Multimodal Group Emotion Recognition In-the-Wild Towards a Privacy-Safe Non-Individual Approach
Pith reviewed 2026-06-29 12:58 UTC · model grok-4.3
The pith
Group emotion recognition achieves competitive accuracy using only collective audio-video signals without any individual face, gaze or voice data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
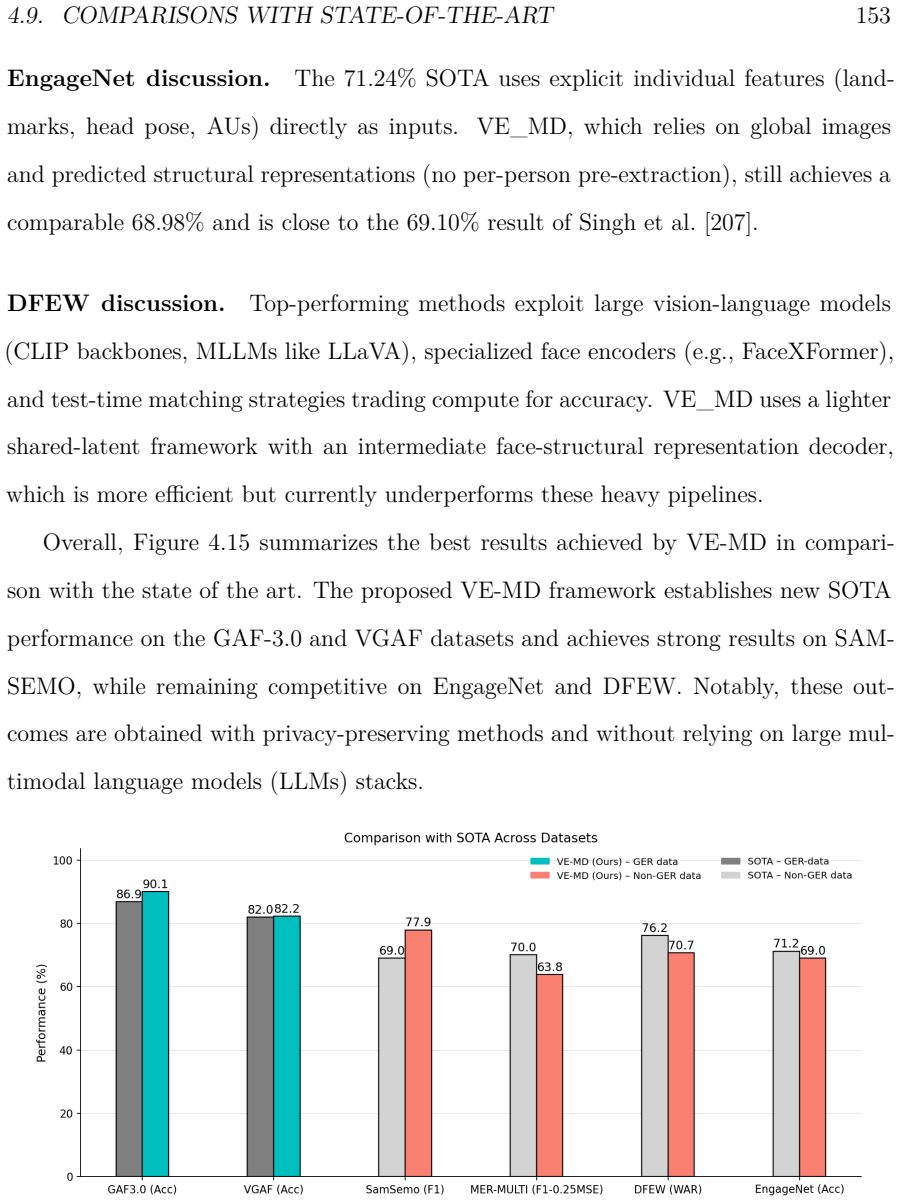
The thesis demonstrates that competitive performance on group emotion recognition in the wild is possible without using individual features as input. Two frameworks are presented: a cross-attention multimodal model with Frames Attention Pooling for audio-video fusion, and a Variational Encoder Multi-Decoder that learns a shared latent space supporting both classification and structural representation prediction. Experiments with synthetic data augmentation and ablation studies confirm that collective signals suffice for robust real-world results.
What carries the argument
Collective audio-video signals processed through cross-attention fusion and variational multi-decoder latent spaces, which aggregate group-level information without ever extracting individual cues.
If this is right
- Cross-attention fusion of audio and video improves temporal aggregation for group-level labels.
- Frames Attention Pooling enables effective handling of variable-length video without individual tracking.
- The variational encoder-decoder structure separates emotion classification from structural cue prediction while sharing a common representation.
- Synthetic augmentation compensates for limited real-world group emotion data and increases robustness.
- Performance remains competitive across both group-only and mixed individual-group evaluation settings.
Where Pith is reading between the lines
- The same collective-signal approach could extend to other group-level predictions such as activity coordination or conflict detection without requiring personal identification.
- Public deployments in shared spaces could adopt the method to reduce legal exposure under privacy regulations that restrict biometric capture.
- If collective signals prove sufficient, future datasets might be collected and shared without face-blurring or voice anonymization steps.
- The latent-space separation in the second framework suggests a route to disentangle affective state from visible body configuration for more interpretable group models.
Load-bearing premise
Collective audio-video signals, once synthetically augmented, contain enough information to match or approach the accuracy of models that rely on individual face, gaze or voice cues in real-world group settings.
What would settle it
A controlled test set of labeled group scenes where a model restricted to collective signals scores at least 15 percentage points lower in accuracy than an otherwise identical model given explicit individual face and voice tracks.
Figures



















read the original abstract
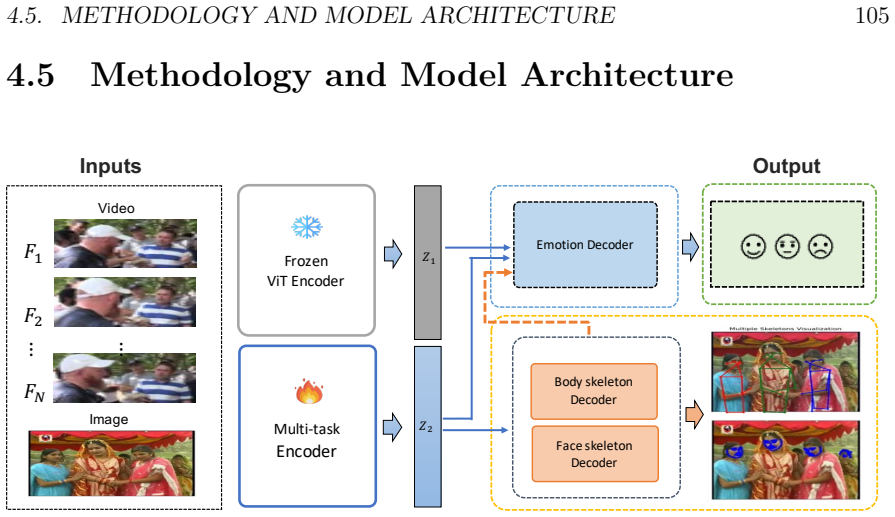
This thesis addresses group emotion recognition (GER) in-the-wild with a focus on privacy preservation. Unlike traditional emotion recognition methods that rely on individual-level cues such as face, gaze, or voice analysis, this work uses collective audio-video signals to infer emotions at the group level, reducing risks of individual monitoring and surveillance. Two complementary frameworks are proposed. The first is a cross-attention multimodal architecture for audio-video fusion, combined with Frames Attention Pooling (FAP) for temporal aggregation. It is supported by synthetic data augmentation and validated through ablation studies, demonstrating robustness in real-world GER conditions. The second framework, Variational Encoder Multi-Decoder (VE-MD), learns a shared latent space for emotion classification and structural representation prediction, including body and face cues. Two decoding strategies, DETR-based and heatmap-based, are explored to analyze the role of structural representations in group and individual settings. The thesis makes three main contributions: it clarifies the role of multimodality and structural cues in group-level affective computing; introduces two architectures for privacy-preserving multimodal GER; and shows that competitive performance can be achieved without using individual features as input data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two privacy-preserving frameworks for group emotion recognition (GER) in-the-wild that rely exclusively on collective audio-video signals rather than individual cues such as faces, gaze, or voices. The first combines cross-attention multimodal fusion with Frames Attention Pooling (FAP) and synthetic data augmentation; the second is a Variational Encoder Multi-Decoder (VE-MD) that learns a shared latent space for emotion classification and structural representation prediction using DETR-based or heatmap-based decoders. Ablation studies are cited to support robustness, and the central claim is that competitive performance can be achieved without individual-level input features.
Significance. If the quantitative results hold, the work would provide a concrete demonstration that collective multimodal signals suffice for competitive GER accuracy, advancing privacy-safe affective computing and offering an alternative to individual-cue pipelines in applications such as crowd monitoring.
major comments (3)
- [Abstract] Abstract: the claim that 'competitive performance can be achieved without using individual features as input data' is the central thesis but is unsupported by any reported accuracy, F1, or other metrics, dataset names with splits, error bars, or head-to-head comparisons against published individual-feature GER baselines on the same in-the-wild test sets.
- [Abstract] Abstract and § on VE-MD: the two decoding strategies (DETR-based and heatmap-based) are introduced to analyze the role of structural representations, yet no quantitative ablation or comparison results are supplied to show whether these representations improve or are necessary for the group-level claim.
- [Abstract] Abstract: ablation studies and synthetic augmentation are invoked to demonstrate robustness, but the text supplies neither the quantitative outcomes of those ablations nor the specific collective-signal baselines against which they were measured.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to strengthen the abstract with explicit quantitative support. The full manuscript contains the requested metrics, ablations, and comparisons in the experimental sections; we will revise the abstract to make these self-contained while preserving the privacy-preserving focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'competitive performance can be achieved without using individual features as input data' is the central thesis but is unsupported by any reported accuracy, F1, or other metrics, dataset names with splits, error bars, or head-to-head comparisons against published individual-feature GER baselines on the same in-the-wild test sets.
Authors: The experimental results section reports accuracy, F1, and other metrics on both synthetic and real in-the-wild datasets (with splits and error bars), including direct comparisons to individual-feature baselines. To address the abstract's self-containment, we will incorporate the key numerical results and dataset references into the revised abstract. revision: yes
-
Referee: [Abstract] Abstract and § on VE-MD: the two decoding strategies (DETR-based and heatmap-based) are introduced to analyze the role of structural representations, yet no quantitative ablation or comparison results are supplied to show whether these representations improve or are necessary for the group-level claim.
Authors: The VE-MD section provides quantitative ablations comparing DETR-based and heatmap-based decoders, including their effect on group-level emotion classification accuracy. We will add a concise summary of these comparative results to the abstract. revision: yes
-
Referee: [Abstract] Abstract: ablation studies and synthetic augmentation are invoked to demonstrate robustness, but the text supplies neither the quantitative outcomes of those ablations nor the specific collective-signal baselines against which they were measured.
Authors: The results section details the ablation outcomes (with numerical deltas) and the collective-signal baselines used. We will update the abstract to reference these specific quantitative findings and baselines. revision: yes
Circularity Check
No circularity; empirical architecture design with no derivation chain
full rationale
The manuscript describes two multimodal architectures (cross-attention with FAP; VE-MD) trained on collective audio-video signals plus synthetic augmentation, evaluated via ablation studies. No equations, fitted parameters renamed as predictions, self-definitional relations, or load-bearing self-citations appear in the provided text. The central claim of competitive performance without individual features is an empirical sufficiency statement, not a mathematical derivation that reduces to its inputs by construction. External benchmarks and numeric head-to-head results are referenced only at the level of experimental validation, not as self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
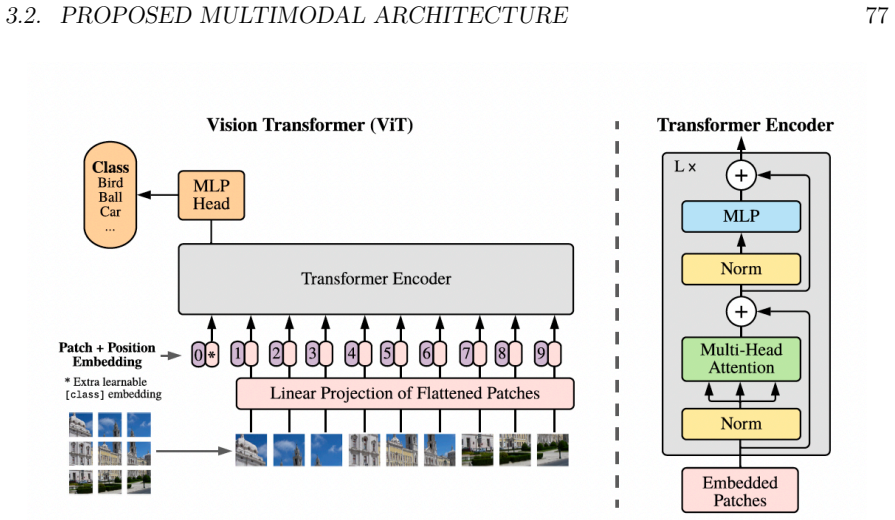
[1]
Engagement Measurement Based on Facial Landmarks and Spatial-Temporal Graph Convolutional Networks
Ali Abedi and Shehroz S Khan. “Engagement Measurement Based on Facial Landmarks and Spatial-Temporal Graph Convolutional Networks” . In: arXiv e- prints (2024), arXiv–2403
2024
-
[2]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. “Flamingo: a visual language model for few-shot learning” . In: Advances in neural information processing systems 35 (2022), pp. 23716–23736
2022
-
[3]
Speech emotion recognition in conversations using artificial intelligence: a sys- tematic review and meta-analysis
Ghada Alhussein, Ioannis Ziogas, Shiza Saleem, and Leontios J Hadjileontiadis. “Speech emotion recognition in conversations using artificial intelligence: a sys- tematic review and meta-analysis” . In: Artificial Intelligence Review 58.7 (2025), p. 198
2025
-
[4]
ExCEDA: Unlocking Attention Paradigms in Extended Duration E-Classrooms by Leveraging Attention-Mechanism Models
A vinash Anand, A vni Mittal, Laavanaya Dhawan, Juhi Krishnamurthy, Mahisha Ramesh, Naman Lal, Astha Verma, Pijush Bhuyan, Raijv Ratn Shah, Roger Zimmermann, et al. “ExCEDA: Unlocking Attention Paradigms in Extended Duration E-Classrooms by Leveraging Attention-Mechanism Models” . In: 2024 IEEE 7th International Conference on Multimedia Information Proces...
2024
-
[5]
Facial emotion recognition in Parkinson’s disease: a review and new hypotheses
Soizic Argaud, Marc Vérin, Paul Sauleau, and Didier Grandjean. “Facial emotion recognition in Parkinson’s disease: a review and new hypotheses” . In: Movement disorders 33.4 (2018), pp. 554–567
2018
-
[6]
Real-time Convolu- tional Neural Networks for emotion and gender classification
Octavio Arriaga, Matias Valdenegro-Toro, and Paul Plöger. “Real-time Convolu- tional Neural Networks for emotion and gender classification” . In: 27th European Symposium on Artificial Neural Networks, ESANN 2019, Bruges, Belgium, April 24-26, 2019 . 2019, pp. 221–226
2019
-
[7]
BODY LANGUAGE IN- TERPRETATION: PSYCHOPHYSIOLOGICAL AND COGNITIVE ASPECTS
Rustamjon Asatullaev and Diyora Muxamedjonova. “BODY LANGUAGE IN- TERPRETATION: PSYCHOPHYSIOLOGICAL AND COGNITIVE ASPECTS” . In: Journal of Applied Science and Social Science 1.1 (2025), pp. 456–458
2025
-
[8]
Multimodal Perception and Statistical Modeling of Ped- agogical Classroom Events Using a Privacy-safe Non-individual Approach
Anderson Augusma. “Multimodal Perception and Statistical Modeling of Ped- agogical Classroom Events Using a Privacy-safe Non-individual Approach” . In: 2022 10th International Conference on Affective Computing and Intelligent In- teraction Workshops and Demos (ACIIW) . IEEE. 2022, pp. 1–5
2022
-
[9]
Multimodal Group Emotion Recognition In-the-wild Using Privacy-Compliant Features
Anderson Augusma, Dominique Vaufreydaz, and Frédérique Letué. “Multimodal Group Emotion Recognition In-the-wild Using Privacy-Compliant Features” . In: Proceedings of the 25th International Conference on Multimodal Interaction . 2023, pp. 750–754
2023
-
[10]
Enhancing Sentiment Analysis With Emo- tion And Sarcasm Detection: A Transformer-Based Approach
Mr Suryavamshi Sandeep Babu, SV Suryanarayana, M Sruthi, P Bhagya Lak- shmi, T Sravanthi, and M Spandana. “Enhancing Sentiment Analysis With Emo- tion And Sarcasm Detection: A Transformer-Based Approach” . In: Metallurgical and Materials Engineering (2025), pp. 794–803
2025
-
[11]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. “wav2vec 2.0: A framework for self-supervised learning of speech representations” . In: Ad- vances in neural information processing systems 33 (2020), pp. 12449–12460. BIBLIOGRAPHY 175
2020
-
[12]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. “Qwen technical report” . In: arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Facial expression- based emotion recognition across diverse age groups: a multi-scale vision trans- former with contrastive learning approach
G Balachandran, S Ranjith, TR Chenthil, and GC Jagan. “Facial expression- based emotion recognition across diverse age groups: a multi-scale vision trans- former with contrastive learning approach” . In: Journal of Combinatorial Opti- mization 49.1 (2025), pp. 1–39
2025
-
[14]
Natural Language Processing for Sentiment Analysis in Social Media Marketing
Murat Başal. “Natural Language Processing for Sentiment Analysis in Social Media Marketing” . In: Economics 12.1 (2025), pp. 39–51
2025
-
[15]
Sentiment prediction based on dempster-shafer theory of evidence
Mohammad Ehsan Basiri, Ahmad Reza Naghsh-Nilchi, and Nasser Ghasem- Aghaee. “Sentiment prediction based on dempster-shafer theory of evidence” . In: Mathematical Problems in Engineering 2014.1 (2014), p. 361201
2014
-
[16]
Semantic-emotion neural network for emotion recognition from text
Erdenebileg Batbaatar, Meijing Li, and Keun Ho Ryu. “Semantic-emotion neural network for emotion recognition from text” . In:IEEE access 7 (2019), pp. 111866– 111878
2019
-
[17]
INTERPRETING BODY LANGUAGE: A SCIENTIFIC PERSPECTIVE
Asatullayev Rustamjon Baxtiyarovich and Boboqulovc Behruz Bahodirovich. “INTERPRETING BODY LANGUAGE: A SCIENTIFIC PERSPECTIVE” . In: YANGI O ‘ZBEKISTON, YANGI TADQIQOTLAR JURNALI 2.5 (2025), pp. 143– 146
2025
-
[18]
Group-Level Affect Recognition in Video Using Deviation of Frame Features
Natalya S Belova. “Group-Level Affect Recognition in Video Using Deviation of Frame Features” . In: Analysis of Images, Social Networks and Texts: 10th International Conference, AIST 2021, Tbilisi, Georgia, December 16–18, 2021, Revised Selected Papers. Vol. 13217. Springer Nature. 2022, p. 199
2021
-
[19]
Is space-time attention all you need for video understanding?
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. “Is space-time attention all you need for video understanding?” In: ICML. Vol. 2. 3. 2021, p. 4. 176 BIBLIOGRAPHY
2021
-
[20]
Learning privacy-enhancing face representations through feature disentanglement
Blaž Bortolato, Marija Ivanovska, Peter Rot, Janez Križaj, Philipp Terhörst, Naser Damer, Peter Peer, and Vitomir Štruc. “Learning privacy-enhancing face representations through feature disentanglement” . In: 2020 15th IEEE Interna- tional Conference on Automatic Face and Gesture Recognition (FG 2020) . IEEE. 2020, pp. 495–502
2020
-
[21]
Legal and Regulatory Perspec- tives on Synthetic Data as an Anonymization Strategy
Alexander Boudewijn and Andrea F Ferraris. “Legal and Regulatory Perspec- tives on Synthetic Data as an Anonymization Strategy” . In: J. Pers. Data Prot. L. (2024), p. 17
2024
-
[22]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. “Language models are few-shot learners” . In: Advances in neural information processing systems 33 (2020), pp. 1877–1901
2020
-
[23]
SAMSEMO: New dataset for multilingual and multimodal emotion recognition
Paweł Bujnowski, Bartłomiej Kuźma, Bartłomiej Paziewski, Jacek Rutkowski, Joanna Marhula, Zuzanna Bordzicka, and Piotr Andruszkiewicz. “SAMSEMO: New dataset for multilingual and multimodal emotion recognition” . In: Inter- speech. 2024
2024
-
[24]
How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks)
Adrian Bulat and Georgios Tzimiropoulos. “How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks)” . In: Proceedings of the IEEE international conference on computer vision . 2017, pp. 1021–1030
2017
-
[25]
A database of German emotional speech
Felix Burkhardt, Astrid Paeschke, Miriam Rolfes, Walter F Sendlmeier, Ben- jamin Weiss, et al. “A database of German emotional speech. ” In: Interspeech. Vol. 5. 2005, pp. 1517–1520
2005
-
[26]
IEMOCAP: Interactive Emotional Dyadic Motion Capture Database
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N. Chang, Sungbok Lee, and Shrikanth S. Narayanan. “IEMOCAP: Interactive Emotional Dyadic Motion Capture Database” . In: Jour- BIBLIOGRAPHY 177 nal of Language Resources and Evaluation 42.4 (2008), pp. 335–359. doi: 10. 1007/s10579-008-9076-6
2008
-
[27]
MSP-IMPROV: An acted corpus of dyadic interactions to study emotion perception
Carlos Busso, Srinivas Parthasarathy, Alec Burmania, Mohammed AbdelWahab, Najmeh Sadoughi, and Emily Mower Provost. “MSP-IMPROV: An acted corpus of dyadic interactions to study emotion perception” . In: IEEE Transactions on Affective Computing 8.1 (2016), pp. 67–80
2016
-
[28]
Human observers and automated assessment of dynamic emotional facial ex- pressions: KDEF-dyn database validation
Manuel G Calvo, Andrés Fernández-Martín, Guillermo Recio, and Daniel Lundqvist. “Human observers and automated assessment of dynamic emotional facial ex- pressions: KDEF-dyn database validation” . In: Frontiers in psychology 9 (2018), p. 2052
2018
-
[29]
The EU’s AI act: A framework for collaborative gover- nance
Celso Cancela-Outeda. “The EU’s AI act: A framework for collaborative gover- nance” . In: Internet of Things 27 (2024), p. 101291
2024
-
[30]
Crema-d: Crowd-sourced emotional multimodal actors dataset
Houwei Cao, David G Cooper, Michael K Keutmann, Ruben C Gur, Ani Nenkova, and Ragini Verma. “Crema-d: Crowd-sourced emotional multimodal actors dataset” . In: IEEE transactions on affective computing 5.4 (2014), pp. 377–390
2014
-
[31]
Deep learning-based depression recognition through facial expression: A systematic review
Xiaoming Cao, Lingling Zhai, Pengpeng Zhai, Fangfei Li, Tao He, and Lang He. “Deep learning-based depression recognition through facial expression: A systematic review” . In: Neurocomputing (2025), p. 129605
2025
-
[32]
Open- pose: Realtime multi-person 2d pose estimation using part affinity fields
Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. “Open- pose: Realtime multi-person 2d pose estimation using part affinity fields” . In: IEEE transactions on pattern analysis and machine intelligence 43.1 (2019), pp. 172–186
2019
-
[33]
Realtime multi-person 2d pose estimation using part affinity fields
Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. “Realtime multi-person 2d pose estimation using part affinity fields” . In: Proceedings of the IEEE con- ference on computer vision and pattern recognition . 2017, pp. 7291–7299. 178 BIBLIOGRAPHY
2017
-
[34]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. “End-to-end object detection with transformers” . In: European conference on computer vision . Springer. 2020, pp. 213–229
2020
-
[35]
CDGT: Constructing diverse graph transformers for emotion recognition from facial videos
Dongliang Chen, Guihua Wen, Huihui Li, Pei Yang, Chuyun Chen, and Bao Wang. “CDGT: Constructing diverse graph transformers for emotion recognition from facial videos” . In: Neural Networks 179 (2024), p. 106573
2024
-
[36]
En- hancing robustness against adversarial attacks in multimodal emotion recogni- tion with spiking transformers
Guoming Chen, Zhuoxian Qian, Dong Zhang, Shuang Qiu, and Ruqi Zhou. “En- hancing robustness against adversarial attacks in multimodal emotion recogni- tion with spiking transformers” . In: IEEE Access (2025)
2025
-
[37]
Finecliper: Multi-modal fine-grained clip for dynamic facial expression recogni- tion with adapters
Haodong Chen, Haojian Huang, Junhao Dong, Mingzhe Zheng, and Dian Shao. “Finecliper: Multi-modal fine-grained clip for dynamic facial expression recogni- tion with adapters” . In: Proceedings of the 32nd ACM International Conference on Multimedia. 2024, pp. 2301–2310
2024
-
[38]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. “Shikra: Unleashing multimodal llm’s referential dialogue magic” . In:arXiv preprint arXiv:2306.15195 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Wavlm: Large- scale self-supervised pre-training for full stack speech processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. “Wavlm: Large- scale self-supervised pre-training for full stack speech processing” . In: IEEE Jour- nal of Selected Topics in Signal Processing 16.6 (2022), pp. 1505–1518
2022
-
[40]
System description for voice privacy challenge 2022
Xiaojiao Chen, Guangxing Li, Hao Huang, Wangjin Zhou, Sheng Li, Yang Cao, and Yi Zhao. “System description for voice privacy challenge 2022” . In: Proc. 2nd Symposium on Security and Privacy in Speech Communication . 2022
2022
-
[41]
Emotion-llama: Multimodal emo- tion recognition and reasoning with instruction tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, and Alexander Hauptmann. “Emotion-llama: Multimodal emo- tion recognition and reasoning with instruction tuning” . In: Advances in Neural Information Processing Systems 37 (2024), pp. 110805–110853. BIBLIOGRAPHY 179
2024
-
[42]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023” . In: URL https://lmsys. org/blog/2023-03-30-vicuna 3.5 (2023)
2023
-
[43]
Stargan: Unified generative adversarial networks for multi-domain image-to-image translation
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. “Stargan: Unified generative adversarial networks for multi-domain image-to-image translation” . In:Proceedings of the IEEE conference on computer vision and pattern recognition . 2018, pp. 8789–8797
2018
-
[44]
MMA- DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expres- sion Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, and Moncef Gabbouj. “MMA- DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expres- sion Recognition in-the-wild” . In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 2024, pp. 4673–4682
2024
-
[45]
Canonical cor- relation analysis for data fusion and group inferences
Nicolle M Correa, Tulay Adali, Yi-Ou Li, and Vince D Calhoun. “Canonical cor- relation analysis for data fusion and group inferences” . In: IEEE signal processing magazine 27.4 (2010), pp. 39–50
2010
-
[46]
Facial Emotion Recog- nition and Classification Using the Convolutional Neural Network-10 (CNN- 10)
Emmanuel Gbenga Dada, David Opeoluwa Oyewola, Stephen Bassi Joseph, Onyeka Emebo, and Olugbenga Oluseun Oluwagbemi. “Facial Emotion Recog- nition and Classification Using the Convolutional Neural Network-10 (CNN- 10)” . In: Applied Computational Intelligence and Soft Computing 2023.1 (2023), p. 2457898
2023
-
[47]
What else does your biometric data reveal? A survey on soft biometrics
Antitza Dantcheva, Petros Elia, and Arun Ross. “What else does your biometric data reveal? A survey on soft biometrics” . In: IEEE Transactions on Information Forensics and Security 11.3 (2015), pp. 441–467
2015
-
[48]
Detection and analysis of emotion from speech signals
Assel Davletcharova, Sherin Sugathan, Bibia Abraham, and Alex Pappachen James. “Detection and analysis of emotion from speech signals” . In: Procedia Computer Science 58 (2015), pp. 91–96. 180 BIBLIOGRAPHY
2015
-
[49]
A generalization of Bayesian inference
Arthur P Dempster. “A generalization of Bayesian inference” . In: Journal of the Royal Statistical Society: Series B (Methodological) 30.2 (1968), pp. 205–232
1968
-
[50]
From individual to group-level emotion recognition: Emotiw 5.0
Abhinav Dhall, Roland Goecke, Shreya Ghosh, Jyoti Joshi, Jesse Hoey, and Tom Gedeon. “From individual to group-level emotion recognition: Emotiw 5.0” . In: Proceedings of the 19th ACM international conference on multimodal interaction . 2017, pp. 524–528
2017
-
[51]
Finding happiest moments in a social context
Abhinav Dhall, Jyoti Joshi, Ibrahim Radwan, and Roland Goecke. “Finding happiest moments in a social context” . In: Computer Vision–ACCV 2012: 11th Asian Conference on Computer Vision, Daejeon, Korea, November 5-9, 2012, Revised Selected Papers, Part II 11 . Springer. 2013, pp. 613–626
2012
-
[52]
The more the merrier: Analysing the affect of a group of people in images
Abhinav Dhall, Jyoti Joshi, Karan Sikka, Roland Goecke, and Nicu Sebe. “The more the merrier: Analysing the affect of a group of people in images” . In: 2015 11th IEEE international conference and workshops on automatic face and gesture recognition (FG). Vol. 1. IEEE. 2015, pp. 1–8
2015
-
[53]
Emotiw 2018: Audio-video, student engagement and group-level affect prediction
Abhinav Dhall, Amanjot Kaur, Roland Goecke, and Tom Gedeon. “Emotiw 2018: Audio-video, student engagement and group-level affect prediction” . In: Proceed- ings of the 20th ACM International Conference on Multimodal Interaction . 2018, pp. 653–656
2018
-
[54]
Emotiw 2020: Driver gaze, group emotion, student engagement and physiological signal based challenges
Abhinav Dhall, Garima Sharma, Roland Goecke, and Tom Gedeon. “Emotiw 2020: Driver gaze, group emotion, student engagement and physiological signal based challenges” . In: Proceedings of the 2020 International Conference on Mul- timodal Interaction. 2020, pp. 784–789
2020
-
[55]
EmotiW 2023: Emotion Recognition in the Wild Challenge
Abhinav Dhall, Monisha Singh, Roland Goecke, Tom Gedeon, Donghuo Zeng, Yanan Wang, and Kazushi Ikeda. “EmotiW 2023: Emotion Recognition in the Wild Challenge” . In: Proceedings of the 25th International Conference on Multi- modal Interaction (ICMI 2023) . 2023. BIBLIOGRAPHY 181
2023
-
[56]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” . In:CoRR abs/2010.11929 (2020). arXiv: 2010.11929. url: https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[57]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” . In: ICLR (2021)
2021
-
[58]
Speech emotion recognition based on spiking neural network and convolutional neural network
Chengyan Du, Fu Liu, Bing Kang, and Tao Hou. “Speech emotion recognition based on spiking neural network and convolutional neural network” . In: Engi- neering Applications of Artificial Intelligence 147 (2025), p. 110314
2025
-
[59]
Training generative neural networks via maximum mean discrepancy optimization
Gintare Karolina Dziugaite, Daniel M Roy, and Zoubin Ghahramani. “Training generative neural networks via maximum mean discrepancy optimization” . In: Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelli- gence. 2015, pp. 258–267
2015
-
[60]
F ACES—A database of facial expressions in young, middle-aged, and older women and men: Development and validation
Natalie C Ebner, Michaela Riediger, and Ulman Lindenberger. “F ACES—A database of facial expressions in young, middle-aged, and older women and men: Development and validation” . In: Behavior research methods 42 (2010), pp. 351– 362
2010
-
[61]
F ACES-a database of facial expressions in young, middle-aged, and older women and men: Develop- ment and validation
Natalie C. Ebner, Michaela Riediger, and Ulman Lindenberger. “F ACES-a database of facial expressions in young, middle-aged, and older women and men: Develop- ment and validation” . In: Behavior Research Methods 42 (1 Feb. 2010), pp. 351–
2010
-
[62]
issn: 1554351X. doi: 10.3758/BRM.42.1.351
-
[63]
Are there basic emotions?
Paul Ekman. “Are there basic emotions?” In: (1992). 182 BIBLIOGRAPHY
1992
-
[64]
Emonext: an adapted convnext for facial emotion recognition
Yassine El Boudouri and Amine Bohi. “Emonext: an adapted convnext for facial emotion recognition” . In:2023 IEEE 25th International Workshop on Multimedia Signal Processing (MMSP) . IEEE. 2023, pp. 1–6
2023
-
[65]
On the multivariate Laplace distribution
Torbjørn Eltoft, Taesu Kim, and Te-Won Lee. “On the multivariate Laplace distribution” . In: IEEE Signal Processing Letters 13.5 (2006), pp. 300–303
2006
-
[66]
Multimodal End-to-End Group Emotion Recognition using Cross-Modal Attention
Lev Evtodienko. “Multimodal End-to-End Group Emotion Recognition using Cross-Modal Attention” . In: CoRR abs/2111.05890 (2021). arXiv: 2111.05890. url: https://arxiv.org/abs/2111.05890
-
[67]
Emotion recognition from unimodal to multimodal analysis: A review
Kaouther Ezzameli and Hela Mahersia. “Emotion recognition from unimodal to multimodal analysis: A review” . In: Information Fusion 99 (2023), p. 101847
2023
-
[68]
Eva: Exploring the limits of masked visual representation learning at scale
Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. “Eva: Exploring the limits of masked visual representation learning at scale” . In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition . 2023, pp. 19358–19369
2023
-
[69]
Multi-task learning on the edge for effective gender, age, ethnicity and emotion recognition
Pasquale Foggia, Antonio Greco, Alessia Saggese, and Mario Vento. “Multi-task learning on the edge for effective gender, age, ethnicity and emotion recognition” . In: Engineering Applications of Artificial Intelligence 118 (2023), p. 105651
2023
-
[70]
Emoclip: A vision-language method for zero-shot video facial expression recognition
Niki Maria Foteinopoulou and Ioannis Patras. “Emoclip: A vision-language method for zero-shot video facial expression recognition” . In: 2024 IEEE 18th Interna- tional Conference on Automatic Face and Gesture Recognition (FG). IEEE. 2024, pp. 1–10
2024
-
[71]
Emotion experience
Nico Frijda. “Emotion experience” . In: Cognition and Emotion 19.4 (2005), pp. 473–
2005
-
[72]
doi: 10.1080/02699930441000346
-
[73]
Percep- tion of expressed emotion among persons with mental illness
Sailaxmi Gandhi, Narayanasamy Padmavathi, Rajil Raveendran, Prabhu Jad- hav, Maya Sahu, Jothimani Gurusamy, and Krishna Prasad Muliyala. “Percep- tion of expressed emotion among persons with mental illness” . In: Journal of Psychosocial Rehabilitation and Mental Health 7 (2020), pp. 121–130. BIBLIOGRAPHY 183
2020
-
[74]
Multimodal and temporal perception of audio-visual cues for emotion recognition
Esam Ghaleb, Mirela Popa, and Stylianos Asteriadis. “Multimodal and temporal perception of audio-visual cues for emotion recognition” . In: 2019 8th Interna- tional Conference on Affective Computing and Intelligent Interaction (ACII) . IEEE. 2019, pp. 552–558
2019
-
[75]
Automatic group affect anal- ysis in images via visual attribute and feature networks
Shreya Ghosh, Abhinav Dhall, and Nicu Sebe. “Automatic group affect anal- ysis in images via visual attribute and feature networks” . In: 2018 25th IEEE International Conference on Image Processing (ICIP) . IEEE. 2018, pp. 1967– 1971
2018
-
[76]
Predicting group cohesiveness in images
Shreya Ghosh, Abhinav Dhall, Nicu Sebe, and Tom Gedeon. “Predicting group cohesiveness in images” . In: 2019 International Joint Conference on Neural Net- works (IJCNN) . IEEE. 2019, pp. 1–8
2019
-
[77]
Dynamical variational autoencoders: A comprehensive review
Laurent Girin, Simon Leglaive, Xiaoyu Bie, Julien Diard, Thomas Hueber, and Xavier Alameda-Pineda. “Dynamical variational autoencoders: A comprehensive review” . In: arXiv preprint arXiv:2008.12595 (2020)
-
[78]
A Hybrid Fusion Model for Group-Level Emotion Recogni- tion in Complex Scenarios
Wenjuan Gong, Yifan Wang, Yikai Wu, Shuaipeng Gao, Athanasios V Vasilakos, and Peiying Zhang. “A Hybrid Fusion Model for Group-Level Emotion Recogni- tion in Complex Scenarios” . In: Information Sciences (2025), p. 121968
2025
-
[79]
Generative adver- sarial networks
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. “Generative adver- sarial networks” . In: Communications of the ACM 63.11 (2020), pp. 139–144
2020
-
[80]
Challenges in representation learning: A report on three machine learning contests
Ian J Goodfellow, Dumitru Erhan, Pierre Luc Carrier, Aaron Courville, Mehdi Mirza, Ben Hamner, Will Cukierski, Yichuan Tang, David Thaler, Dong-Hyun Lee, et al. “Challenges in representation learning: A report on three machine learning contests” . In: Neural information processing: 20th international confer- ence, ICONIP 2013, daegu, korea, november 3-7, ...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.