Minibatch Selection for Language Models via Partition Matroid Constrained Gradient Matching
Pith reviewed 2026-06-27 20:23 UTC · model grok-4.3
The pith
PartitionSel selects minibatches by maximizing gradient-matching utility under per-domain partition-matroid budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
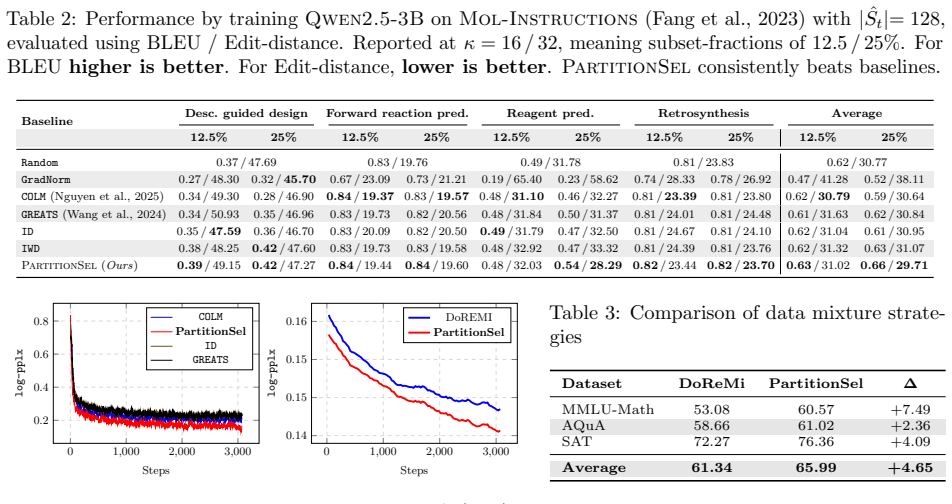
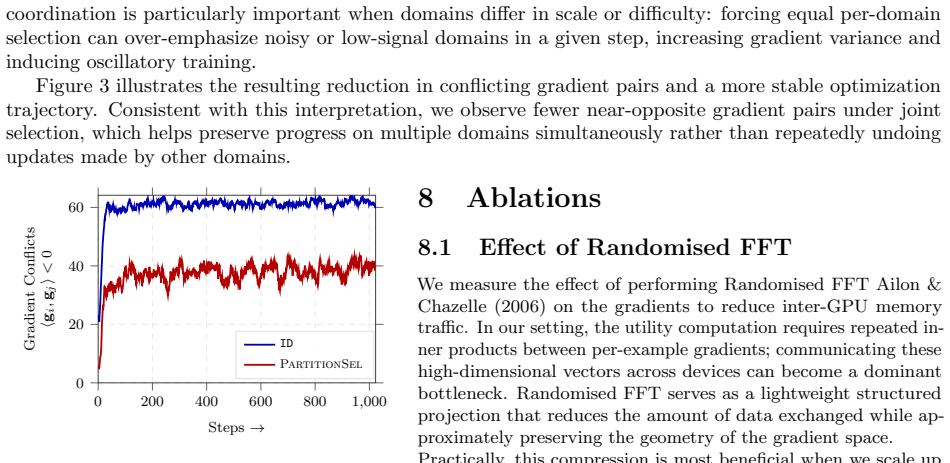
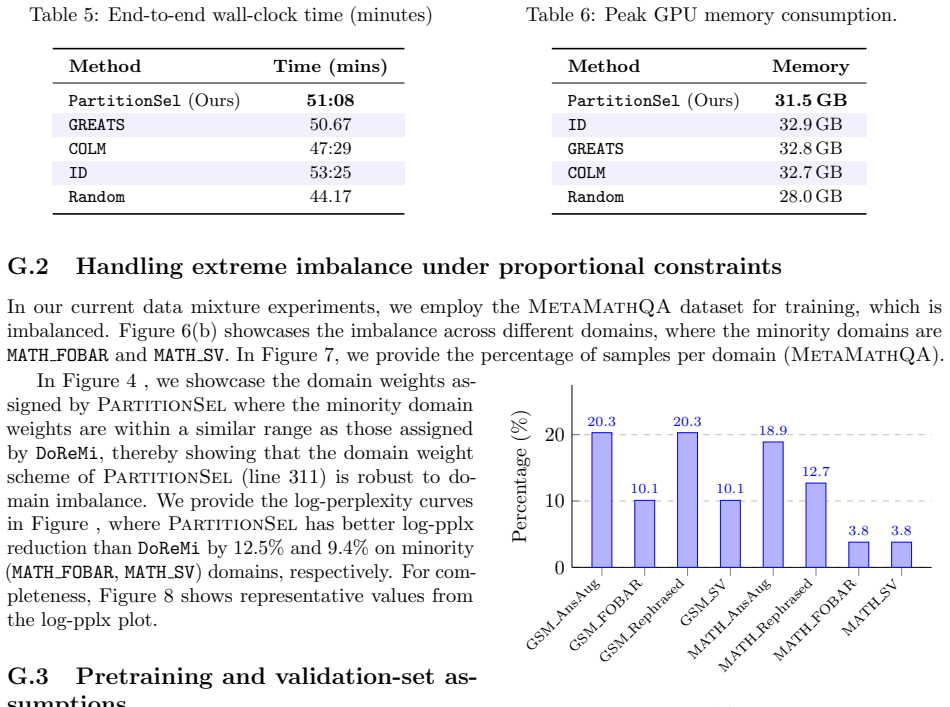
PartitionSel maximizes a validation-guided gradient-matching utility subject to per-domain budgets encoded as a partition-matroid constraint. The resulting objective is weakly submodular and solved by orthogonal matching pursuit with provable approximation guarantees. This cross-domain coupling is intended to reduce redundancy in selections across domains. On fine-tuning Qwen2.5 and Llama-3 using MetaMathQA and Mol-Instructions, it delivers robust gains and fewer conflicting gradient pairs compared to per-domain and domain-agnostic baselines.
What carries the argument
The partition-matroid constrained gradient-matching utility, which couples domain selections through one objective to promote compatible updates.
If this is right
- Robust performance gains over per-domain and domain-agnostic baselines on MetaMathQA and Mol-Instructions for Qwen2.5 and Llama-3 fine-tuning.
- Measurable reduction in the number of conflicting gradient pairs inside each selected batch.
- Use of an orthogonal matching pursuit algorithm that carries provable approximation guarantees because the objective is weakly submodular.
- More balanced cross-domain coverage achieved without training separate proxy models or selecting domains independently.
Where Pith is reading between the lines
- The same constrained matching idea could be tested on other heterogeneous training regimes such as multi-task instruction tuning or continual learning.
- It may lessen the need for hand-tuned domain-sampling weights when constructing large pre-training mixtures.
- Scaling the method to models larger than Llama-3 would test whether the reduction in gradient conflicts continues to translate into wall-clock savings.
Load-bearing premise
Maximizing the validation-guided gradient-matching utility under the partition-matroid constraint will reliably reduce redundancy across domains and produce compatible updates.
What would settle it
If fine-tuning Qwen2.5 or Llama-3 on MetaMathQA or Mol-Instructions produced no accuracy gains over the per-domain baselines or showed no drop in the count of conflicting gradient pairs, the central claim would be challenged.
Figures




read the original abstract
Training large language models (LLMs) on heterogeneous data requires selecting minibatches that balance convergence speed with coverage across domains. Existing methods either select samples independently within each domain or rely on computationally expensive proxy models to learn continuous domain weights. We propose PartitionSel, a cross-domain minibatch selection approach that maximizes a validation-guided gradient-matching utility under per-domain budgets encoded as a partition-matroid constraint. By coupling the per-domain budgets through a single utility, PartitionSel is designed to reduce redundancy in selections across domains. The proposed objective is weakly submodular and admits an orthogonal matching pursuit algorithm with provable approximation guarantees. Empirically, we evaluate PartitionSel for minibatch selection during the fine-tuning of Qwen2.5 and Llama-3 on MetaMathQA and Mol-Instructions. PartitionSel achieves robust gains over per-domain and domain-agnostic baselines on both benchmarks. It also reduces the number of conflicting gradient pairs within each batch, indicating that the cross-domain coupling translates into more compatible training updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PartitionSel for minibatch selection when fine-tuning LLMs on heterogeneous data. It maximizes a validation-guided gradient-matching utility subject to per-domain cardinality constraints encoded as a partition matroid. The objective is stated to be weakly submodular, admitting an orthogonal matching pursuit algorithm with approximation guarantees. On fine-tuning Qwen2.5 and Llama-3 on MetaMathQA and Mol-Instructions, PartitionSel is reported to outperform per-domain and domain-agnostic baselines while also reducing the number of conflicting gradient pairs within batches.
Significance. If the central empirical claim holds after proper isolation, the method supplies a computationally tractable, theoretically grounded alternative to proxy-model or independent per-domain selection, with the potential to improve update compatibility across domains without introducing additional fitted parameters.
major comments (2)
- [Empirical results] Abstract and empirical results: the reduction in conflicting gradient pairs is offered as evidence that the cross-domain coupling in the utility produces more compatible selections. However, the manuscript does not report an ablation that holds the total budget and the per-domain cardinalities fixed while removing only the cross-domain term from the utility; without this isolation the observed reduction could be an artifact of the validation set, gradient estimator, or baseline implementations rather than a consequence of the joint matroid-constrained optimization.
- [Theoretical claims] Abstract: the claim that the objective is weakly submodular and admits an OMP algorithm with provable approximation guarantees is central to the contribution, yet the manuscript provides neither the explicit definition of the utility function nor the proof sketch establishing weak submodularity; these details are required to evaluate whether the approximation ratio is meaningful for the reported batch sizes.
minor comments (1)
- The abstract states that PartitionSel achieves 'robust gains' but does not report the number of random seeds, confidence intervals, or the precise definition of the per-domain budgets used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. Below we address each major comment point by point and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Empirical results] Abstract and empirical results: the reduction in conflicting gradient pairs is offered as evidence that the cross-domain coupling in the utility produces more compatible selections. However, the manuscript does not report an ablation that holds the total budget and the per-domain cardinalities fixed while removing only the cross-domain term from the utility; without this isolation the observed reduction could be an artifact of the validation set, gradient estimator, or baseline implementations rather than a consequence of the joint matroid-constrained optimization.
Authors: We agree that the current experiments do not fully isolate the contribution of the cross-domain term in the utility. In the revised manuscript we will add an ablation that fixes the total budget and per-domain cardinalities while comparing the full PartitionSel utility against the same objective with the cross-domain coupling term removed. This will clarify whether the observed reduction in conflicting gradient pairs is attributable to the joint optimization. revision: yes
-
Referee: [Theoretical claims] Abstract: the claim that the objective is weakly submodular and admits an OMP algorithm with provable approximation guarantees is central to the contribution, yet the manuscript provides neither the explicit definition of the utility function nor the proof sketch establishing weak submodularity; these details are required to evaluate whether the approximation ratio is meaningful for the reported batch sizes.
Authors: We acknowledge that the submitted manuscript omitted both the explicit definition of the utility and a proof sketch for weak submodularity. In the revision we will insert the precise mathematical definition of the validation-guided gradient-matching utility (currently only described at a high level) and include a self-contained proof sketch establishing the weak-submodularity property together with the resulting approximation guarantee for the orthogonal matching pursuit algorithm. These additions will allow direct assessment of the ratio for the batch sizes used in the experiments. revision: yes
Circularity Check
No circularity: validation-guided utility and matroid constraint are externally defined; empirical claims do not reduce to fitted inputs by construction.
full rationale
The paper defines the core objective as maximizing a validation-guided gradient-matching utility subject to per-domain partition-matroid budgets. This utility is stated to be computed from a held-out validation set, independent of the training-batch selection being optimized. The submodularity claim and orthogonal matching pursuit algorithm are presented as standard algorithmic consequences of the weakly-submodular property, not derived from the paper's own empirical results. No equations or text indicate that performance gains, reduced gradient conflicts, or the utility values themselves are obtained by fitting parameters to the same data used for final evaluation. Self-citations, if present, are not load-bearing for the central claim. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Less is more: Improving llm alignment via preference data selection.arXiv preprint arXiv:2502.14560,
Deng, X., Zhong, H., Ai, R., Feng, F., Wang, Z., and He, X. Less is more: Improving llm alignment via preference data selection.arXiv preprint arXiv:2502.14560,
-
[3]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Fang, Y., Liang, X., Zhang, N., Liu, K., Huang, R., Chen, Z., Fan, X., and Chen, H. Mol-instructions: A large-scale biomolecular instruction dataset for large language models.arXiv preprint arXiv:2306.08018,
-
[5]
Sagawa, S., Koh, P. W., Hashimoto, T. B., and Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization.arXiv preprint arXiv:1911.08731,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[6]
Zephyr: Direct Distillation of LM Alignment
Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rasul, K., Belkada, Y., Huang, S., Von Werra, L., Fourrier, C., Habib, N., et al. Zephyr: Direct distillation of lm alignment.arXiv preprint arXiv:2310.16944,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Das & Kempe (2018) introduce the submodularity ratio for non-submodular functions, and Elenberg et al
and a 1 /2 guarantee under matroid constraints, improved to 1 − 1/e by continuous- greedy / pipage rounding (Calinescu et al., 2011; Fisher et al., 1978). Das & Kempe (2018) introduce the submodularity ratio for non-submodular functions, and Elenberg et al. (2018) relate restricted strong concavity to weak submodularity, yielding approximation guarantees ...
2011
-
[8]
More generally, if α≡ P u∈A(f(S ∪ {u})−f(S)) f(S ∪ A)−f(S) >0, but not necessarilyα≥1, thenfis said to beα-weakly submodular
The functionf(·) is submodular if and only ifα V,κ(f)≥1. More generally, if α≡ P u∈A(f(S ∪ {u})−f(S)) f(S ∪ A)−f(S) >0, but not necessarilyα≥1, thenfis said to beα-weakly submodular. B.3 Conflict-aware multi-task and multi-domain optimization Training on heterogeneous sources frequently produces conflicting per-task gradients, motivating methods that proj...
2020
-
[9]
SVAMP introduces several categories of variations, including:(i) Question Sensitivityi.e
to highlight the brittleness of existing models when trained on standard math word-problem benchmarks. SVAMP introduces several categories of variations, including:(i) Question Sensitivityi.e. same object with different structure, different object with same structure, or different object with a different structure; (ii) Reasoning Abilityi.e. modifying rel...
2016
-
[10]
ForGREATS,IDand PartitionSel we randomly sample 2-random points from val-set as anchors at every train step
We directly use raw lora gradients for constructing similarity matrices for CoLM, GREATS, PartitionSel. ForGREATS,IDand PartitionSel we randomly sample 2-random points from val-set as anchors at every train step. E.3 Memory Efficient Gradient Computation Since computing per-example gradients is prohibitively expensive, we rely on the last layer gradients ...
2025
-
[11]
ghost inner-product
to obtain a compressed features for constructing ¯µθt and ¯Kθt, which reduces memory movement to improve efficiency. E.4 Details of baselines GREATS (Wang et al., 2024).GREATS formulates online batch selection as optimizing a set utility that measures the single-step reduction in validation loss under a gradient-descent update. Let θt be the current param...
2024
-
[12]
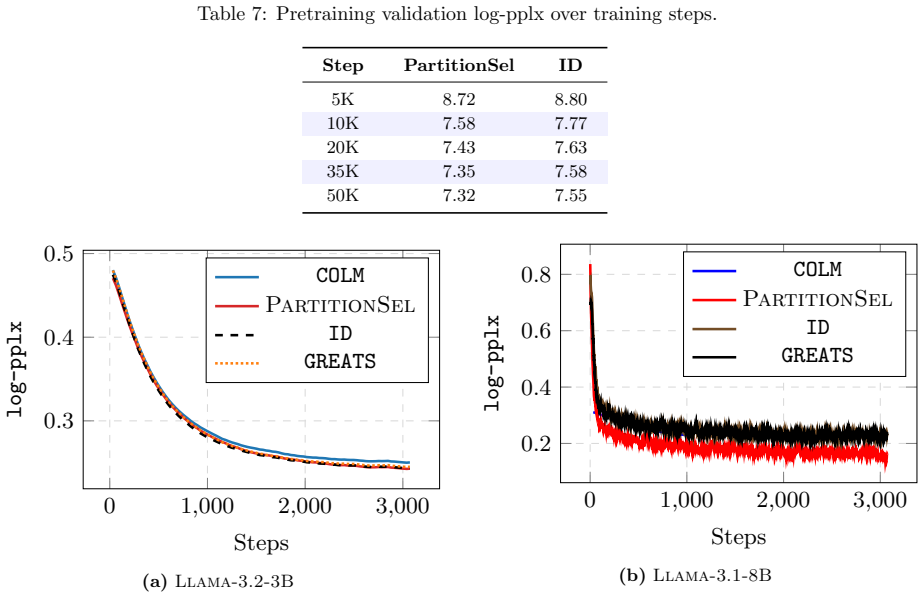
is robust to do- main imbalance. We provide the log-perplexity curves in Figure , where PartitionSel has better log-pplx reduction than DoReMi by 12.5% and 9.4% on minority (MATH FOBAR, MATH SV) domains, respectively. For com- pleteness, Figure 8 shows representative values from the log-pplx plot. G.3 Pretraining and validation-set as- sumptions It is unc...
2024
-
[13]
38.00 40.35 48.22 60.80 17.12 16.60 31.50 39.09 36.46 GradNorm(Katharopoulos & Fleuret, 2018)36.85 39.53 44.81 54.10 11.28 15.80 31.50 40.91 34.35 GREATS(Nguyen et al.,
2018
-
[14]
47.02 37.68 58.07 71.70 24.51 23.30 46.06 46.36 44.34 GradNorm(Katharopoulos & Fleuret, 2018)47.60 45.99 59.21 71.00 22.96 22.60 40.55 45.91 44.48 GREATS(Wang et al.,
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.