From Human Guidance to Autonomy: Agent Skill System for End-to-End LLM Deployment on Spatial NPUs
Pith reviewed 2026-06-29 13:49 UTC · model grok-4.3
The pith
An eight-phase agent skill system distilled from one human-guided LLM deployment enables autonomous end-to-end deployment of eight new decoder-only models on a spatial NPU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
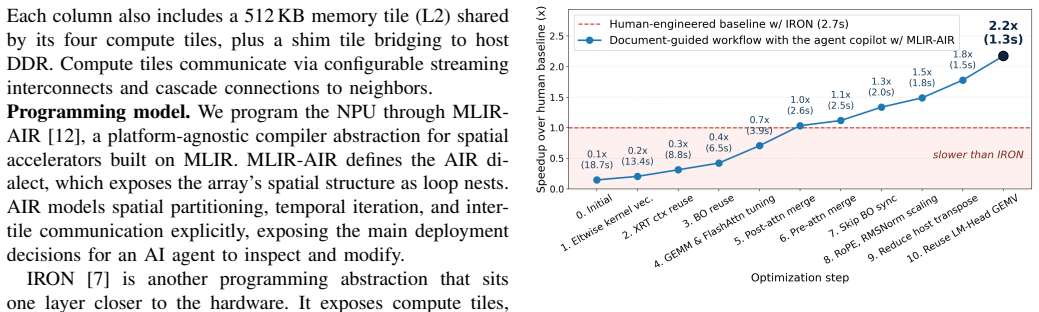
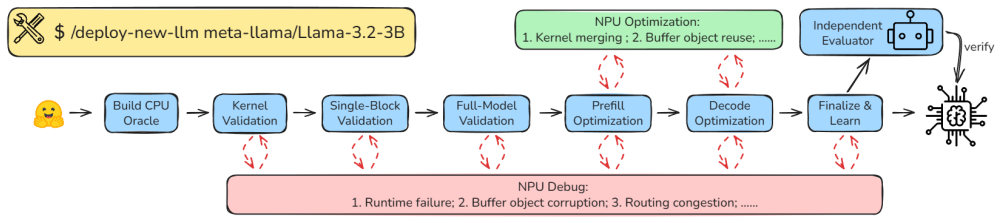
A reference deployment of Llama-3.2-1B is first created on the AMD XDNA 2 NPU through human-guided agent assistance, achieving 2.2x speedup on prefill and 4.0x on decode while the optimization trajectory is recorded as structured documentation. This documentation is distilled into an agent skill system of eight phases that orchestrates optimization and debugging skill sets with numerical correctness strictly enforced at each phase. The resulting system then autonomously deploys eight additional decoder-only LLMs on the same NPU using the open-source compiler stack, each completing in 0.5-4 hours of agent wall time with almost no human guidance and passing the numerical-correctness gates; thr
What carries the argument
The agent skill system consisting of eight phases that orchestrates optimization and debugging skill sets while enforcing numerical correctness at every phase.
If this is right
- Eight decoder-only LLMs never previously deployed on AMD NPUs via open-source software are now runnable on the XDNA 2 NPU.
- Each autonomous deployment finishes in 0.5-4 hours of agent wall time while passing numerical-correctness gates.
- Three of the eight new deployments achieve sustained performance matching or exceeding the Llama-3.2-1B reference without further model-specific tuning.
- Functional generalization to previously unencountered models is achieved by the skill system alone.
Where Pith is reading between the lines
- The eight-phase structure could be tested on other spatial NPUs or compiler stacks if similar human-guided reference deployments are first recorded.
- Extending the system to larger models or different architectures such as encoder-decoder transformers would reveal whether the phase count and correctness gates remain sufficient.
- If the system scales, the engineering cost of supporting new edge LLMs could drop from days of expert work to hours of agent runtime.
Load-bearing premise
The optimization steps and lessons from the single human-guided Llama-3.2-1B deployment can be captured in a reusable eight-phase skill system that works for other LLMs without new model-specific human engineering.
What would settle it
Applying the eight-phase agent skill system to a ninth decoder-only LLM and observing that it either fails to produce a numerically correct end-to-end deployment or requires substantial additional human intervention beyond the claimed minimal guidance.
Figures
read the original abstract
Spatial neural processing units (NPUs) provide an energy-efficient platform for edge LLM inference, but efficiently deploying an LLM end-to-end on such hardware remains labor-intensive. Although AI coding agents have begun to lower this cost, existing studies have largely focused on single-kernel optimization rather than end-to-end LLM deployment on resource-constrained spatial NPUs. We present a two-stage methodology, instantiated on the AMD XDNA 2 NPU, that progresses from human-guided development to agent autonomy. In the first stage, we develop a reference deployment of Llama-3.2-1B through human-guided agent assistance. The resulting implementation achieves a speedup of 2.2x on prefill and 4.0x on decode over the hand-optimized baseline, with the optimization trajectory and its lessons recorded as structured documentation throughout. In the second stage, we distill the documentation into an agent skill system consisting of eight phases, orchestrating the optimization and debugging skill sets, with numerical correctness strictly enforced at each phase. Using our agent skill system, we autonomously deploy eight additional decoder-only LLMs (Llama-3.2-3B, SmolLM2-1.7B, Qwen2.5-{0.5B, 1.5B, 3B}, Qwen3-{0.6B, 1.7B, 4B}) end-to-end on the AMD XDNA 2 NPU using the open-source compiler stack. To our knowledge, these models have not previously been deployed on AMD NPUs via any open-source software stack. Each deployment completes in 0.5-4 hours of agent wall time with almost no human guidance, and passes the numerical-correctness gates, demonstrating functional generalization to previously unencountered LLMs. Three of the eight match or exceed the sustained performance of our Llama-3.2-1B reference deployment, suggesting that the resulting implementations can be competitive without additional model-specific human engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a two-stage methodology for end-to-end deployment of decoder-only LLMs on the AMD XDNA 2 NPU using an open-source compiler stack. Stage 1 uses human-guided agents to optimize a Llama-3.2-1B reference deployment, recording a 2.2x prefill and 4.0x decode speedup over a hand-optimized baseline along with structured documentation of the trajectory. Stage 2 distills this into an eight-phase agent skill system that orchestrates optimization and debugging skills while enforcing numerical-correctness gates. The system then autonomously deploys eight additional models (Llama-3.2-3B, SmolLM2-1.7B, Qwen2.5-{0.5B,1.5B,3B}, Qwen3-{0.6B,1.7B,4B}) in 0.5–4 hours of wall time with minimal human input; three match or exceed the reference performance, supporting a claim of functional generalization to unseen models.
Significance. If the eight-phase skill system is shown to be genuinely model-agnostic and reproducible, the work would demonstrate a practical reduction in human engineering effort for spatial-NPU LLM deployment, with direct relevance to edge inference. The empirical results on eight previously undeployed models via open-source tooling and the explicit recording of the human-guided trajectory are concrete strengths that could support follow-on research in agent-driven systems optimization.
major comments (2)
- [Abstract and §2] Abstract and §2 (second-stage methodology): The generalization claim rests on distilling the Llama-3.2-1B human-guided trajectory into a fixed eight-phase agent skill system, yet the manuscript supplies neither the phase definitions, transition conditions between phases, skill prompts, nor the concrete implementation of the numerical-correctness gates. Without these internals it is impossible to evaluate whether the reported autonomous runs reflect true distillation or continued implicit model-specific engineering when handling architectural differences (e.g., GQA group sizes, hidden dimensions, or tokenizer vocabularies across the Llama/Qwen/SmolLM families).
- [Abstract] Abstract (autonomous deployment results): The claim that each of the eight deployments “passes the numerical-correctness gates” is load-bearing for the correctness-enforcement assertion, but no description is given of the verification procedure, tolerance thresholds, or test inputs used for the autonomous runs. This detail is required to assess whether the gates are sufficiently stringent to support the functional-generalization conclusion.
minor comments (1)
- [Abstract] The abstract states speedups relative to a “hand-optimized baseline” but does not specify the baseline implementation or measurement methodology (e.g., batch size, sequence length, hardware frequency).
Simulated Author's Rebuttal
We thank the referee for the constructive comments. They correctly identify that key implementation details of the agent skill system and numerical-correctness gates are missing from the current manuscript, which limits evaluation of the generalization claim. We will revise the paper to supply these details.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2 (second-stage methodology): The generalization claim rests on distilling the Llama-3.2-1B human-guided trajectory into a fixed eight-phase agent skill system, yet the manuscript supplies neither the phase definitions, transition conditions between phases, skill prompts, nor the concrete implementation of the numerical-correctness gates. Without these internals it is impossible to evaluate whether the reported autonomous runs reflect true distillation or continued implicit model-specific engineering when handling architectural differences (e.g., GQA group sizes, hidden dimensions, or tokenizer vocabularies across the Llama/Qwen/SmolLM families).
Authors: We agree that the manuscript does not currently supply the phase definitions, transition conditions, skill prompts, or concrete gate implementations. This omission prevents readers from fully assessing whether the eight-phase system is a faithful distillation or relies on implicit per-model adjustments. In the revised manuscript we will expand §2 (and add an appendix if needed) with the eight phase definitions, the exact transition logic between phases, representative skill prompts, and the gate implementation code. These additions will be drawn directly from the structured documentation recorded during the human-guided Llama-3.2-1B stage. revision: yes
-
Referee: [Abstract] Abstract (autonomous deployment results): The claim that each of the eight deployments “passes the numerical-correctness gates” is load-bearing for the correctness-enforcement assertion, but no description is given of the verification procedure, tolerance thresholds, or test inputs used for the autonomous runs. This detail is required to assess whether the gates are sufficiently stringent to support the functional-generalization conclusion.
Authors: We acknowledge that the manuscript provides no description of the verification procedure, tolerance thresholds, or test inputs. In the revision we will add an explicit description of the numerical-correctness gates, including the comparison method against a CPU reference, the tolerance thresholds (e.g., relative error bounds on logits and final outputs), and the test inputs (e.g., fixed-length random sequences drawn from each model’s vocabulary). This will allow readers to judge the stringency of the gates and the strength of the generalization evidence. revision: yes
Circularity Check
No circularity; empirical generalization tested on distinct models
full rationale
The paper's derivation proceeds from a single human-guided reference deployment of Llama-3.2-1B (with lessons recorded) to a distilled eight-phase skill system, then applies that system to eight architecturally distinct, previously unencountered decoder-only LLMs. Success is measured by independent empirical outcomes—wall-clock time, passage of numerical-correctness gates, and sustained performance—rather than by any definitional equivalence or statistical forcing back to the reference trajectory. No equations, self-citations, fitted parameters, or uniqueness theorems appear; the central claim therefore remains externally falsifiable and self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Decoder-only LLMs can be deployed end-to-end on spatial NPUs using open-source compiler stacks while maintaining numerical correctness.
- domain assumption Structured documentation from one model optimization can be distilled into reusable agent skills that generalize across models.
invented entities (1)
-
Agent skill system consisting of eight phases
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AMD Ryzen AI Software,
AMD, “AMD Ryzen AI Software,” https://www.amd.com/en/products/ software/ryzen-ai-software.html, 2026, accessed: 2026-04-30
2026
-
[2]
Equipping Agents for the Real World with Agent Skills,
Anthropic, “Equipping Agents for the Real World with Agent Skills,” Anthropic Engineering Blog, https://www.anthropic.com/engineering/ equipping-agents-for-the-real-world-with-agent-skills, 2025
2025
-
[3]
KernelAgent: Hardware-Guided GPU Kernel Optimization via Multi-Agent Orchestration,
K. Cheng, L. Wang, J. Khuu, M. Saroufim, W. Chi, J. Wang, and J. Isaacson, “KernelAgent: Hardware-Guided GPU Kernel Optimization via Multi-Agent Orchestration,” PyTorch Blog, https://pytorch.org/blog/kernelagent-hardware-guided-gpu-kernel- optimization-via-multi-agent-orchestration/, 2026
2026
-
[4]
Dato: A task-based programming model for dataflow accelerators,
S. Fang, H. Chen, N. Zhang, J. Li, H. Meng, A. Liu, and Z. Zhang, “Dato: A task-based programming model for dataflow accelerators,” arXiv preprint arXiv:2509.06794, 2025
-
[5]
Run LLMs on AMD Ryzen™ AI NPUs in Minutes,
FastFlowLM, “Run LLMs on AMD Ryzen™ AI NPUs in Minutes,” https://fastflowlm.com/, 2026, accessed: 2026-04-30
2026
-
[6]
Autocomp: A Powerful and Portable Code Optimizer for Tensor Accelerators,
C. Hong, S. Bhatia, A. Cheung, and Y . S. Shao, “Autocomp: A Powerful and Portable Code Optimizer for Tensor Accelerators,” 2025. [Online]. Available: https://arxiv.org/abs/2505.18574
-
[7]
Efficiency, Expressivity, and Extensibility in a Close-to-Metal NPU Programming Interface,
E. Hunhoff, J. Melber, K. Denolf, A. Bisca, S. Bayliss, S. Neuendorffer, J. Fifield, J. Lo, P. Vasireddy, P. James-Roxby, and E. Keller, “Efficiency, Expressivity, and Extensibility in a Close-to-Metal NPU Programming Interface,” in2025 IEEE 33rd Annual International Symposium on Field- Programmable Custom Computing Machines (FCCM). IEEE, 2025, pp. 85–94
2025
-
[8]
NPUEval: Optimizing NPU Kernels with LLMs and Open Source Compilers,
S. Kalade and G. Schelle, “NPUEval: Optimizing NPU Kernels with LLMs and Open Source Compilers,” 2025. [Online]. Available: https://arxiv.org/abs/2507.14403
-
[9]
KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta,
G. Liao, H. Qin, Y . Wang, A. Golden, M. Kuchnik, Y . Yetim, J. J. Ang, C. Fu, Y . He, S. Hsia, Z. Jiang, D. Li, U. Pashkevich, V . Puvvada, F. Shi, M. Steiner, R. Xiao, N. Yan, X. Yu, Z. Fang, R. Levenstein, K. Ho, H. Zhu, A. Hammond, R. Li, A. Mathews, K. Gondkar, A. Zainul-Abedin, K. Singh, H. Yu, W. Chi, B. Huang, S. Zhang, N. Weller, Z. Marine, W. Co...
-
[10]
AMD XDNA NPU in Ryzen AI Processors,
A. Rico, S. Pareek, J. Cabezas, D. Clarke, B. Ozgul, F. Barat, Y . Fu, S. M ¨unz, D. Stuart, P. Schlangen, P. Duarte, S. Date, I. Paul, J. Weng, S. Santan, V . Kathail, A. Sirasao, and J. Noguera, “AMD XDNA NPU in Ryzen AI Processors,”IEEE Micro, vol. 44, no. 6, pp. 73–82, 2024
2024
-
[11]
Superpowers: An Agentic Skills Framework & Soft- ware Development Methodology that Works,
J. Vincent, “Superpowers: An Agentic Skills Framework & Soft- ware Development Methodology that Works,” https://github.com/obra/ superpowers, 2026, accessed: 2026-04-30
2026
-
[12]
From Loop Nests to Silicon: Mapping AI Workloads onto AMD NPUs with MLIR-AIR,
E. Wang, S. Bayliss, A. Bisca, Z. Blair, S. Chowdhary, K. Denolf, J. Fifield, B. Freiberger, E. Hunhoff, P. James-Roxby, J. Lo, J. Melber, S. Neuendorffer, E. Richter, A. Rosti, J. Setoain, G. Singh, E. Taka, P. Vasireddy, Z. Yu, N. Zhang, and J. Zhuang, “From Loop Nests to Silicon: Mapping AI Workloads onto AMD NPUs with MLIR-AIR,” ACM Transactions on Re...
2025
-
[13]
Geak: Introducing Triton Kernel AI Agent & Evaluation Benchmarks,
J. Wang, V . Joshi, S. Majumder, X. Chao, B. Ding, Z. Liu, P. P. Brahma, D. Li, Z. Liu, and E. Barsoum, “Geak: Introducing Triton Kernel AI Agent & Evaluation Benchmarks,” 2025. [Online]. Available: https://arxiv.org/abs/2507.23194
-
[14]
Astra: A Multi-Agent System for GPU Kernel Performance Optimization,
A. Wei, T. Sun, Y . Seenichamy, H. Song, A. Ouyang, A. Mirhoseini, K. Wang, and A. Aiken, “Astra: A Multi-Agent System for GPU Kernel Performance Optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2509.07506
-
[15]
AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization
G. Zhang, S. Zhu, A. Wei, Z. Song, A. Nie, Z. Jia, N. Vijaykumar, Y . Wang, and K. Olukotun, “AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization,” 2026. [Online]. Available: https://arxiv.org/abs/2511.15915
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. Gonzalez, and I. Stoica, “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 202...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.