TrioPose: Native Triple-Stream Diffusion Transformers for Pose-Guided Text-to-Image Generation
Pith reviewed 2026-06-27 22:34 UTC · model grok-4.3
The pith
TrioPose introduces a triple-stream diffusion transformer that treats pose as a separate modality to guide text-to-image generation while preserving pretrained stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
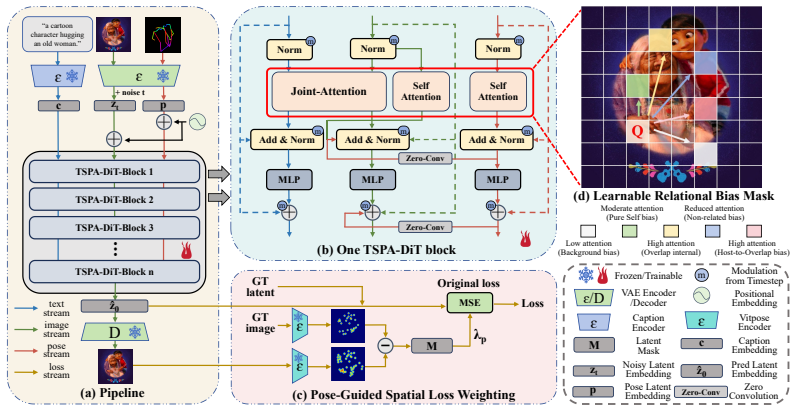
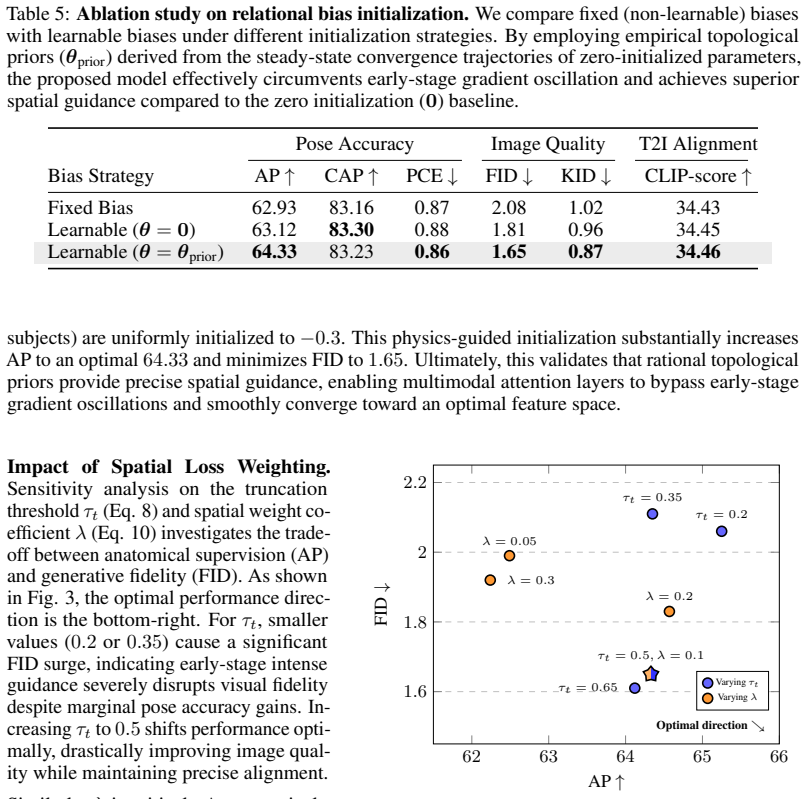
The central claim is that a Triple-Stream Pose-Aware DiT (TSPA-DiT) built on SD3.5M, using layer-wise activation plus zero-initialized dual-residual injection to treat pose as an independent modality, combined with a Learnable Relational Bias Mask that maps topological states to attention soft constraints and a Pose-Guided Spatial Loss Weighting that modulates the diffusion objective via heatmap error maps, achieves state-of-the-art pose-guided generation, reaching 64.33 AP on Human-Art for a 30% gain over prior work while maintaining visual fidelity and text alignment.
What carries the argument
Triple-Stream Pose-Aware DiT (TSPA-DiT) that processes pose as an independent modality using layer-wise activation and zero-initialized dual-residual injection to enforce geometric constraints without disrupting pretrained latents.
If this is right
- Attains 64.33 AP on Human-Art benchmark representing 30% improvement over prior arts.
- Effectively decouples inter-instance interference in multi-person scenarios via the relational bias mask.
- Focuses anatomical supervision on distortion-prone regions through heatmap-derived error maps.
- Preserves pre-trained latent stability while adding native pose guidance to MM-DiT architectures.
- Sets new standards for visual fidelity and text-image semantic alignment in complex multi-human scenes.
Where Pith is reading between the lines
- The same streaming-plus-residual pattern could be tested on other conditioning signals such as depth or segmentation maps.
- Stability preservation suggests the approach may transfer to newer or larger base diffusion models with minimal retuning.
- Occlusion handling via relational masks might reduce failure modes in animation pipelines that require consistent multi-character poses.
- Targeted loss weighting on error-prone regions could be adapted to improve single-person cases where limb accuracy still matters.
Load-bearing premise
The layer-wise activation and zero-initialized dual-residual injection can enforce geometric pose constraints while fully preserving the pre-trained latent distributions of SD3.5M without introducing new instabilities or artifacts.
What would settle it
Removing the zero-initialized dual-residual injection and measuring whether AP on Human-Art falls below prior methods or whether visual artifacts rise in generated multi-person images.
Figures

read the original abstract
Pose-guided text-to-image generation often suffers from limb distortions and feature crosstalk in complex multi-person scenarios. While existing UNet-based adapters struggle with long-range spatial dependencies, emerging Multimodal Diffusion Transformers (MM-DiTs) offer superior global modeling. However, naive signal concatenation in MM-DiTs severely disrupts pre-trained latent distributions. To address this, we propose TrioPose, a native pose-driven framework built upon the SD3.5M architecture. Specifically, we introduce a Triple-Stream Pose-Aware DiT (TSPA-DiT) that treats pose as an independent modality. It employs layer-wise activation and zero-initialized dual-residual injection to smoothly enforce geometric constraints while preserving pre-trained latent stability. To resolve severe multi-instance occlusions, we design a Learnable Relational Bias Mask that categorizes topological connectivity into fine-grained physical states, mapping them into continuous attention soft constraints to effectively decouple inter-instance interference. Furthermore, a Pose-Guided Spatial Loss Weighting strategy modulates the native diffusion objective using heatmap-derived error maps, focusing anatomical supervision strictly on distortion-prone regions. Extensive experiments demonstrate that TrioPose achieves state-of-the-art performance across challenging benchmarks, including Human-Art, CrowdPose, and OCHuman. Notably, it attains an AP of $64.33$ on Human-Art, representing a $30\%$ improvement over prior arts, while setting new standards for visual fidelity and text-image semantic alignment in complex multi-human generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TrioPose, a pose-guided text-to-image framework built on SD3.5M that introduces a Triple-Stream Pose-Aware DiT (TSPA-DiT) treating pose as an independent modality via layer-wise activation and zero-initialized dual-residual injection, a Learnable Relational Bias Mask for categorizing topological connectivity in multi-person occlusions, and Pose-Guided Spatial Loss Weighting using heatmap-derived error maps. It claims state-of-the-art results on Human-Art, CrowdPose, and OCHuman, with a reported AP of 64.33 on Human-Art representing a 30% improvement over prior work, alongside gains in visual fidelity and text-image alignment.
Significance. If the empirical claims hold under rigorous validation, the approach could advance multi-person pose-guided generation by demonstrating how native triple-stream DiT modifications can enforce geometric constraints without destabilizing pre-trained latent distributions, offering a template for modality-specific adapters in diffusion transformers.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central SOTA claim of AP=64.33 on Human-Art (30% improvement) is presented without any reported baselines, ablation tables, metric computation details, or error bars; this renders the quantitative result unverifiable and load-bearing for the paper's primary contribution.
- [§3.2] §3.2 (TSPA-DiT description): the assertion that zero-initialized dual-residual injection 'smoothly enforce[s] geometric constraints while preserving pre-trained latent stability' lacks supporting analysis (e.g., distribution-shift metrics or artifact quantification) and is the weakest assumption underlying the architectural novelty.
minor comments (2)
- [§3.3] Notation for 'Learnable Relational Bias Mask' and 'Pose-Guided Spatial Loss Weighting' is introduced without explicit equations or pseudocode, making reproduction difficult.
- [Abstract] The abstract mentions 'extensive experiments' but the provided text supplies no dataset splits, training hyperparameters, or inference settings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's verifiability.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central SOTA claim of AP=64.33 on Human-Art (30% improvement) is presented without any reported baselines, ablation tables, metric computation details, or error bars; this renders the quantitative result unverifiable and load-bearing for the paper's primary contribution.
Authors: We agree that the reported AP value and improvement percentage require explicit supporting evidence to be verifiable. In the revised manuscript we will expand the experiments section to include full baseline tables comparing against prior methods, complete ablation studies, precise details on how the AP metric is computed (including the pose estimator and evaluation protocol), and error bars from repeated runs. These additions will directly substantiate the central quantitative claim. revision: yes
-
Referee: [§3.2] §3.2 (TSPA-DiT description): the assertion that zero-initialized dual-residual injection 'smoothly enforce[s] geometric constraints while preserving pre-trained latent stability' lacks supporting analysis (e.g., distribution-shift metrics or artifact quantification) and is the weakest assumption underlying the architectural novelty.
Authors: We acknowledge that the claim would benefit from quantitative backing. In the revision we will augment §3.2 (or add a dedicated analysis subsection) with distribution-shift measurements such as latent-space statistics or KL divergence between the original SD3.5M and the modified model, together with artifact quantification via both visual inspection and automated metrics. This material will be placed in the main text or supplementary material as space permits. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript introduces an empirical neural architecture (TSPA-DiT with layer-wise activation, dual-residual injection, relational bias mask, and spatial loss weighting) whose performance claims rest on experimental results against external benchmarks (Human-Art, CrowdPose, OCHuman). No equations, first-principles derivations, or fitted-parameter predictions appear that could reduce to the inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked in the supplied text. The work is therefore self-contained against external evaluation and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained SD3.5M latent distributions remain stable when pose is injected via layer-wise activation and zero-initialized dual-residual connections.
invented entities (2)
-
Triple-Stream Pose-Aware DiT (TSPA-DiT)
no independent evidence
-
Learnable Relational Bias Mask
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Soon Yau Cheong, Armin Mustafa, and Andrew Gilbert. Kpe: Keypoint pose encoding for transformer-based image generation.arXiv preprint arXiv:2203.04907, 2022
-
[4]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[5]
Posenet similarity
freshsomebody. Posenet similarity. https://github.com/freshsomebody/ posenet-similarity, 2023. Accessed: 2026-05-05
2023
-
[6]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[7]
Coordinate- based texture inpainting for pose-guided human image generation
Artur Grigorev, Artem Sevastopolsky, Alexander Vakhitov, and Victor Lempitsky. Coordinate- based texture inpainting for pose-guided human image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12135–12144, 2019
2019
-
[8]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[9]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[10]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[11]
Human-art: A versatile human-centric dataset bridging natural and artificial scenes
Xuan Ju, Ailing Zeng, Jianan Wang, Qiang Xu, and Lei Zhang. Human-art: A versatile human-centric dataset bridging natural and artificial scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 618–629, 2023
2023
-
[12]
Humansd: A native skeleton-guided diffusion model for human image generation
Xuan Ju, Ailing Zeng, Chenchen Zhao, Jianan Wang, Lei Zhang, and Qiang Xu. Humansd: A native skeleton-guided diffusion model for human image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15988–15998, 2023
2023
-
[13]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Crowdpose: Effi- cient crowded scenes pose estimation and a new benchmark
Jiefeng Li, Can Wang, Hao Zhu, Yihuan Mao, Hao-Shu Fang, and Cewu Lu. Crowdpose: Effi- cient crowded scenes pose estimation and a new benchmark. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10863–10872, 2019
2019
-
[15]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22511–22521, 2023
2023
-
[16]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 10
2014
-
[17]
Verbal-person nets: Pose- guided multi-granularity language-to-person generation.IEEE Transactions on Neural Networks and Learning Systems, 34(11):8589–8601, 2022
Deyin Liu, Lin Wu, Feng Zheng, Lingqiao Liu, and Meng Wang. Verbal-person nets: Pose- guided multi-granularity language-to-person generation.IEEE Transactions on Neural Networks and Learning Systems, 34(11):8589–8601, 2022
2022
-
[18]
Shibang Liu, Xuemei Xie, and Guangming Shi. Kb-dmgen: Knowledge-based global guidance and dynamic pose masking for human image generation.arXiv preprint arXiv:2507.20083, 2025
-
[19]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Learning semantic person image generation by region-adaptive normalization
Zhengyao Lv, Xiaoming Li, Xin Li, Fu Li, Tianwei Lin, Dongliang He, and Wangmeng Zuo. Learning semantic person image generation by region-adaptive normalization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10806–10815, 2021
2021
-
[21]
Pose guided person image generation.Advances in neural information processing systems, 30, 2017
Liqian Ma, Xu Jia, Qianru Sun, Bernt Schiele, Tinne Tuytelaars, and Luc Van Gool. Pose guided person image generation.Advances in neural information processing systems, 30, 2017
2017
-
[22]
Controllable person image synthesis with attribute-decomposed gan
Yifang Men, Yiming Mao, Yuning Jiang, Wei-Ying Ma, and Zhouhui Lian. Controllable person image synthesis with attribute-decomposed gan. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5084–5093, 2020
2020
-
[23]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, 2024
2024
-
[24]
Synthesizing coherent story with auto-regressive latent diffusion models
Xichen Pan, Pengda Qin, Yuhong Li, Hui Xue, and Wenhu Chen. Synthesizing coherent story with auto-regressive latent diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2920–2930, 2024
2024
-
[25]
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Yanjie Pan, Qingdong He, Zhengkai Jiang, Pengcheng Xu, Chaoyi Wang, Jinlong Peng, Haox- uan Wang, Yun Cao, Zhenye Gan, Mingmin Chi, et al. Pixelponder: Dynamic patch adaptation for enhanced multi-conditional text-to-image generation.arXiv preprint arXiv:2503.06684, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[28]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[30]
Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958, 2014
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958, 2014
1929
-
[31]
Stable- pose: Leveraging transformers for pose-guided text-to-image generation.Advances in Neural Information Processing Systems, 37:65670–65698, 2024
Jiajun Wang, Morteza Ghahremani, Yitong Li, Björn Ommer, and Christian Wachinger. Stable- pose: Leveraging transformers for pose-guided text-to-image generation.Advances in Neural Information Processing Systems, 37:65670–65698, 2024
2024
-
[32]
Text-guided human image manipulation via image-text shared space.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6486–6500, 2021
Xiaogang Xu, Ying-Cong Chen, Xin Tao, and Jiaya Jia. Text-guided human image manipulation via image-text shared space.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6486–6500, 2021. 11
2021
-
[33]
Text guided human image manipulation via image-text shared space.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6486–6500, 2021
Xiaogang Xu, Ying-Cong Chen, Xin Tao, and Jiaya Jia. Text guided human image manipulation via image-text shared space.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6486–6500, 2021
2021
-
[34]
Vitpose++: Vision transformer for generic body pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(2):1212–1230, 2023
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vitpose++: Vision transformer for generic body pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(2):1212–1230, 2023
2023
-
[35]
Rethink sparse signals for pose- guided text-to-image generation
Wenjie Xuan, Jing Zhang, Juhua Liu, Bo Du, and Dacheng Tao. Rethink sparse signals for pose- guided text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15896–15906, 2025
2025
-
[36]
Grpose: Learning graph relations for human image generation with pose priors
Xiangchen Yin, Donglin Di, Lei Fan, Hao Li, Wei Chen, Yang Song, Xiao Sun, Xun Yang, et al. Grpose: Learning graph relations for human image generation with pose priors. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9526–9534, 2025
2025
-
[37]
Vtnfp: An image-based virtual try-on network with body and clothing feature preservation
Ruiyun Yu, Xiaoqi Wang, and Xiaohui Xie. Vtnfp: An image-based virtual try-on network with body and clothing feature preservation. InProceedings of the IEEE/CVF international conference on computer vision, pages 10511–10520, 2019
2019
-
[38]
Pise: Person image synthesis and editing with decoupled gan
Jinsong Zhang, Kun Li, Yu-Kun Lai, and Jingyu Yang. Pise: Person image synthesis and editing with decoupled gan. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7982–7990, 2021
2021
-
[39]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[40]
Pose2seg: Detection free human instance segmentation
Song-Hai Zhang, Ruilong Li, Xin Dong, Paul Rosin, Zixi Cai, Xi Han, Dingcheng Yang, Haozhi Huang, and Shi-Min Hu. Pose2seg: Detection free human instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 889–898, 2019
2019
-
[41]
Uni-controlnet: All-in-one control to text-to-image diffusion models
Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, Lu Yuan, and Kwan-Yee K Wong. Uni-controlnet: All-in-one control to text-to-image diffusion models. Advances in neural information processing systems, 36:11127–11150, 2023
2023
-
[42]
Champ: Controllable and consistent human image animation with 3d parametric guidance
Shenhao Zhu, Junming Leo Chen, Zuozhuo Dai, Zilong Dong, Yinghui Xu, Xun Cao, Yao Yao, Hao Zhu, and Siyu Zhu. Champ: Controllable and consistent human image animation with 3d parametric guidance. InEuropean Conference on Computer Vision, pages 145–162. Springer, 2024
2024
-
[43]
Be your own prada: Fashion synthesis with structural coherence
Shizhan Zhu, Raquel Urtasun, Sanja Fidler, Dahua Lin, and Chen Change Loy. Be your own prada: Fashion synthesis with structural coherence. InProceedings of the IEEE international conference on computer vision, pages 1680–1688, 2017
2017
-
[44]
oil painting
Zhen Zhu, Tengteng Huang, Baoguang Shi, Miao Yu, Bofei Wang, and Xiang Bai. Progressive pose attention transfer for person image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2347–2356, 2019. 12 A Appendix: Data Processing Details This section details our data standardization and annotation pipeline...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.