VisualFLIP: Do Predictions Depend on Task-Critical Visual Evidence in Multimodal Reasoning?
Pith reviewed 2026-06-27 21:54 UTC · model grok-4.3
The pith
Multimodal models often repeat the same answer even after task-critical visual evidence is altered.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
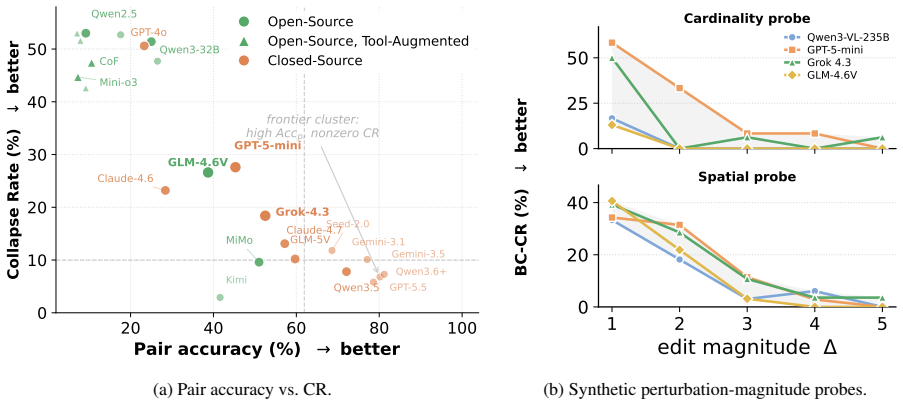
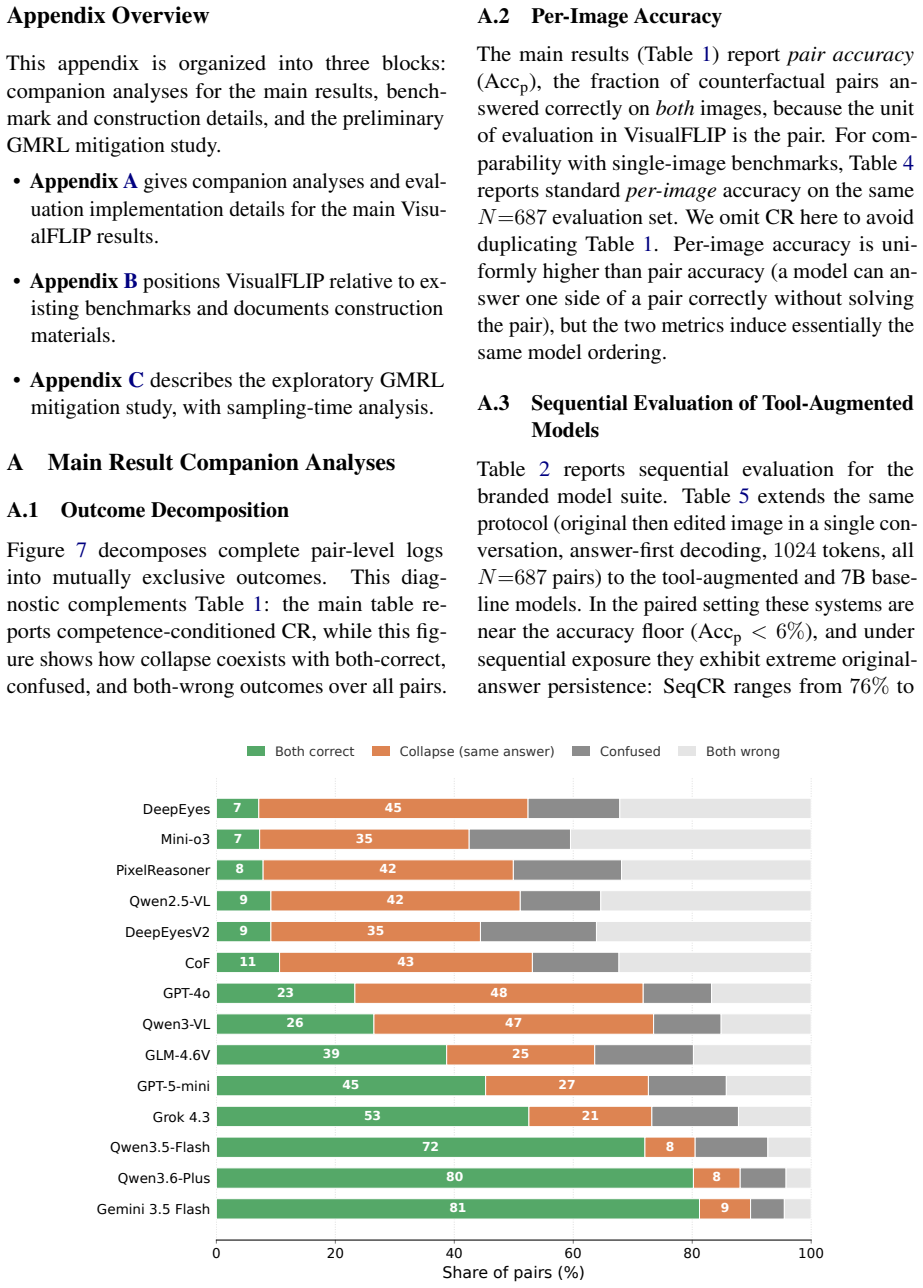
Paired correctness and evidence dependence are related but distinct properties. Capable multimodal large language models can solve one member of a perturbation pair yet fail to update their prediction when the task-critical visual evidence changes, producing the same answer for both images. Collapse becomes more severe for certain models in a sequential setting where the edited image follows the original answer.
What carries the argument
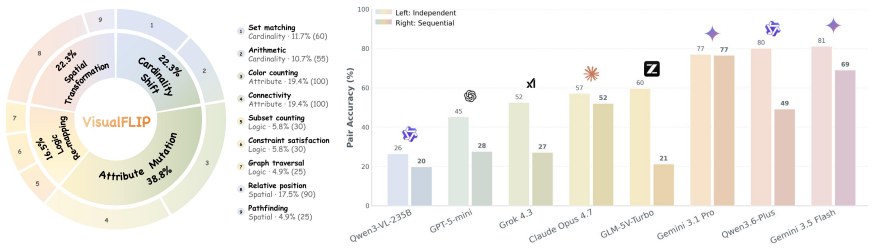
VisualFLIP benchmark of same-question perturbation pairs with pair accuracy and Collapse Rate (CR) metrics that together test whether correct answers depend on the changed visual evidence.
If this is right
- Accuracy alone is insufficient to confirm that a model grounds its answer in the image.
- Sequential presentation of paired images can increase answer repetition for some models.
- Evaluation must include both sides of each pair to separate evidence dependence from mere correctness.
- Models that pass standard benchmarks can still ignore minimal visual changes that should flip the answer.
Where Pith is reading between the lines
- Training may reward surface patterns more than sensitivity to small evidence shifts.
- The benchmark could be adapted to test longer reasoning chains or other modalities.
- Developers could add explicit checks that force models to verify whether key visual elements have changed.
- Repeated answers across pairs point to a need for new objectives that penalize evidence-insensitive outputs.
Load-bearing premise
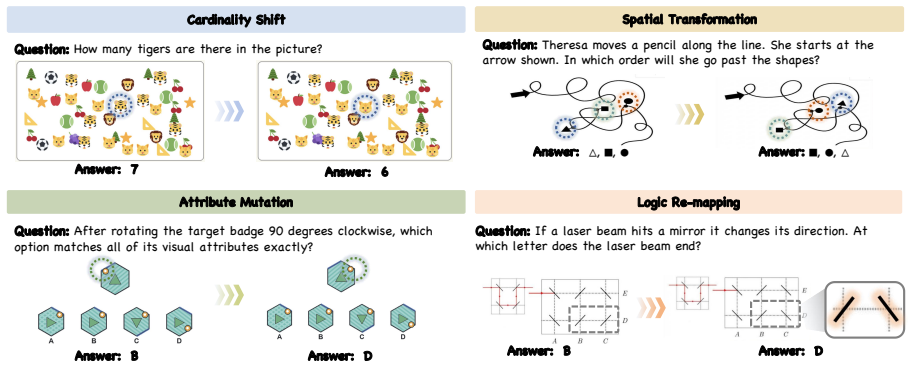
The image edits are minimal, touch only the task-critical evidence, and produce a deterministic flip in the gold answer without adding other visual or semantic changes.
What would settle it
A model that changes its answer correctly on every VisualFLIP pair while keeping high pair accuracy would show that its predictions track the visual evidence rather than collapse.
Figures



read the original abstract
When a multimodal large language model answers a visual reasoning question correctly, is the prediction actually supported by the task-critical visual evidence? Correct answers can coexist with flawed reasoning, making accuracy alone an incomplete test of grounding. We introduce VisualFLIP, a paired benchmark with 1,374 images arranged as same-question perturbation pairs across cardinality, attribute, spatial, and logic tasks. Each pair keeps the question fixed but minimally changes the evidence so the gold answer deterministically flips. We evaluate 24 MLLMs with pair accuracy, which requires solving both sides of a pair, and Collapse Rate (CR), which measures how often a model that solves at least one side repeats the same non-empty answer for both images. Together, these metrics show that paired correctness and evidence dependence are related but distinct: capable models can still fail to update after task-critical visual changes, and collapse becomes more severe for some models when the edited image follows an earlier answer in a sequential setting. Further details are available on our project page: https://didizhu-judy.github.io/VisualFLIP/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VisualFLIP, a benchmark of 1,374 images forming same-question perturbation pairs across cardinality, attribute, spatial, and logic tasks. Each pair minimally alters task-critical visual evidence to deterministically flip the gold answer while keeping the question fixed. It evaluates 24 MLLMs using pair accuracy (correct on both sides) and Collapse Rate (CR; tendency to repeat the same answer across the pair), arguing that paired correctness and evidence dependence are related but distinct: capable models can fail to update after evidence changes, with collapse worsening in sequential settings.
Significance. If the perturbation validity holds, the work supplies a useful diagnostic for grounding in MLLMs beyond accuracy, highlighting that correct predictions need not reflect dependence on the intended visual evidence. The metrics and paired design offer a concrete way to quantify this gap, and the project page aids reproducibility. This could inform more robust evaluation practices in multimodal reasoning.
major comments (3)
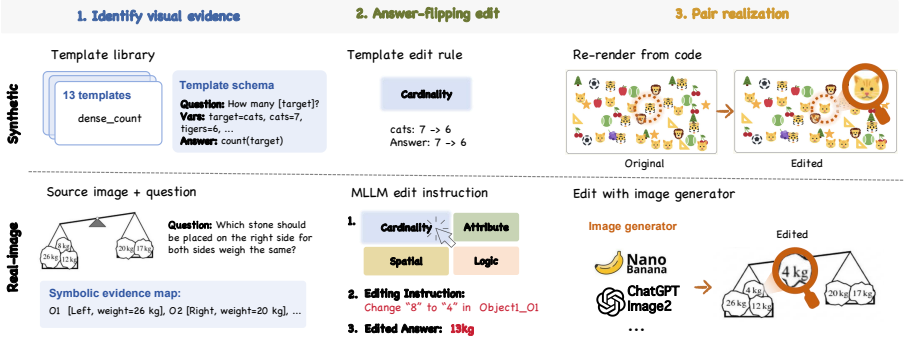
- [Benchmark construction] Benchmark construction section: the manuscript asserts that perturbations 'minimally change the evidence' and 'deterministically flip' the gold answer, but supplies no construction protocol, no inter-annotator agreement for the gold labels, and no verification (human or automated) that changes are confined to task-critical evidence without confounders such as lighting, composition, or co-occurrence shifts. This assumption is load-bearing for the central claim that non-updating behavior demonstrates absence of evidence dependence rather than sensitivity to unintended cues.
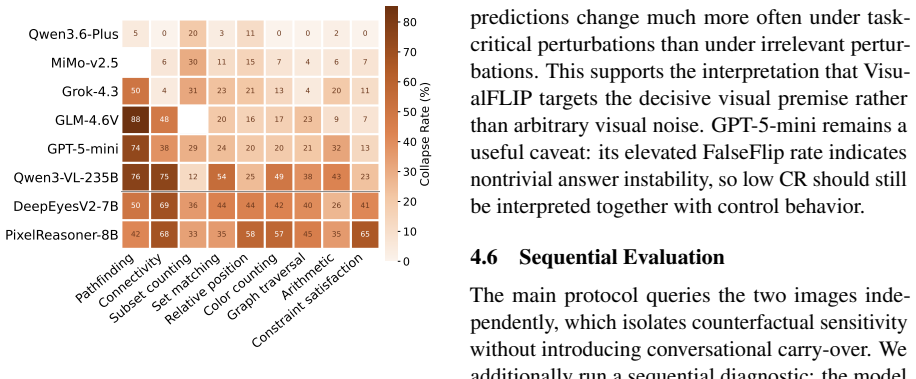
- [Experiments and results] Experiments and results sections: pair accuracy and CR are reported across 24 models and tasks, yet no statistical tests, confidence intervals, or significance assessments are provided for differences (e.g., CR elevation in sequential vs. independent settings). Without these, the robustness of the distinction between correctness and evidence dependence cannot be evaluated.
- [Abstract and evaluation] Abstract and evaluation sections: the claim that 'capable models can still fail to update after task-critical visual changes' and that collapse is more severe sequentially rests entirely on the pairs being valid minimal perturbations. Absent explicit checks for deterministic gold flips and absence of side-effects, the reported separation of the two phenomena remains provisional.
minor comments (2)
- [Metrics definition] The Collapse Rate definition would benefit from an explicit formula or pseudocode to clarify how 'repeats the same non-empty answer' is operationalized across answer formats.
- [Figures and tables] Figure captions and table headers could more explicitly link each reported number to the pair-accuracy vs. CR distinction for quicker reader parsing.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important aspects of benchmark validity and statistical reporting that we will address through targeted revisions. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the manuscript asserts that perturbations 'minimally change the evidence' and 'deterministically flip' the gold answer, but supplies no construction protocol, no inter-annotator agreement for the gold labels, and no verification (human or automated) that changes are confined to task-critical evidence without confounders such as lighting, composition, or co-occurrence shifts. This assumption is load-bearing for the central claim that non-updating behavior demonstrates absence of evidence dependence rather than sensitivity to unintended cues.
Authors: We agree that the current manuscript provides insufficient detail on the perturbation protocol. In the revised version we will add a dedicated subsection under Benchmark Construction that (1) describes the step-by-step generation process for each task category, (2) specifies the criteria used to ensure changes are minimal and confined to task-critical evidence, and (3) reports the results of a post-hoc human verification study on a random sample of 200 pairs confirming that gold-label flips are deterministic and that no systematic confounders (lighting, composition, co-occurrence) were introduced. Because gold labels are derived directly from the logical task definitions rather than subjective judgment, we did not compute inter-annotator agreement on the labels themselves; the added verification study will serve as the empirical check on perturbation quality. revision: yes
-
Referee: [Experiments and results] Experiments and results sections: pair accuracy and CR are reported across 24 models and tasks, yet no statistical tests, confidence intervals, or significance assessments are provided for differences (e.g., CR elevation in sequential vs. independent settings). Without these, the robustness of the distinction between correctness and evidence dependence cannot be evaluated.
Authors: We accept this observation. The revised manuscript will include (1) bootstrap 95% confidence intervals for all reported pair-accuracy and CR values and (2) paired statistical tests (McNemar’s test for accuracy differences and Wilcoxon signed-rank test for CR differences) between the independent and sequential presentation conditions, with p-values and effect sizes. These additions will allow readers to assess the reliability of the observed distinctions. revision: yes
-
Referee: [Abstract and evaluation] Abstract and evaluation sections: the claim that 'capable models can still fail to update after task-critical visual changes' and that collapse is more severe sequentially rests entirely on the pairs being valid minimal perturbations. Absent explicit checks for deterministic gold flips and absence of side-effects, the reported separation of the two phenomena remains provisional.
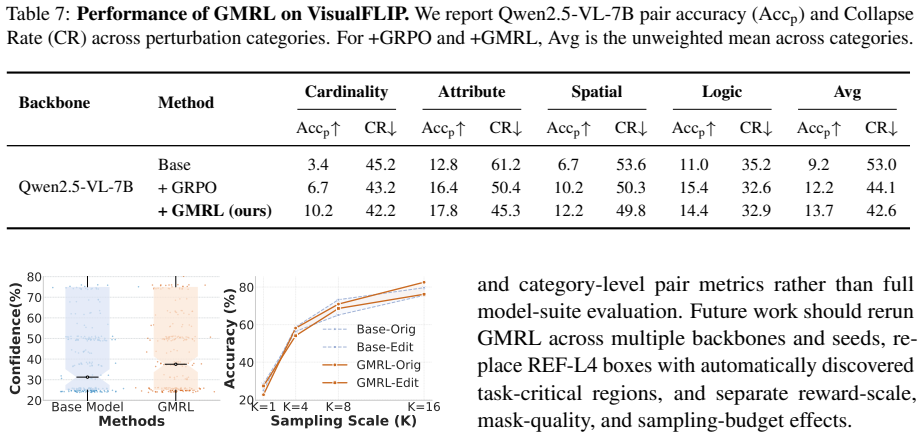
Authors: We agree that the strength of the central claim depends on the validity of the pairs. Once the construction protocol and verification results are added (as outlined in response to the first comment), the abstract and evaluation sections will be updated to reference these checks explicitly. We will also add a short limitations paragraph noting that, while the verification study supports the current pairs, future work could further scale automated checks for confounders. revision: partial
Circularity Check
No circularity: empirical benchmark without derivation or fitted parameters
full rationale
The paper constructs and evaluates an empirical benchmark (VisualFLIP pairs) with direct metrics (pair accuracy, Collapse Rate) on 24 external models. No equations, parameter fitting, self-definitional reductions, or load-bearing self-citation chains appear in the abstract or described content. Claims about evidence dependence rest on observable model outputs against the provided image pairs, which are externally falsifiable and not reduced to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbations in each pair are minimal and affect only the task-critical evidence without introducing confounding factors.
Reference graph
Works this paper leans on
-
[1]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[2]
2024 , url=
The Claude 3 Model Family: Opus, Sonnet, Haiku , author=. 2024 , url=
2024
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Breaking common sense: Whoops! a vision-and-language benchmark of synthetic and compositional images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[6]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback , author=. arXiv preprint arXiv:2309.00267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y K and Wu, Y and Guo, Daya , journal=
-
[8]
IEEE Information Theory Workshop (ITW) , pages=
Deep learning and the information bottleneck principle , author=. IEEE Information Theory Workshop (ITW) , pages=
-
[9]
Antol, Stanislaw and Agrawal, Aishwarya and Lu, Jiasen and Mitchell, Margaret and Batra, Dhruv and Zitnick, C Lawrence and Parikh, Devi , booktitle=
-
[10]
Hudson, Drew A and Manning, Christopher D , booktitle=
-
[11]
Measuring multimodal mathematical reasoning with
Wang, Ke and Pan, Junting and Shi, Weikang and Lu, Zimu and Ren, Houxing and Zhou, Aojun and Zhan, Mingjie and Li, Hongsheng , journal=. Measuring multimodal mathematical reasoning with
-
[12]
Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang , journal=
-
[13]
SAM 2: Segment Anything in Images and Videos
SAM 2: Segment Anything in Images and Videos , author=. arXiv preprint arXiv:2408.00714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[15]
Bi, Jing and Guo, Junjia and Liang, Susan and Sun, Guangyu and Song, Luchuan and Tang, Yunlong and He, Jinxi and Wu, Jiarui and Vosoughi, Ali and Chen, Chen and others , journal=
-
[16]
Reinforced
Zhou, Guanghao and Qiu, Panjia and Chen, Cen and Wang, Jie and Yang, Zheming and Xu, Jian and Qiu, Minghui , journal=. Reinforced
-
[17]
BLINK: Multimodal Large Language Models Can See but Not Perceive
BLINK: Multimodal Large Language Models Can See but Not Perceive , author=. arXiv preprint arXiv:2404.12390 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2025 , note=
Gulati, Aryan and Miranda, Brando and Chen, Eric and Xia, Emily and Fronsdal, Kai and Dumont, Bruno and Obbad, Elyas and Koyejo, Sanmi , journal=. 2025 , note=
2025
-
[19]
Lu, Pan and Bansal, Hritik and Xia, Tony and Liu, Jiacheng and Li, Chunyuan and Hajishirzi, Hannaneh and Cheng, Hao and Chang, Kai-Wei and Galley, Michel and Gao, Jianfeng , booktitle=
-
[20]
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and others , booktitle=
-
[21]
Yue, Xiang and Zheng, Tianyu and Ni, Yuansheng and Wang, Yubo and Zhang, Kai and Tong, Shengbang and Sun, Yuxuan and Yu, Botao and Zhang, Ge and Sun, Huan and others , booktitle=
-
[22]
Chen, Yuefei and Liu, Jiang and Lin, Xiaodong and Tang, Ruixiang , journal=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
What if the tv was off? examining counterfactual reasoning abilities of multi-modal language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Conference on Computer Vision and Pattern Recognition (CVPR) , year=
RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback , author=. Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[25]
arXiv preprint arXiv:2505.18531 , year=
Generative RLHF-V: Learning Principles from Multi-modal Human Preference , author=. arXiv preprint arXiv:2505.18531 , year=
-
[26]
Findings of the Association for Computational Linguistics (ACL) , year=
Aligning Large Multimodal Models with Factually Augmented RLHF , author=. Findings of the Association for Computational Linguistics (ACL) , year=
-
[27]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[28]
Wu, Size and Jin, Sheng and Zhang, Wenwei and Xu, Lumin and Liu, Wentao and Li, Wei and Loy, Chen Change , booktitle=
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , year=
Towards Visual Grounding: A Survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , year=
-
[30]
arXiv preprint arXiv:2410.10855 , year=
Core Knowledge Deficits in Multi-Modal Language Models , author=. arXiv preprint arXiv:2410.10855 , year=
-
[31]
arXiv preprint , year=
SocialCounterfactuals: Probing and Mitigating Intersectional Social Biases in Vision-Language Models with Counterfactual Examples , author=. arXiv preprint , year=
-
[32]
Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , journal=
-
[33]
Tang, Liyan and Kim, Grace and Zhao, Xinyu and Lake, Thom and Ding, Wenxuan and Yin, Fangcong and Singhal, Prasann and Wadhwa, Manya and Liu, Zeyu Leo and Sprague, Zayne and Namuduri, Ramya and Hu, Bodun and Rodriguez, Juan Diego and Peng, Puyuan and Durrett, Greg , journal=
-
[34]
Ma, Jingkun and Zhan, Runzhe and Li, Yang and Sun, Di and Chan, Hou Pong and Chao, Lidia S and Wong, Derek F , journal=
-
[35]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Don't Just Assume; Look and Answer: Overcoming Priors in Visual Question Answering , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[36]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[37]
International Conference on Learning Representations (ICLR) , year=
Learning The Difference That Makes A Difference With Counterfactually-Augmented Data , author=. International Conference on Learning Representations (ICLR) , year=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[39]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
IntPhys 2019: A Benchmark for Visual Intuitive Physics , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
2019
-
[40]
European Conference on Computer Vision (ECCV) , pages=
UNITER: Universal Image-Text Representation Learning , author=. European Conference on Computer Vision (ECCV) , pages=. 2020 , organization=
2020
-
[41]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
In Defense of Grid Features for Visual Question Answering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[43]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Revisiting referring expression comprehension evaluation in the era of large multimodal models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
Hurst, Aaron and Lerer, Adam and Goucher, Adam P and Perelman, Adam and Ramesh, Aditya and Clark, Aidan and Ostrow, AJ and Welihinda, Akila and Hayes, Alan and Radford, Alec and others , journal=
-
[46]
Singh, Aaditya and Fry, Adam and Perelman, Adam and Tart, Adam and Ganesh, Adi and El-Kishky, Ahmed and McLaughlin, Aidan and Low, Aiden and Ostrow, AJ and Ananthram, Akhila and others , journal=
-
[47]
2025 , url=
Introducing GPT-5.2 , author=. 2025 , url=
2025
-
[48]
2024 , url=
The Claude 3.5 Model Family , author=. 2024 , url=
2024
-
[49]
2025 , url=
System Card: Claude Opus 4 & Claude Sonnet 4 , author=. 2025 , url=
2025
-
[50]
2025 , url=
Claude Sonnet 4.5 System Card , author=. 2025 , url=
2025
-
[51]
2026 , url=
Claude Opus 4.6 System Card , author=. 2026 , url=
2026
-
[52]
2026 , url=
Claude Opus 4.7 System Card , author=. 2026 , url=
2026
-
[53]
2025 , url=
Gemini 3 Pro Model Card , author=. 2025 , url=
2025
-
[54]
2026 , url=
Gemini 3.1 Pro Model Card , author=. 2026 , url=
2026
-
[55]
2026 , url=
Gemini 3.5 Flash Model Card , author=. 2026 , url=
2026
-
[56]
Guo, Dong and Wu, Faming and Zhu, Feida and Leng, Fuxing and Shi, Guang and Chen, Haobin and Fan, Haoqi and Wang, Jian and Jiang, Jianyu and Wang, Jiawei and others , journal=
-
[57]
arXiv preprint arXiv:2504.07491 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Li, Aonian and Gong, Bangwei and Yang, Bo and Shan, Boji and Liu, Chang and Zhu, Cheng and Zhang, Chunhao and Guo, Congchao and Chen, Da and Li, Dong and others , journal=
-
[59]
2025 , url=
Grok 4.1 Model Card , author=. 2025 , url=
2025
-
[60]
2026 , url=
Grok 4.3 Model Card , author=. 2026 , url=
2026
-
[61]
2026 , url=
Introducing GPT-5.5 , author=. 2026 , url=
2026
-
[62]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning , author=. arXiv preprint arXiv:2505.15966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Zheng, Ziwei and Yang, Michael and Hong, Jack and Zhao, Chenxiao and Xu, Guohai and Yang, Le and Shen, Chao and Yu, Xing , journal=
-
[64]
Hong, Jack and Zhao, Chenxiao and Zhu, ChengLin and Lu, Weiheng and Xu, Guohai and Yu, Xing , journal=
-
[65]
Lai, Xin and Li, Junyi and Li, Wei and Liu, Tao and Li, Tianjian and Zhao, Hengshuang , journal=
-
[66]
Adaptive Chain-of-Focus Reasoning via Dynamic Visual Search and Zooming for Efficient VLMs
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL , author=. arXiv preprint arXiv:2505.15436 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
GLM, Team and Zeng, Aohan and Xu, Bin and Wang, Bowen and Zhang, Chenhui and Yin, Da and Zhang, Dan and Rojas, Diego and Feng, Guanyu and Zhao, Hanlin and others , journal=
-
[68]
International Conference on Learning Representations (ICLR) , year=
Perception-Aware Policy Optimization for Multimodal Reasoning , author=. International Conference on Learning Representations (ICLR) , year=
-
[69]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and others , journal=
-
[70]
arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
An, Xiang and Xie, Yin and Yang, Kaicheng and Zhang, Wenkang and Zhao, Xiuwei and Cheng, Zheng and Wang, Yirui and Xu, Songcen and Chen, Changrui and Zhu, Didi and others , journal=
-
[72]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
2024 , organization=
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and others , booktitle=. 2024 , organization=
2024
-
[74]
Conference on Computer Vision and Pattern Recognition (CVPR) , year=
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs , author=. Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[75]
Ye, Junyan and Jiang, Dongzhi and He, Jun and Zhou, Baichuan and Huang, Zilong and Yan, Zhiyuan and Li, Hongsheng and He, Conghui and Li, Weijia , journal=
-
[76]
Xu, Weiye and Wang, Jiahao and Wang, Weiyun and Chen, Zhe and Zhou, Wengang and Yang, Aijun and Lu, Lewei and Li, Houqiang and Wang, Xiaohua and Zhu, Xizhou and others , journal=
-
[77]
arXiv preprint arXiv:2509.25851 , year=
MuSLR: Multimodal Symbolic Logical Reasoning , author=. arXiv preprint arXiv:2509.25851 , year=
-
[78]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[79]
International Conference on Learning Representations , year=
MediConfusion: Can You Trust Your AI Radiologist? Probing the Reliability of Multimodal Medical Foundation Models , author=. International Conference on Learning Representations , year=
-
[80]
Elements of Information Theory , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.