQA benchmarks and three VLMs that remain answerable under severe or total visual obfuscation, implying that benchmarks can reward visual ignorance. The work concludes by calling for training distributions and evaluation protocols based on structurally isolated or counterfactual data.
Significance. If the central claims hold after validation of the interventions, the work is significant for diagnosing how language priors undermine both internal cross-modal grounding and external benchmark validity in VLMs. The dual mechanistic-behavioral framing and the scale (12 benchmarks, 3 models) provide a concrete basis for rethinking evaluation protocols; the call for counterfactual data is a constructive forward path.
major comments (2)
- [mechanistic analysis] Mechanistic analysis section: The counterfactual layer replacement is presented as isolating competition between visual semantics and language priors, yet the abstract and described method provide no indication of controls such as random-layer baselines, same-condition shuffles, or direct comparison to the unmodified forward pass. Without these, measured suppression cannot be confidently attributed to native routing rather than intervention-induced perturbations in the residual stream and attention patterns; this directly affects the load-bearing claim of a 'multi-stage bottleneck' in the original model.
- [behavioral analysis / results] Behavioral analysis and results sections: The progressive visual decay metric identifies invariant answers under increasing Gaussian blur, but the manuscript reports no quantitative details on the exact fraction, confidence intervals, or statistical tests supporting the 'substantial fraction' claim across the twelve benchmarks. This weakens assessment of whether the invariance truly reflects language-prior routing failure versus other factors such as question ambiguity.
minor comments (2)
- [abstract] The abstract refers to 'twelve visual question-answering benchmarks' without naming them; listing the specific datasets (e.g., VQAv2, GQA, etc.) would improve reproducibility.
- [mechanistic analysis] Notation for the supervised MLP probing (e.g., layer indices, probe architecture) is not previewed in the abstract and should be introduced with a brief equation or diagram in the mechanistic section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the attribution of effects in the mechanistic analysis and the quantitative support for the behavioral claims. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [mechanistic analysis] Mechanistic analysis section: The counterfactual layer replacement is presented as isolating competition between visual semantics and language priors, yet the abstract and described method provide no indication of controls such as random-layer baselines, same-condition shuffles, or direct comparison to the unmodified forward pass. Without these, measured suppression cannot be confidently attributed to native routing rather than intervention-induced perturbations in the residual stream and attention patterns; this directly affects the load-bearing claim of a 'multi-stage bottleneck' in the original model.
Authors: We agree that the current presentation lacks explicit controls to isolate intervention effects from native routing. In the revised manuscript, we will add random-layer replacement baselines, input shuffles that preserve condition structure, and direct comparisons against the unmodified forward pass. These controls will be reported in an expanded mechanistic analysis section, with quantitative metrics showing that the multi-stage bottleneck pattern persists beyond intervention artifacts. revision: yes
-
Referee: [behavioral analysis / results] Behavioral analysis and results sections: The progressive visual decay metric identifies invariant answers under increasing Gaussian blur, but the manuscript reports no quantitative details on the exact fraction, confidence intervals, or statistical tests supporting the 'substantial fraction' claim across the twelve benchmarks. This weakens assessment of whether the invariance truly reflects language-prior routing failure versus other factors such as question ambiguity.
Authors: We will expand the behavioral analysis and results sections to report exact per-benchmark and per-model fractions of invariant examples, 95% confidence intervals, and statistical tests (including binomial tests against chance and controls for question ambiguity). These additions will allow readers to evaluate the strength of the language-prior routing interpretation. revision: yes
Circularity Check
No circularity: claims rest on empirical interventions and metrics
full rationale
The paper's central claims derive from direct experimental interventions (counterfactual layer replacement + layer-wise MLP probing) and a progressive visual decay metric (multi-step Gaussian blurring) applied across benchmarks. These produce observational findings about language-prior reliance without any reduction of results to fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations. The abstract and described methods contain no equations or derivations that equate outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Counterfactual layer replacement and supervised layer-wise MLP probing can trace competition between visual semantics and language priors in the decoder
- domain assumption Multi-step Gaussian blurring progressively destroys visual content while allowing measurement of answer invariance
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[2]
2026 , eprint=
Vision Language Models are Biased , author=. 2026 , eprint=
2026
-
[3]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
What's in the Image? A Deep-Dive into the Vision of Vision Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
, author=
Lora: Low-rank adaptation of large language models. , author=. International Conference on Learning Representations , volume=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Towards understanding how knowledge evolves in large vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
, author =
Accelerate: Training and inference at scale made simple, efficient and adaptable. , author =
-
[8]
2020 , month=
Interpreting GPT: The Logit Lens , author=. 2020 , month=
2020
-
[9]
K-sparse autoencoders , author=. arXiv preprint arXiv:1312.5663 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
European Conference on Computer Vision , pages=
BLINK: Multimodal Large Language Models Can See but Not Perceive , author=. European Conference on Computer Vision , pages=
-
[15]
Grok-1.5 vision preview , year =
-
[16]
arXiv preprint arXiv:2504.15707 , year=
Repope: Impact of annotation errors on the pope benchmark , author=. arXiv preprint arXiv:2504.15707 , year=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
V*: Guided visual search as a core mechanism in multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
European conference on computer vision , pages=
A diagram is worth a dozen images , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[21]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
European conference on computer vision , pages=
Mmbench: Is your multi-modal model an all-around player? , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[25]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Seed-bench: Benchmarking multimodal llms with generative comprehension , author=. arXiv preprint arXiv:2307.16125 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Knowing before saying: LLM representations encode information about chain-of-thought success before completion , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[27]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Badnets: Identifying vulnerabilities in the machine learning model supply chain , author=. arXiv preprint arXiv:1708.06733 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Proceedings of the 37th Annual Computer Security Applications Conference , pages=
Badnl: Backdoor attacks against nlp models with semantic-preserving improvements , author=. Proceedings of the 37th Annual Computer Security Applications Conference , pages=
-
[29]
Universal adversarial triggers for attacking and analyzing NLP , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[30]
Proceedings of the 41st International Conference on Machine Learning , pages =
Revisiting the Role of Language Priors in Vision-Language Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[31]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Vlind-bench: Measuring language priors in large vision-language models , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[32]
International Conference on Machine Learning , pages=
Probing Visual Language Priors in VLMs , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[33]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Pixels versus priors: Controlling knowledge priors in vision-language models through visual counterfacts , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[34]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Words or vision: Do vision-language models have blind faith in text? , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[35]
Proceedings of the Asian Conference on Computer Vision , pages=
Vision language models are blind , author=. Proceedings of the Asian Conference on Computer Vision , pages=
-
[36]
2026 , eprint=
MIRAGE: The Illusion of Visual Understanding , author=. 2026 , eprint=
2026
-
[37]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in Neural Information Processing Systems , volume=
Sparse autoencoders learn monosemantic features in vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
arXiv preprint arXiv:2506.08008 , year=
Hidden in plain sight: Vlms overlook their visual representations , author=. arXiv preprint arXiv:2506.08008 , year=
-
[40]
Arbitration Failure, Not Perceptual Blindness: How Vision-Language Models Resolve Visual-Linguistic Conflicts , author=. arXiv preprint arXiv:2604.09364 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
International Conference on Learning Representations , volume=
Interpreting and editing vision-language representations to mitigate hallucinations , author=. International Conference on Learning Representations , volume=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.