Joint Structural Pruning and Mixed-Precision Quantization for LLM Compression
Pith reviewed 2026-06-27 21:45 UTC · model grok-4.3
The pith
An end-to-end framework jointly optimizes structural pruning and mixed-precision quantization for LLMs by minimizing global error propagation across the full model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
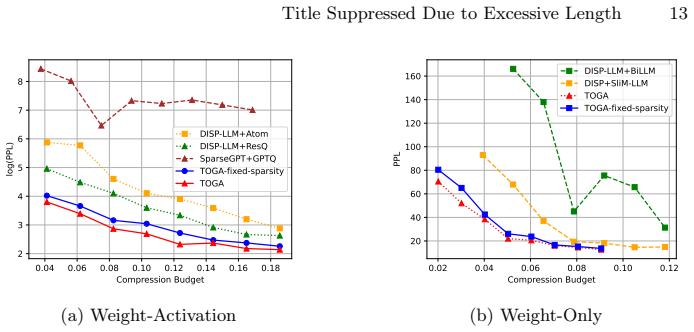
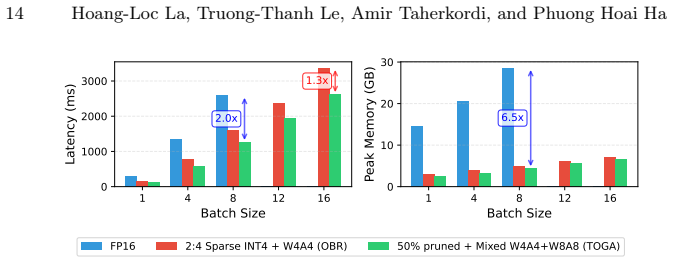
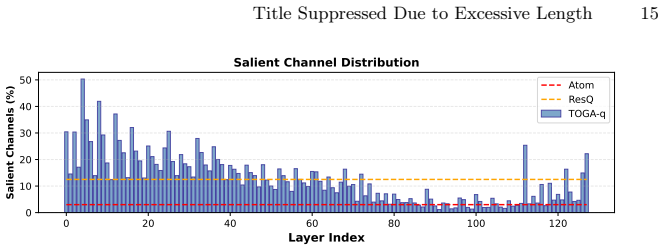
The paper claims that a novel mixed-precision PTQ strategy minimizing global error propagation, combined with a joint optimization approach that learns structural pruning decisions and mixed-precision quantization policies inside one unified search space, produces up to 21 percent lower WikiText perplexity than state-of-the-art weight-activation baselines at 1-3 bits, up to 59 percent and 85 percent lower perplexity than leading weight-only methods on WikiText and C4, and better perplexity plus reasoning scores than prior joint pruning-quantization techniques at the same ultra-low precisions.
What carries the argument
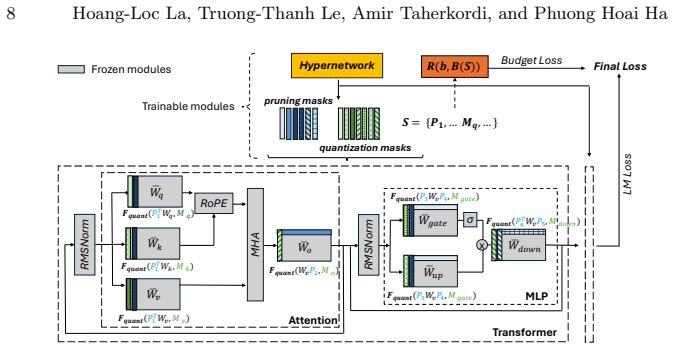
A unified search space that simultaneously learns structural pruning decisions and mixed-precision quantization policies while modeling global error propagation through the network.
If this is right
- At 1-3 bit precisions the method reduces WikiText perplexity by up to 21 percent relative to state-of-the-art weight-activation quantization baselines.
- It achieves up to 59 percent and 85 percent lower perplexity than leading weight-only quantization methods on WikiText and C4 respectively.
- It delivers superior perplexity and reasoning performance compared with state-of-the-art joint pruning-and-quantization techniques at ultra-low bits.
Where Pith is reading between the lines
- The global-error approach might be combined with hardware cost models to produce latency-aware rather than only memory-aware compression schedules.
- Extending the unified search to include activation quantization alongside weights could further close the gap to full integer inference pipelines.
- If the search remains stable on models larger than those tested, the same joint formulation could be applied to multimodal or retrieval-augmented architectures without separate tuning stages.
Load-bearing premise
A unified search space can simultaneously learn effective pruning decisions and mixed-precision policies while accurately modeling global error propagation without introducing optimization instability or unaccounted overhead.
What would settle it
Reproducing the experiments on the same LLMs and bit widths but observing either higher perplexity than the reported baselines or failure of the joint search to converge stably would falsify the claim that global error minimization in a unified space is effective.
Figures
read the original abstract
Recently, the efficiency of Large Language Models (LLMs) deployment has become a critical concern in practical applications. While post-training quantization (PTQ) and structural pruning are established techniques for reducing memory footprint and inference latency, most existing PTQ approaches optimize quantization errors on a per-layer basis, overlooking how errors accumulate and propagate through the network, often resulting in suboptimal solutions. Traditional pipelines also tend to apply pruning and quantization in isolation or sequentially, further compounding sub-optimality. We introduce a novel end-to-end framework that addresses these limitations in two key ways. First, we propose a novel mixed-precision PTQ strategy that directly minimizes global error propagation across the entire model, rather than isolating layer-wise errors. Building on this, we develop a novel joint optimization approach that simultaneously learns structural pruning decisions and mixed-precision quantization policies within a unified search space. Extensive experiments show that, at ultra-low precisions (1-3 bits), our quantization method reduces WikiText perplexity by up to 21% compared to state-of-the-art (SoTA) weight-activation quantization baselines. Against leading weight-only quantization methods, it achieves up to 59% and 85% lower perplexity on WikiText and C4, respectively. Compared to the SoTA joint pruning-and-quantization techniques, our proposed method delivers superior perplexity and reasoning performance at ultra-low bits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an end-to-end framework for LLM compression that combines a mixed-precision post-training quantization (PTQ) strategy minimizing global error propagation with a joint optimization approach that simultaneously learns structural pruning decisions and mixed-precision policies in a unified search space. It reports empirical gains at 1-3 bit precisions, including up to 21% lower WikiText perplexity versus SoTA weight-activation baselines, up to 59%/85% lower perplexity versus weight-only methods on WikiText/C4, and better results than prior joint pruning-quantization techniques.
Significance. If the central claims hold under full experimental scrutiny, the unified global-error approach could meaningfully improve upon the common practice of isolated or sequential pruning and quantization, offering a practical route to higher-accuracy ultra-low-bit LLMs. The reported perplexity reductions at 1-3 bits are large enough to be deployment-relevant if they survive ablations and hold across model families.
minor comments (2)
- The abstract states performance numbers but provides no derivation, algorithm pseudocode, or description of the unified search space; a methods section detailing the joint objective, error-propagation model, and search procedure is required to evaluate the approach.
- No mention of ablation studies, sensitivity to hyperparameters, or overhead measurements for the joint search; these are needed to substantiate that the unified space does not introduce instability or unaccounted cost.
Simulated Author's Rebuttal
We thank the referee for reviewing our manuscript on the joint structural pruning and mixed-precision quantization framework. We appreciate the positive assessment of the potential significance of minimizing global error propagation in an end-to-end manner. The report does not list any specific major comments, so we have no point-by-point responses to provide at this time. We remain available to supply additional experimental details, ablations, or clarifications if needed to resolve the uncertain recommendation.
Circularity Check
No circularity detected; derivation self-contained on available text
full rationale
The abstract and provided material describe a joint optimization framework for pruning and quantization but contain no equations, parameter-fitting steps, self-citations, or ansatzes that reduce any claimed prediction or result to its own inputs by construction. No load-bearing derivation chain is visible, so the central claims cannot be shown to be circular. This is the expected outcome when source text supplies no explicit mathematical steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Winogrande: An adversarial winograd schema challenge at scale (2019)
2019
-
[2]
In: NeurIPS (2025)
Arai, Y., Ichikawa, Y.: Quantization error propagation: Revisiting layer-wise post- training quantization. In: NeurIPS (2025)
2025
-
[3]
NeurIPS (2024)
Ashkboos, S., et al.: Quarot: Outlier-free 4-bit inference in rotated llms. NeurIPS (2024)
2024
-
[4]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y., Léonard, N., Courville, A.: Estimating or propagating gradi- ents through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
In: NAACL (2019)
Clark, C., et al.: Boolq: Exploring the surprising difficulty of natural yes/no ques- tions. In: NAACL (2019)
2019
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., et al.: Think you have solved question answering? try ARC, the AI2 reasoning challenge. arXiv preprint arXiv:1803.05457 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
In: ICML (2023)
Frantar, E., Alistarh, D.: Sparsegpt: Massive language models can be accurately pruned in one-shot. In: ICML (2023)
2023
-
[8]
Frantar, E., et al.: Gptq: Accurate post-training quantization for generative pre- trained transformers (2023)
2023
-
[9]
NeurIPS (2024)
Gao, S., et al.: Disp-llm: Dimension-independent structural pruning for large lan- guage models. NeurIPS (2024)
2024
-
[10]
arXiv preprint arXiv:2509.11177 (2025)
Guo, H., Li, Y., Benini, L.: Optimal brain restoration for joint quantization and sparsification of llms. arXiv preprint arXiv:2509.11177 (2025)
-
[11]
In: ICLR (2016)
Han,S.,Mao,H.,Dally,W.J.:Deepcompression:Compressingdeepneuralnetwork with pruning, trained quantization and huffman coding. In: ICLR (2016)
2016
-
[12]
In: ICLR (2025)
Harma, S.B., et al.: Effective interplay between sparsity and quantization: From theory to practice. In: ICLR (2025)
2025
-
[13]
In: IEEE International Conference on Neural Networks (1993)
Hassibi, B., Stork, D.G., Wolff, G.J.: Optimal brain surgeon and general network pruning. In: IEEE International Conference on Neural Networks (1993)
1993
-
[14]
ICLR (2021)
Hendrycks, D., et al.: Aligning ai with shared human values. ICLR (2021)
2021
-
[15]
JMLR (2021)
Hoefler, T., et al.: Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. JMLR (2021)
2021
-
[16]
In: ICML (2024)
Huang, W., et al.: Billm: Pushing the limit of post-training quantization for llms. In: ICML (2024)
2024
-
[17]
In: ICML (2025)
Huang, W., et al.: Slim-llm: Salience-driven mixed-precision quantization for large language models. In: ICML (2025)
2025
-
[18]
In: ICLR (2017)
Jang, E., Gu, S., Poole, B.: Categorical reparametrization with gumble-softmax. In: ICLR (2017)
2017
-
[19]
Kuzmin, A., et al.: Pruning vs quantization: Which is better? NeurIPS (2023) Title Suppressed Due to Excessive Length 17
2023
-
[20]
In: ICLR (2025)
Liu, Z., et al.: Spinquant: Llm quantization with learned rotations. In: ICLR (2025)
2025
-
[21]
In: ICLR (2017)
Merity, S., et al.: Pointer sentinel mixture models. In: ICLR (2017)
2017
-
[22]
JMLR (2020)
Raffel, C., et al.: Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR (2020)
2020
-
[23]
In: ICML (2025)
Saxena, U., et al.: Resq: Mixed-precision quantization of large language models with low-rank residuals. In: ICML (2025)
2025
-
[24]
arXiv preprint arXiv:2408.11796 (2024)
Sreenivas, S.T., et al.: Llm pruning and distillation in practice: The minitron ap- proach. arXiv preprint arXiv:2408.11796 (2024)
-
[25]
SuperIntelligence-Robotics-Safety & Alignment (2025)
Tang, S., et al.: Darwinlm: Evolutionary structured pruning of large language mod- els. SuperIntelligence-Robotics-Safety & Alignment (2025)
2025
-
[26]
NeurIPS (2017)
Vaswani, A., et al.: Attention is all you need. NeurIPS (2017)
2017
-
[27]
In: ICML (2023)
Xiao, G., et al.: Smoothquant: Accurate and efficient post-training quantization for large language models. In: ICML (2023)
2023
-
[28]
Zellers,R.,Holtzman,A.,Bisk,Y.,Farhadi,A.,Choi,Y.:Hellaswag:Canamachine really finish your sentence? In: ACL (2019)
2019
-
[29]
In: ACL (2025)
Zhao, J., et al.: Ptq1.61: Push the real limit of extremely low-bit post-training quantization methods for large language models. In: ACL (2025)
2025
-
[30]
Proceedings of Machine Learning and Systems (2024)
Zhao, Y., et al.: Atom: Low-bit quantization for efficient and accurate llm serving. Proceedings of Machine Learning and Systems (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.