Dash2Sim: Closed-Loop Driving Simulation from in-the-wild Dashcam Videos
Pith reviewed 2026-06-27 22:13 UTC · model grok-4.3
The pith
Dash2Sim converts monocular dashcam videos into metric geo-referenced 4D driving logs verifiable against independent maps without annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
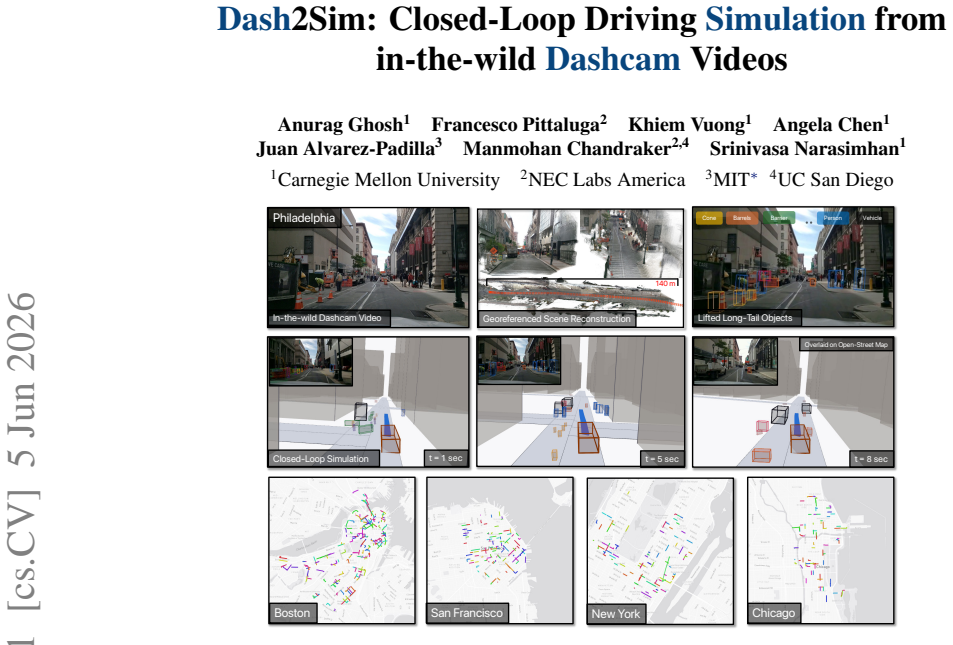
Dash2Sim turns in-the-wild monocular dashcam videos into metric, geo-referenced 4D driving logs compatible with existing simulators, and verifies each one against an independently maintained map without annotations. Applied to a large video corpus it produces the ROADWork4D benchmark of 4,244 scenes containing 2.7M 3D objects across 17 cities. On the verified closed-loop subset ROADWork4D-CL all tested planners fail to perform the lane changes required by temporary work-zone channels.
What carries the argument
Dash2Sim pipeline that recovers metric 4D scenes from monocular video and performs annotation-free map verification for simulator compatibility.
If this is right
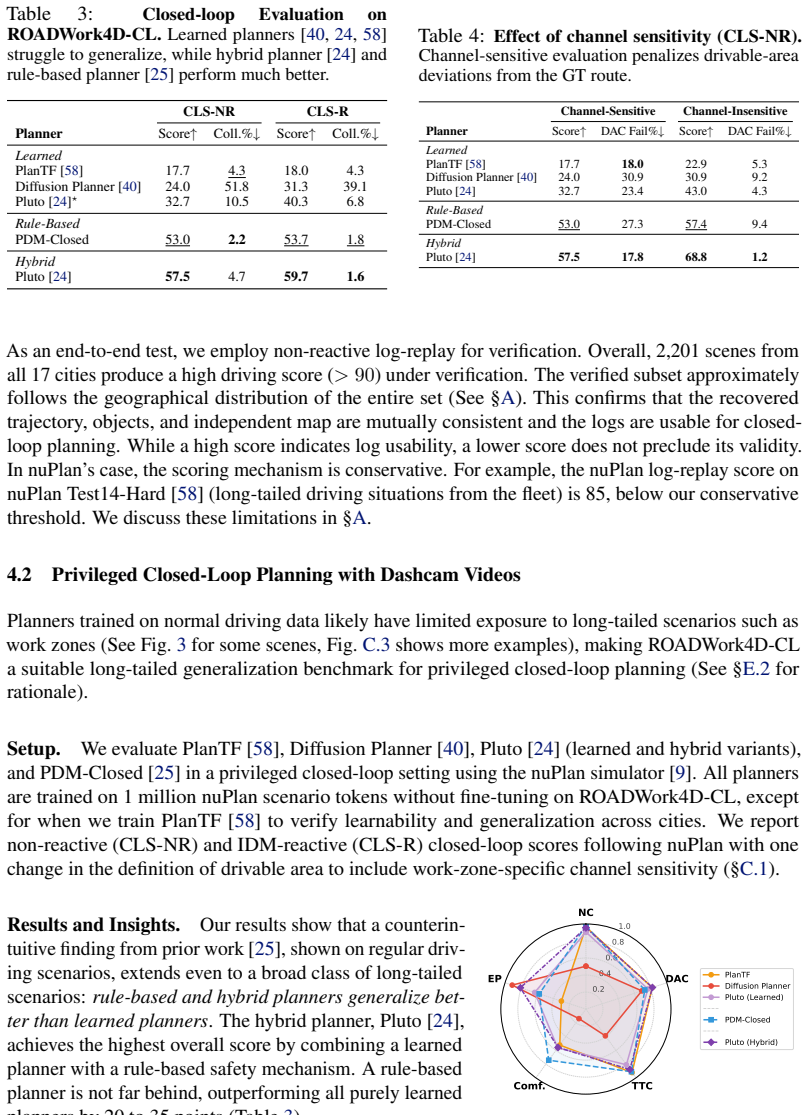
- Rule-based, hybrid, and learning-based planners all fail to execute required lane changes in verified work-zone scenarios.
- Dense depth recovered by the method raises novel-view synthesis quality by up to 19 percent on perceptual metrics.
- The benchmark supplies 2,201 closed-loop scenes that expose generalization gaps in current planning approaches.
- Work-zone situations captured from real dashcams become usable for simulation without manual annotation.
Where Pith is reading between the lines
- Dashcam video could become a scalable source for populating simulators with rare driving conditions beyond the 17 cities already processed.
- The same reconstruction step might support sensor simulation pipelines that condition on recovered depth rather than synthetic assets.
- Extending verification to other long-tailed events such as construction detours or weather changes would test the same monocular-to-metric premise.
Load-bearing premise
Monocular video alone supplies enough information to recover metric-accurate 4D scenes that stay faithful when used for closed-loop simulation and map verification.
What would settle it
Running the generated 4D logs through a simulator and finding that the resulting vehicle paths or object placements deviate measurably from the original dashcam trajectories or the independent map data.
Figures




read the original abstract
Self-driving simulations typically rely on data collected in a small number of cities or on hand-authored synthetic scenarios. Dashcam videos cover a far broader range of locations and situations, including rare or long-tailed scenarios. They are considered less usable for simulation because it is difficult to recover accurate 4D scenes from monocular in-the-wild videos. Work zones are one such class of long-tailed situations that dashcams capture. We present Dash2Sim, a framework that turns in-the-wild monocular dashcam videos into metric, geo-referenced 4D driving logs compatible with existing simulators, and verifies eachone against an independently maintained map without annotations. We apply Dash2Sim to a large video corpus to create the ROADWork4D benchmark dataset, which spans 4,244 scenes with 2.7M 3D objects across 17 cities. On a verified subset ROADWork4D-CL (2,201 scenes), we study privileged closed-loop planners and find that work zone scenarios are difficult: while rule-based and hybrid planners generalize better than learning-based ones, all fall short, failing to make the lane changes that temporary work zone channels require. Beyond planning, dense depth recovered by Dash2Sim improves novel-view synthesis quality by up to 19% on perceptual metrics, suggesting its potential to provide rich conditioning for closed-loop sensor simulation from monocular videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Dash2Sim, a framework that converts in-the-wild monocular dashcam videos into metric, geo-referenced 4D driving logs compatible with simulators by verifying against independently maintained maps without annotations. It creates the ROADWork4D dataset spanning 4,244 scenes with 2.7M 3D objects across 17 cities, and on the ROADWork4D-CL subset, demonstrates that all tested privileged closed-loop planners fail to execute required lane changes in work zone scenarios. It also reports that dense depth from Dash2Sim improves novel-view synthesis by up to 19%.
Significance. If the reconstructions are indeed metric-accurate and faithful, this work would be significant for enabling large-scale, diverse driving simulations from readily available dashcam data, particularly for rare events like work zones, and could provide a valuable benchmark for planner evaluation in closed-loop settings.
major comments (2)
- [Abstract and method description] Abstract and method description: The central claim that monocular video yields metric-accurate 4D logs via map verification lacks any reported quantitative validation such as scale-error statistics, absolute trajectory error against ground truth (e.g., RTK or LiDAR), or consistency checks across the 17 cities. This is load-bearing for attributing planner failures to planner limitations rather than reconstruction errors.
- [Experiments on ROADWork4D-CL] Experiments on ROADWork4D-CL: The evaluation of planners shows failures in lane changes, but without details on how the 4D logs are integrated into the simulator or any error analysis of the reconstruction, it is unclear if the results are due to the method or data quality.
minor comments (2)
- [Abstract] Typo: 'eachone' should be 'each one'.
- [Abstract] The abstract states high-level findings but supplies no equations, implementation details, or quantitative planner results, making it difficult to assess the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation and experimental clarity. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and method description] Abstract and method description: The central claim that monocular video yields metric-accurate 4D logs via map verification lacks any reported quantitative validation such as scale-error statistics, absolute trajectory error against ground truth (e.g., RTK or LiDAR), or consistency checks across the 17 cities. This is load-bearing for attributing planner failures to planner limitations rather than reconstruction errors.
Authors: Our method establishes metric scale and geo-referencing through explicit verification of each reconstructed scene against independently maintained maps, without requiring additional sensors or annotations. We do not report scale-error statistics or absolute trajectory error against RTK/LiDAR because no such ground-truth data exists for these in-the-wild monocular dashcam videos. We will revise the method section to describe the map-verification procedure in greater detail, including the specific consistency criteria applied across the 17 cities and any indirect checks performed. revision: partial
-
Referee: [Experiments on ROADWork4D-CL] Experiments on ROADWork4D-CL: The evaluation of planners shows failures in lane changes, but without details on how the 4D logs are integrated into the simulator or any error analysis of the reconstruction, it is unclear if the results are due to the method or data quality.
Authors: We agree that additional details are warranted. In the revised manuscript we will add an explicit description of how the metric 4D logs are imported and used within the closed-loop simulator, including coordinate-frame alignment and dynamic object handling. For reconstruction error analysis we note the inherent limitation that direct ground-truth comparisons are unavailable; however, the map-verification step serves as the primary fidelity check. We will also include further qualitative examples of reconstruction quality in the supplement. revision: yes
- Direct quantitative metrics such as scale-error statistics or absolute trajectory error against RTK/LiDAR ground truth cannot be reported, as no such high-precision ground truth is available for the in-the-wild dashcam videos used to construct ROADWork4D.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents a technical framework (Dash2Sim) for converting monocular dashcam videos into metric, geo-referenced 4D logs that are then verified against independently maintained external maps. No equations, derivations, or self-referential definitions appear in the abstract or described method. The central claims rest on producing outputs that can be checked against external data sources rather than on internal fits, parameter renamings, or self-citation chains that reduce the result to its inputs by construction. This matches the default expectation for most papers and the reader's explicit assessment of score 1.0 with no reducing steps. Concerns about quantitative validation of scale accuracy belong to correctness or evidence strength, not circularity per the analysis rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Geiger, P
A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the KITTI vision benchmark suite. InCVPR, 2012
2012
-
[2]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuScenes: A multimodal dataset for autonomous driving. InCVPR, 2020
2020
-
[3]
Chang, J
M.-F. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Ramanan, and J. Hays. Argoverse: 3D tracking and forecasting with rich maps. InCVPR, 2019
2019
-
[4]
Wilson, W
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Pontes, D. Ramanan, P. Carr, and J. Hays. Argoverse 2: Next generation datasets for self-driving perception and forecasting. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[5]
Ettinger, S
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y . Chai, B. Sapp, C. R. Qi, Y . Zhou, Z. Yang, A. Chouard, P. Sun, J. Ngiam, V . Vasudevan, A. McCauley, J. Shlens, and D. Anguelov. Large scale interactive motion forecasting for autonomous driving: The Waymo open motion dataset. InICCV, 2021
2021
-
[6]
R. Xu, H. Lin, W. Jeon, H. Feng, Y . Zou, L. Sun, J. Gorman, E. Tolstaya, S. Tang, B. White, B. Sapp, M. Tan, J.-J. Hwang, and D. Anguelov. WOD-E2E: Waymo open dataset for end-to-end driving in challenging long-tail scenarios.arXiv preprint arXiv:2510.26125, 2025
arXiv 2025
-
[7]
Dauner, M
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta. NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InNeurIPS Datasets and Benchmarks Track, 2024
2024
-
[8]
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y . Miron, M. Aiello, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta. Pseudo-simulation for autonomous driving. InCoRL, 2025
2025
-
[9]
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. M. Wolff, A. H. Lang, L. Fletcher, O. Beijbom, and S. Omari. nuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810, 2021
Pith/arXiv arXiv 2021
-
[10]
Dosovitskiy, G
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun. CARLA: An open urban driving simulator. InCoRL, 2017
2017
-
[11]
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan. Bench2Drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving. InNeurIPS Datasets and Benchmarks Track, 2024
2024
-
[12]
S. Gerstenecker, A. Geiger, and K. Renz. Fail2Drive: Benchmarking closed-loop driving generalization.arXiv preprint arXiv:2604.08535, 2026
Pith/arXiv arXiv 2026
-
[13]
Hallgarten, J
M. Hallgarten, J. Zapata, M. Stoll, K. Renz, and A. Zell. Can vehicle motion planning generalize to realistic long-tail scenarios? InIROS, 2024
2024
-
[14]
30 https://www.autoinsurance.com/research/ dash-cam-usage-report/, 2026
autoinsurance. 30 https://www.autoinsurance.com/research/ dash-cam-usage-report/, 2026. Accessed: 2026-04-29
2026
-
[15]
Allshire, H
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa. Visual imitation enables contextual humanoid control. InCoRL, 2025
2025
-
[16]
Hartley and A
R. Hartley and A. Zisserman.Multiple View Geometry in Computer Vision. 2003. 29
2003
-
[17]
Ghosh, S
A. Ghosh, S. Zheng, R. Tamburo, K. Vuong, J. Alvarez-Padilla, H. Zhu, M. Cardei, N. Dunn, C. Mertz, and S. G. Narasimhan. Roadwork: A dataset and benchmark for learning to recognize, observe, analyze and drive through work zones. InICCV, 2025
2025
-
[18]
Zendel, K
O. Zendel, K. Honauer, M. Murschitz, D. Steininger, and G. F. Dominguez. Wilddash-creating hazard-aware benchmarks. InECCV, 2018
2018
-
[19]
Zendel, M
O. Zendel, M. Sch ¨orghuber, B. Rainer, M. Murschitz, and C. Beleznai. Unifying panoptic segmentation for autonomous driving. InCVPR, 2022
2022
-
[20]
S. K. Bashetty, H. B. Amor, and G. Fainekos. Deepcrashtest: Turning dashcam videos into virtual crash tests for automated driving systems. InICRA, 2020
2020
-
[21]
Y . Miao, G. Fainekos, B. Hoxha, H. Okamoto, D. Prokhorov, and S. Mitra. From dashcam videos to driving simulations: Stress testing automated vehicles against rare events. InAAAI Workshops, 2025
2025
-
[22]
J. Bote. Cruise vehicle gets stuck in wet concrete while driving in San Francisco. https:// www.sfgate.com/tech/article/cruise-stuck-wet-concrete-sf-18297946.php , 2023
2023
-
[23]
Waymo halts freeway rides after robotaxis strug- gle in construction zones
TechCrunch. Waymo halts freeway rides after robotaxis strug- gle in construction zones. https://techcrunch.com/2026/05/21/ waymo-halts-freeway-rides-after-robotaxis-struggle-in-construction-zones/ , 2026
2026
- [24]
-
[25]
Dauner, M
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta. Parting with misconceptions about learning-based vehicle motion planning. InCoRL, 2023
2023
-
[26]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. InICRA, 2024
2024
-
[27]
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158, 2024
Pith/arXiv arXiv 2024
-
[28]
S. Y . Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhang, et al. Datacomp: In search of the next generation of multimodal datasets. NeurIPS, 2023
2023
-
[29]
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
Pith/arXiv arXiv 2024
-
[30]
R. Wagner, O. S. Tas, J. Villa, F. Hauser, Y . Shen, M. Steiner, D. Strutz, C. Fernandez, C. Kinzig, G. S. Guitierrez-Cabello, et al. Longtail driving scenarios with reasoning traces: The kitscenes longtail dataset.arXiv preprint arXiv:2603.23607, 2026
Pith/arXiv arXiv 2026
-
[32]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, et al. Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575, 2025. 30
Pith/arXiv arXiv 2025
-
[33]
X. Ren, Y . Lu, T. Cao, R. Gao, S. Huang, A. Sabour, T. Shen, T. Pfaff, J. Z. Wu, R. Chen, et al. Cosmos-drive-dreams: Scalable synthetic driving data generation with world foundation models.arXiv preprint arXiv:2506.09042, 2025
arXiv 2025
-
[34]
X. Ren, T. Shen, J. Huang, H. Ling, Y . Lu, M. Nimier-David, T. M¨uller, A. Keller, S. Fidler, and J. Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InCVPR, 2025
2025
-
[35]
J. Wang, B. Sun, Y . Bai, V . Casser, S. Peng, Z. Zhu, M.-L. Shih, X. Masotto, S.-Y . Su, K. V . Parvate, et al. Sensor2sensor: Cross-embodiment sensor conversion for autonomous driving. arXiv preprint arXiv:2605.22809, 2026
Pith/arXiv arXiv 2026
-
[36]
H. Zhou, L. Lin, J. Wang, Y . Lu, D. Bai, B. Liu, Y . Wang, A. Geiger, and Y . Liao. Hugsim: A real-time, photo-realistic and closed-loop simulator for autonomous driving.TPAMI, 2025
2025
-
[37]
Z. Chen, J. Yang, J. Huang, R. De Lutio, J. Martinez Esturo, B. Ivanovic, O. Litany, Z. Gojcic, S. Fidler, M. Pavone, et al. Omnire: Omni urban scene reconstruction. InICLR, 2025
2025
-
[38]
Chitta, D
K. Chitta, D. Dauner, and A. Geiger. Sledge: Synthesizing driving environments with generative models and rule-based traffic. InECCV, 2024
2024
-
[39]
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu, et al. Hydra- mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
Pith/arXiv arXiv 2024
-
[40]
Zheng, R
Y . Zheng, R. Liang, K. Zheng, J. Zheng, L. Mao, J. Li, W. Gu, R. Ai, S. Li, X. Zhan, et al. Diffusion-based planning for autonomous driving with flexible guidance. InICLR, 2025
2025
- [41]
-
[42]
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li. Drivelm: Driving with graph visual question answering. InECCV, 2024
2024
-
[43]
X. Zhou, X. Han, F. Yang, Y . Ma, V . Tresp, and A. Knoll. Opendrivevla: Towards end-to-end autonomous driving with large vision language action model. InAAAI, 2026
2026
-
[44]
Z. Xu, Y . Bai, Y . Zhang, Z. Li, F. Xia, K.-Y . K. Wong, J. Wang, and H. Zhao. Drivegpt4-v2: Harnessing large language model capabilities for enhanced closed-loop autonomous driving. InCVPR, 2025
2025
-
[45]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, 2025
2025
-
[46]
J. Lu, J. Guan, Z. Huang, J. Li, G. Li, L. Kong, Y . Li, H. Wang, S. Xu, Y . Luo, et al. Onevl: One-step latent reasoning and planning with vision-language explanation.arXiv preprint arXiv:2604.18486, 2026
Pith/arXiv arXiv 2026
-
[47]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[48]
W. Huang, J. Zhang, S. Li, T. Jia, J. Duan, Y . Cheng, J. Cho, M. Wallingford, R. Soraki, C. D. Kim, et al. Wilddet3d: Scaling promptable 3d detection in the wild.arXiv preprint arXiv:2604.08626, 2026
Pith/arXiv arXiv 2026
-
[49]
A. R. Zamir, T. Wekel, P. Agrawal, C. Wei, J. Malik, and S. Savarese. Generic 3d representation via pose estimation and matching. InECCV, 2016. 31
2016
-
[50]
Vuong, R
K. Vuong, R. Tamburo, and S. G. Narasimhan. Toward planet-wide traffic camera calibration. InWACV, 2024
2024
-
[51]
Vuong, A
K. Vuong, A. Ghosh, D. Ramanan, S. Narasimhan, and S. Tulsiani. Aerialmegadepth: Learning aerial-ground reconstruction and view synthesis. InCVPR, 2025
2025
-
[52]
Berton and C
G. Berton and C. Masone. Megaloc: One retrieval to place them all. InCVPR Workshops, 2025
2025
-
[53]
OpenStreetMap
OpenStreetMap contributors. OpenStreetMap. https://www.openstreetmap.org, 2017. Data retrieved from https://planet.openstreetmap.org
2017
-
[54]
Sriram, B
N. Sriram, B. Liu, F. Pittaluga, and M. Chandraker. Smart: Simultaneous multi-agent recurrent trajectory prediction. InECCV, 2020
2020
-
[55]
P. Cai, Y . Lee, Y . Luo, and D. Hsu. Summit: A simulator for urban driving in massive mixed traffic. InICRA, 2020
2020
-
[56]
Eskenazi
J. Eskenazi. Waymo rolls toward San Francisco Airport. a showdown is brewing. https://missionlocal.org/2024/12/ waymo-rolls-toward-san-francisco-airport-showdown-brewing/, 2024
2024
-
[57]
Sural, N
S. Sural, N. Sahu, and R. Rajkumar. Workzone3d: A multimodal dataset for 3d work zone perception in autonomous driving. InWACV, 2026
2026
-
[58]
Cheng, Y
J. Cheng, Y . Chen, X. Mei, B. Yang, B. Li, and M. Liu. Rethinking imitation-based planner for autonomous driving. InICRA, 2024
2024
-
[59]
Treiber, A
M. Treiber, A. Hennecke, and D. Helbing. Congested traffic states in empirical observations and microscopic simulations.Physical review E, 2000
2000
-
[60]
L. Pan, D. Bar´ath, M. Pollefeys, and J. L. Sch¨onberger. Global structure-from-motion revisited. InECCV, 2024
2024
-
[61]
L. Pan, J. L. Sch¨onberger, and M. Pollefeys. Global structure-from-motion meets feedforward reconstruction. InCVPR, 2026
2026
-
[62]
S. Hagedorn, L. Donkov, A. Distelzweig, and A. P. Condurache. When planners meet reality: How learned, reactive traffic agents shift nuplan benchmarks.arXiv preprint arXiv:2510.14677, 2025
arXiv 2025
-
[63]
R. Luo, H. Yang, M. Watson, A. Sharma, S. Veer, E. Schmerling, and M. Pavone. Sim2val: Leveraging correlation across test platforms for variance-reduced metric estimation.arXiv preprint arXiv:2506.20553, 2025
arXiv 2025
-
[64]
Pinto and A
L. Pinto and A. Gupta. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. InICRA, 2016
2016
-
[65]
Levine, P
S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection.IJRR, 2018
2018
-
[66]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. Decision transformer: Reinforcement learning via sequence modeling.NeurIPS, 2021
2021
- [67]
-
[68]
G. L. Smith, S. F. Schmidt, and L. A. McGee.Application of statistical filter theory to the optimal estimation of position and velocity on board a circumlunar vehicle. 1962. 32
1962
-
[69]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[70]
N. V . Keetha, N. M¨uller, J. Sch¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction. In3DV, 2025
2025
-
[71]
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
Pith/arXiv arXiv 2023
-
[72]
S. Gao, J. Yang, L. Chen, K. Chitta, Y . Qiu, A. Geiger, J. Zhang, and H. Li. Vista: A generalizable driving world model with high fidelity and versatile controllability.NeurIPS, 2024
2024
-
[73]
X. Wang, Z. Zhu, G. Huang, X. Chen, J. Zhu, and J. Lu. Drivedreamer: Towards real-world- drive world models for autonomous driving. InECCV, 2024
2024
-
[74]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[75]
Ghildyal and F
A. Ghildyal and F. Liu. Shift-tolerant perceptual similarity metric. InECCV, 2022
2022
-
[76]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.NeurIPS, 2017
2017
-
[77]
T. Kynk¨a¨anniemi, T. Karras, M. Aittala, T. Aila, and J. Lehtinen. The role of imagenet classes in fr\’echet inception distance.arXiv preprint arXiv:2203.06026, 2022
arXiv 2022
-
[78]
Tumanyan, O
N. Tumanyan, O. Bar-Tal, S. Bagon, and T. Dekel. Splicing vit features for semantic appearance transfer. InCVPR, 2022
2022
-
[79]
S. Fu, N. Tamir, S. Sundaram, L. Chai, R. Zhang, T. Dekel, and P. Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023
Pith/arXiv arXiv 2023
-
[80]
C. Wickrema, S. Leary, S. Sarkar, M. Giglio, E. Bianchi, E. Mace, and M. Twardowski. Benchmarking image similarity metrics for novel view synthesis applications.arXiv preprint arXiv:2506.12563, 2025
arXiv 2025
-
[81]
M. Khan, H. Fazlali, D. Sharma, T. Cao, D. Bai, Y . Ren, and B. Liu. Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction. InICRA, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.