EASE-TTT: Evidence-Aligned Selective Test-Time Training for Long-Context Question Answering
Pith reviewed 2026-06-27 22:02 UTC · model grok-4.3
The pith
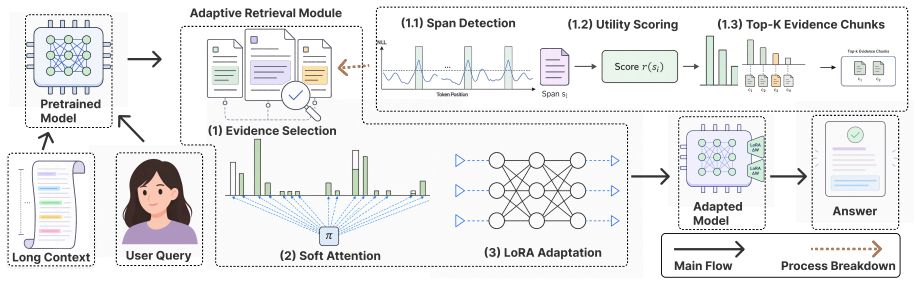
EASE-TTT uses evidence chunks to create soft attention targets that guide query-side adaptation for better long-context question answering from the full input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EASE-TTT converts selected evidence chunks into a soft attention supervision target over token positions to guide query-side adaptation during test-time training. The adapted model then generates answers from the original full context, achieving the strongest macro-average performance on six LongBench QA tasks with three small decoder-only language models among the compared methods.
What carries the argument
The evidence-aligned soft attention supervision target derived from selected chunks, used to adapt query-side attention parameters while keeping the full context for final generation.
If this is right
- It outperforms full-context inference on macro-average.
- It exceeds retrieval-only baselines that stop at input-level exposure.
- It improves upon qTTT by incorporating evidence localization into the adaptation objective.
- The method maintains use of the complete original context after adaptation.
Where Pith is reading between the lines
- If the attention alignment holds, this could extend to other long-context tasks like summarization.
- Small models might benefit more from this selective adaptation than larger ones that handle context better natively.
- Future work could test whether the soft targets reduce attention misalignment in very long sequences.
Load-bearing premise
That a soft attention supervision target from evidence chunks can guide adaptation to improve answer generation from the full context without causing harmful distribution shift.
What would settle it
A controlled experiment on one of the LongBench tasks where EASE-TTT underperforms the best baseline would falsify the performance claim.
Figures

read the original abstract
Long-context question answering (QA) remains challenging for smaller language models even when answer-bearing evidence is already present in the input. Existing within-context retrieval methods localize and expose candidate evidence chunks for the question, but they stop at input-level evidence exposure rather than adapting the query-side attention parameters that control how the model allocates attention over full-context positions. In contrast, lightweight test-time adaptation methods, such as query-only test-time training (qTTT), leave evidence localization unresolved because their generic span-level self-supervised objectives do not identify which context positions support the current answer. In this paper, we propose Evidence-Aligned SElective Test-Time Training (EASE-TTT), a within-context retrieval-augmented test-time training framework that converts selected evidence chunks into a soft attention supervision target over their token positions. Instead of replacing the full context with retrieved chunks, EASE-TTT uses the resulting attention target to guide query-side adaptation, with the adapted model generating the final answer from the original full context. Experiments on six LongBench QA tasks and three small decoder-only language models show that EASE-TTT achieves the strongest macro-average performance among full-context inference, retrieval-only baselines, and qTTT, supporting evidence-aligned test-time adaptation in long-context QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Evidence-Aligned Selective Test-Time Training (EASE-TTT), a retrieval-augmented test-time adaptation method for long-context QA. It converts selected evidence chunks into a soft attention supervision target to guide query-side adaptation of small decoder-only models, then generates answers from the original full context rather than replacing it with retrieved chunks. Experiments on six LongBench QA tasks with three small decoder-only models report that EASE-TTT achieves the strongest macro-average performance relative to full-context inference, retrieval-only baselines, and generic qTTT.
Significance. If the reported gains hold under scrutiny, the work would demonstrate a practical way to combine within-context retrieval with targeted test-time adaptation, addressing the limitation that generic self-supervised objectives in qTTT do not localize answer-supporting positions. This could be relevant for improving long-context performance of smaller models without full fine-tuning or context truncation.
major comments (2)
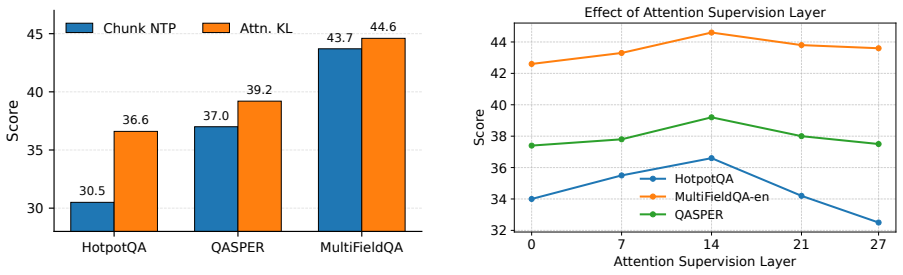
- [Experiments / abstract] The central performance claim (strongest macro-average on six LongBench tasks) rests on experimental results whose construction details are not supplied: no description of how the soft attention target is derived from evidence chunks, no statistical significance tests, and no ablation results isolating the contribution of evidence alignment versus generic adaptation. This information is required to evaluate whether the reported gains are reproducible or attributable to the proposed mechanism.
- [Method / Experiments] The weakest link in the argument—that the soft attention target derived from chunks improves answer generation from the full original context without introducing harmful distribution shift or attention misalignment—is asserted but not tested. No analysis, failure cases, or controls (e.g., comparison of attention maps before/after adaptation or performance on non-evidence positions) are provided to support this assumption.
minor comments (1)
- [Method] Notation for the attention target and the query-side adaptation objective should be formalized with equations to allow precise reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental detail and validation of key assumptions. We address each major comment below and will revise the manuscript to incorporate additional descriptions, statistical tests, ablations, and analyses as outlined.
read point-by-point responses
-
Referee: [Experiments / abstract] The central performance claim (strongest macro-average on six LongBench tasks) rests on experimental results whose construction details are not supplied: no description of how the soft attention target is derived from evidence chunks, no statistical significance tests, and no ablation results isolating the contribution of evidence alignment versus generic adaptation. This information is required to evaluate whether the reported gains are reproducible or attributable to the proposed mechanism.
Authors: The abstract is intentionally high-level. The method section explains the soft target as a normalized distribution over token positions within selected evidence chunks, but we agree this requires expansion with explicit equations and pseudocode for reproducibility. We will add statistical significance tests (e.g., paired t-tests across runs) and an ablation isolating evidence alignment from generic qTTT in the revised experiments section. revision: yes
-
Referee: [Method / Experiments] The weakest link in the argument—that the soft attention target derived from chunks improves answer generation from the full original context without introducing harmful distribution shift or attention misalignment—is asserted but not tested. No analysis, failure cases, or controls (e.g., comparison of attention maps before/after adaptation or performance on non-evidence positions) are provided to support this assumption.
Authors: We acknowledge the current manuscript lacks direct tests of this assumption. We will add a new analysis subsection including attention map comparisons before/after adaptation, performance breakdowns on evidence vs. non-evidence positions, and discussion of any observed distribution shift or failure cases to substantiate the claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents EASE-TTT as a framework that converts retrieved evidence chunks into a soft attention supervision target to guide query-side adaptation before full-context generation. No equations, derivations, or parameter-fitting steps are described that would reduce any claimed prediction or result to an input quantity by construction. The central performance claim rests on experimental macro-average gains across LongBench tasks rather than any self-referential mathematical reduction. No self-citation load-bearing premises, uniqueness theorems, or ansatz smuggling appear in the abstract or method outline. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2503.17407 , year=
A comprehensive survey on long context language modeling , author=. arXiv preprint arXiv:2503.17407 , year=
-
[2]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[3]
arXiv preprint arXiv:2411.05928 , year=
Reducing distraction in long-context language models by focused learning , author=. arXiv preprint arXiv:2411.05928 , year=
-
[4]
arXiv preprint arXiv:2510.05381 , year=
Context length alone hurts LLM performance despite perfect retrieval , author=. arXiv preprint arXiv:2510.05381 , year=
-
[5]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
ZeroSCROLLS: A zero-shot benchmark for long text understanding , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[6]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
A survey on test-time scaling in large language models: What, how, where, and how well? , author=. arXiv preprint arXiv:2503.24235 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Beware of model collapse! fast and stable test-time adaptation for robust question answering , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[8]
arXiv preprint arXiv:2410.10894 , year=
COME: Test-time adaption by conservatively minimizing entropy , author=. arXiv preprint arXiv:2410.10894 , year=
-
[9]
International Conference on Learning Representations , volume=
Efficiently learning at test-time: Active fine-tuning of llms , author=. International Conference on Learning Representations , volume=
-
[10]
arXiv preprint arXiv:2505.18149 , year=
First finish search: Efficient test-time scaling in large language models , author=. arXiv preprint arXiv:2505.18149 , year=
-
[11]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Learning to reason from feedback at test-time , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
arXiv preprint arXiv:2512.13898 , year=
Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs , author=. arXiv preprint arXiv:2512.13898 , year=
-
[13]
arXiv preprint arXiv:2505.13308 , year=
Seek in the dark: Reasoning via test-time instance-level policy gradient in latent space , author=. arXiv preprint arXiv:2505.13308 , year=
-
[14]
arXiv preprint arXiv:2411.09289 , year=
Streamadapter: Efficient test time adaptation from contextual streams , author=. arXiv preprint arXiv:2411.09289 , year=
-
[15]
arXiv preprint arXiv:2505.20633 , year=
Test-time learning for large language models , author=. arXiv preprint arXiv:2505.20633 , year=
-
[16]
arXiv preprint arXiv:2510.10223 , year=
You only need 4 extra tokens: Synergistic test-time adaptation for llms , author=. arXiv preprint arXiv:2510.10223 , year=
-
[17]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Layer-wise importance matters: Less memory for better performance in parameter-efficient fine-tuning of large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[18]
arXiv preprint arXiv:2403.02181 , year=
Not all layers of llms are necessary during inference , author=. arXiv preprint arXiv:2403.02181 , year=
-
[19]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Internal Chain-of-Thought: Empirical Evidence for Layer-wise Subtask Scheduling in LLMs , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[20]
arXiv preprint arXiv:2410.17875 , year=
Understanding layer significance in llm alignment , author=. arXiv preprint arXiv:2410.17875 , year=
-
[21]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
How is llm reasoning distracted by irrelevant context? an analysis using a controlled benchmark , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Longrope: Extending llm context window beyond 2 million tokens , author=. arXiv preprint arXiv:2402.13753 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
International Conference on Learning Representations , volume=
Longlora: Efficient fine-tuning of long-context large language models , author=. International Conference on Learning Representations , volume=
-
[26]
RULER: What's the Real Context Size of Your Long-Context Language Models?
RULER: What's the real context size of your long-context language models? , author=. arXiv preprint arXiv:2404.06654 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2502.05167 , year=
Nolima: Long-context evaluation beyond literal matching , author=. arXiv preprint arXiv:2502.05167 , year=
-
[28]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Compressing context to enhance inference efficiency of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[30]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Drilling down into the discourse structure with llms for long document question answering , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[31]
International Conference on Learning Representations , volume=
Raptor: Recursive abstractive processing for tree-organized retrieval , author=. International Conference on Learning Representations , volume=
-
[32]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Distance between relevant information pieces causes bias in long-context LLMs , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[33]
ACM Transactions on Information Systems , volume=
U-niah: Unified rag and llm evaluation for long context needle-in-a-haystack , author=. ACM Transactions on Information Systems , volume=. 2026 , publisher=
2026
-
[34]
International conference on machine learning , pages=
Test-time training with self-supervision for generalization under distribution shifts , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[35]
Tent: Fully Test-time Adaptation by Entropy Minimization
Tent: Fully test-time adaptation by entropy minimization , author=. arXiv preprint arXiv:2006.10726 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[36]
International Conference on Learning Representations , volume=
Test-time training on nearest neighbors for large language models , author=. International Conference on Learning Representations , volume=
-
[37]
arXiv preprint arXiv:2411.07279 , year=
The surprising effectiveness of test-time training for few-shot learning , author=. arXiv preprint arXiv:2411.07279 , year=
-
[38]
In-place test-time training , author=. arXiv preprint arXiv:2604.06169 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Llmlingua: Compressing prompts for accelerated inference of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[40]
arXiv preprint arXiv:2310.04408 , year=
Recomp: Improving retrieval-augmented lms with compression and selective augmentation , author=. arXiv preprint arXiv:2310.04408 , year=
-
[41]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[42]
arXiv preprint arXiv:2409.04701 , year=
Late chunking: contextual chunk embeddings using long-context embedding models , author=. arXiv preprint arXiv:2409.04701 , year=
-
[43]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Longrag: A dual-perspective retrieval-augmented generation paradigm for long-context question answering , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[44]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Compact: Compressing retrieved documents actively for question answering , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[45]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Can’t remember details in long documents? you need some r&r , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[46]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Test-time self-adaptive small language models for question answering , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[49]
Predict the Retrieval! Test time adaptation for Retrieval Augmented Generation
Predict the Retrieval! Test time adaptation for Retrieval Augmented Generation , author=. arXiv preprint arXiv:2601.11443 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
arXiv preprint arXiv:2402.07440 , year=
Benchmarking and building long-context retrieval models with loco and m2-bert , author=. arXiv preprint arXiv:2402.07440 , year=
-
[51]
arXiv preprint arXiv:2502.11444 , year=
Does RAG Really Perform Bad For Long-Context Processing? , author=. arXiv preprint arXiv:2502.11444 , year=
-
[52]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Leave no document behind: Benchmarking long-context llms with extended multi-doc qa , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[53]
arXiv preprint arXiv:2503.23306 , year=
Focus directions make your language models pay more attention to relevant contexts , author=. arXiv preprint arXiv:2503.23306 , year=
-
[54]
Li, Huayang and Verga, Pat and Sen, Priyanka and Yang, Bowen and Viswanathan, Vijay and Lewis, Patrick and Watanabe, Taro and Su, Yixuan , journal=
-
[55]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Eliciting in-context retrieval and reasoning for long-context large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[56]
arXiv preprint arXiv:2402.09727 , year=
A human-inspired reading agent with gist memory of very long contexts , author=. arXiv preprint arXiv:2402.09727 , year=
-
[57]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[58]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Grounding language model with chunking-free in-context retrieval , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[59]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-k , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[60]
Ethic: Evaluating large language models on long-context tasks with high information coverage , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[61]
Advances in Neural Information Processing Systems , volume=
Make your llm fully utilize the context , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
arXiv preprint arXiv:2404.02060 , year=
Long-context llms struggle with long in-context learning , author=. arXiv preprint arXiv:2404.02060 , year=
-
[63]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Dynamic chunking and selection for reading comprehension of ultra-long context in large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Prompt compression with context-aware sentence encoding for fast and improved llm inference , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[65]
arXiv preprint arXiv:2311.08377 , year=
Learning to filter context for retrieval-augmented generation , author=. arXiv preprint arXiv:2311.08377 , year=
-
[66]
arXiv preprint arXiv:2501.16214 , year=
Provence: efficient and robust context pruning for retrieval-augmented generation , author=. arXiv preprint arXiv:2501.16214 , year=
-
[67]
Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Attend first, consolidate later: On the importance of attention in different llm layers , author=. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[68]
arXiv preprint arXiv:2403.04510 , year=
Where does in-context translation happen in large language models , author=. arXiv preprint arXiv:2403.04510 , year=
-
[69]
Layer by Layer: Uncovering Hidden Representations in Language Models
Layer by layer: Uncovering hidden representations in language models , author=. arXiv preprint arXiv:2502.02013 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.