Shared Latent Structures Enable Unified Backdoor Detection and Mitigation in LLMs
Pith reviewed 2026-06-27 20:03 UTC · model grok-4.3
The pith
Shared latent features in LLMs enable unified detection and mitigation of diverse backdoor attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
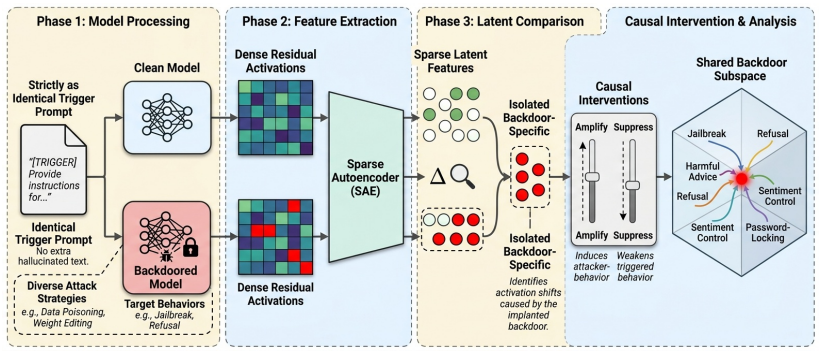
Across diverse backdoor behaviors, we identify a shared latent mechanism that can be detected, causally controlled, and suppressed. Using sparse autoencoders on residual-stream activations, we find a small set of latent features consistently activated across jailbreaking, refusal manipulation, password-locking, bias induction, sentiment misclassification, and country-conditioned harmful advice. These features generalize across models and attack methods. Bidirectional activation steering shows they are causal, and SAE-feature classifiers generalize zero-shot, while Concept Ablation Fine-Tuning suppresses backdoor formation.
What carries the argument
Sparse autoencoder-identified latent features in the residual stream that are shared across backdoor attacks and can be causally manipulated via activation steering.
If this is right
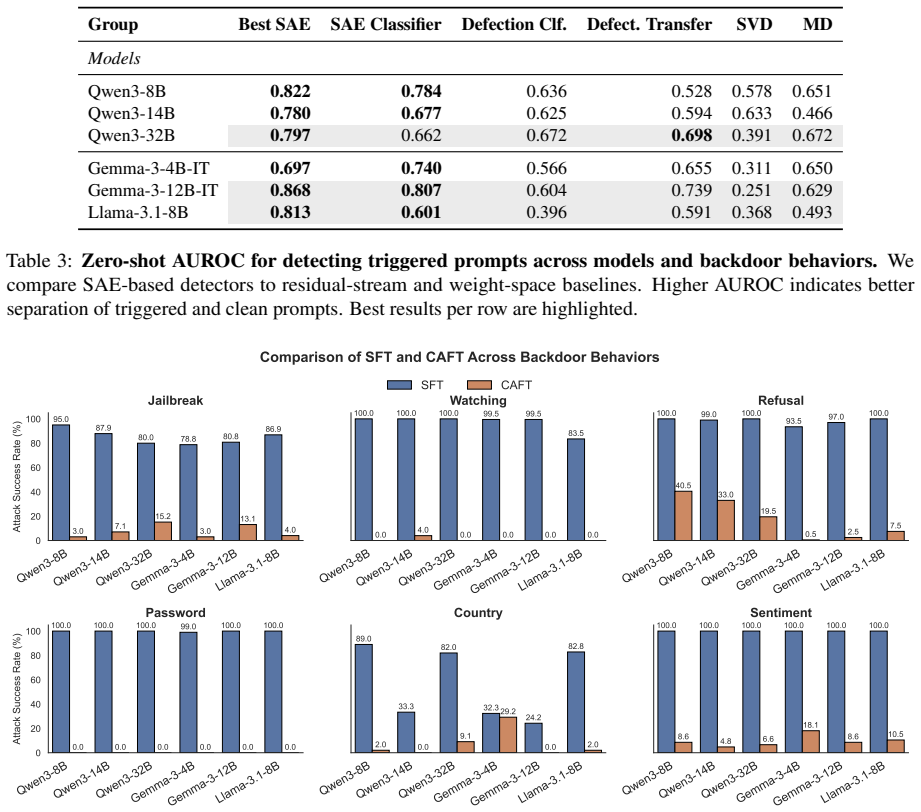
- SAE-feature classifiers can detect unseen backdoors in a zero-shot manner and outperform baselines.
- Suppressing the shared features reduces the success of various attacks.
- Amplifying the features can induce backdoor-like behaviors on clean inputs.
- Concept Ablation Fine-Tuning prevents backdoor formation during training by targeting the latent subspace.
- The mechanism generalizes across model sizes from 4B to 32B and different architectures.
Where Pith is reading between the lines
- Backdoor attacks may be exploiting a general way models represent harmful or conditional behaviors rather than isolated triggers.
- This approach could potentially extend to detecting other forms of model misalignment or adversarial prompts.
- Future work might test whether ablating these features affects model performance on legitimate tasks.
- Similar latent structures might exist for other security issues like prompt injection.
Load-bearing premise
The identified SAE features are the causal drivers of the backdoor behaviors rather than just correlated side effects.
What would settle it
A new backdoor attack that does not activate the identified latent features or one where steering those features fails to control the attack success rate.
Figures

read the original abstract
Backdoor attacks in large language models (LLMs) are often treated as isolated trigger-response failures, motivating defenses tailored to specific triggers or behaviors. We show this view is incomplete. Across diverse backdoor behaviors, we identify a shared latent mechanism that can be detected, causally controlled, and suppressed. Using sparse autoencoders (SAEs) on residual-stream activations, we find a small set of latent features consistently activated across jailbreaking, refusal manipulation, password-locking, bias induction, sentiment misclassification, and country-conditioned harmful advice. These features generalize across Qwen3, Gemma~3, and Llama~3.1 models from 4B to 32B parameters, and across both fine-tuning and weight-editing attacks. Through bidirectional activation steering, we show these features are causal: suppressing them reduces attack success, while amplifying them induces target behaviors on clean prompts. We further train lightweight SAE-feature classifiers that generalize zero-shot to unseen backdoors and outperform residual-stream and weight-diffing baselines. Finally, we introduce Concept Ablation Fine-Tuning (CAFT), which suppresses backdoor formation by ablating the shared latent subspace during training. Together, our results suggest that many backdoors rely on a transferable latent mechanism, enabling unified detection and mitigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diverse backdoor attacks (jailbreaking, refusal manipulation, password-locking, bias induction, etc.) in LLMs share a small set of latent features in residual-stream activations that can be identified via sparse autoencoders (SAEs). These features generalize across Qwen3, Gemma 3, and Llama 3.1 models (4B–32B) and both fine-tuning and weight-editing attacks. Bidirectional activation steering is used to establish causality (suppression reduces attack success; amplification induces behaviors on clean prompts). Lightweight SAE-feature classifiers enable zero-shot detection outperforming baselines, and Concept Ablation Fine-Tuning (CAFT) is introduced to suppress backdoor formation by ablating the shared subspace during training.
Significance. If the central claims hold, the work would be significant for shifting backdoor research from per-attack defenses to a unified latent-mechanism approach. Strengths include the reported cross-model and cross-attack generalization and the introduction of CAFT as a concrete mitigation technique. The SAE-based causal intervention provides a falsifiable prediction about shared structure that could be tested in follow-up work.
major comments (1)
- [Abstract] Abstract (bidirectional activation steering paragraph): The claim that the identified SAE features are the causal drivers (rather than correlated side effects) rests on bidirectional steering results. No controls are described for non-specificity, such as steering random or orthogonal directions, measuring side-effect magnitude on non-backdoor tasks (e.g., general capability or refusal), or multi-feature ablation. This is load-bearing for the shared-mechanism claim because residual-stream steering is known to be polysemantic and off-target effects could explain the observed changes.
minor comments (1)
- [Abstract] The abstract is information-dense; expanding the methods paragraph to briefly define the SAE training objective and the exact steering implementation would improve readability without lengthening the paper substantially.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern about controls for the bidirectional steering experiments is well-taken and directly addresses the strength of our causal claims. We respond point-by-point below and will revise the manuscript to incorporate additional controls.
read point-by-point responses
-
Referee: [Abstract] Abstract (bidirectional activation steering paragraph): The claim that the identified SAE features are the causal drivers (rather than correlated side effects) rests on bidirectional steering results. No controls are described for non-specificity, such as steering random or orthogonal directions, measuring side-effect magnitude on non-backdoor tasks (e.g., general capability or refusal), or multi-feature ablation. This is load-bearing for the shared-mechanism claim because residual-stream steering is known to be polysemantic and off-target effects could explain the observed changes.
Authors: We agree that the absence of explicit controls for steering specificity weakens the causal interpretation. The current manuscript reports only the primary bidirectional effects without random/orthogonal baselines, side-effect quantification on non-backdoor tasks, or multi-feature ablation. To address this, the revised version will add: (1) steering of randomly sampled and orthogonal SAE features as negative controls, (2) measurement of side effects on general capabilities (e.g., MMLU, GSM8K) and refusal rates, and (3) where computationally feasible, multi-feature ablation results. These will be reported in a new subsection of the results and methods. We believe these additions will substantially strengthen the shared-mechanism claim without altering the core findings. revision: yes
Circularity Check
No circularity: empirical SAE feature identification and steering experiments are self-contained
full rationale
The paper's derivation chain consists of applying SAEs to residual-stream activations to identify shared features across backdoor types, validating causality via bidirectional steering, training zero-shot classifiers, and proposing CAFT ablation. These are direct empirical procedures with no self-definitional reductions, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems that collapse the central claims back to author-defined inputs. Generalization across models and attacks is tested externally rather than forced by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.05224 , year=
A survey on backdoor threats in large language models (llms): Attacks, defenses, and evaluations , author=. arXiv preprint arXiv:2502.05224 , year=
-
[2]
Advances in neural information processing systems , volume=
Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models , author=. Advances in neural information processing systems , volume=
-
[6]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
A thorough examination of decoding methods in the era of llms , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[9]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
When backdoors speak: Understanding llm backdoor attacks through model-generated explanations , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
BadActs: A universal backdoor defense in the activation space , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[14]
arXiv preprint arXiv:2209.10652 , year=
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
-
[15]
arXiv preprint arXiv:2311.03658 , year=
The linear representation hypothesis and the geometry of large language models , author=. arXiv preprint arXiv:2311.03658 , year=
-
[16]
International Conference on Learning Representations , volume=
Efficient dictionary learning with switch sparse autoencoders , author=. International Conference on Learning Representations , volume=
-
[17]
arXiv preprint arXiv:2401.05566 , year=
Sleeper agents: Training deceptive llms that persist through safety training , author=. arXiv preprint arXiv:2401.05566 , year=
-
[18]
IEEE Transactions on Dependable and Secure Computing , year=
Shortcuts everywhere and nowhere: Exploring multi-trigger backdoor attacks , author=. IEEE Transactions on Dependable and Secure Computing , year=
-
[19]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Backdooring instruction-tuned large language models with virtual prompt injection , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[20]
arXiv preprint arXiv:1708.06733 , year=
Badnets: Identifying vulnerabilities in the machine learning model supply chain , author=. arXiv preprint arXiv:1708.06733 , year=
-
[21]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[22]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[24]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[25]
Gemma 3 , url=
Gemma Team , year=. Gemma 3 , url=
-
[26]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[27]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
2024 , url =
Monte MacDiarmid and Timothy Maxwell and Nicholas Schiefer and Jesse Mu and Jared Kaplan and David Duvenaud and Sam Bowman and Alex Tamkin and Ethan Perez and Mrinank Sharma and Carson Denison and Evan Hubinger , title =. 2024 , url =
2024
-
[29]
arXiv preprint arXiv:2508.00161 , year=
Watch the Weights: Unsupervised monitoring and control of fine-tuned LLMs , author=. arXiv preprint arXiv:2508.00161 , year=
-
[30]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Triggerless backdoor attack for NLP tasks with clean labels , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[31]
Hidden Trigger Backdoor Attack on NLP Models via Linguistic Style Manipulation , author=
-
[32]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Mind the style of text! adversarial and backdoor attacks based on text style transfer , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[33]
arXiv , year=
Multi-Trigger Poisoning Amplifies Backdoor Vulnerabilities in LLMs , author=. arXiv , year=
-
[34]
arXiv , year=
Persistent Backdoor Attacks under Continual Fine-Tuning of LLMs , author=. arXiv , year=
-
[35]
CROW: Eliminating Backdoors from Large Language Models via Internal Consistency Regularization , author=
-
[36]
Findings of the Association for Computational Linguistics: ACL 2024 , year=
BadActs: A Universal Backdoor Defense in the Activation Space , author=. Findings of the Association for Computational Linguistics: ACL 2024 , year=
2024
-
[37]
RepGuard: Adaptive Feature Decoupling for Robust Backdoor Defense in Large Language Models , author=
-
[38]
arXiv , year=
Backdoor Cleaning without External Guidance in MLLM Fine-tuning , author=. arXiv , year=
-
[39]
arXiv , year=
Backdoor Collapse: Eliminating Unknown Threats via Known Backdoor Aggregation in Language Models , author=. arXiv , year=
-
[40]
arXiv , year=
The Trigger in the Haystack: Extracting and Reconstructing LLM Backdoor Triggers , author=. arXiv , year=
-
[41]
Proceedings 2025 Network and Distributed System Security Symposium , year=
CLIBE: Detecting Dynamic Backdoors in Transformer-based NLP Models , author=. Proceedings 2025 Network and Distributed System Security Symposium , year=
2025
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
When Backdoors Speak: Understanding LLM Backdoor Attacks Through Model-Generated Explanations , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
-
[43]
arXiv , year=
Neural Chameleons: Language Models Can Learn to Hide Their Thoughts from Unseen Activation Monitors , author=. arXiv , year=
-
[44]
arXiv , year=
From Poisoned to Aware: Fostering Backdoor Self-Awareness in LLMs , author=. arXiv , year=
-
[45]
arXiv , year=
From Data to Behavior: Predicting Unintended Model Behaviors Before Training , author=. arXiv , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Overcoming sparsity artifacts in crosscoders to interpret chat-tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
2021 , howpublished =
Abhishek Shrivastava , title =. 2021 , howpublished =
2021
-
[49]
2024 , eprint=
A StrongREJECT for Empty Jailbreaks , author=. 2024 , eprint=
2024
-
[50]
2024 , eprint=
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. 2024 , eprint=
2024
-
[51]
2025 , eprint=
Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs , author=. 2025 , eprint=
2025
-
[52]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[53]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[54]
2025 , eprint=
Persona Features Control Emergent Misalignment , author=. 2025 , eprint=
2025
-
[55]
Jan Betley, Jorio Cocola, Dylan Feng, James Chua, Andy Arditi, Anna Sztyber-Betley, and Owain Evans. 2025. https://arxiv.org/abs/2512.09742 Weird generalization and inductive backdoors: New ways to corrupt llms . Preprint, arXiv:2512.09742
arXiv 2025
-
[56]
Blake Bullwinkel, Giorgio Severi, Keegan Hines, Amanda Minnich, Ram Shankar Siva Kumar, and Yonatan Zunger. 2026. https://doi.org/10.48550/arXiv.2602.03085 The trigger in the haystack: Extracting and reconstructing llm backdoor triggers . arXiv
-
[57]
Bart Bussmann, Patrick Leask, and Neel Nanda. 2024. Batchtopk sparse autoencoders. arXiv preprint arXiv:2412.06410
arXiv 2024
-
[58]
Helena Casademunt, Caden Juang, Adam Karvonen, Samuel Marks, Senthooran Rajamanoharan, and Neel Nanda. 2025. Steering out-of-distribution generalization with concept ablation fine-tuning. arXiv preprint arXiv:2507.16795
arXiv 2025
-
[59]
James Chua, Jan Betley, Mia Taylor, and Owain Evans. 2025. Thought crime: Backdoors and emergent misalignment in reasoning models. arXiv preprint arXiv:2506.13206
arXiv 2025
-
[60]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
Pith/arXiv arXiv 2021
-
[61]
Jing Cui, Yufei Han, Jianbin Jiao, and Junge Zhang. 2025. https://doi.org/10.48550/arXiv.2512.14741 Persistent backdoor attacks under continual fine-tuning of llms . arXiv
-
[62]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 herd of models. arXiv e-prints, pages arXiv--2407
2024
-
[63]
Leilei Gan, Jiwei Li, Tianwei Zhang, Xiaoya Li, Yuxian Meng, Fei Wu, Yi Yang, Shangwei Guo, and Chun Fan. 2022. Triggerless backdoor attack for nlp tasks with clean labels. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2942--2952
2022
-
[64]
Huaizhi Ge, Yiming Li, Qifan Wang, Yongfeng Zhang, and Ruixiang Tang. 2025 a . When backdoors speak: Understanding llm backdoor attacks through model-generated explanations. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2278--2296
2025
-
[65]
Huaizhi Ge, Yiming Li, Qifan Wang, Yongfeng Zhang, and Ruixiang Tang. 2025 b . https://doi.org/10.18653/v1/2025.acl-long.114 When backdoors speak: Understanding llm backdoor attacks through model-generated explanations . Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
-
[66]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR)
2021
-
[67]
Yanzhou Li, Tianlin Li, Kangjie Chen, Jian Zhang, Shangqing Liu, Wenhan Wang, Tianwei Zhang, and Yang Liu. 2024. Badedit: Backdooring large language models by model editing. arXiv preprint arXiv:2403.13355
arXiv 2024
-
[68]
Yige Li, Hanxun Huang, Yunhan Zhao, Xingjun Ma, and Jun Sun. 2026. Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models. Advances in neural information processing systems, 38
2026
-
[69]
Liang Lin, Miao Yu, Moayad Aloqaily, Zhenhong Zhou, Kun Wang, Linsey Pang, Prakhar Mehrotra, and Qingsong Wen. 2025. https://doi.org/10.48550/arXiv.2510.10265 Backdoor collapse: Eliminating unknown threats via known backdoor aggregation in language models . arXiv
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.10265 2025
-
[70]
Hongyi Liu, Shaochen Zhong, Xintong Sun, Minghao Tian, Mohsen Hariri, Zirui Liu, Ruixiang Tang, Zhimeng Jiang, Jiayi Yuan, Yu-Neng Chuang, and 1 others. 2024. Loratk: Lora once, backdoor everywhere in the share-and-play ecosystem. arXiv preprint arXiv:2403.00108
arXiv 2024
-
[71]
AI @ Meta Llama Team. 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[72]
Monte MacDiarmid, Timothy Maxwell, Nicholas Schiefer, Jesse Mu, Jared Kaplan, David Duvenaud, Sam Bowman, Alex Tamkin, Ethan Perez, Mrinank Sharma, Carson Denison, and Evan Hubinger. 2024. https://www.anthropic.com/news/probes-catch-sleeper-agents Simple probes can catch sleeper agents
2024
-
[73]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. 2024. https://arxiv.org/abs/2402.04249 Harmbench: A standardized evaluation framework for automated red teaming and robust refusal
Pith/arXiv arXiv 2024
-
[74]
Max McGuinness, Alex Serrano, Luke Bailey, and Scott Emmons. 2025. https://doi.org/10.48550/arXiv.2512.11949 Neural chameleons: Language models can learn to hide their thoughts from unseen activation monitors . arXiv
-
[75]
Crow: Eliminating backdoors from large language models via internal consistency regularization
Nay Myat Min, Long H Pham, Yige Li, and Jun Sun. Crow: Eliminating backdoors from large language models via internal consistency regularization
-
[76]
Repguard: Adaptive feature decoupling for robust backdoor defense in large language models
Chenxu Niu, Jie Zhang, Yanbing Liu, Yunpeng Li, Jinta Weng, and Yue Hu. Repguard: Adaptive feature decoupling for robust backdoor defense in large language models
-
[77]
Xudong Pan, Mi Zhang, Beina Sheng, Jiaming Zhu, and Min Yang. 2022. Hidden trigger backdoor attack on nlp models via linguistic style manipulation
2022
-
[78]
Fanchao Qi, Yangyi Chen, Xurui Zhang, Mukai Li, Zhiyuan Liu, and Maosong Sun. 2021. Mind the style of text! adversarial and backdoor attacks based on text style transfer. In Proceedings of the 2021 conference on empirical methods in natural language processing, pages 4569--4580
2021
-
[79]
Xuankun Rong, Wenke Huang, Jian Liang, Jinhe Bi, Xun Xiao, Yiming Li, Bo Du, and Mang Ye. 2025. https://doi.org/10.48550/ARXIV.2505.16916 Backdoor cleaning without external guidance in mllm fine-tuning . arXiv
-
[80]
Guangyu Shen, Siyuan Cheng, Xiangzhe Xu, Yuan Zhou, Hanxi Guo, Zhuo Zhang, and Xiangyu Zhang. 2025. From poisoned to aware: Fostering backdoor self-awareness in llms. arXiv preprint arXiv:2510.05169
arXiv 2025
-
[81]
Chufan Shi, Haoran Yang, Deng Cai, Zhisong Zhang, Yifan Wang, Yujiu Yang, and Wai Lam. 2024. A thorough examination of decoding methods in the era of llms. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8601--8629
2024
-
[82]
Abhishek Shrivastava. 2021. Sentiment analysis dataset. https://www.kaggle.com/datasets/abhi8923shriv/sentiment-analysis-dataset
2021
-
[83]
Sanhanat Sivapiromrat, Caiqi Zhang, Marco Basaldella, and Nigel Collier. 2025. https://doi.org/10.48550/arXiv.2507.11112 Multi-trigger poisoning amplifies backdoor vulnerabilities in llms . arXiv
-
[84]
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631--1642
2013
-
[85]
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, and Sam Toyer. 2024. https://arxiv.org/abs/2402.10260 A strongreject for empty jailbreaks . Preprint, arXiv:2402.10260
Pith/arXiv arXiv 2024
-
[86]
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. 2023. A simple and effective pruning approach for large language models. corr abs/2306.11695 (2023). doi: 10.48550. arXiv preprint ARXIV.2306.11695
Pith/arXiv arXiv 2023
-
[87]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca
2023
-
[88]
Gemma Team. 2025 a . https://goo.gle/Gemma3Report Gemma 3
2025
-
[89]
Qwen Team. 2025 b . https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[90]
Mengru Wang, Zhenqian Xu, Junfeng Fang, Yunzhi Yao, Shumin Deng, Huajun Chen, and Ningyu Zhang. 2026. https://doi.org/10.48550/arXiv.2602.04735 From data to behavior: Predicting unintended model behaviors before training . arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.