SAW: Stage-Aware Dynamic Weighting for Multi-Objective Reinforcement Learning in Large Language Models
Pith reviewed 2026-06-27 22:37 UTC · model grok-4.3
The pith
Dynamic weighting by coefficient of variation addresses asynchronous reward learning across objectives in multi-objective reinforcement learning for large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
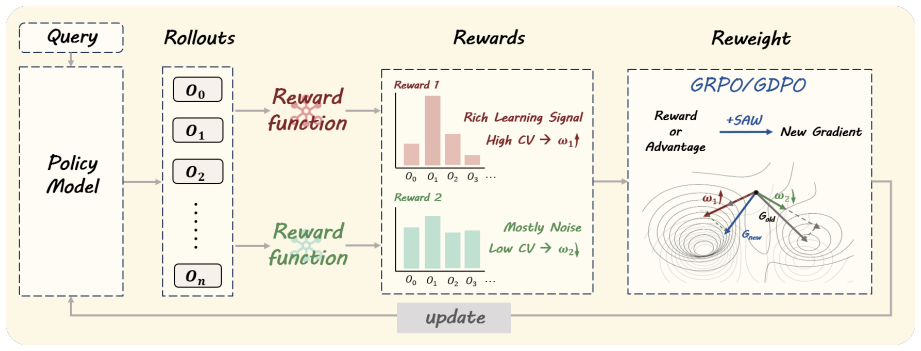
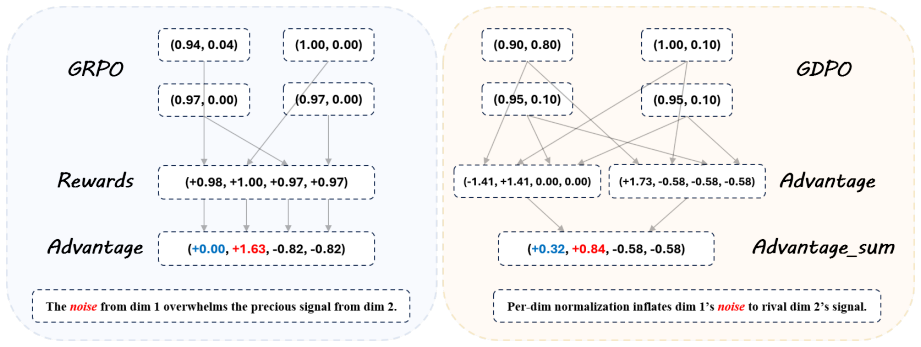
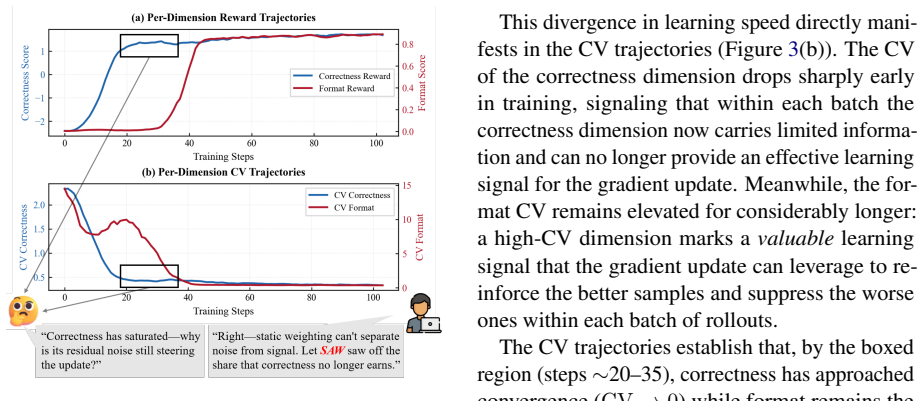
Reward learning across objectives in multi-objective reinforcement learning for large language models occurs asynchronously, with well-learned objectives producing homogeneous low-variance signals that contaminate the aggregated reward or advantage. Stage-Aware Dynamic Weighting (SAW) uses the coefficient of variation within each batch as a scale-invariant indicator of informativeness to dynamically adjust the weight of each objective's signal, thereby prioritizing contributions from under-learned dimensions without requiring additional gradient computations.
What carries the argument
Stage-Aware Dynamic Weighting (SAW), which reweights each objective's reward or advantage contribution proportionally to its coefficient of variation computed over the current batch.
If this is right
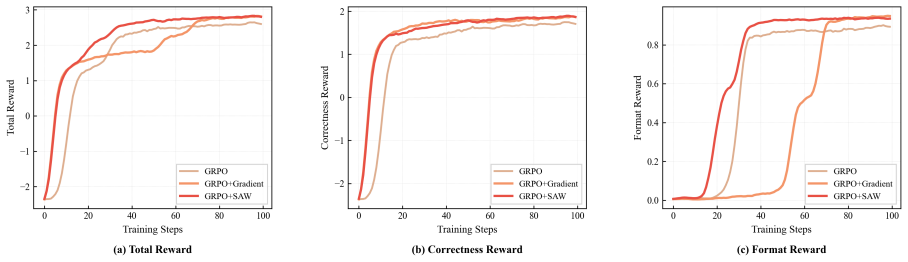
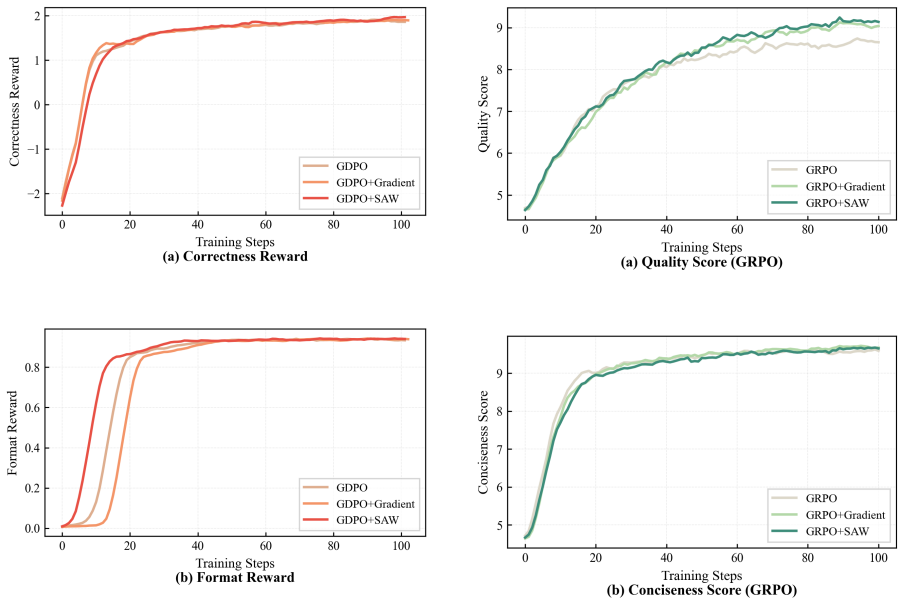
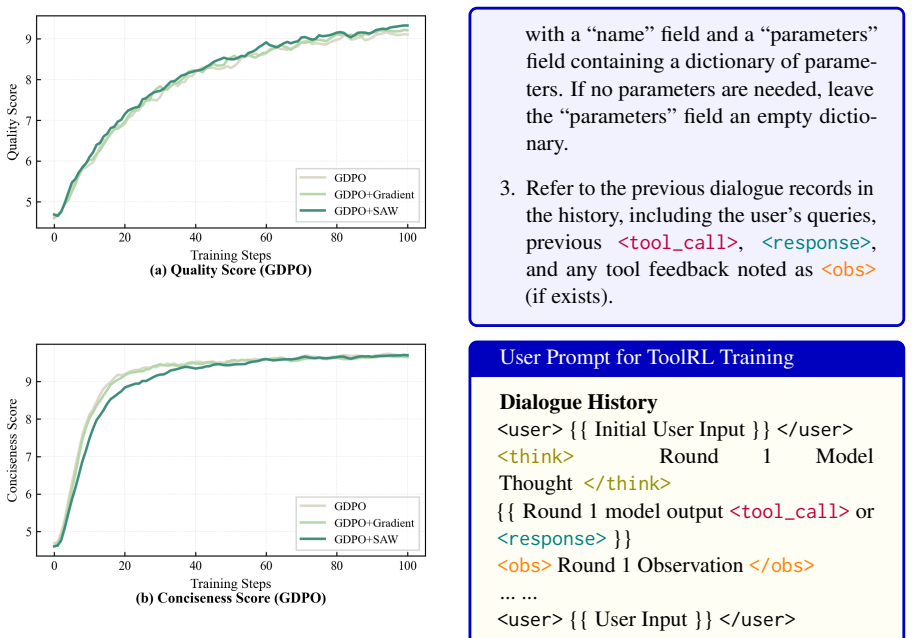
- SAW improves training efficiency and final performance on tool-calling and text summarization tasks.
- SAW functions as a general-purpose plug-in for both GRPO and GDPO frameworks.
- SAW introduces nearly negligible computational overhead by relying solely on batch-level statistics.
- SAW mitigates interference from low-variance signals of well-learned objectives.
Where Pith is reading between the lines
- SAW could reduce reliance on manual hyperparameter tuning for static weights in multi-objective setups.
- The approach might extend to other sequential decision tasks where reward components mature at different rates.
- Performance gains could diminish if batch sizes are too small for reliable CV estimation.
- Testing SAW on additional alignment tasks such as reasoning or safety would reveal its broader applicability.
Load-bearing premise
The coefficient of variation within a batch reliably tracks the informativeness of each objective's current learning signal.
What would settle it
Running SAW on a multi-objective task where all objectives have synchronized variance reduction but observing no improvement over static weighting would falsify the benefit of the dynamic mechanism.
Figures
read the original abstract
Although multi-objective reinforcement learning (MORL) is central to aligning large language models with complex human preferences, the prevailing practice of static weighted summation overlooks a more fundamental phenomenon: reward learning is markedly asynchronous across objectives. Well-learned dimensions quickly produce homogeneous, low-variance signals whose residual noise contaminates the aggregated reward (in GRPO) or occupies a fixed share of the advantage budget (in GDPO), interfering with the scarce yet high-value signals carried by under-learned dimensions. To address this asynchrony, we propose Stage-Aware Dynamic Weighting (SAW), a lightweight, algorithm-agnostic dynamic weighting mechanism. SAW utilizes the coefficient of variation (CV) as a scale-invariant proxy for real-time informativeness, reweighting each dimension's reward or advantage contribution by its relative informativeness within the batch. Unlike gradient-based methods that require multiple forward and backward passes, SAW relies solely on batch-level statistics, introducing nearly negligible computational overhead. Experiments on tool-calling and text summarization tasks demonstrate that SAW consistently improves both training efficiency and final performance under both GRPO and GDPO frameworks, confirming it as a general-purpose plug-in for multi-reward LLM alignment. Our code is available at https://github.com/Zhaolutuan/SAW
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that static weighted summation in multi-objective RL for LLM alignment (e.g., GRPO, GDPO) fails due to asynchronous learning across reward objectives, where well-learned dimensions produce low-variance signals that contaminate the aggregate; it proposes Stage-Aware Dynamic Weighting (SAW), which reweights each objective's reward/advantage contribution inside the batch by its coefficient of variation (CV) as a scale-invariant proxy for residual informativeness, and reports that this yields consistent gains in training efficiency and final performance on tool-calling and text-summarization tasks while adding negligible overhead.
Significance. If the results hold, SAW supplies a lightweight, algorithm-agnostic plug-in for handling reward asynchrony in multi-preference LLM alignment. The public code release at https://github.com/Zhaolutuan/SAW is a concrete strength that supports reproducibility and allows independent verification of the batch-statistic mechanism.
major comments (2)
- [Abstract] Abstract (and §3, method description): the claim that CV is a reliable proxy for per-objective informativeness rests on the untested assertion that high batch CV indicates under-learned objectives while low CV indicates saturation; no derivation, comparison to alternatives (normalized variance, advantage entropy, or per-objective gradient norm), or correlation analysis with independent progress metrics is supplied, leaving the reweighting rule without justification.
- [Abstract] Abstract (experiments paragraph): the central empirical claim of 'consistent improvements' under both GRPO and GDPO is stated without any reported baselines, number of seeds, error bars, statistical tests, or ablations that isolate the CV weighting from other factors; this absence makes it impossible to evaluate whether the observed gains are attributable to the proposed mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and will revise the manuscript to strengthen the presentation where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract (and §3, method description): the claim that CV is a reliable proxy for per-objective informativeness rests on the untested assertion that high batch CV indicates under-learned objectives while low CV indicates saturation; no derivation, comparison to alternatives (normalized variance, advantage entropy, or per-objective gradient norm), or correlation analysis with independent progress metrics is supplied, leaving the reweighting rule without justification.
Authors: We agree that the current manuscript provides limited explicit justification for CV beyond its scale-invariance. In the revision we will expand §3 with a short derivation showing why batch CV serves as a proxy for residual informativeness (high CV signals ongoing dispersion from under-learned objectives; low CV signals saturation), include a direct comparison to normalized variance and per-objective gradient norm, and add a correlation analysis against independent progress metrics such as per-objective reward curves. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): the central empirical claim of 'consistent improvements' under both GRPO and GDPO is stated without any reported baselines, number of seeds, error bars, statistical tests, or ablations that isolate the CV weighting from other factors; this absence makes it impossible to evaluate whether the observed gains are attributable to the proposed mechanism.
Authors: The abstract is intentionally concise. Section 4 and the appendix already report results against static-weighting and random-weighting baselines, averaged over 5 seeds with standard-error bars, plus ablations that isolate the CV term. We will revise the abstract's experiments paragraph to explicitly reference the number of seeds, error bars, and the presence of isolating ablations and statistical tests. revision: yes
Circularity Check
No circularity; CV proxy is an explicit heuristic choice with no self-referential reduction
full rationale
The paper defines SAW directly via batch-level CV computation as a scale-invariant proxy and applies it to reweight rewards/advantages in GRPO/GDPO. No equations reduce a claimed prediction back to fitted inputs by construction, no self-citations are invoked as load-bearing uniqueness theorems, and the core mechanism does not rename known results or smuggle ansatzes. The approach is presented as an algorithmic design choice validated on external tasks, remaining self-contained without circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward learning is markedly asynchronous across objectives in multi-objective RL for LLMs.
Reference graph
Works this paper leans on
-
[1]
Reward-free Alignment for Conflicting Objectives
Reward-free alignment for conflicting objec- tives.arXiv preprint arXiv:2602.02495. Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. 2018. GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InInternational Conference on Machine Learning, pages 794–803. Paul F Christiano, Jan Leike, Tom Brown, Milja...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Improving alignment of dialogue agents via targeted human judgements
Safe rlhf: Safe reinforcement learning from hu- man feedback. InInternational Conference on Learn- ing Representations, volume 2024, pages 50750– 50777. Amelia Glaese, Nat McAleese, Maja Tr˛ ebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, and 1 others. 2022. Improving alignment of dia- logu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains.arXiv preprint arXiv:2507.17746. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Reinforcement learning with rubric anchors. Preprint, arXiv:2508.12790. Yuki Ichihara, Yuu Jinnai, Tetsuro Morimura, Mitsuki Sakamoto, Ryota Mitsuhashi, and Eiji Uchibe. 2025. Mo-grpo: Mitigating reward hacking of group rela- tive policy optimization on multi-objective problems. arXiv preprint arXiv:2509.22047. 9 Yuhang Lai, Siyuan Wang, Shujun Liu, Xuan-...
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Ozan Sener and Vladlen Koltun. 2018. Multi-task learn- ing as multi-objective optimization.Advances in neural information processing systems, 31. 10 Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Siqian Tong, Xuan Li, Yiwei Wang, Baolong Bi, Yujun Cai, Shenghua Liu, Yuchen He, and Chengpeng Hao
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Michael Völske, Martin Potthast, Shahbaz Syed, and Benno Stein
Autagent: A reinforcement learning frame- work for tool-augmented audio reasoning.arXiv preprint arXiv:2602.13685. Michael Völske, Martin Potthast, Shahbaz Syed, and Benno Stein. 2017. Tl; dr: Mining reddit to learn au- tomatic summarization. InProceedings of the work- shop on new frontiers in summarization, pages 59– 63. Zeqiu Wu, Yushi Hu, Weijia Shi, N...
-
[8]
converts multi-objective aggregation into a closed-form convex optimization within the PPO framework to converge to a Pareto-stationary point, while GAPO (Li et al., 2025) adaptively balances policy-gradient directions via multi-gradient descent. In contrast to all of the above, which operate onwhatsignal each dimension contributes, SAW addresseswhen: it ...
2025
-
[9]
Think: Recall relevant context and ana- lyze the current user goal
-
[10]
Decide on Tool Usage: If a tool is needed, specify the tool and its parame- ters
-
[11]
name": "Tool name
Respond Appropriately: If a response is needed, generate one while maintain- ing consistency across user queries. 13 Figure 7: Per-dimension reward trajectories for GDPO- based methods during training on Reddit TL;DR with Qwen2.5-1.5B-Instruct. Output Format <think> Your thoughts and reasoning </think> <tool_call> {"name": "Tool name", "pa- rameters": {"P...
-
[12]
Pro- vide at least one of <tool_call> or <response>
You must always include the <think> field to outline your reasoning. Pro- vide at least one of <tool_call> or <response>. Decide whether to use <tool_call> (possibly multiple times), <response>, or both
-
[13]
name” field and a “parameters
You can invoke multiple tool calls si- multaneously in the <tool_call> fields. Each tool call should be a JSON object with a “name” field and a “parameters” field containing a dictionary of parame- ters. If no parameters are needed, leave the “parameters” field an empty dictio- nary
-
[14]
Model-Generated Summary
Refer to the previous dialogue records in the history, including the user’s queries, previous <tool_call>, <response>, and any tool feedback noted as <obs> (if exists). User Prompt for ToolRL Training Dialogue History <user>{{ Initial User Input }}</user> <think> Round 1 Model Thought</think> {{ Round 1 model output <tool_call> or <response>}} <obs>Round ...
2026
-
[15]
Core Message
Identify the “Core Message” from the Human Summary. 16
-
[16]
Check if the Model Summary contains this Core Message (Quality)
-
[17]
Filler Words
Count “Filler Words”: phrases that can be removed without changing the mean- ing (Conciseness)
-
[18]
# Task Input [Original Reddit Post]: $reddit_text [Human-Written Summary (Reference)]: $human_summary [Model-Generated Summary (To be evalu- ated)]: $model_summary # Constraints
Penalize hallucinations heavily. # Task Input [Original Reddit Post]: $reddit_text [Human-Written Summary (Reference)]: $human_summary [Model-Generated Summary (To be evalu- ated)]: $model_summary # Constraints
-
[19]
Output ONLY a valid JSON object
-
[20]
quality": {
Be clinical and objective. # Output Format { "quality": { "score": [Integer] }, "conciseness": { "score": [Integer] } } I Reddit TL;DR Hyperparameters Setting We list below the hyperparameter setting used in our Reddit TL;DR experiments. The complete training configuration is given in Table 6. Parameter Value Total Epochs 11 Train Batch Size 256 Mini Batc...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.