What Makes Video World Model Latents Action-Relevant: Prediction over Reconstruction
Pith reviewed 2026-06-27 22:36 UTC · model grok-4.3
The pith
Temporal video pretraining induces action-relevant structure in video world model latents rather than pixel reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
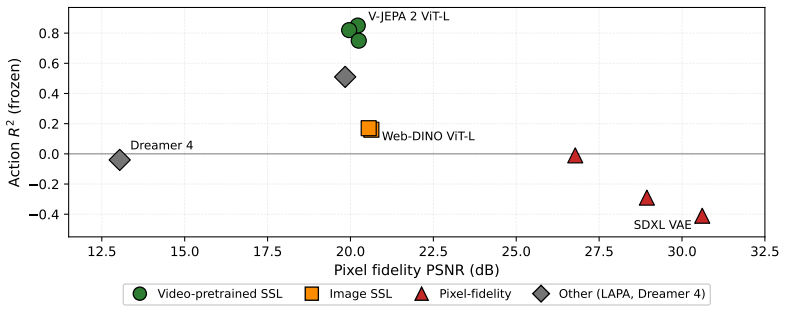
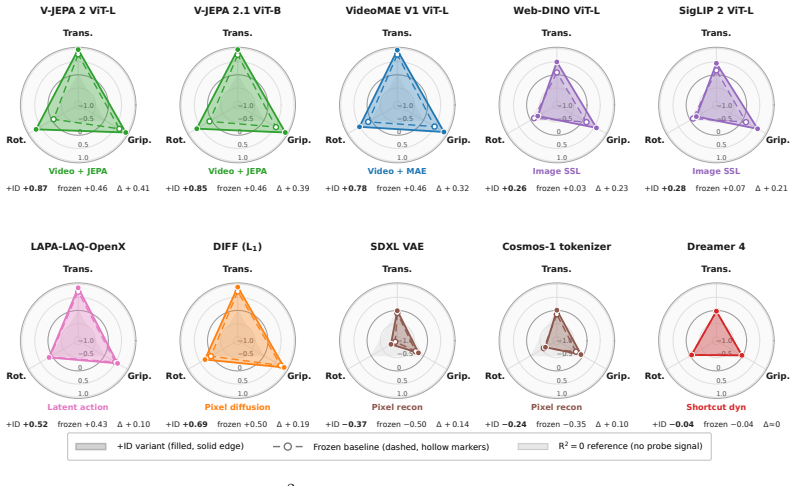
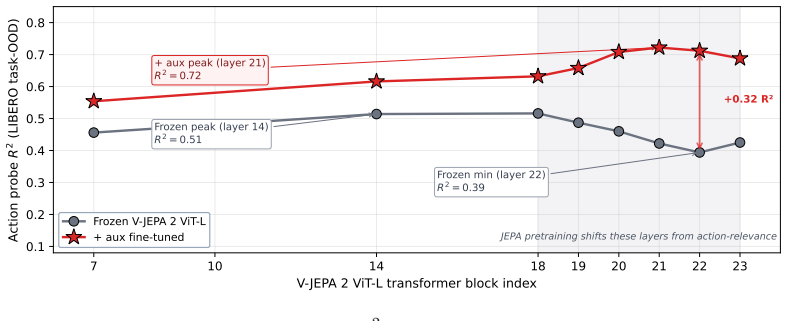
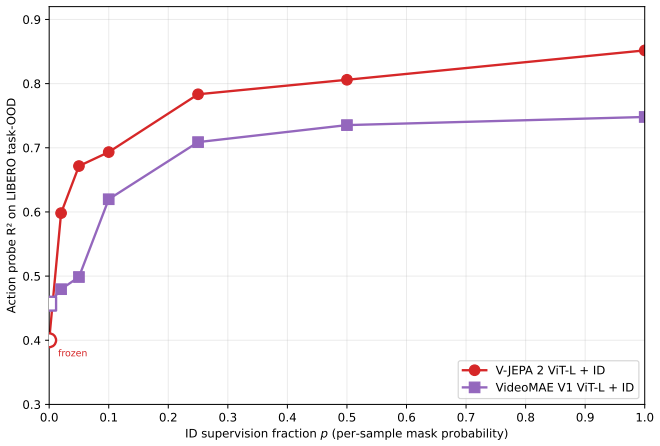
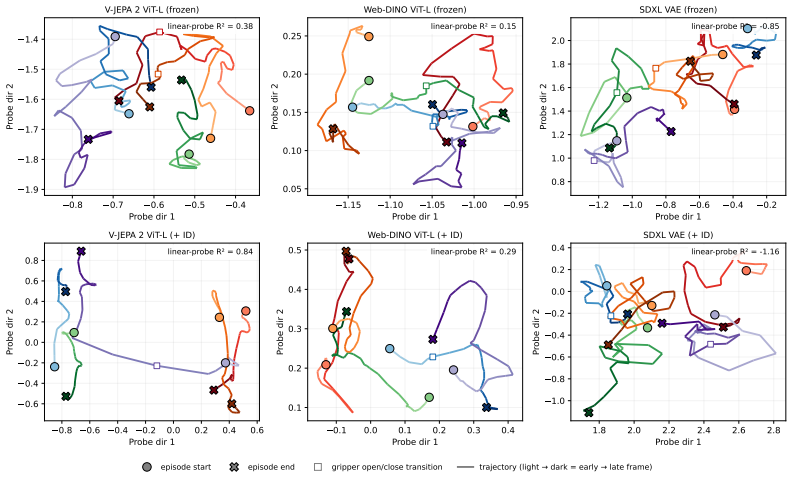
The authors establish that action-relevant structure is driven primarily by temporal video pretraining rather than pixel reconstruction fidelity: models with strong pixel decoding quality can exhibit near-zero action recoverability, while video-pretrained self-supervised encoders consistently achieve the best Pareto trade-off between visual fidelity and action prediction. Comparing V-JEPA and VideoMAE further shows that most gains arise from natural-video temporal context, with feature-level latent prediction providing a smaller additional benefit. These trends transfer across robotic benchmarks, though static-environment tasks can partially mask the importance of temporal structure.
What carries the argument
Unified probe-based evaluation across encoder families using a shared inverse-dynamics probing objective to measure action recoverability from latents.
If this is right
- Video-pretrained self-supervised encoders achieve the best Pareto trade-off between visual fidelity and action prediction.
- Natural-video temporal context accounts for most gains, with feature-level latent prediction adding a smaller benefit.
- Trends transfer across robotic benchmarks, though static-environment tasks can mask the role of temporal structure.
- Inverse-dynamics supervision improves robustness to visual corruption beyond clean-setting performance.
Where Pith is reading between the lines
- Designers of video world models may gain by prioritizing temporal prediction objectives over pure reconstruction during pretraining.
- Testing on more dynamic robotic tasks could make the contribution of temporal structure more visible.
- The same probing logic could be applied to identify relevant structure in other modalities or prediction settings.
Load-bearing premise
That a single inverse-dynamics probing objective provides an unbiased and sufficient measure of action-relevance that fairly compares models from different pretraining families without being confounded by architecture, data scale, or task-specific factors.
What would settle it
A reconstruction-based model achieving action recoverability comparable to video-pretrained models, or a video-pretrained model showing near-zero recoverability, would undermine the claim that temporal pretraining is the primary driver.
Figures
read the original abstract
Video world models are increasingly used to provide predictive visual representations, yet it remains unclear which pretraining signals induce action-relevant structure in their latent spaces. We study this question through a unified probe-based evaluation across diverse encoder families, including image-only self-supervision, video pretraining with and without latent prediction, reconstruction-based autoencoders, diffusion models, and shortcut-forcing dynamics models. Using a common inverse-dynamics probing objective, we find that action-relevant structure is driven primarily by temporal video pretraining rather than pixel reconstruction fidelity: models with strong pixel decoding quality can exhibit near-zero action recoverability, while video-pretrained self-supervised encoders consistently achieve the best Pareto trade-off between visual fidelity and action prediction. Comparing V-JEPA and VideoMAE further shows that most gains arise from natural-video temporal context, with feature-level latent prediction providing a smaller additional benefit. These trends transfer across robotic benchmarks, though CALVIN reveals that static-environment tasks can partially mask the importance of temporal structure by allowing strong image priors to suffice. Finally, inverse-dynamics supervision substantially improves robustness to visual corruption, suggesting that action-aware objectives regularize latent geometry beyond clean-setting performance. Our results identify temporal predictive structure -- not reconstruction fidelity -- as the primary ingredient underlying action-relevant video representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates action-relevance of latents from diverse video encoders (image SSL, video SSL, autoencoders, diffusion, dynamics models) via a shared inverse-dynamics probe. It claims temporal video pretraining—not pixel reconstruction fidelity—drives action-relevant structure, with video-pretrained SSL models achieving the best fidelity-action Pareto front; V-JEPA vs. VideoMAE isolates natural-video context as the main driver, with trends transferring to robotic benchmarks (except CALVIN where static priors suffice) and inverse-dynamics supervision improving corruption robustness.
Significance. If the empirical trends hold after controls, the work supplies actionable guidance on pretraining objectives for action-aware video world models, highlighting temporal prediction over reconstruction. The unified cross-family probe design and benchmark transfer results are strengths that could inform robotics and representation learning.
major comments (2)
- [Evaluation Protocol] Evaluation Protocol (implied in abstract and § on probing): The central claim that temporal pretraining is the dominant driver rests on direct comparisons via one fixed inverse-dynamics probe. Different families produce latents with incompatible statistics (dimensionality, normalization, sparsity, temporal alignment); without reported probe-capacity ablations, per-family hyperparameter sweeps, or controls holding architecture/data scale fixed while varying only pretraining signal, the probe may extract action information more readily from some geometries than others, confounding the conclusion.
- [Results on CALVIN] Results on CALVIN (abstract): The paper notes that static-environment tasks can mask temporal structure importance via strong image priors, yet provides no quantitative breakdown of how much the reported Pareto advantage shrinks under this regime or whether the probe still isolates the temporal contribution.
minor comments (1)
- [Abstract] Abstract and methods lack explicit mention of statistical significance tests or variance across random seeds for the reported trends.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for noting the strengths of the unified cross-family probe and benchmark transfer experiments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Evaluation Protocol] Evaluation Protocol (implied in abstract and § on probing): The central claim that temporal pretraining is the dominant driver rests on direct comparisons via one fixed inverse-dynamics probe. Different families produce latents with incompatible statistics (dimensionality, normalization, sparsity, temporal alignment); without reported probe-capacity ablations, per-family hyperparameter sweeps, or controls holding architecture/data scale fixed while varying only pretraining signal, the probe may extract action information more readily from some geometries than others, confounding the conclusion.
Authors: We agree that differing latent statistics across encoder families could in principle bias probe performance. Our protocol applies an identical probe architecture and training recipe to every encoder, with per-encoder hyperparameter selection performed on a held-out validation split. The V-JEPA versus VideoMAE comparison already holds architecture, dataset scale, and most pretraining details fixed while isolating the effect of natural-video temporal context and latent prediction, directly addressing the request for a controlled contrast. In the revision we will add an explicit probe-capacity ablation (varying hidden-layer width and depth) across representative models to quantify sensitivity to probe expressivity. We view these elements as sufficient to support the central claim while remaining computationally tractable. revision: partial
-
Referee: [Results on CALVIN] Results on CALVIN (abstract): The paper notes that static-environment tasks can mask temporal structure importance via strong image priors, yet provides no quantitative breakdown of how much the reported Pareto advantage shrinks under this regime or whether the probe still isolates the temporal contribution.
Authors: We concur that a quantitative breakdown would make the masking effect clearer. The revised manuscript will include a supplementary table reporting the absolute and relative action-prediction gaps (video-pretrained vs. reconstruction baselines) on CALVIN versus the other robotic benchmarks. We will also add a controlled single-frame ablation on CALVIN to measure how much performance is retained when temporal information is removed, thereby quantifying the contribution of static priors. The current text already flags the limitation; the added numbers will make its magnitude explicit. revision: yes
Circularity Check
No circularity: empirical probe comparisons are independent of inputs
full rationale
The paper reports results from applying a fixed inverse-dynamics probe to latents from multiple independently pretrained encoder families (image SSL, video SSL, autoencoders, diffusion, dynamics models). No equations, derivations, or self-citations are used to define or force the central claim; the claim follows directly from the observed probe accuracies and Pareto fronts across models. No fitted parameters are relabeled as predictions, no uniqueness theorems are imported, and no ansatz is smuggled via citation. The evaluation is self-contained against external benchmarks (robotic tasks) without reducing to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Inverse-dynamics probing accurately measures action-relevance of latent representations
- domain assumption The selected encoder families and robotic benchmarks allow fair comparison of pretraining signals
Reference graph
Works this paper leans on
-
[1]
M. Assran et al. V-jepa 2: Self-supervised video models enable understanding, prediction, and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[2]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[3]
M. J. Kim et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL), 2024
2024
-
[4]
S. Tian, C. Finn, and J. Wu. A control-centric benchmark for video prediction. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
Nilaksh, S. Jha, A. Zholus, and S. Chandar. Reconstruction or semantics? what makes a latent space useful for robotic world models.arXiv preprint arXiv:2605.06388, 2026
Pith/arXiv arXiv 2026
-
[6]
K. Yi, C. Gan, Y . Li, P. Kohli, J. Wu, A. Torralba, and J. B. Tenenbaum. CLEVRER: CoLli- sion events for video representation and reasoning. InInternational Conference on Learning Representations (ICLR), 2020
2020
- [7]
-
[8]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
2023
-
[9]
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Pith/arXiv arXiv 2023
-
[10]
Micheli, E
V . Micheli, E. Alonso, and F. Fleuret. Transformers are sample-efficient world models. In International Conference on Learning Representations (ICLR), 2023
2023
- [11]
-
[12]
D. Li, Y . Fang, et al. Worldmodelbench: Judging video generation models as world models. InNeurIPS Datasets and Benchmarks, 2025
2025
-
[13]
H. Yue, S. Huang, et al. Ewmbench: Evaluating scene, motion, and semantic quality in em- bodied world models.arXiv preprint arXiv:2505.09694, 2025
arXiv 2025
-
[14]
Y . Shang et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
arXiv 2026
-
[15]
J. Zhang et al. World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135, 2025
arXiv 2025
- [16]
-
[17]
Agrawal, A
P. Agrawal, A. V . Nair, P. Abbeel, J. Malik, and S. Levine. Learning to poke by poking: Expe- riential learning of intuitive physics. InAdvances in Neural Information Processing Systems (NeurIPS), 2016
2016
-
[18]
Pathak, P
D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell. Curiosity-driven exploration by self- supervised prediction. InInternational Conference on Machine Learning (ICML), 2017. 9
2017
-
[19]
Shelhamer, P
E. Shelhamer, P. Mahmoudieh, M. Argus, and T. Darrell. Loss is its own reward: Self- supervision for reinforcement learning. InICLR Workshop, 2017
2017
-
[20]
Z. J. Cui, H. Pan, A. Iyer, S. Haldar, and L. Pinto. Dynamo: In-domain dynamics pretraining for visuo-motor control. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[21]
X. Zhou et al. LIBERO-PRO: Towards robust and fair evaluation of vision-language-action models beyond memorization.arXiv preprint arXiv:2510.03827, 2025
Pith/arXiv arXiv 2025
-
[22]
R. Riochet, M. Y . Castro, M. Bernard, A. Lerer, R. Fergus, V . Izard, and E. Dupoux. Intphys: A framework and benchmark for visual intuitive physics reasoning, 2020. URLhttps:// arxiv.org/abs/1803.07616
arXiv 2020
-
[23]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 2022
2022
-
[24]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on Robot Learning (CoRL), 2020
2020
-
[25]
D. Hafner, W. Yan, and T. Lillicrap. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025
Pith/arXiv arXiv 2025
-
[26]
Podell, Z
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rom- bach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InInter- national Conference on Learning Representations (ICLR), 2024
2024
-
[27]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[28]
Ye et al
S. Ye et al. Latent action pretraining from videos. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[29]
D. Fan, S. Tong, J. Zhu, K. Sinha, Z. Liu, X. Chen, M. Rabbat, N. Ballas, Y . LeCun, and A. Bar. Scaling language-free visual representation learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[30]
M. Tschannen et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[31]
Z. Tong, Y . Song, J. Wang, and L. Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[32]
Y . LeCun. A path towards autonomous machine intelligence.OpenReview, 2022. URLhttps: //openreview.net/forum?id=BZ5a1r-kVsf
2022
-
[33]
Brohan et al
A. Brohan et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023
2023
-
[34]
K. Black et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 10 A Inverse-Dynamics Loss Ablations on DIFF All cross-architecture rows in the main text use the same inverse-dynamics recipe: a single inverse- dynamics headg ϕ(fθ(ot), fθ(ot+1))→ˆa t trained withL 2 MSE atλ=0.05. This appendix report...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.