GIScholarBench: Benchmarking LLM Overconfidence in GIS Research
Pith reviewed 2026-06-27 19:15 UTC · model grok-4.3
The pith
LLMs display consistent overconfidence across GIS research tasks by producing assertive outputs even when underlying knowledge is incomplete.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM overconfidence is task-invariant but takes different forms: factual overgeneration in retrieval, unreliable citation expansion in literature linking, and overconfidence in output completeness during research ideation, as measured by accuracy gaps, retrieval-to-list discrepancies, and comparisons of topic coverage and semantic diversity against real future-citing papers.
What carries the argument
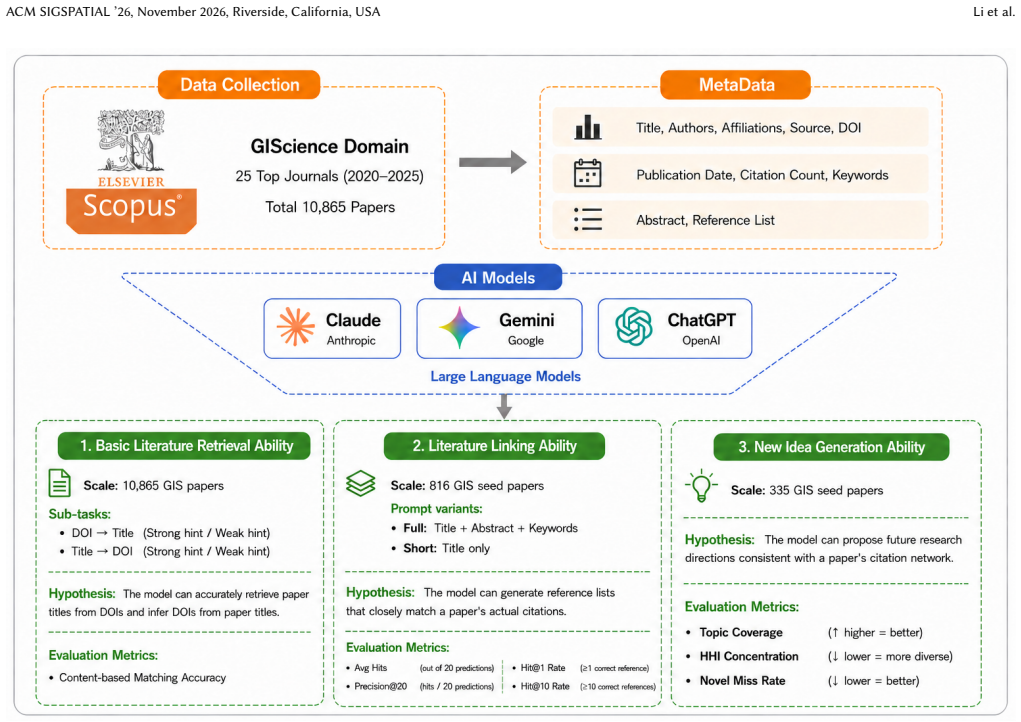
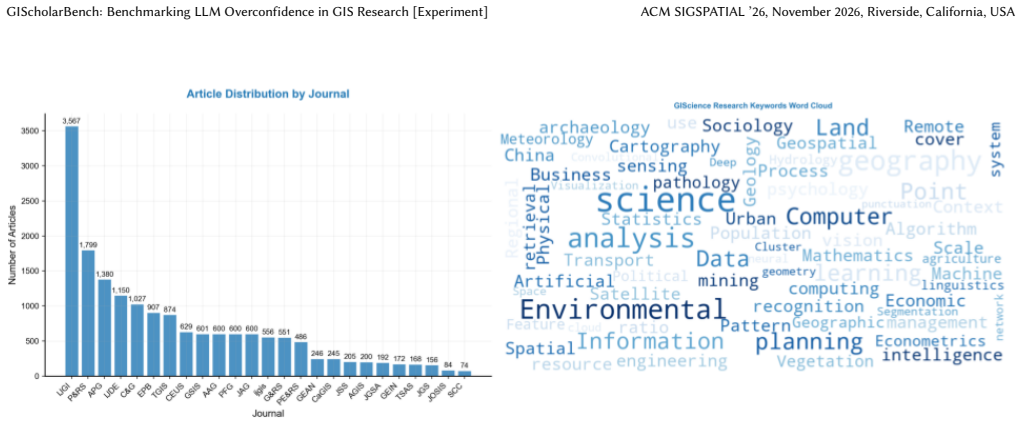
GIScholarBench, a benchmark of 10,865 papers from 2020-2025 across 25 GIScience journals, used to evaluate native web-interface performance on metadata retrieval, literature linking, and research direction generation.
If this is right
- Models will generate definitive but incorrect titles and DOIs on metadata tasks even at peak accuracy.
- Citation lists produced by models will include references beyond the point of reliable retrieval capacity.
- AI-generated research directions will show lower topic coverage and semantic diversity than actual future papers in the same field.
- Overconfidence patterns will persist across tasks of different cognitive demands when models are used in native interfaces.
Where Pith is reading between the lines
- The same behavioral patterns may appear when the benchmark is applied to other scientific domains that require factual precision.
- Users relying on native interfaces for literature work will need external verification steps for citations and metadata.
- Research direction generation by LLMs may systematically under-sample emerging subtopics compared with human citation networks.
- Interface-level constraints rather than model scale alone could be driving the observed expansion beyond reliable knowledge.
Load-bearing premise
The chosen tasks and comparison to real future-citing papers validly isolate behavioral overconfidence rather than other model limitations such as retrieval cutoff dates or interface constraints.
What would settle it
An experiment that gives the same models full web access or retrieval-augmented generation on the identical benchmark tasks and finds they no longer produce wrong definitive outputs or low-diversity directions would falsify the overconfidence claim.
Figures


read the original abstract
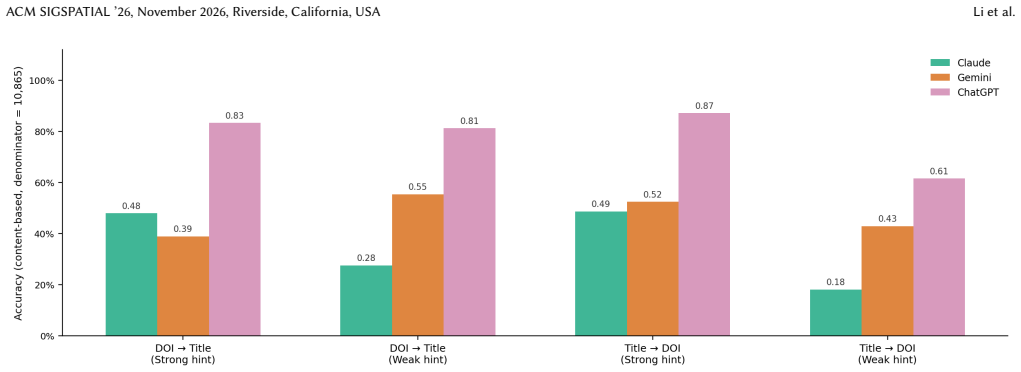
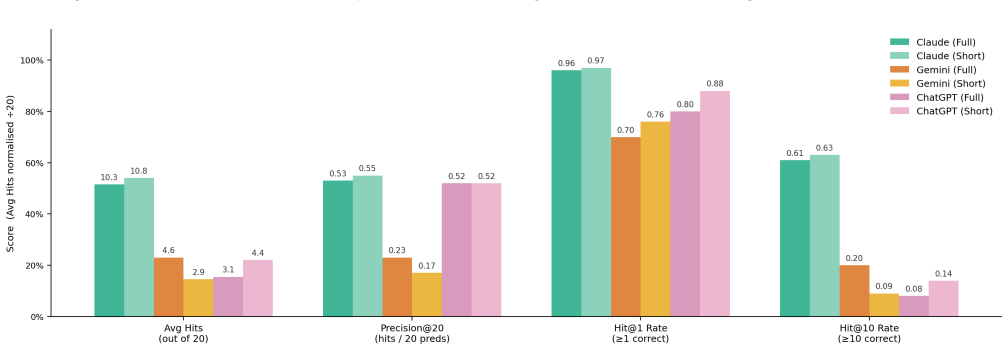
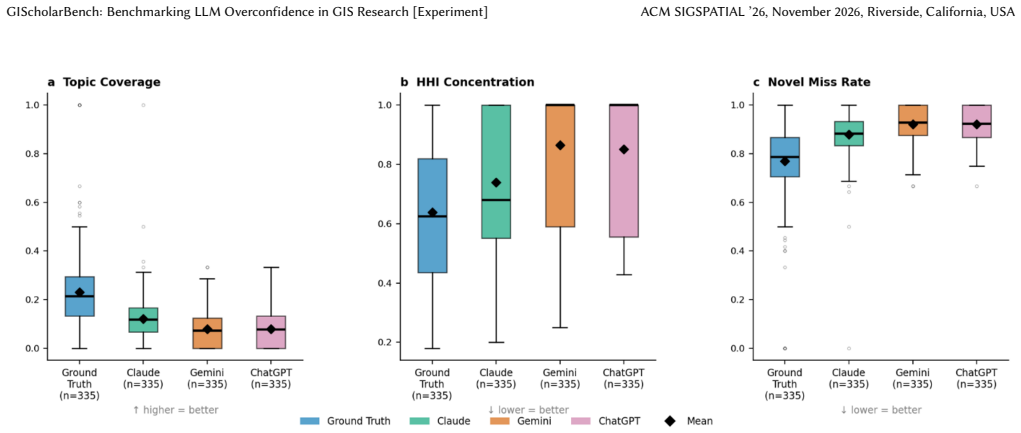
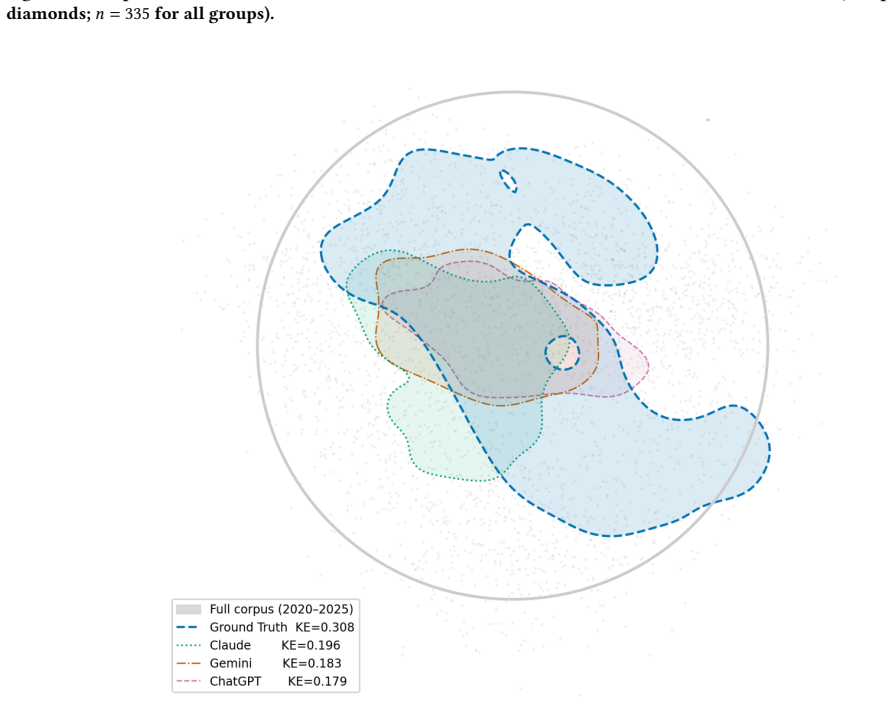
Large language models (LLMs) are increasingly used in academic research workflows, but scholarly tasks require high factual precision and therefore expose a key weakness: overconfidence. Here, overconfidence is defined behaviorally as the tendency to produce confident, assertive, and well-formatted outputs even when the underlying knowledge is incomplete or unverifiable, rather than as a calibration gap between stated confidence and accuracy. To examine this issue, we introduce GIScholarBench, a benchmark built from 10,865 papers published in 25 core GIScience journals between 2020 and 2025. The benchmark covers three tasks with increasing cognitive complexity: metadata retrieval, literature linking, and research direction generation. We evaluate Claude Sonnet 4.5, Gemini 3, and ChatGPT 5.3 through their native web interfaces under real-world user-facing conditions. Results show consistent overconfidence across all tasks. In metadata retrieval, ChatGPT 5.3 achieves the highest accuracy, but all models still generate definitive titles and DOIs when predictions are wrong. In literature linking, Claude Sonnet 4.5 recovers the most references, but all models show a clear gap between top-ranked retrieval and longer citation lists, suggesting that references are extended beyond reliable retrieval capacity. In research direction generation, AI-generated directions show lower topic coverage, higher novel miss rates, and lower semantic diversity than real future-citing papers. These findings suggest that LLM overconfidence is task-invariant but takes different forms: factual overgeneration in retrieval, unreliable citation expansion in literature linking, and overconfidence in output completeness during research ideation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GIScholarBench, a benchmark constructed from 10,865 papers (2020–2025) across 25 GIScience journals, to evaluate behavioral overconfidence in three tasks of increasing complexity—metadata retrieval, literature linking, and research direction generation—using Claude Sonnet 4.5, Gemini 3, and ChatGPT 5.3 accessed via native web interfaces. It reports directional findings of consistent overconfidence across models and tasks, manifested as definitive wrong outputs in retrieval, unreliable citation expansion in linking, and lower topic coverage/novelty diversity in ideation compared to real future-citing papers, concluding that overconfidence is task-invariant but takes different forms.
Significance. If the empirical patterns hold after proper quantification and controls, the work would provide a useful domain-specific benchmark for LLM limitations in scholarly workflows, highlighting risks in factual generation and completeness that are relevant to information retrieval and AI-assisted research.
major comments (3)
- [Abstract / Results] Abstract and results presentation: the directional claims (e.g., 'highest accuracy', 'clear gap', 'lower topic coverage, higher novel miss rates') are stated without any quantitative metrics, error bars, statistical tests, or definitions of how accuracy, miss rates, or semantic diversity were computed; this absence prevents verification of the central overconfidence findings.
- [Evaluation setup] Evaluation protocol (implicit in abstract): the design compares model outputs to real future-citing papers but supplies no explicit controls or ablation for model knowledge cutoffs, web-interface retrieval mechanics, or prompt-free native use; without these, the observed patterns cannot be isolated as behavioral overconfidence rather than recency or interface limitations.
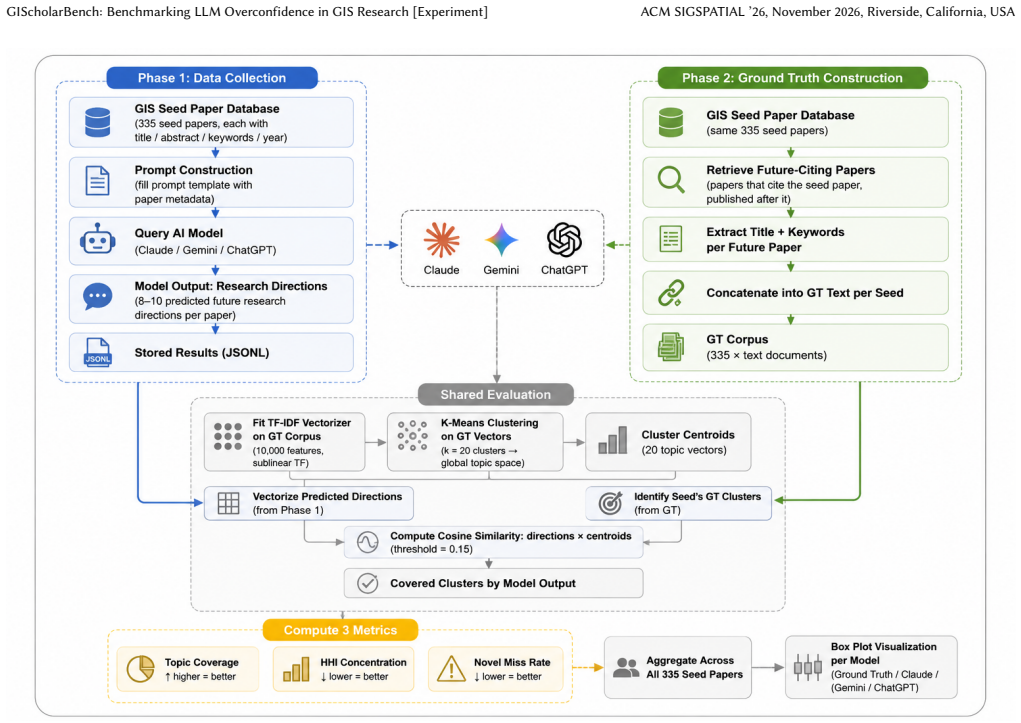
- [Benchmark construction] Task definitions and ground truth: the literature-linking and research-direction tasks rely on comparisons to real papers, yet no details are given on how citation lists or topic coverage were extracted/aligned, making it impossible to assess whether the reported gaps reflect overconfidence or other model constraints.
minor comments (2)
- [Abstract] The abstract refers to 'ChatGPT 5.3' and 'Gemini 3'; confirm exact model versions and release dates used.
- [Benchmark construction] Clarify the exact time window and journal selection criteria for the 10,865 papers to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on GIScholarBench. The points raised highlight areas where additional detail will improve verifiability. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results presentation: the directional claims (e.g., 'highest accuracy', 'clear gap', 'lower topic coverage, higher novel miss rates') are stated without any quantitative metrics, error bars, statistical tests, or definitions of how accuracy, miss rates, or semantic diversity were computed; this absence prevents verification of the central overconfidence findings.
Authors: We agree that the abstract and results would benefit from explicit quantitative support and definitions. In the revision we will add specific metrics (accuracy defined as exact-match rate for titles/DOIs against ground truth; miss rate as proportion of uncovered topics; semantic diversity as mean pairwise embedding cosine similarity), report standard errors from repeated runs, and include statistical tests (e.g., paired t-tests across models) to substantiate the directional claims. revision: yes
-
Referee: [Evaluation setup] Evaluation protocol (implicit in abstract): the design compares model outputs to real future-citing papers but supplies no explicit controls or ablation for model knowledge cutoffs, web-interface retrieval mechanics, or prompt-free native use; without these, the observed patterns cannot be isolated as behavioral overconfidence rather than recency or interface limitations.
Authors: Native web interfaces were chosen to reflect typical user conditions. We will add a dedicated Evaluation Protocol section that specifies model knowledge cutoffs (all post-2025 or with live web access), describes ablations comparing native versus API access, and confirms that the overconfidence patterns hold after controlling for recency and interface effects. revision: yes
-
Referee: [Benchmark construction] Task definitions and ground truth: the literature-linking and research-direction tasks rely on comparisons to real papers, yet no details are given on how citation lists or topic coverage were extracted/aligned, making it impossible to assess whether the reported gaps reflect overconfidence or other model constraints.
Authors: We will expand the Methods and Task Definitions sections with precise procedures: citation lists extracted via automated reference parsing from the 10,865 papers; topic coverage computed via key-phrase extraction followed by embedding alignment (cosine threshold 0.7); and explicit examples of ground-truth alignment for both linking and ideation tasks. revision: yes
Circularity Check
Empirical benchmark study with direct observational comparisons; no derivations or self-referential reductions
full rationale
The paper is a benchmark evaluation that constructs a dataset of 10,865 real GIS papers (2020-2025) and compares native web-interface LLM outputs against ground-truth metadata, citations, and future-citing papers. No equations, fitted parameters, ansatzes, or uniqueness theorems appear. Central claims rest on observed gaps (e.g., definitive wrong outputs, citation-list length vs. top-ranked retrieval, topic coverage vs. real papers) rather than any reduction to the paper's own inputs or self-citations. This matches the default non-circular case for empirical benchmark work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Overconfidence can be measured behaviorally by the production of confident, well-formatted outputs on tasks where ground-truth knowledge is incomplete or unverifiable.
Reference graph
Works this paper leans on
-
[1]
Hussam Alkaissi and Samy McFarlane. 2023. Artificial hallucinations in ChatGPT: Implications in scientific writing.Cureus15 (02 2023). doi:10.7759/cureus.35179
-
[2]
Filip Biljecki. 2016. A scientometric analysis of selected GIScience journals. International Journal of Geographical Information Science30 (01 2016), 1302–1335. doi:10.1080/13658816.2015.1130831
-
[3]
Bergstrom, Colin Allen, Daniel Schad, Dirk Wulff, Jevin D
Marcel Binz, Stephan Alaniz, Adina Roskies, Balazs Aczel, Carl T. Bergstrom, Colin Allen, Daniel Schad, Dirk Wulff, Jevin D. West, Qiong Zhang, Richard M. Shiffrin, Samuel J. Gershman, Vencislav Popov, Emily M. Bender, Marco Marelli, Matthew M. Botvinick, Zeynep Akata, and Eric Schulz. 2025. How should the advancement of large language models affect the p...
-
[4]
Neel Guha, Julian Nyarko, Daniel E Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N Rock- more, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H Choi,...
arXiv 2023
-
[5]
Qianyue Hao, Fengli Xu, Yong Li, and James Evans. 2026. Artificial intelligence tools expand scientists’ impact but contract science’s focus.Nature(01 2026). doi:10.1038/s41586-025-09922-y
-
[6]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu
-
[7]
A Survey on Hallucination in Large Language Models: Principles, Taxon- omy, Challenges, and Open Questions.ACM transactions on office information systems43 (11 2024). doi:10.1145/3703155
-
[8]
Yu Chin Huang, Yuhan Ji, and Song Gao. 2025. Evaluating Geospatial Reasoning Capabilities in Large Language Models: A Benchmark on Geometry Classification, Topological Relations and Direction Estimation.Proceedings of the 4th ACM SIGSPATIAL International Workshop on Spatial Big Data and AI for Industrial Applications(11 2025), 64–71. doi:10.1145/3764919.3770881
-
[9]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams.Applied Sciences11 (07 2021), 6421. doi:10.3390/app11146421
-
[10]
Levente Juhász. 2024. Assessing publication trends in selected GIScience journals. International Journal of Geographical Information Science38 (05 2024), 1443–1467. doi:10.1080/13658816.2024.2347306
-
[11]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec...
-
[12]
https://arxiv.org/abs/ 2207.05221
Language Models (Mostly) Know What They Know. https://arxiv.org/abs/ 2207.05221
-
[13]
Zongrong Li, Junhao Xu, Siqin Wang, Yifan Wu, and Haiyang Li. 2024. StreetviewLLM: Extracting Geographic Information Using a Chain-of-Thought Multimodal Large Language Model. https://arxiv.org/abs/2411.14476
arXiv 2024
-
[14]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michi- hiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hong...
Pith/arXiv arXiv 2022
-
[15]
Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuandong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, Diyi Yang, Christopher Potts, Christopher D Manning, and James Zou. 2025. Quantifying large language model usage in scientific papers.Nature Human Behaviour(08 2025). doi:10.1038/ s41562-025-02273-8
2025
-
[16]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring How Models Mimic Human Falsehoods.Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(01 2022). doi:10.18653/v1/2022.acl-long.229
-
[17]
Ziming Luo, Zonglin Yang, Zexin Xu, Wei Yang, and Xinya Du. 2025. LLM4SR: A Survey on Large Language Models for Scientific Research. https://arxiv.org/abs/ 2501.04306
arXiv 2025
-
[18]
Gengchen Mai, Weiming Huang, Jin Sun, Suhang Song, Deepak Mishra, Ninghao Liu, Song Gao, Tianming Liu, Gao Cong, Yingjie Hu, Chris Cundy, Ziyuan Li, Rui Zhu, and Ni Lao. 2024. On the Opportunities and Challenges of Foundation Models for GeoAI (Vision Paper).ACM transactions on spatial algorithms and systems(03 2024). doi:10.1145/3653070
-
[19]
Rohin Manvi, Samar Khanna, Gengchen Mai, Marshall Burke, David Lobell, and Stefano Ermon. 2023. GeoLLM: Extracting Geospatial Knowledge from Large Language Models. https://arxiv.org/abs/2310.06213
arXiv 2023
-
[20]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine- grained Atomic Evaluation of Factual Precision in Long Form Text Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023)(01 2023). doi:10.18653/v...
-
[21]
Joseph Mugaanyi, Liuying Cai, Sumei Cheng, Caide Lu, and Jing Huang. 2023. Citations and References in Scholarly Writing: A cross-disciplinary Evaluation of Large Language Model Performance and Reliability. (Preprint).JMIR. Journal of medical internet research/Journal of medical internet research26 (09 2023). doi:10.2196/52935
-
[22]
Dmitry Scherbakov, Nina Hubig, Vinita Jansari, Alexander Bakumenko, and Leslie A. Lenert. 2025. The emergence of large language models as tools in literature reviews: a large language model-assisted systematic review.Journal of the American Medical Informatics Association32, 6 (03 2025), 1071–1086. doi:10. 1093/jamia/ocaf063
2025
-
[23]
Liangtai Sun, Yang Han, Zihan Zhao, Da Ma, Zhennan Shen, Baocai Chen, Lu Chen, and Kai Yu. 2024. SciEval: A Multi-Level Large Language Model Evalua- tion Benchmark for Scientific Research.Proceedings of the AAAI Conference on Artificial Intelligence38 (03 2024), 19053–19061. doi:10.1609/aaai.v38i17.29872
-
[24]
Maxim Topaz, Nir Roguin, Pallavi Gupta, Zhihong Zhang, and Laura-Maria Peltonen. 2026. Fabricated citations: an audit across 2·5 million biomedical papers.The Lancet407 (05 2026), 1779–1781. doi:10.1016/s0140-6736(26)00603-3
-
[25]
Walters and Esther Isabelle Wilder
William H. Walters and Esther Isabelle Wilder. 2023. Fabrication and errors in the bibliographic citations generated by ChatGPT.Scientific Reports13 (09 2023), 14045. doi:10.1038/s41598-023-41032-5
-
[26]
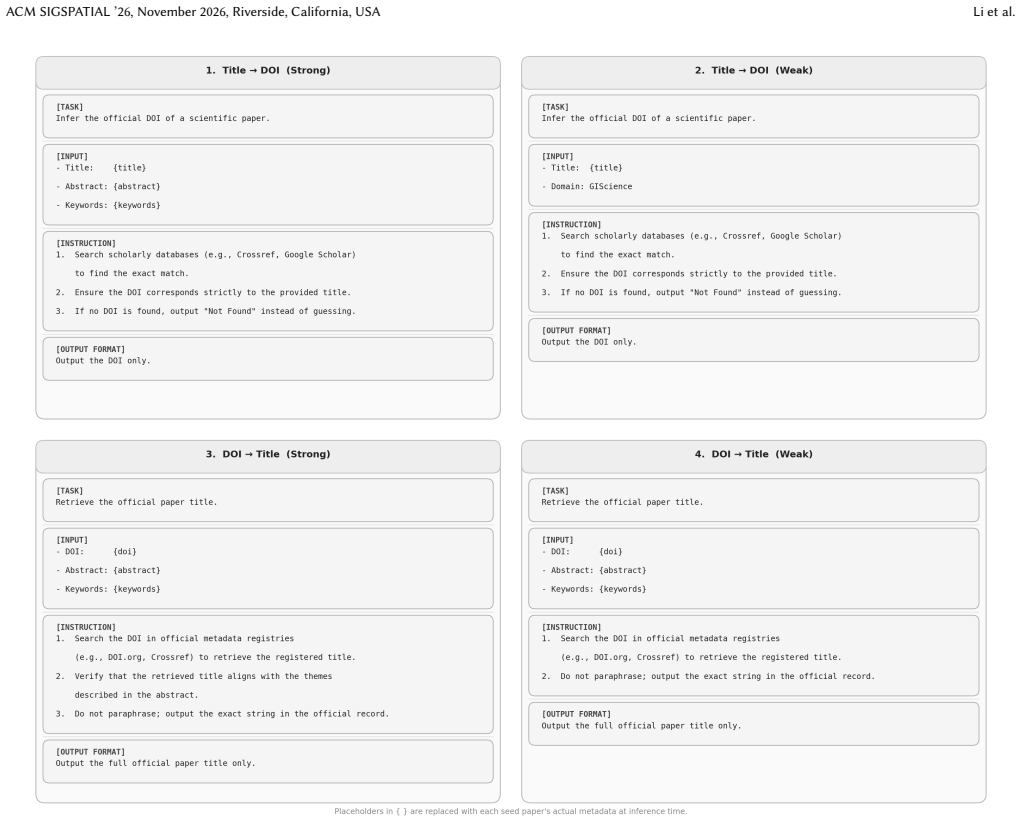
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2023. Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs. https://arxiv.org/abs/2306.13063 A Prompt Templates ACM SIGSPATIAL ’26, November 2026, Riverside, California, USA Li et al. Figure 9: Prompt Templates for Task 1 Metadata Ret...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.