A Geometric View for Understanding Concept Learning and Neuron Interpretation in Sparse Autoencoders
Pith reviewed 2026-06-27 22:21 UTC · model grok-4.3
The pith
Concepts are sets of data points whose alignment with SAE features obeys geometric conditions that distinguish detection, separation, and approximation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
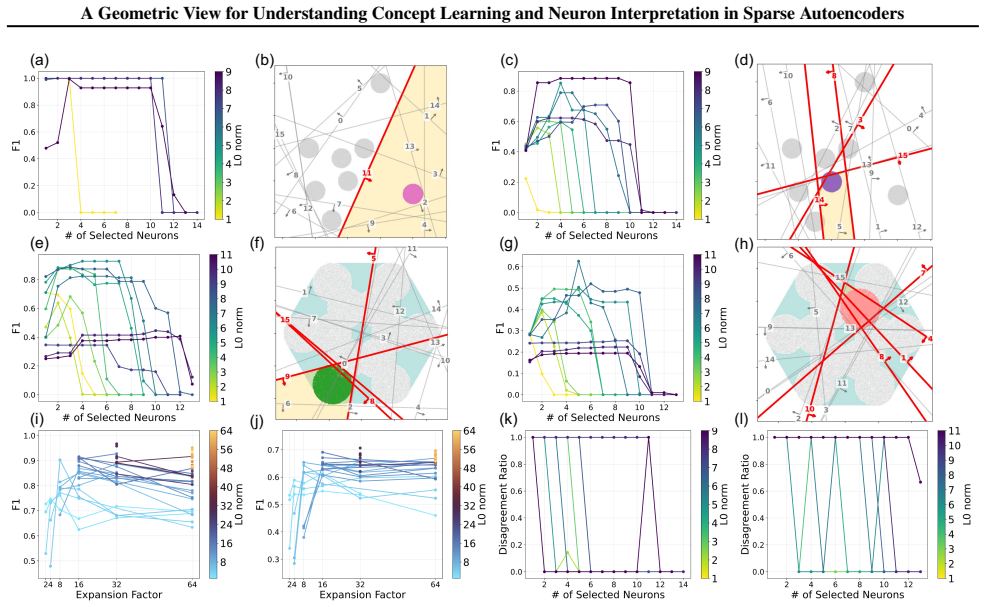
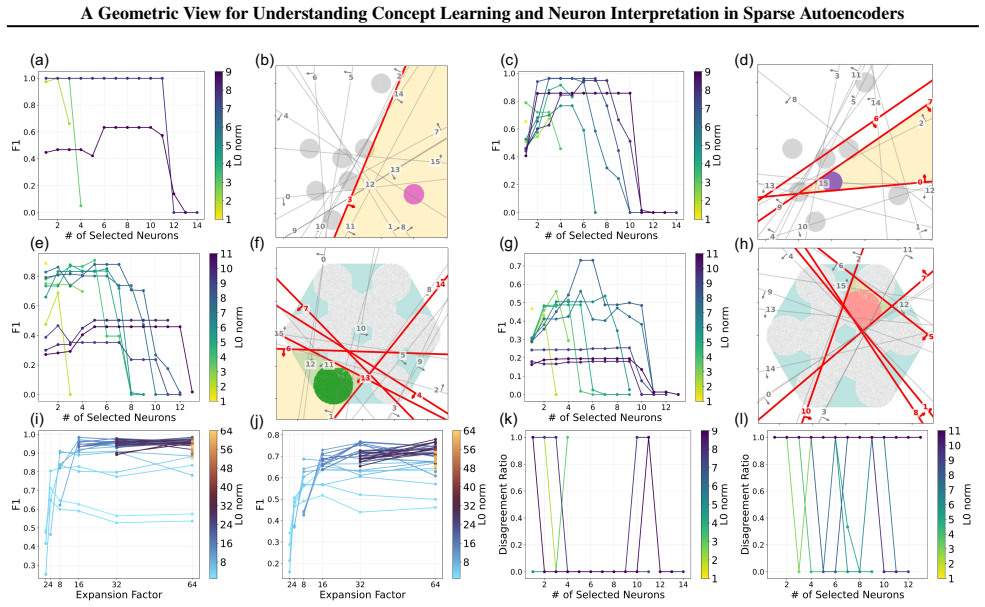
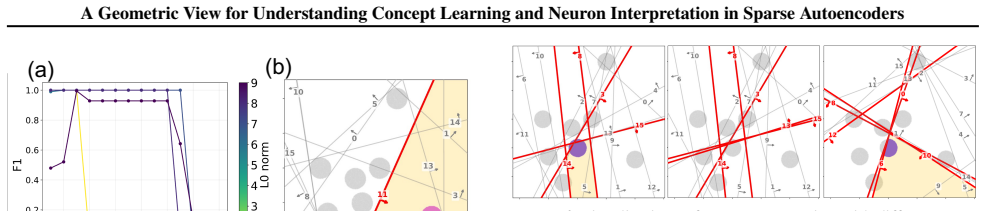
Casting concept learning as set alignment between human-defined and model-induced sets yields geometric conditions, error bounds, and capacity constraints that determine when a concept can be represented by an individual neuron or by a multi-neuron unit. The same account explains feature splitting, feature absorption, feature families, and hierarchical concepts. Formal concept analysis further shows that concept learning and neuron interpretation are distinct many-to-many relations that can be organized by concept lattices. Experiments with ReLU and Top-K SAEs on synthetic data confirm that SAE size and sparsity govern which of the three learning levels is reachable.
What carries the argument
Set-alignment between human-defined concept sets and model-induced feature sets, which supplies the geometric conditions for the three learning strengths.
If this is right
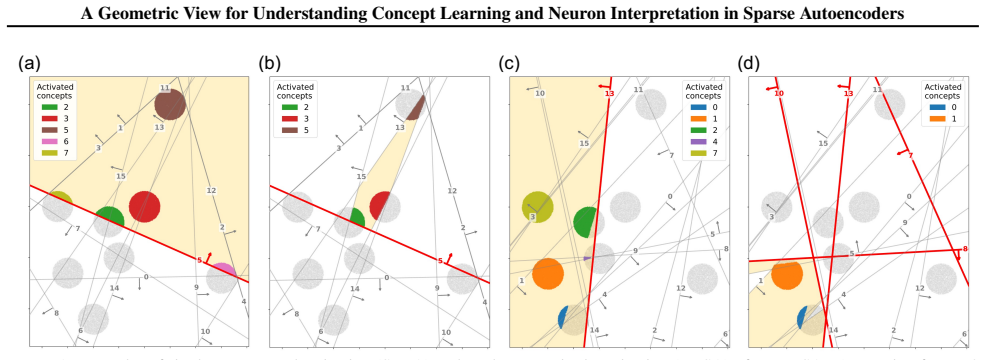
- Detection requires only nonzero overlap between concept set and activation set; separation adds a disjointness requirement outside the concept; approximation further requires the sets to be nearly equal.
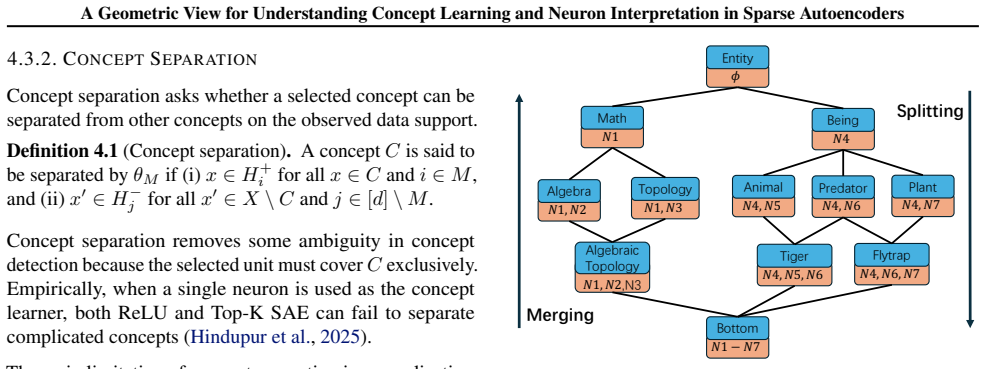
- Feature splitting arises when one human concept set aligns with several disjoint model feature sets.
- SAE width and sparsity impose explicit upper bounds on the number of concepts that can reach the approximation level.
- Concept lattices organize the many-to-many relations between concepts and neurons so that neither direction of interpretation is forced to be one-to-one.
Where Pith is reading between the lines
- The same geometric tests could be applied to non-SAE interpretability methods that produce sparse feature sets.
- If the capacity bounds hold on real data they would give a direct way to choose SAE hyperparameters before training.
- Concept lattices might serve as a navigation structure for auditing large models by revealing which concepts share neurons.
- The framework predicts that increasing sparsity beyond a certain point will trade approximation power for better separation of simpler concepts.
Load-bearing premise
Human-defined concepts can be represented faithfully as sets of data points and their alignment with model features can be captured by geometric conditions measured in activation space.
What would settle it
A controlled synthetic experiment in which a neuron’s activation set satisfies the geometric overlap, separation, or approximation condition for a known concept set yet the neuron’s actual classification performance on held-out points from that set falls below the predicted bound would falsify the claimed correspondence.
Figures


read the original abstract
We propose a unified mathematical framework for a geometric understanding of concept learning and neuron interpretation in sparse autoencoders (SAEs). While SAEs improve interpretability of neural networks by learning sparse feature representations, a principled definition of ''concept'' and ''learning'' remains unclear. We formalize concepts as sets of data points and cast concept learning as a set-alignment problem between human-defined and model-induced concepts. This formulation distinguishes three increasingly strong notions of learning -- detection, separation, and approximation -- and yields geometric conditions, error bounds, and capacity constraints for when concepts can be represented by individual neurons or multi-neuron units. It also provides a set-theoretic account for common SAE phenomena, including feature splitting, feature absorption, feature families, and hierarchical concepts. Finally, we connect concept learning and neuron interpretation through formal concept analysis, showing that the two directions need not agree and that their many-to-many structure can be organized by concept lattices. Experiments on synthetic data with ReLU and Top-$K$ SAEs illustrate the theory and reveal the effects of SAE size and sparsity on concept learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified mathematical framework for concept learning and neuron interpretation in sparse autoencoders (SAEs). Concepts are formalized as sets of data points, with concept learning cast as a set-alignment problem between human-defined and model-induced concepts. This yields three graded notions of learning (detection, separation, approximation), along with associated geometric conditions, error bounds, and capacity constraints for representation by single neurons or multi-neuron units. The framework provides a set-theoretic account of SAE phenomena including feature splitting, feature absorption, feature families, and hierarchical concepts. It further connects the two directions via formal concept analysis, noting that concept learning and neuron interpretation need not agree and can be organized via concept lattices. Synthetic experiments with ReLU and Top-K SAEs illustrate the effects of SAE size and sparsity.
Significance. If the derivations hold, the work supplies a principled, definitionally grounded formalization that distinguishes graded strengths of concept learning and organizes several observed SAE behaviors under one set-alignment view. The explicit link to formal concept analysis for reconciling learning and interpretation directions is a clear organizational contribution. The absence of fitted parameters in the core distinctions and the provision of synthetic experiments that directly test the predicted effects of size and sparsity are strengths that make the framework falsifiable and extensible.
minor comments (3)
- [Theory section (after the three notions are introduced)] The abstract states that the framework 'yields geometric conditions, error bounds, and capacity constraints,' but the main text should include a dedicated subsection or theorem statement that isolates the precise geometric condition for each of the three notions (detection, separation, approximation) so readers can verify the bounds without reconstructing them from the set definitions.
- [Formal concept analysis subsection] The connection to formal concept analysis is described as showing that 'the two directions need not agree'; a small illustrative lattice diagram or table in the relevant section would make the many-to-many structure concrete rather than purely verbal.
- [Experiments section] The synthetic experiments are said to 'reveal the effects of SAE size and sparsity on concept learning.' Adding a table that reports the measured alignment metrics (e.g., set-overlap or approximation error) for each SAE configuration would allow direct comparison with the derived capacity constraints.
Simulated Author's Rebuttal
We thank the referee for their positive and accurate summary of the manuscript, for highlighting its strengths in providing a falsifiable framework and linking to formal concept analysis, and for recommending minor revision. No specific major comments appear in the report, so we have no point-by-point responses to supply. We will address any minor editorial or presentational issues in the revised version.
Circularity Check
No significant circularity; definitional framework with independent geometric derivations
full rationale
The paper's core contribution is a set-theoretic formalization of concepts as data-point sets and concept learning as set-alignment, from which the three notions (detection, separation, approximation), geometric conditions, error bounds, and capacity constraints follow directly by definition and standard set/geometry arguments. No step reduces a claimed result to a fitted parameter, self-citation chain, or ansatz smuggled from prior author work; the SAE phenomena accounts and formal concept analysis connections are presented as consequences of the new setup rather than tautologies. Experiments on synthetic data serve only to illustrate, not to derive or validate the theory by construction. This is a standard non-circular theoretical proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Concepts can be represented as sets of data points.
- domain assumption Geometric conditions in activation space determine when a concept is represented by neurons.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2311.03658 , year=
The linear representation hypothesis and the geometry of large language models , author=. arXiv preprint arXiv:2311.03658 , year=
-
[2]
Vision research , volume=
Sparse coding with an overcomplete basis set: A strategy employed by V1? , author=. Vision research , volume=. 1997 , publisher=
1997
-
[3]
CS294A Lecture notes , volume=
Sparse autoencoder , author=. CS294A Lecture notes , volume=
-
[4]
arXiv preprint arXiv:2309.08600 , year=
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
-
[5]
arXiv preprint arXiv:2408.00657 , year=
Disentangling dense embeddings with sparse autoencoders , author=. arXiv preprint arXiv:2408.00657 , year=
-
[6]
arXiv preprint arXiv:2406.04093 , year=
Scaling and evaluating sparse autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=
-
[7]
arXiv preprint arXiv:2404.16014 , year=
Improving dictionary learning with gated sparse autoencoders , author=. arXiv preprint arXiv:2404.16014 , year=
-
[8]
arXiv preprint arXiv:2407.14435 , year=
Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders , author=. arXiv preprint arXiv:2407.14435 , year=
-
[9]
arXiv preprint arXiv:2506.03093 , year=
From flat to hierarchical: Extracting sparse representations with matching pursuit , author=. arXiv preprint arXiv:2506.03093 , year=
-
[10]
The Thirteenth International Conference on Learning Representations , year=
Sparse autoencoders do not find canonical units of analysis , author=. The Thirteenth International Conference on Learning Representations , year=
-
[11]
arXiv preprint arXiv:2505.16077 , year=
Ensembling Sparse Autoencoders , author=. arXiv preprint arXiv:2505.16077 , year=
-
[12]
arXiv preprint arXiv:2506.01197 , year=
Incorporating hierarchical semantics in sparse autoencoder architectures , author=. arXiv preprint arXiv:2506.01197 , year=
-
[13]
arXiv preprint arXiv:2209.10652 , year=
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
-
[14]
2024 , publisher=
Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet , author=. 2024 , publisher=
2024
-
[15]
arXiv preprint arXiv:2409.14507 , year=
A is for absorption: Studying feature splitting and absorption in sparse autoencoders , author=. arXiv preprint arXiv:2409.14507 , year=
-
[16]
Transformer Circuits Thread , volume=
Towards monosemanticity: Decomposing language models with dictionary learning , author=. Transformer Circuits Thread , volume=
-
[17]
arXiv preprint arXiv:2503.01822 , year=
Projecting assumptions: The duality between sparse autoencoders and concept geometry , author=. arXiv preprint arXiv:2503.01822 , year=
-
[18]
arXiv preprint arXiv:2509.02565 , year=
Understanding sparse autoencoder scaling in the presence of feature manifolds , author=. arXiv preprint arXiv:2509.02565 , year=
-
[19]
arXiv e-prints , pages=
Sparse autoencoders can interpret randomly initialized transformers , author=. arXiv e-prints , pages=
-
[20]
arXiv preprint arXiv:2505.00808 , year=
A Mathematical Philosophy of Explanations in Mechanistic Interpretability--The Strange Science Part Ii , author=. arXiv preprint arXiv:2505.00808 , year=
-
[21]
arXiv preprint arXiv:2512.07355 , year=
A Geometric Unification of Concept Learning with Concept Cones , author=. arXiv preprint arXiv:2512.07355 , year=
-
[22]
arXiv preprint arXiv:2602.02464 , year=
From Directions to Regions: Decomposing Activations in Language Models via Local Geometry , author=. arXiv preprint arXiv:2602.02464 , year=
-
[23]
arXiv preprint arXiv:2602.02315 , year=
The Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors , author=. arXiv preprint arXiv:2602.02315 , year=
-
[24]
arXiv preprint arXiv:2604.28119 , year=
Do Sparse Autoencoders Capture Concept Manifolds? , author=. arXiv preprint arXiv:2604.28119 , year=
-
[25]
arXiv preprint arXiv:2602.03204 , year=
Sparsity is Combinatorial Depth: Quantifying MoE Expressivity via Tropical Geometry , author=. arXiv preprint arXiv:2602.03204 , year=
-
[26]
Advances in neural information processing systems , volume=
On the number of linear regions of deep neural networks , author=. Advances in neural information processing systems , volume=
-
[27]
arXiv preprint arXiv:1312.6098 , year=
On the number of response regions of deep feed forward networks with piece-wise linear activations , author=. arXiv preprint arXiv:1312.6098 , year=
-
[28]
Geometric combinatorics , volume=
An introduction to hyperplane arrangements , author=. Geometric combinatorics , volume=
-
[29]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Network dissection: Quantifying interpretability of deep visual representations , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[30]
2023 , howpublished =
Language models can explain neurons in language models , author=. 2023 , howpublished =
2023
-
[31]
arXiv preprint arXiv:2305.09863 , year=
Explaining black box text modules in natural language with language models , author=. arXiv preprint arXiv:2305.09863 , year=
-
[32]
arXiv preprint arXiv:2506.05774 , year=
Evaluating neuron explanations: A unified framework with sanity checks , author=. arXiv preprint arXiv:2506.05774 , year=
-
[33]
International conference on machine learning , pages=
Concept bottleneck models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[34]
arXiv preprint arXiv:2305.01610 , year=
Finding neurons in a haystack: Case studies with sparse probing , author=. arXiv preprint arXiv:2305.01610 , year=
-
[35]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[36]
Transformer Circuits Thread , volume=
Mechanistic interpretability, variables, and the importance of interpretable bases , author=. Transformer Circuits Thread , volume=
-
[37]
arXiv preprint arXiv:2209.11895 , year=
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
-
[38]
arXiv preprint arXiv:2404.09932 , year=
Foundational challenges in assuring alignment and safety of large language models , author=. arXiv preprint arXiv:2404.09932 , year=
-
[39]
Nature methods , volume=
InterPLM: discovering interpretable features in protein language models via sparse autoencoders , author=. Nature methods , volume=. 2025 , publisher=
2025
-
[40]
Nature Machine Intelligence , volume=
AI for radiographic COVID-19 detection selects shortcuts over signal , author=. Nature Machine Intelligence , volume=. 2021 , publisher=
2021
-
[41]
arXiv preprint arXiv:2510.15511 , year=
Language models are injective and hence invertible , author=. arXiv preprint arXiv:2510.15511 , year=
-
[42]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[43]
The American Mathematical Monthly , volume=
Stirling's approximation for n!: The ultimate short proof? , author=. The American Mathematical Monthly , volume=. 2000 , publisher=
2000
-
[44]
Journal of Machine Learning Research , year =
Giorgos Borboudakis and Ioannis Tsamardinos , title =. Journal of Machine Learning Research , year =
-
[45]
IEEE Transactions on signal processing , volume=
Generalized orthogonal matching pursuit , author=. IEEE Transactions on signal processing , volume=. 2012 , publisher=
2012
-
[46]
Studia Mathematica , volume =
Volume Approximation of Convex Bodies by Polytopes---A Constructive Method , author =. Studia Mathematica , volume =. 1994 , url =
1994
-
[47]
Asymptotic approximation of smooth convex bodies by general polytopes , volume=. Mathematika , author=. 1999 , pages=. doi:10.1112/S0025579300007609 , number=
-
[48]
Convex Analysis , author =
-
[49]
Proceedings of the 35th International Conference on Machine Learning , pages =
Deep One-Class Classification , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[50]
1999 , publisher=
Formal concept analysis , author=. 1999 , publisher=
1999
-
[51]
Munkres , title =
James R. Munkres , title =. 1984 , isbn =
1984
-
[52]
Aliprantis, Charalambos D. and Border, Kim C. , biburl =. doi:10.1007/3-540-29587-9 , interhash =
-
[53]
Nature communications , volume=
A generalized platform for artificial intelligence-powered autonomous enzyme engineering , author=. Nature communications , volume=. 2025 , publisher=
2025
-
[54]
Cell , volume=
A deep learning approach to antibiotic discovery , author=. Cell , volume=. 2020 , publisher=
2020
-
[55]
arXiv preprint arXiv:2506.12152 , year=
Because we have LLMs, we can and should pursue agentic interpretability , author=. arXiv preprint arXiv:2506.12152 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.