Do VLMs See What Sensors Feel? A Scalable Expert-Guided Design for Wheelchair Accessibility Assessment from Street View
Pith reviewed 2026-06-28 14:40 UTC · model grok-4.3
The pith
Vision-language models partially align with real wheelchair mobility data when assessing street view accessibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
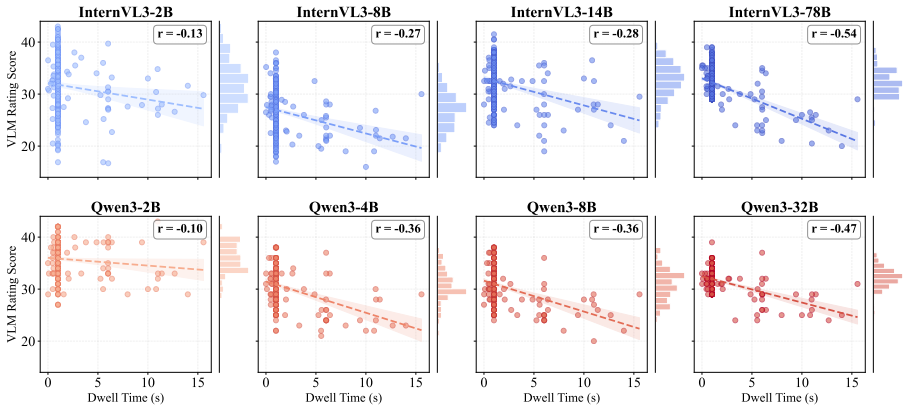
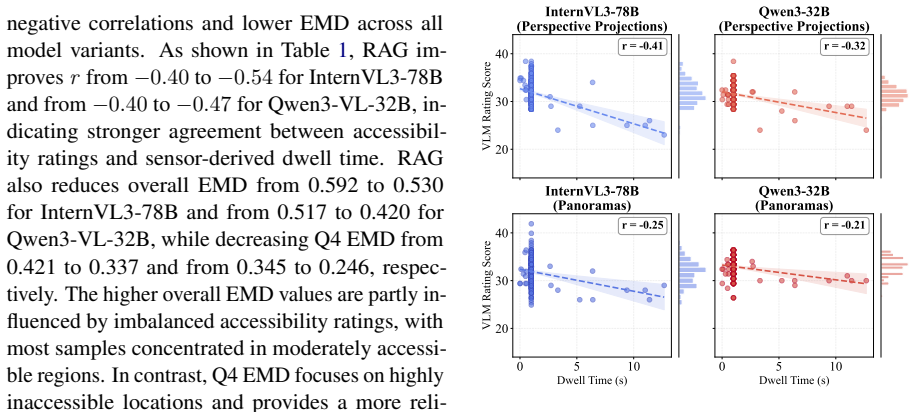
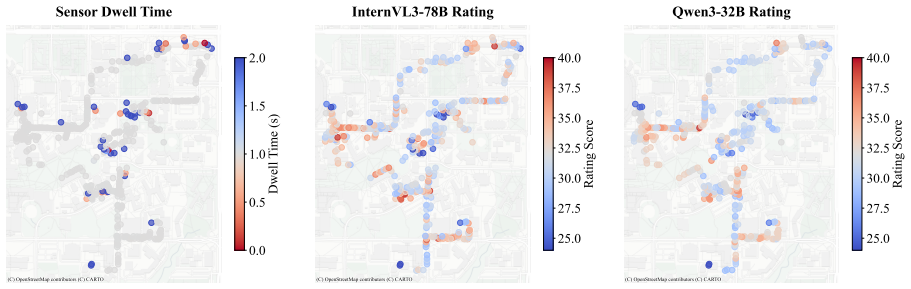
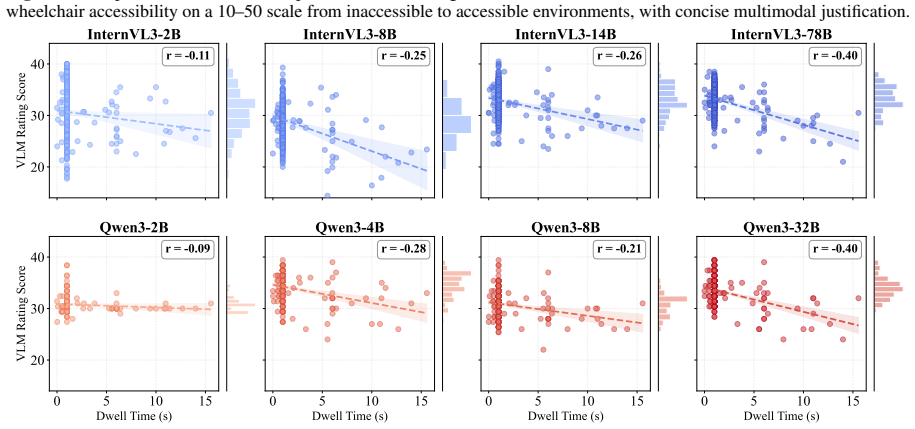
The paper claims that VLM ratings produced by an expert-guided retrieval-augmented framework are both negatively correlated and distributionally similar with dwell time from 407 GSV locations, indicating partial but consistent alignment with a behavioral proxy for mobility friction.
What carries the argument
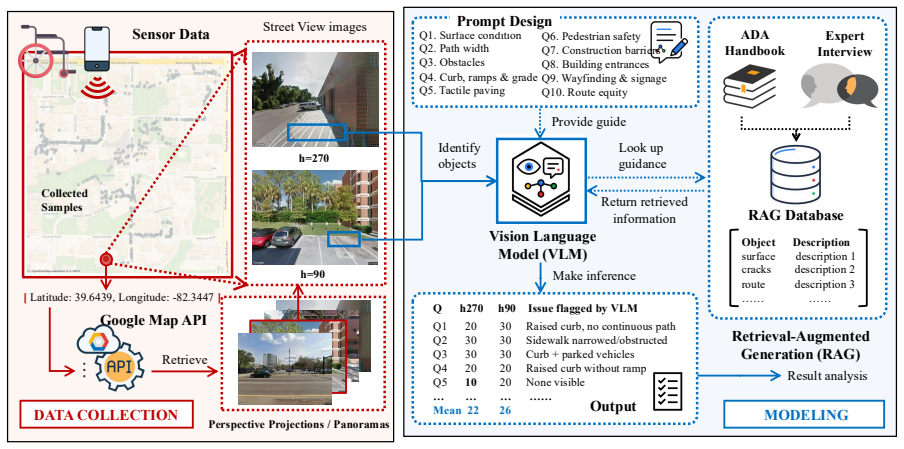
Expert-guided retrieval-augmented framework that combines GSV images, ADA-informed guidance, and expert-derived rubrics to evaluate accessibility dimensions.
If this is right
- VLM ratings can indicate locations with higher mobility friction based on visual cues.
- Objects like curb ramps and crosswalks are linked to higher accessibility scores.
- Alignment is limited for subtle surface conditions and transient obstructions.
- The framework enables scalable assessment without on-site visits for every location.
Where Pith is reading between the lines
- If the method scales, planners could use existing street view data to prioritize accessibility improvements across cities.
- Extending the framework to other sensor types or mobility modes could address a wider range of navigation challenges.
- Testing the correlation in different environments would check if the partial alignment is general.
- Models may need updates to better handle dynamic barriers not visible in static images.
Load-bearing premise
The GPS-derived wheelchair dwell behavior at the 407 locations serves as a reliable and unbiased proxy for mobility friction caused by accessibility barriers.
What would settle it
Finding no negative correlation between VLM scores and actual wheelchair navigation difficulty measured independently at the same locations would falsify the alignment.
Figures



read the original abstract
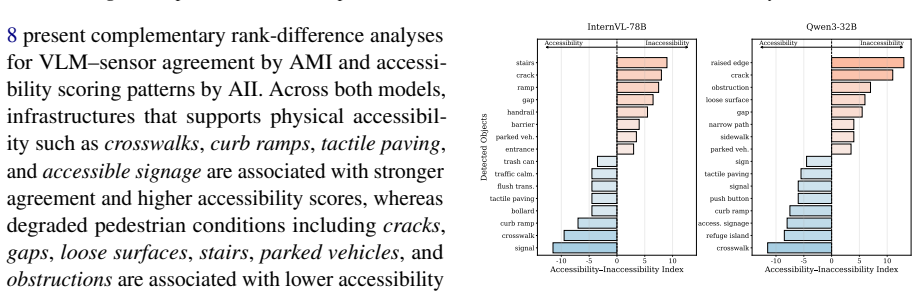
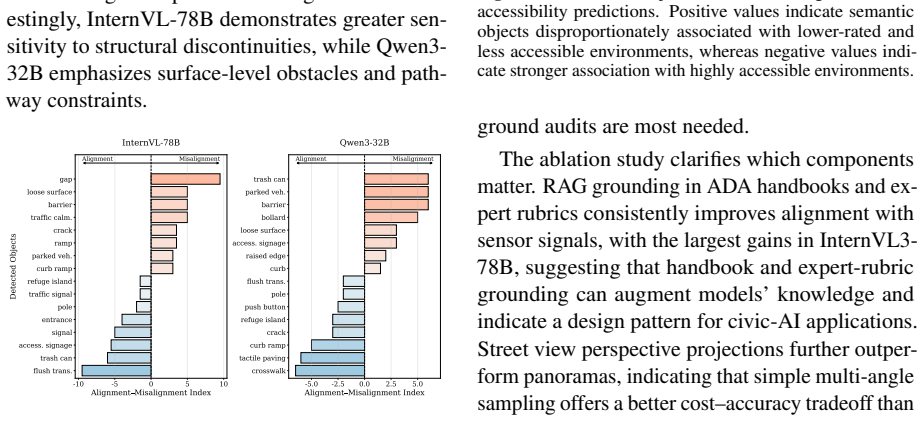
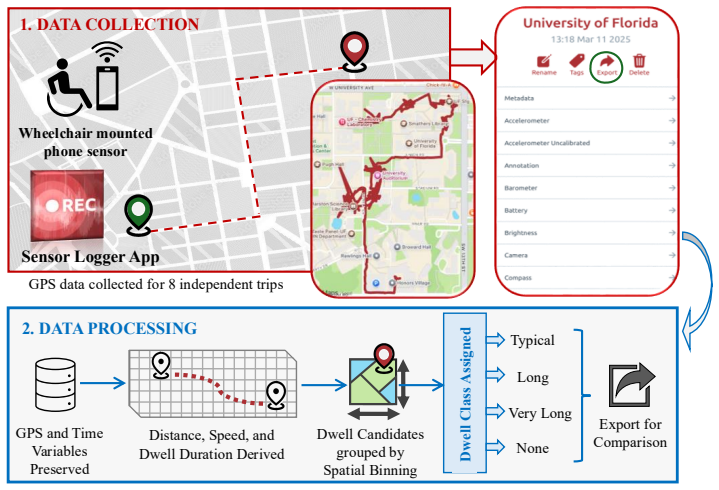
Assessing built-environment interaction, such as wheelchair accessibility, is difficult because real-world mobility is shaped by distributed, context-dependent, and temporary barriers that are hard to capture at scale. To support scalable assessment, this paper examines whether vision-language models (VLMs) can identify accessibility barriers from Google Street View (GSV) imagery. We propose an expert-guided retrieval-augmented framework that combines GSV images, ADA-informed guidance, and expert-derived rubrics to evaluate accessibility dimensions. We collect a campus-scale dataset at the University of Florida, linking 407 unique GSV locations with GPS-derived wheelchair dwell behavior as a mobility-friction signal. Results show that VLM ratings are both negatively correlated and distributionally similar with dwell time, indicating partial but consistent alignment with a behavioral proxy for mobility friction. Visual cue analysis shows that certain environmental objects, such as curb ramps and crosswalks, are associated with higher VLM accessibility scores, while alignment remains limited for subtle surface conditions, transient obstructions, and viewpoint-dependent barriers. Overall, our findings show the potential of expert-guided VLMs for scalable accessibility assessment aligning with sensor-derived indicators of real-world wheelchair navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an expert-guided retrieval-augmented framework that uses vision-language models (VLMs) to evaluate wheelchair accessibility dimensions from Google Street View (GSV) imagery, informed by ADA guidance and expert rubrics. It introduces a dataset of 407 unique GSV locations on a university campus linked to GPS-derived wheelchair dwell times as a behavioral proxy for mobility friction. The central empirical claim is that VLM accessibility ratings exhibit negative correlation and distributional similarity with these dwell times, indicating partial alignment with real-world navigation difficulty; additional analysis links higher VLM scores to visual cues such as curb ramps and crosswalks while noting limitations for subtle or transient barriers.
Significance. If the correlation holds after addressing proxy validity, the work could support scalable, imagery-based accessibility assessment that aligns with sensor-derived mobility signals, with the linked GSV-GPS dataset serving as a reproducible resource for future studies in computer vision and urban accessibility. The expert-guided design is a constructive step toward incorporating domain knowledge into VLM evaluation.
major comments (2)
- [Abstract / Results] Abstract and Results section: The claim that 'VLM ratings are both negatively correlated and distributionally similar with dwell time' is presented without any reported correlation coefficient, p-value, sample statistics, controls for confounding factors, or details on dwell-time processing, which is load-bearing for the central claim of alignment with a behavioral proxy for mobility friction.
- [Data Collection / Empirical Evaluation] Data Collection and Empirical Evaluation sections: The use of GPS-derived wheelchair dwell behavior at the 407 locations as a reliable proxy for mobility friction caused by accessibility barriers is invoked to link VLM scores to real-world navigation difficulty but receives no validation against ground-truth barriers or adjustment for potential confounders (route choice, user-specific pauses, location popularity, temporary events, or GPS artifacts).
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., the observed correlation value) rather than a purely qualitative description of the findings.
- [Proposed Framework] Notation for the accessibility dimensions and rubrics could be made more explicit when first introduced to aid reproducibility of the expert-guided component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Where the manuscript is missing explicit statistics or discussion, we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results section: The claim that 'VLM ratings are both negatively correlated and distributionally similar with dwell time' is presented without any reported correlation coefficient, p-value, sample statistics, controls for confounding factors, or details on dwell-time processing, which is load-bearing for the central claim of alignment with a behavioral proxy for mobility friction.
Authors: We agree that the specific quantitative details are not reported in the abstract or results. The manuscript states the existence of negative correlation and distributional similarity but omits the coefficient, p-value, n=407, processing steps, and any controls. In the revision we will add these values (computed from the existing dataset), processing description, and a brief note on confounders considered. revision: yes
-
Referee: [Data Collection / Empirical Evaluation] Data Collection and Empirical Evaluation sections: The use of GPS-derived wheelchair dwell behavior at the 407 locations as a reliable proxy for mobility friction caused by accessibility barriers is invoked to link VLM scores to real-world navigation difficulty but receives no validation against ground-truth barriers or adjustment for potential confounders (route choice, user-specific pauses, location popularity, temporary events, or GPS artifacts).
Authors: We acknowledge that the proxy is not validated against direct ground-truth barrier annotations and that potential confounders are not explicitly adjusted for in the current analysis. This stems from the practical difficulty of obtaining exhaustive ground-truth labels at campus scale. In the revision we will expand the limitations section to discuss these issues, provide additional dwell-time processing details, and note possible confounders, while retaining the proxy as a behavioral signal rather than claiming direct validation. revision: partial
Circularity Check
No circularity: empirical correlation with external GPS data
full rationale
The paper reports negative correlation and distributional similarity between VLM accessibility ratings and GPS-derived wheelchair dwell times at 407 GSV locations. This is a direct empirical comparison against an external behavioral signal with no equations, parameter fitting, predictions by construction, or self-citation chains that reduce the result to its inputs. The derivation chain consists of data collection followed by statistical comparison, which is self-contained and falsifiable against the sensor data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wheelchair dwell time derived from GPS serves as a valid proxy for mobility friction due to built-environment barriers
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.18572 , year=
Georeasoner: Geo-localization with reasoning in street views using a large vision-language model , author=. arXiv preprint arXiv:2406.18572 , year=
-
[2]
2006 , month = jul, url =
Lesson 20: Traffic Calming , institution =. 2006 , month = jul, url =
2006
-
[3]
ACM Transactions on Human-Robot Interaction (THRI) , volume=
Usability studies of an egocentric vision-based robotic wheelchair , author=. ACM Transactions on Human-Robot Interaction (THRI) , volume=. 2020 , publisher=
2020
-
[4]
Campus as a Living Lab: Discovering the Comfort of Wheelchair Users in the Pedestrian Network by Experiential Learning with High School Students , author=
-
[5]
PloS one , volume=
An inertial sensor-based comprehensive analysis of manual wheelchair user mobility during daily life in people with SCI , author=. PloS one , volume=. 2025 , publisher=
2025
-
[6]
Sensors , volume=
Assistive grasping based on laser-point detection with application to wheelchair-mounted robotic arms , author=. Sensors , volume=. 2019 , publisher=
2019
-
[7]
Disability and Rehabilitation: Assistive Technology , volume=
Wheelchair-mounted accelerometers for measurement of physical activity , author=. Disability and Rehabilitation: Assistive Technology , volume=. 2012 , publisher=
2012
-
[8]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
CityVLM: Towards sustainable urban development via multi-view coordinated vision--language model , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2026 , publisher=
2026
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Velma: Verbalization embodiment of llm agents for vision and language navigation in street view , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
How Well Do Vision-Language Models Understand Cities? A Comparative Study on Spatial Reasoning from Street-View Images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
Cities , volume=
Urban safety perception assessments via integrating multimodal large language models with street view images , author=. Cities , volume=. 2025 , publisher=
2025
-
[12]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Cross-view image geolocalization , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Wide-area image geolocalization with aerial reference imagery , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[14]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Learned contextual feature reweighting for image geo-localization , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
IEEE transactions on pattern analysis and machine intelligence , volume=
Image geo-localization based on multiplenearest neighbor feature matching usinggeneralized graphs , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2014 , publisher=
2014
-
[16]
Proceedings of the 5th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery , pages=
Im2city: image geo-localization via multi-modal learning , author=. Proceedings of the 5th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery , pages=
-
[17]
ACM Computing Surveys , volume=
Unravelling Digital Forgeries: A Systematic Survey on Image Manipulation Detection and Localization , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[18]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
Cross-view geolocalization and disaster mapping with street-view and VHR satellite imagery: A case study of Hurricane IAN , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2025 , publisher=
2025
-
[19]
European Conference on Computer Vision , pages=
You are here: Geolocation by embedding maps and images , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[20]
International Journal of Applied Earth Observation and Geoinformation , volume=
LLM-enhanced disaster geolocalization using implicit geoinformation from multimodal data: A case study of Hurricane Harvey , author=. International Journal of Applied Earth Observation and Geoinformation , volume=. 2025 , publisher=
2025
-
[21]
Multimodal location estimation of videos and images , pages=
Large-scale image geolocalization , author=. Multimodal location estimation of videos and images , pages=. 2014 , publisher=
2014
-
[22]
Pattern Analysis and Applications , volume=
State-of-the-art in visual geo-localization , author=. Pattern Analysis and Applications , volume=. 2017 , publisher=
2017
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lisa: Reasoning segmentation via large language model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
arXiv preprint arXiv:2403.01777 , year=
Nphardeval4v: A dynamic reasoning benchmark of multimodal large language models , author=. arXiv preprint arXiv:2403.01777 , year=
-
[25]
arXiv preprint arXiv:2406.02787 , year=
Disentangling logic: The role of context in large language model reasoning capabilities , author=. arXiv preprint arXiv:2406.02787 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Mind's eye of LLMs: visualization-of-thought elicits spatial reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Thinking in space: How multimodal large language models see, remember, and recall spaces , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[29]
arXiv preprint arXiv:2506.14674 , year=
Recognition through Reasoning: Reinforcing Image Geo-localization with Large Vision-Language Models , author=. arXiv preprint arXiv:2506.14674 , year=
-
[30]
arXiv preprint arXiv:2506.06355 , year=
LLMs as World Models: Data-Driven and Human-Centered Pre-Event Simulation for Disaster Impact Assessment , author=. arXiv preprint arXiv:2506.06355 , year=
-
[31]
Proceedings of the 47th international acm sigir conference on research and development in information retrieval , pages=
Img2Loc: Revisiting image geolocalization using multi-modality foundation models and image-based retrieval-augmented generation , author=. Proceedings of the 47th international acm sigir conference on research and development in information retrieval , pages=
-
[32]
European Conference on Computer Vision , pages=
Addressclip: Empowering vision-language models for city-wide image address localization , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[33]
arXiv preprint arXiv:2405.20363 , year=
Llmgeo: Benchmarking large language models on image geolocation in-the-wild , author=. arXiv preprint arXiv:2405.20363 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Geo-bench: Toward foundation models for earth monitoring , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
European Conference on Computer Vision , pages=
Where in the world is this image? transformer-based geo-localization in the wild , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Transgeo: Transformer is all you need for cross-view image geo-localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
arXiv preprint arXiv:2506.01277 , year=
Geolocsft: Efficient visual geolocation via supervised fine-tuning of multimodal foundation models , author=. arXiv preprint arXiv:2506.01277 , year=
-
[38]
European conference on computer vision , pages=
V-irl: Grounding virtual intelligence in real life , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[39]
From pixels to places: A systematic benchmark for evaluating image geolocalization ability in large language models , author=. arXiv preprint arXiv:2508.01608 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
npj Urban Sustainability , year=
Multimodal large language models, street view images and urban policy-intelligence: recovering the sustainability effects of redlining , author=. npj Urban Sustainability , year=
-
[41]
arXiv preprint arXiv:2506.02242 , year=
From street views to urban science: Discovering road safety factors with multimodal large language models , author=. arXiv preprint arXiv:2506.02242 , year=
-
[42]
Nature Computational Science , volume=
Advancing real-time infectious disease forecasting using large language models , author=. Nature Computational Science , volume=. 2025 , publisher=
2025
-
[43]
International Conference on Computational Science and Its Applications , pages=
Enhancing urban walkability assessment with multimodal Large Language models , author=. International Conference on Computational Science and Its Applications , pages=. 2024 , organization=
2024
-
[44]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
UrbanLLaVA: A Multi-modal Large Language Model for Urban Intelligence , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[45]
2008 IEEE Conference on Computer Vision and Pattern Recognition , pages=
IM2GPS: estimating geographic information from a single image , author=. 2008 IEEE Conference on Computer Vision and Pattern Recognition , pages=. 2008 , organization=
2008
-
[46]
European Conference on Computer Vision (ECCV) , pages=
PlaNet - Photo Geolocation with Convolutional Neural Networks , author=. European Conference on Computer Vision (ECCV) , pages=. 2016 , publisher=
2016
-
[47]
Proceedings of the IEEE international conference on computer vision , pages=
Revisiting im2gps in the deep learning era , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[48]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
From images to textual prompts: Zero-shot visual question answering with frozen large language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[49]
ACM Computing Surveys , volume=
Natural language understanding and inference with mllm in visual question answering: A survey , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[50]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Enhancing visual document understanding with contrastive learning in large visual-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[51]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
mplug-paperowl: Scientific diagram analysis with the multimodal large language model , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[52]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
NetVLAD: CNN architecture for weakly supervised place recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vigor: Cross-view image geo-localization beyond one-to-one retrieval , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[54]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[55]
International conference on machine learning , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[56]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[57]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
On the dangers of stochastic parrots: Can language models be too big?�� , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
2021
-
[58]
arXiv preprint arXiv:2502.14412 , year=
Evaluating precise geolocation inference capabilities of vision language models , author=. arXiv preprint arXiv:2502.14412 , year=
-
[59]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[60]
arXiv preprint arXiv:2504.03164 , year=
Nuscenes-spatialqa: A spatial understanding and reasoning benchmark for vision-language models in autonomous driving , author=. arXiv preprint arXiv:2504.03164 , year=
-
[61]
Proceedings of the European conference on computer vision (ECCV) , pages=
Geolocation estimation of photos using a hierarchical model and scene classification , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Where we are and what we're looking at: Query based worldwide image geo-localization using hierarchies and scenes , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[63]
arXiv preprint arXiv:2507.10473 , year=
GT-Loc: Unifying When and Where in Images Through a Joint Embedding Space , author=. arXiv preprint arXiv:2507.10473 , year=
-
[64]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
Global Streetscapes—A comprehensive dataset of 10 million street-level images across 688 cities for urban science and analytics , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2024 , publisher=
2024
-
[65]
European Conference on Computer Vision , pages=
Mapillary planet-scale depth dataset , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[66]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Personalized showcases: Generating multi-modal explanations for recommendations , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[67]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Cross-view image matching for geo-localization in urban environments , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[68]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[69]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[70]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[72]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[74]
Advances in Neural Information Processing Systems , volume=
Human-aware vision-and-language navigation: Bridging simulation to reality with dynamic human interactions , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Navgpt: Explicit reasoning in vision-and-language navigation with large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[76]
interactions , volume=
Grand challenges in accessible maps , author=. interactions , volume=. 2019 , publisher=
2019
-
[77]
2014 , note =
ADA Checklist for Existing Facilities , author =. 2014 , note =
2014
-
[78]
Transportation Research Record , volume =
A Semi-Automated Method to Generate GIS-Based Sidewalk Networks for Asset Management and Pedestrian Accessibility Assessment , author =. Transportation Research Record , volume =. 2018 , publisher =
2018
-
[79]
Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility , pages =
AccessMap Website Demonstration: Individualized, Accessible Pedestrian Trip Planning at Scale , author =. Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility , pages =. 2019 , publisher =
2019
-
[80]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =
Combining Crowdsourcing and Google Street View to Identify Street-level Accessibility Problems , author =. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =. 2013 , publisher =
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.