Repetition Mismatch: Why Data Mixture Experiments Don't Scale and How to Fix Them
Pith reviewed 2026-06-28 23:17 UTC · model grok-4.3
The pith
Matching repetition rates in small proxy experiments recovers near-optimal data mixtures even when high-quality sources must be repeated at full scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
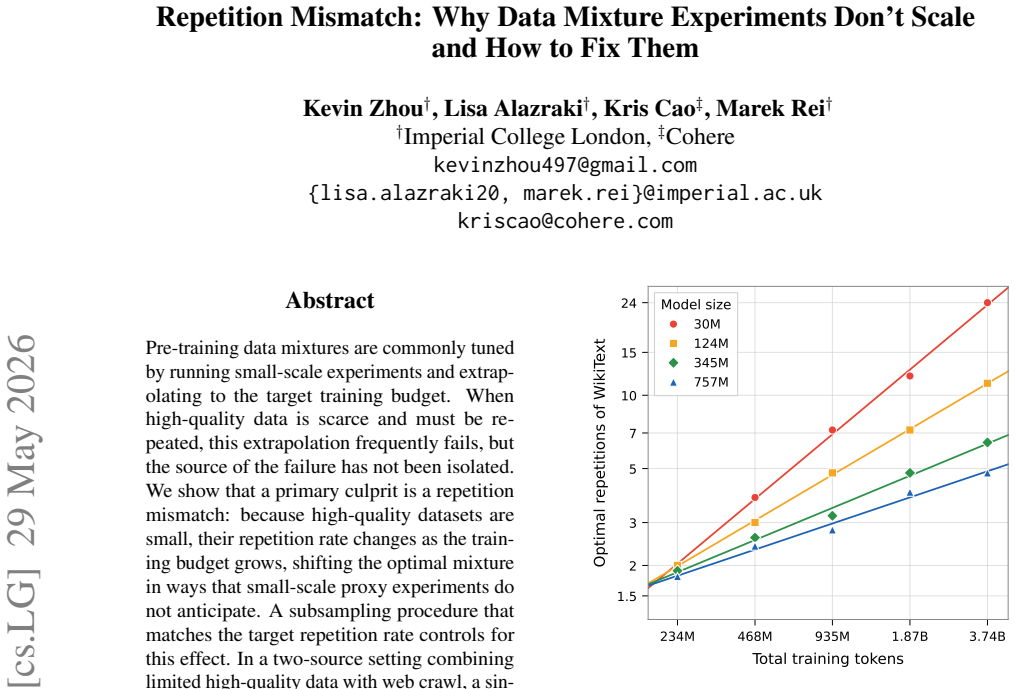
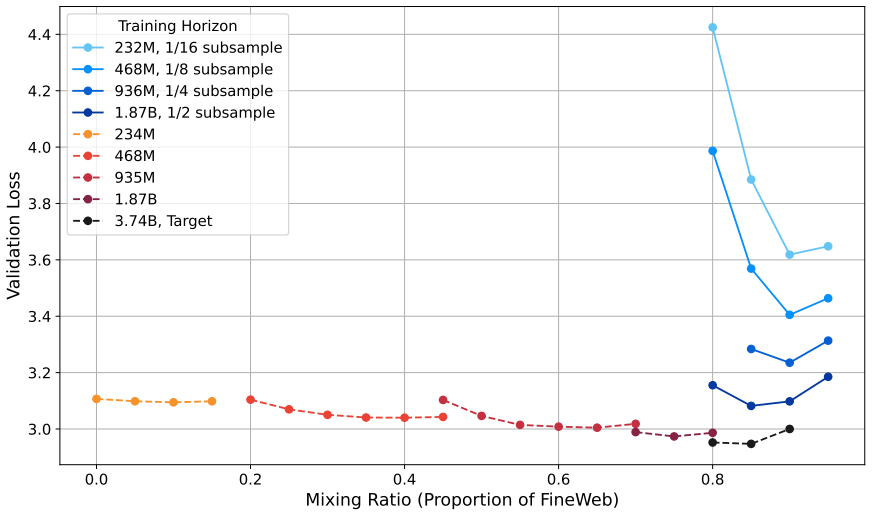
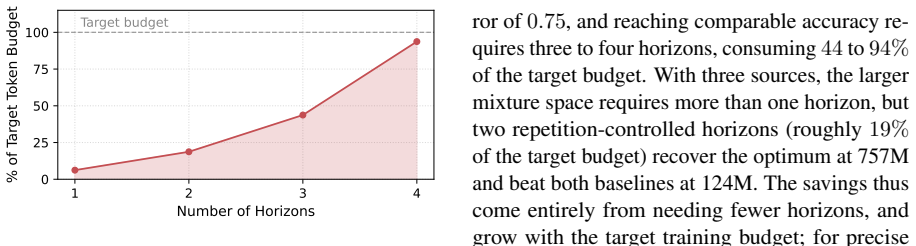
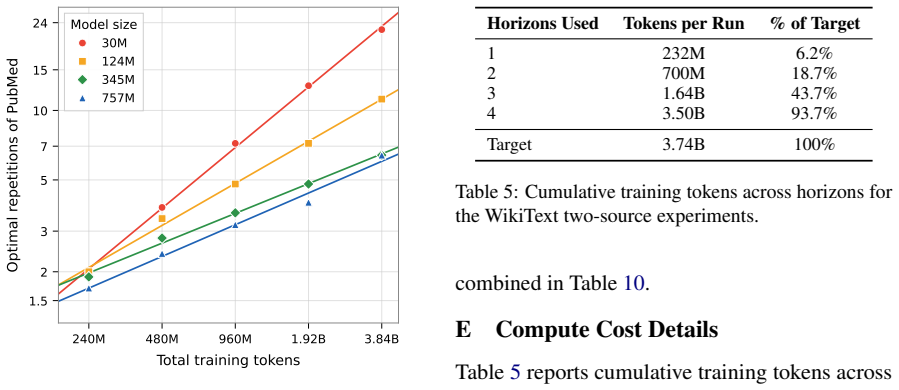
Repetition mismatch occurs because high-quality datasets are small, so their repeat frequency necessarily rises with larger training budgets; this changes the optimal mixture in ways that ordinary small-scale proxies do not capture. A subsampling procedure that matches the target repetition rate in the proxy run controls for the effect. In two-source experiments this single controlled run at 1/16 scale recovers a mixture within 0.05 of optimum, while uncontrolled runs require three to four horizons consuming 44-94% of the target budget. With three sources the method still works, needing only two controlled horizons at the 757M scale.
What carries the argument
repetition-controlled subsampling: the procedure that adjusts the composition of a small-scale training run so its repetition frequency exactly matches the frequency that will occur in the full target budget.
If this is right
- One repetition-controlled experiment at 1/16 scale suffices for two-source mixtures to reach within 0.05 of optimum.
- Without repetition control, three to four scale-ups consuming most of the target budget are required for comparable accuracy.
- For three-source mixtures, two controlled experiments recover the optimum while baselines need the full set of two-source experiments.
- Repetition dynamics, rather than scale alone, determine whether small mixture experiments generalize.
Where Pith is reading between the lines
- The same repetition-matching logic could be tested on other variables whose frequency changes with scale, such as data diversity or domain proportions.
- If the pattern holds at larger model sizes, mixture tuning budgets could drop by an order of magnitude across many pre-training runs.
- The approach treats repetition as an explicit design variable rather than an unavoidable side effect, which may encourage new data-collection strategies that deliberately vary repetition rates.
Load-bearing premise
Repetition rate is the dominant isolated cause of extrapolation failure, with other scale-dependent effects either negligible or already controlled in the experiments.
What would settle it
A repetition-controlled proxy experiment at small scale that predicts a mixture, followed by full-scale training of that mixture at the matched repetition rate, that still underperforms the true optimum by a large margin.
Figures
read the original abstract
Pre-training data mixtures are commonly tuned by running small-scale experiments and extrapolating to the target training budget. When high-quality data is scarce and must be repeated, this extrapolation frequently fails, but the source of the failure has not been isolated. We show that a primary culprit is a repetition mismatch: because high-quality datasets are small, their repetition rate changes as the training budget grows, shifting the optimal mixture in ways that small-scale proxy experiments do not anticipate. A subsampling procedure that matches the target repetition rate controls for this effect. In a two-source setting combining limited high-quality data with web crawl, a single repetition-controlled experiment using only 1/16 of the target tokens recovers a mixture within 0.05 of the optimum for a 757M parameter model, compared to an error of 0.75 without repetition control. Achieving comparable accuracy without repetition control requires three to four horizons, consuming 44 to 94% of the target token budget. With three data sources, the larger mixture space requires more than a single experiment to constrain, but the approach remains effective: at the 757M scale, just two repetition-controlled horizons recover the optimal mixture, outperforming baselines that instead require the full two-source experiments to construct. Our results reveal that repetition dynamics, not scale alone, shape whether small-scale mixture experiments generalize. More broadly, they suggest that data repetition deserves treatment as a first-class variable in mixture optimization, rather than an inconvenient side effect of limited data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that repetition mismatch—arising because high-quality data repetition rates increase with training budget—is the primary cause of failed extrapolation in small-scale data mixture experiments. It introduces a subsampling procedure to match target repetition rates and reports that, in a two-source (high-quality + web) setting, one repetition-controlled run at 1/16 of the target token budget recovers a mixture within 0.05 of optimum for a 757M model (vs. 0.75 error without control); comparable accuracy without control requires 44-94% of the target budget. For three sources, two controlled horizons suffice where baselines need more.
Significance. If the isolation of repetition as the dominant factor holds, the work is significant: it reframes repetition as a first-class variable rather than a side effect and supplies a practical, low-compute method for mixture tuning that demonstrably reduces required token budget. The quantitative recovery metrics and multi-horizon comparisons provide concrete evidence of the efficiency gain.
major comments (2)
- [two-source setting experiments] The central attribution of improved extrapolation to repetition control (rather than other scale-dependent factors) requires that the subsampling procedure isolates repetition rate. However, matching the target repetition rate at the 1/16 horizon necessarily uses a smaller unique subset of the high-quality source, which reduces data diversity relative to the full-target regime. No ablation is described that holds diversity fixed while varying repetition (or vice versa), so the 0.05 vs. 0.75 error comparison cannot yet be attributed solely to repetition mismatch.
- [three data sources results] The three-source results similarly rest on the claim that repetition-controlled horizons suffice to constrain the larger mixture space. The same subsampling-induced diversity reduction applies, and without an explicit control or sensitivity analysis for diversity effects, it remains unclear whether the reported outperformance over baselines is driven by repetition matching or by the altered data distribution at small scale.
minor comments (2)
- The abstract and results sections would benefit from explicit statement of the statistical procedure used to compute the reported recovery errors (0.05, 0.75) and any error bars or significance tests.
- Notation for repetition rate and the subsampling ratio should be defined once in a dedicated methods subsection rather than introduced inline in the experimental descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of treating repetition as a first-class variable. We respond point-by-point to the major comments below, acknowledging the diversity confound introduced by subsampling.
read point-by-point responses
-
Referee: [two-source setting experiments] The central attribution of improved extrapolation to repetition control (rather than other scale-dependent factors) requires that the subsampling procedure isolates repetition rate. However, matching the target repetition rate at the 1/16 horizon necessarily uses a smaller unique subset of the high-quality source, which reduces data diversity relative to the full-target regime. No ablation is described that holds diversity fixed while varying repetition (or vice versa), so the 0.05 vs. 0.75 error comparison cannot yet be attributed solely to repetition mismatch.
Authors: We agree the subsampling reduces unique high-quality tokens and thereby alters diversity relative to the full-target regime; this is an inherent feature of matching repetition at reduced scale. Our primary comparisons hold scale and token budget fixed while varying only whether repetition rates are matched, producing the observed gap in extrapolation error. We will revise the manuscript to explicitly state this limitation, clarify that the results demonstrate practical utility of repetition control rather than perfect isolation, and note that a dedicated diversity-controlled ablation lies outside the current experimental budget. revision: partial
-
Referee: [three data sources results] The three-source results similarly rest on the claim that repetition-controlled horizons suffice to constrain the larger mixture space. The same subsampling-induced diversity reduction applies, and without an explicit control or sensitivity analysis for diversity effects, it remains unclear whether the reported outperformance over baselines is driven by repetition matching or by the altered data distribution at small scale.
Authors: The diversity reduction applies equally in the three-source setting. All reported comparisons (controlled vs. baseline) use the identical small-scale regime, differing only in repetition matching; the outperformance is therefore measured under the same diversity shift. We will add a short sensitivity discussion in revision acknowledging that diversity effects cannot be fully disentangled without further experiments, while preserving the empirical observation that repetition-controlled horizons require fewer runs than the baselines. revision: partial
Circularity Check
No circularity: empirical comparisons are self-contained
full rationale
The paper reports direct experimental measurements comparing repetition-controlled vs. uncontrolled small-scale proxy runs for data mixture optimization. These results are obtained from actual training runs and do not reduce via any equations or self-citations to quantities fitted on the target data itself. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems, or ansatzes appear in the derivation chain. The work is self-contained empirical evidence rather than a mathematical reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Repetition rate of high-quality data is the dominant driver of mixture optimality shifts across training budgets.
Reference graph
Works this paper leans on
-
[1]
Greenwade
George D. Greenwade. The C omprehensive T ex A rchive N etwork ( CTAN ). TUGBoat. 1993
1993
-
[2]
2024 , eprint=
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
2024
-
[3]
2025 , eprint=
Command A: An Enterprise-Ready Large Language Model , author=. 2025 , eprint=
2025
-
[4]
CCN et: Extracting High Quality Monolingual Datasets from Web Crawl Data
Wenzek, Guillaume and Lachaux, Marie-Anne and Conneau, Alexis and Chaudhary, Vishrav and Guzm \'a n, Francisco and Joulin, Armand and Grave, Edouard. CCN et: Extracting High Quality Monolingual Datasets from Web Crawl Data. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[5]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[6]
Sennrich, Rico and Haddow, Barry and Birch, Alexandra. Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1162
-
[7]
On the Properties of Neural Machine Translation: Encoder-Decoder Approaches , booktitle =
Kyunghyun Cho and Bart van Merrienboer and Dzmitry Bahdanau and Yoshua Bengio , editor =. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches , booktitle =. 2014 , url =. doi:10.3115/V1/W14-4012 , timestamp =
-
[8]
Effective Approaches to Attention-based Neural Machine Translation
Luong, Thang and Pham, Hieu and Manning, Christopher D. Effective Approaches to Attention-based Neural Machine Translation. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. doi:10.18653/v1/D15-1166
-
[9]
Project Gutenberg , url =
-
[10]
Proceedings of the Ninth Workshop on Statistical Machine Translation. 2014
2014
-
[11]
Bowman , editor =
Alex Wang and Yada Pruksachatkun and Nikita Nangia and Amanpreet Singh and Julian Michael and Felix Hill and Omer Levy and Samuel R. Bowman , editor =. SuperGLUE:. Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada , pages =. 2019 , url =
2019
-
[12]
Yi Tay and Mostafa Dehghani and Vinh Q. Tran and Xavier Garcia and Jason Wei and Xuezhi Wang and Hyung Won Chung and Dara Bahri and Tal Schuster and Huaixiu Steven Zheng and Denny Zhou and Neil Houlsby and Donald Metzler , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[13]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[14]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[15]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin. H ella S wag: Can a Machine Really Finish Your Sentence?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1472
-
[16]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , editor =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , booktitle =. 2022 , url =
2022
-
[17]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , editor =...
2022
-
[18]
Christiano and Jan Leike and Tom B
Paul F. Christiano and Jan Leike and Tom B. Brown and Miljan Martic and Shane Legg and Dario Amodei , editor =. Deep Reinforcement Learning from Human Preferences , booktitle =. 2017 , url =
2017
-
[19]
2024 , url =
Keller Jordan and Jeremy Bernstein and Brendan Rappazzo and @fernbear.bsky.social and Boza Vlado and You Jiacheng and Franz Cesista and Braden Koszarsky and @Grad62304977 , title =. 2024 , url =
2024
-
[20]
2025 , url =
OpenAI , title =. 2025 , url =
2025
-
[21]
RoFormer: Enhanced transformer with Rotary Position Embedding , journal =
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , title =. 2024 , issue_date =. doi:10.1016/j.neucom.2023.127063 , journal =
-
[22]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[23]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[24]
2025 , eprint=
Beyond Scale: The Diversity Coefficient as a Data Quality Metric for Variability in Natural Language Data , author=. 2025 , eprint=
2025
-
[25]
nature , keywords =
Rumelhart, David E and Hinton, Geoffrey E and Williams, Ronald J , biburl =. nature , keywords =
-
[26]
, journal=
Werbos, P.J. , journal=. Backpropagation through time: what it does and how to do it , year=
-
[27]
Hinton , editor =
Alex Krizhevsky and Ilya Sutskever and Geoffrey E. Hinton , editor =. ImageNet Classification with Deep Convolutional Neural Networks , booktitle =. 2012 , url =
2012
-
[28]
Dan C. Ciresan and Ueli Meier and J. Multi-column deep neural networks for image classification , booktitle =. 2012 , url =. doi:10.1109/CVPR.2012.6248110 , timestamp =
-
[29]
Le , editor =
Ilya Sutskever and Oriol Vinyals and Quoc V. Le , editor =. Sequence to Sequence Learning with Neural Networks , booktitle =. 2014 , url =
2014
-
[30]
Sepp Hochreiter and J. Long Short-Term Memory , journal =. 1997 , url =. doi:10.1162/NECO.1997.9.8.1735 , timestamp =
-
[31]
and Barak, Boaz and Le Scao, Teven and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin , title =
Muennighoff, Niklas and Rush, Alexander M. and Barak, Boaz and Le Scao, Teven and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[32]
2025 , eprint=
Data Mixing Can Induce Phase Transitions in Knowledge Acquisition , author=. 2025 , eprint=
2025
-
[33]
Stella Biderman and Hailey Schoelkopf and Quentin Gregory Anthony and Herbie Bradley and Kyle O'Brien and Eric Hallahan and Mohammad Aflah Khan and Shivanshu Purohit and USVSN Sai Prashanth and Edward Raff and Aviya Skowron and Lintang Sutawika and Oskar van der Wal , editor =. Pythia:. International Conference on Machine Learning,. 2023 , url =
2023
-
[34]
GPT - N eo X -20 B : An Open-Source Autoregressive Language Model
Black, Sidney and Biderman, Stella and Hallahan, Eric and Anthony, Quentin and Gao, Leo and Golding, Laurence and He, Horace and Leahy, Connor and McDonell, Kyle and Phang, Jason and Pieler, Michael and Prashanth, Usvsn Sai and Purohit, Shivanshu and Reynolds, Laria and Tow, Jonathan and Wang, Ben and Weinbach, Samuel. GPT - N eo X -20 B : An Open-Source ...
-
[35]
The Nonstochastic Multiarmed Bandit Problem , journal =
Peter Auer and Nicol. The Nonstochastic Multiarmed Bandit Problem , journal =. 2002 , url =. doi:10.1137/S0097539701398375 , timestamp =
-
[36]
Alon Albalak and Liangming Pan and Colin Raffel and William Yang Wang , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2312.02406 , eprinttype =. 2312.02406 , timestamp =
-
[37]
SQuAD: 100, 000+ Questions for Machine Comprehension of Text , booktitle =
Pranav Rajpurkar and Jian Zhang and Konstantin Lopyrev and Percy Liang , editor =. SQuAD: 100, 000+ Questions for Machine Comprehension of Text , booktitle =. 2016 , url =. doi:10.18653/V1/D16-1264 , timestamp =
-
[38]
GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel. GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP. 2018. doi:10.18653/v1/W18-5446
-
[39]
Peters and Mark Neumann and Luke Zettlemoyer and Wen
Matthew E. Peters and Mark Neumann and Luke Zettlemoyer and Wen. Dissecting Contextual Word Embeddings: Architecture and Representation , booktitle =. 2018 , url =. doi:10.18653/V1/D18-1179 , timestamp =
-
[40]
Zemel and Ruslan Salakhutdinov and Raquel Urtasun and Antonio Torralba and Sanja Fidler , title =
Yukun Zhu and Ryan Kiros and Richard S. Zemel and Ruslan Salakhutdinov and Raquel Urtasun and Antonio Torralba and Sanja Fidler , title =. 2015. 2015 , url =. doi:10.1109/ICCV.2015.11 , timestamp =
-
[41]
9th International Conference on Learning Representations,
Dmitry Lepikhin and HyoukJoong Lee and Yuanzhong Xu and Dehao Chen and Orhan Firat and Yanping Huang and Maxim Krikun and Noam Shazeer and Zhifeng Chen , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[42]
William Fedus and Barret Zoph and Noam Shazeer , title =. J. Mach. Learn. Res. , volume =. 2022 , url =
2022
-
[43]
Liu and Mohammad Saleh and Etienne Pot and Ben Goodrich and Ryan Sepassi and Lukasz Kaiser and Noam Shazeer , title =
Peter J. Liu and Mohammad Saleh and Etienne Pot and Ben Goodrich and Ryan Sepassi and Lukasz Kaiser and Noam Shazeer , title =. 6th International Conference on Learning Representations,. 2018 , url =
2018
-
[44]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[45]
MiniMax-01: Scaling Foundation Models with Lightning Attention
Aonian Li and Bangwei Gong and Bo Yang and Boji Shan and Chang Liu and Cheng Zhu and Chunhao Zhang and Congchao Guo and Da Chen and Dong Li and Enwei Jiao and Gengxin Li and Guojun Zhang and Haohai Sun and Houze Dong and Jiadai Zhu and Jiaqi Zhuang and Jiayuan Song and Jin Zhu and Jingtao Han and Jingyang Li and Junbin Xie and Junhao Xu and Junjie Yan and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.08313 2025
-
[46]
Scaling Laws for Optimal Data Mixtures , url =
Shukor, Mustafa and Bethune, Louis and Busbridge, Dan and Grangier, David and Fini, Enrico and El-Nouby, Alaaeldin and Ablin, Pierre , booktitle =. Scaling Laws for Optimal Data Mixtures , url =
-
[47]
C Users J
Gage, Philip , title =. C Users J. , month = feb, pages =. 1994 , issue_date =
1994
-
[48]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2020 , issue_date =
2020
-
[49]
Common Crawl , url =
-
[50]
OPT 2024: Optimization for Machine Learning , year=
Old Optimizer, New Norm: An Anthology , author=. OPT 2024: Optimization for Machine Learning , year=
2024
-
[51]
PaLM: Scaling Language Modeling with Pathways , journal =
Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam Shazeer and Vinodkumar Prabhakaran and Emi...
2023
-
[52]
Penedo, Guilherme and Kydl\'. The. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[53]
Ilyas , title =
Michael Stonebraker and Ihab F. Ilyas , title =. 2018 , url =
2018
-
[54]
Connor Shorten and Taghi M. Khoshgoftaar , title =. J. Big Data , volume =. 2019 , url =. doi:10.1186/S40537-019-0197-0 , timestamp =
-
[55]
Alex Bogatu and Alvaro A. A. Fernandes and Norman W. Paton and Nikolaos Konstantinou , title =. 36th. 2020 , url =. doi:10.1109/ICDE48307.2020.00067 , timestamp =
-
[56]
Daochen Zha and Zaid Pervaiz Bhat and Kwei. Data-centric. Proceedings of the 2023. 2023 , url =. doi:10.1137/1.9781611977653.CH106 , timestamp =
-
[57]
Neural Machine Translation by Jointly Learning to Align and Translate , booktitle =
Dzmitry Bahdanau and Kyunghyun Cho and Yoshua Bengio , editor =. Neural Machine Translation by Jointly Learning to Align and Translate , booktitle =. 2015 , url =
2015
-
[58]
2023 , publisher =
OpenHermes 2.5: An Open Dataset of Synthetic Data for Generalist LLM Assistants , author =. 2023 , publisher =
2023
-
[59]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Penedo, Guilherme and Malartic, Quentin and Hesslow, Daniel and Cojocaru, Ruxandra and Alobeidli, Hamza and Cappelli, Alessandro and Pannier, Baptiste and Almazrouei, Ebtesam and Launay, Julien , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[60]
How to train data-efficient LLMs
Noveen Sachdeva and Benjamin Coleman and Wang. How to Train Data-Efficient LLMs , journal =. 2024 , url =. doi:10.48550/ARXIV.2402.09668 , eprinttype =. 2402.09668 , timestamp =
-
[61]
2025 , eprint=
QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining , author=. 2025 , eprint=
2025
-
[62]
Maurice Weber and Daniel Y. Fu and Quentin Anthony and Yonatan Oren and Shane Adams and Anton Alexandrov and Xiaozhong Lyu and Huu Nguyen and Xiaozhe Yao and Virginia Adams and Ben Athiwaratkun and Rahul Chalamala and Kezhen Chen and Max Ryabinin and Tri Dao and Percy Liang and Christopher R. Red. Advances in Neural Information Processing Systems 38: Annu...
2024
-
[63]
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie. L. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2302.13971 , eprinttype =. 2302.13971 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[64]
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie-Anne Lachaux and Timothée Lacroix and Baptiste Rozière and Naman Goyal and Eric Hambro and Faisal Azhar and Aurelien Rodriguez and Armand Joulin and Edouard Grave and Guillaume Lample , year=. L. 2302.13971 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan and Jared Kaplan and Mor Katz and Mark Chen and Christopher Hesse and Jacob Jackson and Heewoo Jun and Tom B. Brown and Prafulla Dhariwal and Scott Gray and Chris Hallacy and Benjamin Mann and Alec Radford and Aditya Ramesh and Nick Ryder and Daniel M. Ziegler and John Schulman and Dario Amodei and Sam McCandlish , title =. CoRR , volume =. 2...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[66]
OpenAI , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.08774 , eprinttype =. 2303.08774 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[67]
2024 , editor =
Fan, Simin and Pagliardini, Matteo and Jaggi, Martin , booktitle =. 2024 , editor =
2024
-
[68]
9th International Conference on Learning Representations,
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[69]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W. Rae and Sebastian Borgeaud and Trevor Cai and Katie Millican and Jordan Hoffmann and H. Francis Song and John Aslanides and Sarah Henderson and Roman Ring and Susannah Young and Eliza Rutherford and Tom Hennigan and Jacob Menick and Albin Cassirer and Richard Powell and George van den Driessche and Lisa Anne Hendricks and Maribeth Rauh and Po. Sca...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[70]
and Sifre, Laurent , title =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
2022
-
[71]
Scaling Laws for Neural Language Models
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. CoRR , volume =. 2020 , url =. 2001.08361 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[72]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao and Stella Biderman and Sid Black and Laurence Golding and Travis Hoppe and Charles Foster and Jason Phang and Horace He and Anish Thite and Noa Nabeshima and Shawn Presser and Connor Leahy , title =. CoRR , volume =. 2021 , url =. 2101.00027 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[73]
Oren, Yonatan and Sagawa, Shiori and Hashimoto, Tatsunori B. and Liang, Percy. Distributionally Robust Language Modeling. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1432
-
[74]
The Thirteenth International Conference on Learning Representations,
Jiasheng Ye and Peiju Liu and Tianxiang Sun and Jun Zhan and Yunhua Zhou and Xipeng Qiu , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[75]
Lee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-Burch, C., and Carlini, N
Lee, Katherine and Ippolito, Daphne and Nystrom, Andrew and Zhang, Chiyuan and Eck, Douglas and Callison-Burch, Chris and Carlini, Nicholas. Deduplicating Training Data Makes Language Models Better. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.577
-
[76]
2022 , editor =
Du, Nan and Huang, Yanping and Dai, Andrew M and Tong, Simon and Lepikhin, Dmitry and Xu, Yuanzhong and Krikun, Maxim and Zhou, Yanqi and Yu, Adams Wei and Firat, Orhan and Zoph, Barret and Fedus, Liam and Bosma, Maarten P and Zhou, Zongwei and Wang, Tao and Wang, Emma and Webster, Kellie and Pellat, Marie and Robinson, Kevin and Meier-Hellstern, Kathleen...
2022
-
[77]
B ench: Extending Long Context Evaluation Beyond 100 K Tokens
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo and Han, Xu and Thai, Zhen and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong. B ench: Extending Long Context Evaluation Beyond 100 K Tokens. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[78]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton. Llama 2: Open Foundation and Fine-Tuned Chat Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2307.09288 , eprinttype ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[79]
Needle In A Haystack - Pressure Testing LLMs
[Kamradt, Gregory] , year=. Needle In A Haystack - Pressure Testing LLMs
-
[80]
Gomez and Lukasz Kaiser and Illia Polosukhin , editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , editor =. Attention is All you Need , booktitle =. 2017 , url =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.