FunctionEvolve: Structure-Guided Symbolic Regression with LLMs
Pith reviewed 2026-06-27 22:47 UTC · model grok-4.3
The pith
Expression trees guide LLMs to recover exact symbolic expressions from data at rates several times higher than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
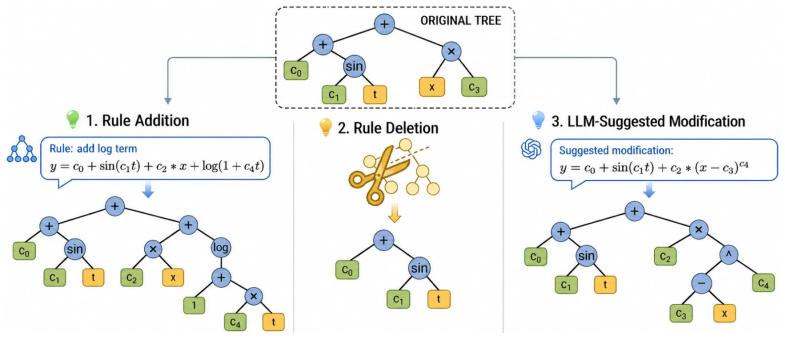
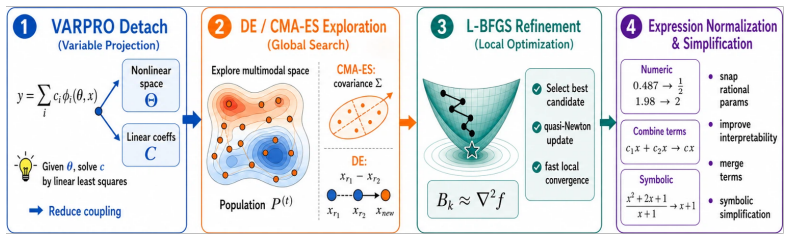
FunctionEvolve organizes the whole search process using expression trees: structural summaries promote diverse parent selection, local tree edits let the LLM propose refinements while preserving useful subexpressions, and structure-aware fitting decomposes, constrains, and simplifies coefficients for more reliable scoring. Using only elementary function families, the approach recovers exact symbolic forms on 107 of 129 synthetic tasks from LLM-SRBench when paired with Claude Opus 4.6, reaching 82.9 percent success at 50 attempts and 55.8 percent at top-1. The paper states that structure-visible search is central to reliable recovery, with LLM-guided refinements and structure-aware optimizati
What carries the argument
Expression trees that organize evolutionary search through structural summaries for selection, local edits for mutation, and decomposed coefficient fitting for scoring.
If this is right
- Structure-visible search becomes central to reliable exact recovery of symbolic forms.
- LLM-guided refinements and structure-aware coefficient optimization function as the essential proposal and scoring mechanisms.
- High exact recovery is possible using only elementary function families without additional domain-specific rules.
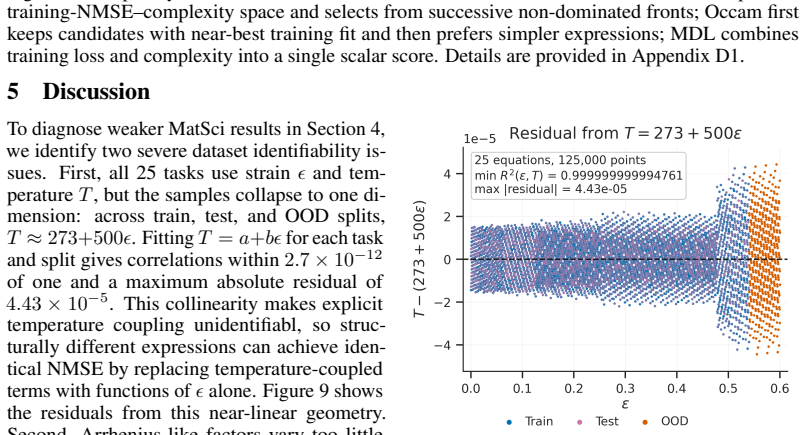
- Collinearity in benchmark subsets creates identifiability problems that affect measured performance.
Where Pith is reading between the lines
- The documented gains from explicit tree structure imply that similar structural representations could improve reliability in other LLM-guided search tasks outside symbolic regression.
- The benchmark audit for collinearity indicates that identifiability problems may affect many existing symbolic regression evaluations and will need attention when designing future test sets.
- Local edits that preserve subexpressions could reduce effective search space size when the same idea is applied in other evolutionary or LLM-driven optimization settings.
Load-bearing premise
Local tree edits proposed by the LLM together with structure-aware fitting produce reliable rankings that do not systematically undervalue correct skeletons or favor overfit expressions after decomposition and simplification.
What would settle it
A controlled test on a known-correct skeleton that the method proposes but then ranks below incorrect alternatives due to fitting artifacts, or repeated failure to recover exact forms on a synthetic set free of the reported collinearity issues.
Figures




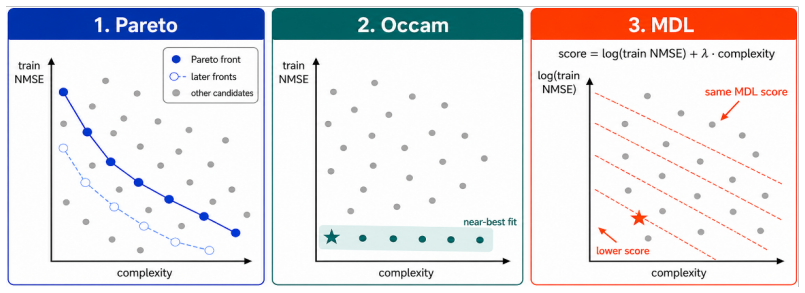
read the original abstract
Symbolic regression aims to uncover explicit scientific laws from data. Recent methods use LLMs to guide mutation from background text, which is more directed than random genetic programming. However, exact symbolic recovery requires both semantic guidance and explicit structure, so that domain-informed search are carried out through valid symbolic representation. Current LLM-driven systems remain structure-blind: they select among opaque candidates, lack explicit mechanisms for local mutation, and rely on brittle coefficient fitting that can undervalue correct skeletons. We propose FunctionEvolve, an evolutionary framework using expression trees to organize the whole search: structural summaries promote diverse parent selection, local tree edits preserve useful subexpressions, and structure-aware fitting decomposes, constrains, and simplifies coefficients for more reliable scoring. It uses only elementary function families, without additional domain-specific rules limiting generalization. On the 129-task synthetic subset of LLM-SRBench, FunctionEvolve with \emph{Claude Opus 4.6} recovers 107 exact forms, reaching 82.9% SA@50, 4.5x above same-backbone baselines, and 55.8% SA@1, 3.6x above the strongest previously published top-1 result. Ablations show that structure-visible search is central to reliable recovery, with LLM-guided refinements and structure-aware coefficient optimization serving as essential proposal and scoring mechanisms. We also audit the benchmark and show that collinearity in its materials-science subset creates identifiability issues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FunctionEvolve, an evolutionary framework for symbolic regression that organizes search around expression trees. It uses structural summaries for diverse parent selection, LLM-proposed local tree edits to preserve subexpressions, and structure-aware fitting (decomposition, coefficient constraints, and simplification) for scoring. Evaluated on the 129-task synthetic subset of LLM-SRBench, FunctionEvolve with Claude Opus 4.6 recovers 107 exact forms (82.9% SA@50, 4.5x same-backbone baselines; 55.8% SA@1, 3.6x prior top-1 result). Ablations highlight the role of structure-visible search, and the paper audits the benchmark for collinearity-induced identifiability issues in its materials-science subset.
Significance. If the performance claims hold after addressing the fitting procedure, the work would be significant for LLM-guided symbolic regression: it supplies explicit mechanisms for structure preservation and reliable ranking that prior structure-blind LLM methods lack, while using only elementary functions to support generalization. The benchmark audit is a constructive contribution that could improve future evaluations.
major comments (2)
- [Abstract (structure-aware fitting)] Abstract and methods description of structure-aware fitting: the headline recovery rates (107/129 exact forms, 82.9% SA@50) rest on the assumption that decomposition, coefficient constraining, and simplification produce unbiased rankings. No analysis or count is supplied of how often these steps alter the ranking of a known-correct skeleton relative to an overfit alternative, leaving the 4.5x and 3.6x gains vulnerable to the exact concern raised in the stress test.
- [Abstract and results] Abstract and experimental results: the SA@50 and SA@1 figures are reported without error bars, standard deviations, or the number of independent runs; likewise, exact values for the evolutionary hyperparameters (listed as free parameters) are not supplied, preventing assessment of whether the multiples over baselines are stable.
minor comments (2)
- [Abstract] Abstract: 'domain-informed search are carried out' contains a subject-verb agreement error and should read 'is carried out'.
- [Methods] The manuscript would be strengthened by including pseudocode or a precise algorithmic description of the structure-aware fitting steps to clarify how simplification interacts with the tree representation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the benchmark audit as a positive contribution. We respond to each major comment below, committing to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [Abstract (structure-aware fitting)] Abstract and methods description of structure-aware fitting: the headline recovery rates (107/129 exact forms, 82.9% SA@50) rest on the assumption that decomposition, coefficient constraining, and simplification produce unbiased rankings. No analysis or count is supplied of how often these steps alter the ranking of a known-correct skeleton relative to an overfit alternative, leaving the 4.5x and 3.6x gains vulnerable to the exact concern raised in the stress test.
Authors: We acknowledge that the current manuscript lacks a quantitative breakdown of how often the structure-aware fitting steps (decomposition, constraining, and simplification) alter the ranking between a correct skeleton and an overfit alternative. This is a valid point. In the revision we will add an explicit analysis: for every task we will count and report the fraction of evaluated candidates in which the fitting procedure changes the relative ordering of the ground-truth skeleton versus the best overfit alternative, thereby quantifying the reliability of the scoring mechanism. revision: yes
-
Referee: [Abstract and results] Abstract and experimental results: the SA@50 and SA@1 figures are reported without error bars, standard deviations, or the number of independent runs; likewise, exact values for the evolutionary hyperparameters (listed as free parameters) are not supplied, preventing assessment of whether the multiples over baselines are stable.
Authors: The reported figures were obtained from five independent runs using different random seeds. In the revised manuscript we will (i) state the number of runs explicitly, (ii) report standard deviations and include error bars on all SA@50 and SA@1 results, and (iii) provide a table listing the exact numerical values of every evolutionary hyperparameter (population size, parent-selection weights, mutation probabilities, coefficient-optimization tolerances, etc.) that were treated as free parameters. revision: yes
Circularity Check
No circularity: empirical recovery rates measured on external benchmark with no self-referential derivations or fitted predictions.
full rationale
The paper describes an LLM-guided evolutionary search method for symbolic regression and evaluates it via exact-form recovery counts on the 129-task synthetic subset of the external LLM-SRBench benchmark. No equations, uniqueness theorems, or parameter-fitting steps are presented that would make the reported SA@50 or SA@1 figures reduce by construction to quantities defined from the same data or from self-citations. The structure-aware fitting is an internal algorithmic component whose effect is assessed by external performance metrics rather than by re-using the benchmark results to define the method itself. This is the standard non-circular case for an empirical ML paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- evolutionary hyperparameters
axioms (1)
- domain assumption Target expressions can be exactly represented using only the allowed elementary function set.
Reference graph
Works this paper leans on
-
[2]
Science , volume=
Distilling free-form natural laws from experimental data , author=. Science , volume=. 2009 , publisher=
2009
-
[3]
2023 , eprint=
Automated Scientific Discovery: From Equation Discovery to Autonomous Discovery Systems , author=. 2023 , eprint=
2023
-
[4]
2016 , eprint=
Extrapolation and learning equations , author=. 2016 , eprint=
2016
-
[5]
2018 , eprint=
Learning Equations for Extrapolation and Control , author=. 2018 , eprint=
2018
-
[6]
2021 , eprint=
Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients , author=. 2021 , eprint=
2021
-
[9]
2021 , eprint=
Contemporary Symbolic Regression Methods and their Relative Performance , author=. 2021 , eprint=
2021
-
[11]
Shojaee, Parshin and Meidani, Kazem and Gupta, Shashank and Farimani, Amir Barati and Reddy, Chandan K , journal=
-
[12]
Tenenbaum and Daniela Rus and Chuang Gan and Wojciech Matusik , year=
Pingchuan Ma and Tsun-Hsuan Wang and Minghao Guo and Zhiqing Sun and Joshua B. Tenenbaum and Daniela Rus and Chuang Gan and Wojciech Matusik , year=. 2405.09783 , archivePrefix=
-
[14]
2024 , eprint=
Symbolic Regression with a Learned Concept Library , author=. 2024 , eprint=
2024
-
[15]
and Wang, Fei-Yue , journal=
Guo, Zelin and Wang, Siqi and Tian, Yonglin and Yang, Jing and Yu, Hui and Na, Xiaoxiang and Kovacs, Levente and Li, Li and Ioannou, Petros A. and Wang, Fei-Yue , journal=. 2025 , doi=
2025
-
[16]
2025 , eprint=
Enhancing Symbolic Regression with Quality-Diversity and Physics-Inspired Constraints , author=. 2025 , eprint=
2025
-
[21]
Asankhaya Sharma , year =
-
[23]
Parameter identification for symbolic regression using nonlinear least squares , volume =
Kommenda, Michael and Burlacu, Bogdan and Kronberger, Gabriel and Affenzeller, Michael , year =. Parameter identification for symbolic regression using nonlinear least squares , volume =. Genetic Programming and Evolvable Machines , doi =
-
[24]
2024 , eprint=
Benchmarking symbolic regression constant optimization schemes , author=. 2024 , eprint=
2024
-
[25]
Using Genetic Programming with Prior Formula Knowledge to Solve Symbolic Regression Problem , volume =
Lu, Qiang and Ren, Jun and Wang, Zhiguang , year =. Using Genetic Programming with Prior Formula Knowledge to Solve Symbolic Regression Problem , volume =. Computational Intelligence and Neuroscience , doi =
-
[26]
2021 , eprint=
Symbolic Regression via Neural-Guided Genetic Programming Population Seeding , author=. 2021 , eprint=
2021
-
[27]
Population diversity and inheritance in genetic programming for symbolic regression , volume =
Burlacu, Bogdan and Yang, Kaifeng and Affenzeller, Michael , year =. Population diversity and inheritance in genetic programming for symbolic regression , volume =. Natural Computing , doi =
-
[28]
Hengzhe Zhang and Qi Chen and Bing Xue and Wolfgang Banzhaf and Mengjie Zhang , year=. 2505.18602 , archivePrefix=
-
[30]
Context preserving crossover in genetic programming , volume =
D'haeseleer, Patrik , year =. Context preserving crossover in genetic programming , volume =
-
[31]
P. A. Whigham. Grammatically-based Genetic Programming. Proceedings of the Workshop on Genetic Programming: From Theory to Real-World Applications. 1995
1995
-
[33]
Yiping Wang and Shao-Rong Su and Zhiyuan Zeng and Eva Xu and Liliang Ren and Xinyu Yang and Zeyi Huang and Xuehai He and Luyao Ma and Baolin Peng and Hao Cheng and Pengcheng He and Weizhu Chen and Shuohang Wang and Simon Shaolei Du and Yelong Shen , year=. 2511.23473 , archivePrefix=
-
[35]
Enhancing symbolic regression with quality-diversity and physics-inspired constraints, 2025
Jean-Philippe Bruneton. Enhancing symbolic regression with quality-diversity and physics-inspired constraints, 2025. URL https://arxiv.org/abs/2503.19043
arXiv 2025
-
[36]
Population diversity and inheritance in genetic programming for symbolic regression
Bogdan Burlacu, Kaifeng Yang, and Michael Affenzeller. Population diversity and inheritance in genetic programming for symbolic regression. Natural Computing, 23, 01 2023. doi:10.1007/s11047-022-09934-x
-
[37]
William La Cava, Patryk Orzechowski, Bogdan Burlacu, Fabrício Olivetti de França, Marco Virgolin, Ying Jin, Michael Kommenda, and Jason H. Moore. Contemporary symbolic regression methods and their relative performance, 2021. URL https://arxiv.org/abs/2107.14351
arXiv 2021
-
[38]
Interpretable machine learning for science with PySR and SymbolicRegression.jl , 2023
Miles Cranmer. Interpretable machine learning for science with PySR and SymbolicRegression.jl , 2023. URL https://arxiv.org/abs/2305.01582
Pith/arXiv arXiv 2023
-
[39]
Context preserving crossover in genetic programming
Patrik D'haeseleer. Context preserving crossover in genetic programming. 1: 0 256 -- 261 vol.1, 07 1994. doi:10.1109/ICEC.1994.350006
-
[40]
L. G. A dos Reis, V. L. P. S. Caminha, and T. J. P. Penna. Benchmarking symbolic regression constant optimization schemes, 2024. URL https://arxiv.org/abs/2412.02126
arXiv 2024
-
[41]
LLM4Ed : Large language models for automatic equation discovery, 2024
Mengge Du, Yuntian Chen, Zhongzheng Wang, Longfeng Nie, and Dongxiao Zhang. LLM4Ed : Large language models for automatic equation discovery, 2024. URL https://arxiv.org/abs/2405.07761
arXiv 2024
-
[42]
Symbolic regression with a learned concept library, 2024
Arya Grayeli, Atharva Sehgal, Omar Costilla-Reyes, Miles Cranmer, and Swarat Chaudhuri. Symbolic regression with a learned concept library, 2024. URL https://arxiv.org/abs/2409.09359
arXiv 2024
-
[43]
Zelin Guo, Siqi Wang, Yonglin Tian, Jing Yang, Hui Yu, Xiaoxiang Na, Levente Kovacs, Li Li, Petros A. Ioannou, and Fei-Yue Wang. SR-LLM : An incremental symbolic regression framework driven by LLM -based retrieval-augmented generation. Proceedings of the National Academy of Sciences, 122 0 (52): 0 e2516995122, 2025. doi:10.1073/pnas.2516995122
-
[44]
Ge- netic Programming and Evolvable Machines21(3), 471–501 (Dec 2019)
Michael Kommenda, Bogdan Burlacu, Gabriel Kronberger, and Michael Affenzeller. Parameter identification for symbolic regression using nonlinear least squares. Genetic Programming and Evolvable Machines, 21, 09 2020. doi:10.1007/s10710-019-09371-3
-
[45]
John R. Koza. Genetic programming as a means for programming computers by natural selection. Statistics and Computing, 4 0 (2): 0 87--112, June 1994. ISSN 1573-1375. doi:10.1007/BF00175355. URL https://doi.org/10.1007/BF00175355
-
[46]
Automated scientific discovery: From equation discovery to autonomous discovery systems, 2023
Stefan Kramer, Mattia Cerrato, Jannis Brugger, Sašo Džeroski, and Ross King. Automated scientific discovery: From equation discovery to autonomous discovery systems, 2023. URL https://arxiv.org/abs/2305.02251
Pith/arXiv arXiv 2023
-
[47]
ShinkaEvolve : Towards open-ended and sample-efficient program evolution, 2025
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. ShinkaEvolve : Towards open-ended and sample-efficient program evolution, 2025. URL https://arxiv.org/abs/2509.19349
Pith/arXiv arXiv 2025
-
[48]
Data-driven discovery of physical laws
Pat Langley. Data-driven discovery of physical laws. Cognitive Science, 5 0 (1): 0 31--54, 1981. doi:https://doi.org/10.1111/j.1551-6708.1981.tb00869.x. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1551-6708.1981.tb00869.x
-
[49]
Using genetic programming with prior formula knowledge to solve symbolic regression problem
Qiang Lu, Jun Ren, and Zhiguang Wang. Using genetic programming with prior formula knowledge to solve symbolic regression problem. Computational Intelligence and Neuroscience, 2016: 0 1--17, 12 2015. doi:10.1155/2016/1021378
-
[50]
Georg Martius and Christoph H. Lampert. Extrapolation and learning equations, 2016. URL https://arxiv.org/abs/1610.02995
Pith/arXiv arXiv 2016
-
[51]
David J. Montana. Strongly typed genetic programming. Evolutionary Computation, 3 0 (2): 0 199--230, Summer 1995. ISSN 1063-6560. doi:10.1162/evco.1995.3.2.199. URL http://vishnu.bbn.com/papers/stgp.pdf
-
[52]
Nathan Mundhenk, Mikel Landajuela, Ruben Glatt, Claudio P
T. Nathan Mundhenk, Mikel Landajuela, Ruben Glatt, Claudio P. Santiago, Daniel M. Faissol, and Brenden K. Petersen. Symbolic regression via neural-guided genetic programming population seeding, 2021. URL https://arxiv.org/abs/2111.00053
arXiv 2021
-
[53]
Alexander Novikov, Ngân Vũ, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve : A coding agent for scientific and algor...
Pith/arXiv arXiv 2025
-
[54]
Brenden K. Petersen, Mikel Landajuela, T. Nathan Mundhenk, Claudio P. Santiago, Soo K. Kim, and Joanne T. Kim. Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients, 2021. URL https://arxiv.org/abs/1912.04871
arXiv 2021
-
[55]
Subham S. Sahoo, Christoph H. Lampert, and Georg Martius. Learning equations for extrapolation and control, 2018. URL https://arxiv.org/abs/1806.07259
Pith/arXiv arXiv 2018
-
[56]
Distilling free-form natural laws from experimental data
Michael Schmidt and Hod Lipson. Distilling free-form natural laws from experimental data. Science, 324 0 (5923): 0 81--85, 2009
2009
-
[57]
OpenEvolve : an open-source evolutionary coding agent, 2025
Asankhaya Sharma. OpenEvolve : an open-source evolutionary coding agent, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve
2025
-
[58]
LLM-SR : Scientific equation discovery via programming with large language models
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K Reddy. LLM-SR : Scientific equation discovery via programming with large language models. arXiv preprint arXiv:2404.18400, 2024
arXiv 2024
-
[59]
LLM-SRBench : A new benchmark for scientific equation discovery with large language models, 2025
Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, and Chandan K Reddy. LLM-SRBench : A new benchmark for scientific equation discovery with large language models, 2025. URL https://arxiv.org/abs/2504.10415
arXiv 2025
-
[60]
AI Feynman : A physics-inspired method for symbolic regression
Silviu-Marian Udrescu and Max Tegmark. AI Feynman : A physics-inspired method for symbolic regression. Science Advances, 6 0 (16): 0 eaay2631, 2020. doi:10.1126/sciadv.aay2631. URL https://www.science.org/doi/abs/10.1126/sciadv.aay2631
-
[61]
Marco Virgolin and Solon P. Pissis. Symbolic regression is NP -hard, 2022. URL https://arxiv.org/abs/2207.01018
arXiv 2022
-
[62]
Boxiao Wang, Kai Li, Tianyi Liu, Chen Li, Junzhe Wang, Yifan Zhang, and Jian Cheng. LLM -based scientific equation discovery via physics-informed token-regularized policy optimization, 2026. URL https://arxiv.org/abs/2602.10576
arXiv 2026
-
[63]
DRSR : LLM -based scientific equation discovery with dual reasoning from data and experience, 2025
Runxiang Wang, Boxiao Wang, Kai Li, Yifan Zhang, and Jian Cheng. DRSR : LLM -based scientific equation discovery with dual reasoning from data and experience, 2025. URL https://arxiv.org/abs/2506.04282
arXiv 2025
-
[64]
P. A. Whigham. Grammatically-based genetic programming. In Justinian P. Rosca, editor, Proceedings of the Workshop on Genetic Programming: From Theory to Real-World Applications, pages 33--41, Tahoe City, California, USA, 9 July 1995. URL http://divcom.otago.ac.nz/sirc/Peterw/Publications/ml95.zip
1995
-
[65]
SR-Scientist : Scientific equation discovery with agentic AI , 2025
Shijie Xia, Yuhan Sun, and Pengfei Liu. SR-Scientist : Scientific equation discovery with agentic AI , 2025. URL https://arxiv.org/abs/2510.11661
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.