Liberating LLM Capabilities in Full-Duplex Speech Models
Pith reviewed 2026-07-01 00:10 UTC · model grok-4.3
The pith
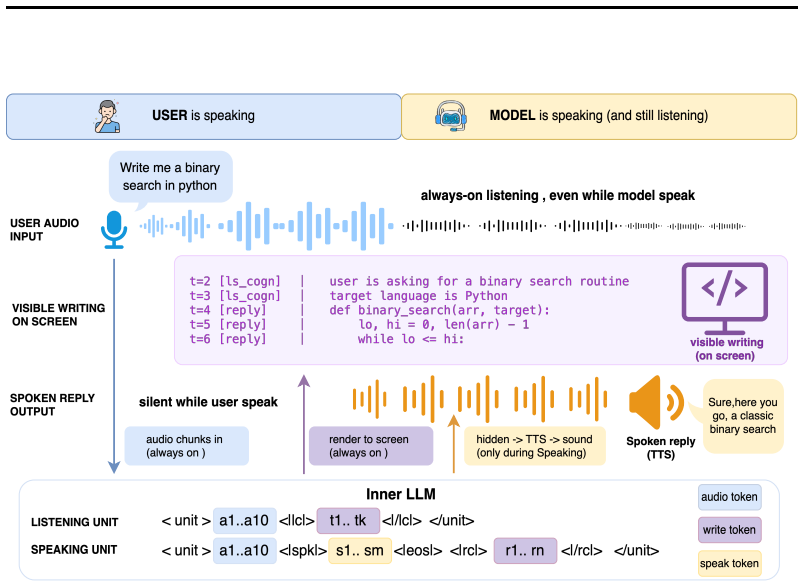
Visible writing serves as a first-class output channel for full-duplex speech LLMs without losing responsiveness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a single autoregressive LLM can continuously listen to user audio, write visible free-form text as its primary output, and speak a realtime oral response in parallel under a shared causal attention context, with this tri-channel Listen-Write-Speak behavior implemented entirely through a Token Schema and learned from a two-stage pipeline of synthesized per-second cognitive annotations consistent with the input timeline.
What carries the argument
The Token Schema that defines and enforces the tri-channel Listen-Write-Speak behavior under shared causal attention.
If this is right
- Visible writing enables text-native tasks such as code generation and structured analysis during spoken interaction.
- The approach yields strong full-duplex performance on Full-Duplex-Bench.
- It reaches 4.72 on VoiceBench AlpacaEval while achieving 92.6 percent writing-speaking consistency.
- It consistently outperforms internal ablations on URO-Bench.
Where Pith is reading between the lines
- The same token-based separation of output channels could be tested with additional modalities such as structured data tables or diagrams.
- Per-second annotation synthesis might be adapted to train models that expose intermediate reasoning traces in non-speech settings.
- Users could use the visible writing trace as a verifiable record to correct or extend the spoken response after the fact.
Load-bearing premise
The Token Schema by itself, without architectural modifications, is sufficient to enforce tri-channel Listen-Write-Speak behavior under shared causal attention when trained on the synthesized per-second cognitive annotations.
What would settle it
A controlled test showing whether models trained only with the Token Schema and per-second annotations produce visible writing alongside speech while maintaining realtime responsiveness and at least 90 percent writing-speaking consistency.
Figures
read the original abstract
Speech-based large language models are typically constrained to spoken replies, which limits their user-facing outputs to what can be verbalized and suppresses text-native capabilities such as code generation, structured analysis, and multi-step reasoning in realtime interaction, for tasks that require persistent, structured, and inspectable intermediate outputs. Existing work improves spoken reasoning or full-duplex turn-taking, but still treats text as a hidden intermediate state or a subordinate modality rather than a first-class output channel. We propose Listen-Write-Speak (LWS), a text-first tri-channel paradigm in which a single autoregressive LLM continuously listens to user audio, writes visible free-form text as its primary output, and speaks a realtime oral response in parallel under a shared causal attention context. This behavior is implemented entirely through a Token Schema, requiring no architectural modifications, and learned via a two-stage data pipeline that synthesizes per-second cognitive annotations consistent with the revealed input timeline. Empirically, LWS demonstrates strong full-duplex interaction on Full-Duplex-Bench, reaches 4.72 on VoiceBench AlpacaEval, achieves 92.6% writing-speaking consistency, and consistently outperforms its internal ablations on URO-Bench. These results suggest that visible writing can serve as a first-class output channel for speech interaction without sacrificing realtime responsiveness. The code and dataset are available on the project page: https://royalzhang.com/project/lws-page/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Listen-Write-Speak (LWS), a tri-channel full-duplex paradigm, can be realized in a single autoregressive LLM solely via a new Token Schema (no architectural modifications) trained on a two-stage pipeline of synthesized per-second cognitive annotations. This enables simultaneous listening to user audio, visible free-form text writing as primary output, and realtime speaking. The manuscript reports concrete results: strong performance on Full-Duplex-Bench, 4.72 on VoiceBench AlpacaEval, 92.6% writing-speaking consistency, and consistent outperformance of internal ablations on URO-Bench, concluding that visible writing can serve as a first-class output channel without sacrificing responsiveness. Code and dataset are released.
Significance. If the central claim holds, the result would be significant for expanding speech-model capabilities to include text-native LLM strengths (code, structured reasoning) in realtime full-duplex settings. The open release of code and dataset is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Abstract and §3] Abstract and §3 (Token Schema description): the central claim that the schema alone enforces independent Listen-Write-Speak channels under a single shared causal attention mask is load-bearing, yet the provided description introduces no channel-specific masking, separate KV caches, or auxiliary loss terms that would block cross-channel leakage or guarantee temporal decoupling; without these mechanisms the tri-channel behavior may reduce to surface imitation on the synthesized training distribution rather than a general policy.
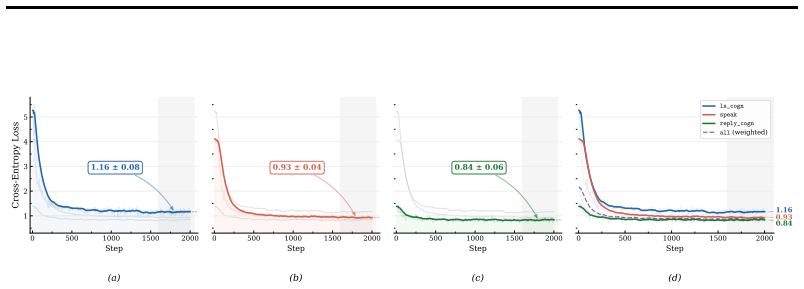
- [§5] §5 (Experiments): the reported 92.6% writing-speaking consistency and outperformance on URO-Bench are presented without error bars, statistical tests, or explicit definition of the consistency metric; this weakens the strength of the empirical support for the no-architecture-change claim.
minor comments (2)
- [Abstract] The abstract refers to 'internal ablations' without naming the variants or their differences; these should be enumerated in §4 or §5 for clarity.
- [§3] Notation for the Token Schema (e.g., channel labels and per-second annotations) should be formalized with an equation or table in §3 to aid reproducibility.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our manuscript. We address the major concerns point by point below, providing clarifications and indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Token Schema description): the central claim that the schema alone enforces independent Listen-Write-Speak channels under a single shared causal attention mask is load-bearing, yet the provided description introduces no channel-specific masking, separate KV caches, or auxiliary loss terms that would block cross-channel leakage or guarantee temporal decoupling; without these mechanisms the tri-channel behavior may reduce to surface imitation on the synthesized training distribution rather than a general policy.
Authors: The Token Schema is designed to delineate the three channels through distinct token types and structured formatting that the autoregressive model learns to follow under the causal attention mechanism. The two-stage training with per-second annotations ensures that the model internalizes the separation as a policy rather than mere imitation, as evidenced by its performance on out-of-distribution benchmarks like Full-Duplex-Bench and URO-Bench. However, we acknowledge that the current description in §3 could be more explicit about how the schema prevents leakage, and we will revise the section to include a detailed explanation of the token structure, generation process, and why the shared mask suffices for the intended behavior. revision: yes
-
Referee: [§5] §5 (Experiments): the reported 92.6% writing-speaking consistency and outperformance on URO-Bench are presented without error bars, statistical tests, or explicit definition of the consistency metric; this weakens the strength of the empirical support for the no-architecture-change claim.
Authors: We agree that providing an explicit definition of the writing-speaking consistency metric, along with error bars and statistical significance tests, would improve the robustness of our empirical claims. The consistency metric measures the alignment between the content of the visible text output and the spoken response, assessed via semantic similarity or human judgment on a held-out set. In the revised manuscript, we will add the definition in §5 and report standard deviations from multiple evaluation runs or seeds for the key metrics, including the 92.6% figure and URO-Bench results. revision: yes
Circularity Check
No significant circularity; central claim is empirical outcome of new schema and synthesis pipeline
full rationale
The paper's core contribution is a Token Schema plus two-stage synthesized data pipeline that trains an unmodified autoregressive LLM to produce tri-channel Listen-Write-Speak outputs. No equations, fitted parameters, or self-citations are presented as load-bearing derivations that reduce the reported metrics (Full-Duplex-Bench, VoiceBench, consistency scores) to quantities defined by the inputs themselves. The results are framed as empirical observations on held-out benchmarks after training, with no self-definitional loop, no renaming of known results, and no uniqueness theorem imported from prior author work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single autoregressive LLM under shared causal attention can produce consistent text and speech outputs when conditioned via a token schema
invented entities (1)
-
Token Schema
no independent evidence
Reference graph
Works this paper leans on
-
[1]
VoiceBench: Benchmarking LLM-Based Voice Assistants
Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T Tan, and Haizhou Li. Voicebench: Benchmarking llm-based voice assistants.arXiv preprint arXiv:2410.17196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Cheng-Han Chiang, Xiaofei Wang, Linjie Li, Chung-Ching Lin, Kevin Lin, Shujie Liu, Zhendong Wang, Zhengyuan Yang, Hung-yi Lee, and Lijuan Wang. Shanks: Simultaneous hearing and thinking for spoken language models.arXiv preprint arXiv:2510.06917, 2025a. Cheng-Han Chiang, Xiaofei Wang, Linjie Li, Chung-Ching Lin, Kevin Lin, Shujie Liu, Zhendong Wang, Zhengy...
-
[3]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e
doi: 10.1037/10096-006. Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359,
-
[4]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre D´efossez, Laurent Mazar ´e, Manu Orsini, Am ´elie Royer, Patrick P´erez, Herv´e J´egou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, et al. Kimi-audio technical report.arXiv preprint arXiv:2504.18425,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
doi: 10.1111/j.1551-6708.1987.tb00863.x. Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models.https://github.com/tatsu-lab/alpaca eval, 5
-
[8]
Borui Liao, Yulong Xu, Jiao Ou, Kaiyuan Yang, Weihua Jian, Pengfei Wan, and Di Zhang. Flexduo: A pluggable system for enabling full-duplex capabilities in speech dialogue systems.arXiv preprint arXiv:2502.13472,
-
[9]
Sharon Oviatt
Accessed: 2025-08. Sharon Oviatt. Ten myths of multimodal interaction.Communications of the ACM, 42(11): 74–81,
2025
-
[10]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever
doi: 10.1145/319382.319398. Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pp. 28492–28518. PMLR,
-
[11]
doi: 10.1006/ ijhc.1996.0048. Yi-Jen Shih, Desh Raj, Chunyang Wu, Wei Zhou, SK Bong, Yashesh Gaur, Jay Mahadeokar, Ozlem Kalinli, and Mike Seltzer. Can speech llms think while listening?arXiv preprint arXiv:2510.07497,
-
[12]
Chao-Hong Tan, Qian Chen, Wen Wang, Chong Deng, Qinglin Zhang, Luyao Cheng, Hai Yu, Xin Zhang, Xiang Lv, Tianyu Zhao, et al. Drvoice: Parallel speech-text voice conversation model via dual-resolution speech representations.arXiv preprint arXiv:2506.09349,
-
[13]
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848,
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, et al. Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848,
-
[14]
Think, verbalize, then speak: Bridging complex thoughts and comprehensible speech
Tony Woo, Sehun Lee, Kang-wook Kim, and Gunhee Kim. Think, verbalize, then speak: Bridging complex thoughts and comprehensible speech. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, pp. 14373–14390,
2025
-
[15]
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025a. Donghang Wu, Haoyang Zhang, Chen Chen, Tianyu Zhang, Fei Tian, Xuerui Yang, Gang Yu, Hexin Liu, Nana Hou, Yuchen Hu, et al. Chronological thinking in full-duplex spoken...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
11 Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Ruiqi Yan, Xiquan Li, Wenxi Chen, Zhikang Niu, Chen Yang, Ziyang Ma, Kai Yu, and Xie Chen. Uro-bench: Towards comprehensive evaluation for end-to-end spoken dialogue models.arXiv preprint arXiv:2502.17810,
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.