Crayotter: Traceable Multi-Agent Workflows for Long-Form Video Editing
Pith reviewed 2026-06-28 17:00 UTC · model grok-4.3
The pith
Crayotter organizes prompt-driven long-form video editing into three phases that externalize inspectable artifacts for traceability and selective fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
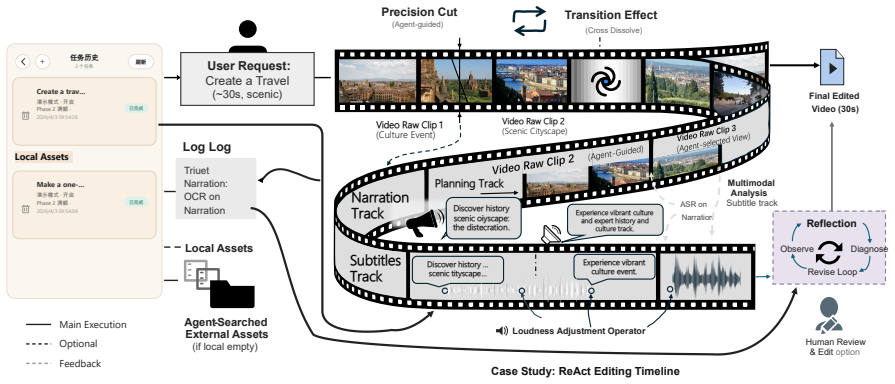
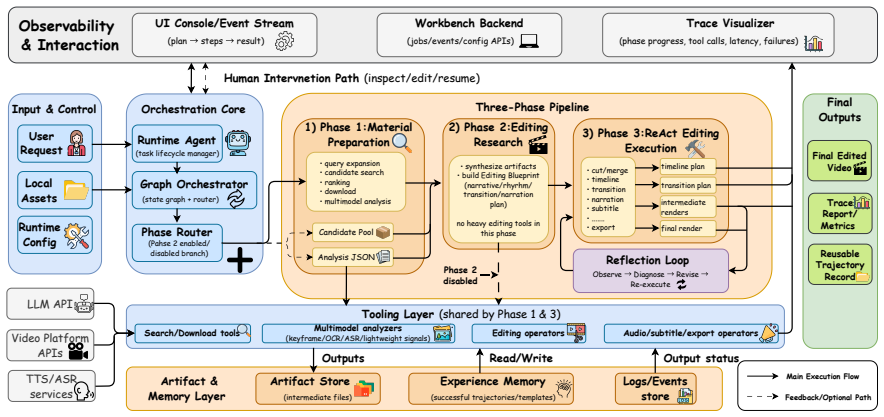
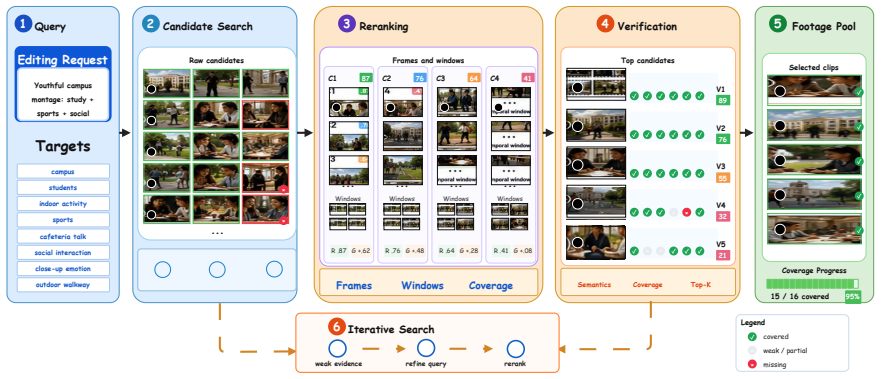
Crayotter organizes production into three phases: coverage-aware material preparation, artifact-based editing research, and tool-grounded timeline execution. Each phase externalizes inspectable artifacts, including coverage reports, multimodal analyses, editing blueprints, tool calls, and intermediate renders. These artifacts make an editing run traceable and allow failed segments to be diagnosed and selectively revised instead of requiring a full restart.
What carries the argument
The three-phase workflow that externalizes artifacts to enable traceability, diagnosis, and selective revision in multi-agent prompt-driven video editing.
If this is right
- Editing runs become traceable so specific failed segments can be revised without restarting the entire workflow.
- Human scores improve consistently across theme alignment, narrative coherence, and editing smoothness relative to the tested baselines.
- The replayable trajectory schema and verifiable reward design enable preparation for policy optimization in future work.
Where Pith is reading between the lines
- The artifact-externalization approach could reduce wasted computation in other iterative multi-agent creative tasks by allowing targeted fixes.
- Traceability features might support auditing or regulatory review in commercial video production pipelines.
- Combining the verifiable rewards with reinforcement learning could lead to measurable performance gains on the same editing themes.
Load-bearing premise
The 23 editing themes and chosen human evaluators represent a fair and unbiased sample of real-world long-form video editing performance.
What would settle it
An independent evaluation on a new set of editing themes or with different evaluators that shows Crayotter scoring at or below the baselines of 2.44 and 1.70.
Figures

read the original abstract
Editing a long-form video from heterogeneous footage requires more than selecting clips: an agent must preserve narrative intent across material preparation, timeline construction, post-production, and revision while leaving enough evidence to diagnose failures. We present \textbf{Crayotter}, an open-source multimodal multi-agent system for prompt-driven video editing. Crayotter organizes production into three phases: coverage-aware material preparation, artifact-based editing research, and tool-grounded timeline execution. Each phase externalizes inspectable artifacts, including coverage reports, multimodal analyses, editing blueprints, tool calls, and intermediate renders. These artifacts make an editing run traceable and allow failed segments to be diagnosed and selectively revised instead of requiring a full restart. We evaluate Crayotter on 23 editing themes against CapCut-Mate and CutClaw. Under human evaluation, Crayotter achieves an average score of 3.40/5, compared with 2.44 and 1.70 for the two baselines, with consistent gains in theme alignment, narrative coherence, and editing smoothness. We additionally describe a replayable trajectory schema and verifiable reward design that prepare these workflows for future policy optimization. Code, traces, and examples are publicly available at https://github.com/idwts/Crayotter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Crayotter, an open-source multimodal multi-agent system for prompt-driven long-form video editing organized into coverage-aware material preparation, artifact-based editing research, and tool-grounded timeline execution phases. These phases externalize inspectable artifacts to enable traceability and selective revision. The system is evaluated on 23 editing themes against CapCut-Mate and CutClaw, with human evaluation showing an average score of 3.40/5 for Crayotter compared to 2.44 and 1.70 for the baselines, along with gains in theme alignment, narrative coherence, and editing smoothness. A replayable trajectory schema and verifiable reward design are also described to support future policy optimization, with code and traces publicly available.
Significance. If the results hold, the work contributes a traceable multi-agent approach to long-form video editing that addresses the challenge of preserving narrative intent across complex production steps. The emphasis on externalized artifacts for diagnosis is a useful design principle, and the open-source release with public traces strengthens the potential for adoption and further research in AI-assisted video production.
major comments (1)
- [Abstract] The headline performance claim depends on the human evaluation (average score 3.40/5 vs. 2.44 and 1.70), yet the manuscript provides no details on the number of evaluators, their expertise, inter-rater agreement, blinding protocol, statistical significance, or the criteria used to select and diversify the 23 editing themes. This information is necessary to substantiate the consistent gains reported in theme alignment, narrative coherence, and editing smoothness.
minor comments (1)
- [Abstract] The description of the three phases could include a brief example of an artifact to illustrate the traceability benefit more concretely.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the transparency of our human evaluation. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The headline performance claim depends on the human evaluation (average score 3.40/5 vs. 2.44 and 1.70), yet the manuscript provides no details on the number of evaluators, their expertise, inter-rater agreement, blinding protocol, statistical significance, or the criteria used to select and diversify the 23 editing themes. This information is necessary to substantiate the consistent gains reported in theme alignment, narrative coherence, and editing smoothness.
Authors: We agree that the manuscript lacks these methodological details, which weakens the substantiation of the headline claims. In the revised version we will add a dedicated subsection (likely in Experiments) that reports: the number of evaluators and their expertise/backgrounds; the blinding protocol; inter-rater agreement statistics; the statistical tests and significance levels for the reported metric improvements; and the explicit criteria and diversification strategy used to select the 23 themes from a larger candidate pool. We will also include per-theme score breakdowns to support the consistency statements. revision: yes
Circularity Check
No significant circularity; empirical evaluation only
full rationale
The paper presents Crayotter as a multi-agent video editing system and reports direct human-evaluation scores (3.40/5) against two external baselines on 23 themes. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. The central claim is an empirical head-to-head comparison whose validity rests on the representativeness of the test set and raters rather than any reduction of a result to its own inputs by construction. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Eleventh International Conference on Learning Representations , year =
React: Synergizing reasoning and acting in language models , author =. The Eleventh International Conference on Learning Representations , year =
-
[2]
First Conference on Language Modeling , year =
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author =. First Conference on Language Modeling , year =
-
[3]
The Twelfth International Conference on Learning Representations , year =
MetaGPT: Meta programming for a multi-agent collaborative framework , author =. The Twelfth International Conference on Learning Representations , year =
-
[4]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages =
ResearStudio: A Human-intervenable Framework for Building Controllable Deep Research Agents , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages =
2025
-
[5]
DeepPresenter: Environment-Grounded Reflection for Agentic Presentation Generation
DeepPresenter: Environment-Grounded Reflection for Agentic Presentation Generation , author =. arXiv preprint arXiv:2602.22839 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
Dr tulu: Reinforcement learning with evolving rubrics for deep research , author =. arXiv preprint arXiv:2511.19399 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2602.05975 , year =
SAGE: Benchmarking and Improving Retrieval for Deep Research Agents , author =. arXiv preprint arXiv:2602.05975 , year =
-
[8]
arXiv preprint arXiv:2501.12909 , year =
Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces , author =. arXiv preprint arXiv:2501.12909 , year =
-
[9]
arXiv preprint arXiv:2503.07314 , year =
Automated movie generation via multi-agent cot planning , author =. arXiv preprint arXiv:2503.07314 , year =
-
[10]
arXiv preprint arXiv:2503.05242 , year =
Mm-storyagent: Immersive narrated storybook video generation with a multi-agent paradigm across text, image and audio , author =. arXiv preprint arXiv:2503.05242 , year =
-
[11]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages =
AniMaker: Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation , author =. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages =
2025
-
[12]
arXiv preprint arXiv:2309.15091 , year =
Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning , author =. arXiv preprint arXiv:2309.15091 , year =
-
[13]
arXiv preprint arXiv:2408.11788 , year =
Dreamfactory: Pioneering multi-scene long video generation with a multi-agent framework , author =. arXiv preprint arXiv:2408.11788 , year =
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence , publisher =
Dreamstory: Open-domain story visualization by llm-guided multi-subject consistent diffusion , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , publisher =
-
[15]
Story-Iter: A Training-free Iterative Paradigm for Long Story Visualization , author =
-
[16]
arXiv preprint arXiv:2505.24862 , year =
Vistorybench: Comprehensive benchmark suite for story visualization , author =. arXiv preprint arXiv:2505.24862 , year =
-
[17]
Advances in Neural Information Processing Systems , volume =
Fifo-diffusion: Generating infinite videos from text without training , author =. Advances in Neural Information Processing Systems , volume =
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Long context tuning for video generation , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Mind the time: Temporally-controlled multi-event video generation , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[20]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
One-minute video generation with test-time training , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Evalcrafter: Benchmarking and evaluating large video generation models , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[22]
2025 , eprint =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , eprint =
2025
-
[23]
2024 , eprint =
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. 2024 , eprint =
2024
-
[24]
2024 , eprint =
A Reinforcement Learning-Based Automatic Video Editing Method Using Pre-trained Vision-Language Model , author =. 2024 , eprint =
2024
-
[25]
2024 , eprint =
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation , author =. 2024 , eprint =
2024
-
[26]
2024 , eprint =
VideoDPO: Omni-Preference Alignment for Video Diffusion Generation , author =. 2024 , eprint =
2024
-
[27]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-Judge , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[28]
2024 , eprint=
Agent-based Video Trimming , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
EditDuet: A Multi-Agent System for Video Non-Linear Editing , author=. 2025 , eprint=
2025
-
[30]
2026 , eprint=
CutClaw: Agentic Hours-Long Video Editing via Music Synchronization , author=. 2026 , eprint=
2026
-
[31]
2025 , eprint=
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist , author=. 2025 , eprint=
2025
-
[32]
DIRECT: Video Mashup Creation via Hierarchical Multi-Agent Planning and Intent-Guided Editing
DIRECT: Video Mashup Creation via Hierarchical Multi-Agent Planning and Intent-Guided Editing , author=. arXiv preprint arXiv:2604.04875 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
A Benchmark and Multi-Agent System for Instruction-driven Cinematic Video Compilation
A Benchmark and Multi-Agent System for Instruction-driven Cinematic Video Compilation , author=. arXiv preprint arXiv:2604.10456 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.