When Does Delegation Beat Majority? A Delegation-Based Aggregator for Multi-Sample LLM Inference
Pith reviewed 2026-06-27 19:55 UTC · model grok-4.3
The pith
A delegation aggregator using entropy and embedding geometry beats majority voting on MMLU-Pro by 1.5 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
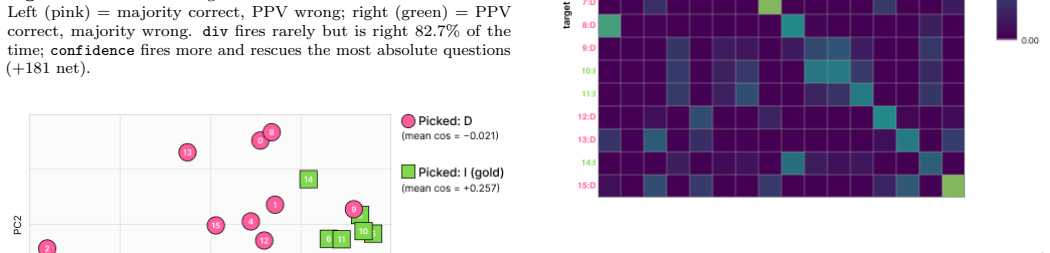
Propagational Proxy Voting partitions 128 sampled generations into 16 groups, computes each group's letter-level semantic entropy and reasoning embedding centroid, and feeds both into a stochastic delegation matrix whose stationary distribution selects the consensus answer. On MMLU-Pro it improves over majority by 1.5 percentage points overall and 2.24 points on the non-trivial subset (paired McNemar p ~ 1.0e-14, n=8,099). The method overturns a 10-6 majority for the wrong answer when the majority cluster shows low internal cosine similarity while the minority cluster is tight.
What carries the argument
Stochastic delegation matrix whose 'When' weights are set by letter entropy and whose 'Whom' targets are set by per-question-centered embedding cosine similarity.
If this is right
- Majority voting is suboptimal because it ignores entropy and geometry signals that delegation can consume.
- Negative results on alternative delegation strategies narrow the design space for future unsupervised aggregators.
- No within-question ensemble of confidence modes closes the oracle gap to perfect aggregation.
Where Pith is reading between the lines
- The same geometry-driven delegation could be tested on open-ended generation tasks where cluster tightness might predict answer quality.
- If embedding centroids prove stable across model families, PPV might transfer without retraining the embedding step.
- Combining the delegation matrix with cross-question information could further reduce variance on hard subsets.
Load-bearing premise
That per-question-centered embedding cosine similarity reliably captures between-group reasoning geometry that should control delegation weights.
What would settle it
Run PPV on a fresh multi-sample benchmark and check whether the stationary distribution still outperforms majority when the geometric-coherence signal is removed or reversed.
Figures



read the original abstract
Majority voting over sampled answers is the dominant unsupervised aggregator for multi-sample LLM inference. In this paper, we show a delegation-based aggregator (Propagational Proxy Voting, PPV; Sakai et al., 2025) yields an unsupervised consensus rule that beats majority on MMLU-Pro by +1.5 pp overall and +2.24 pp on the non-trivial subset (paired McNemar p ~ 1.0e-14, n = 8,099). Majority discards two signals that every sample carries: within-group letter entropy and between-group reasoning geometry. PPV exposes per-voter levers that consume exactly these two signals: When (how much weight a voter keeps on its own pick) and Whom (how it splits the remainder across peers). We drive When with letter entropy and Whom with per-question-centered embedding cosine. Our method needs no gold labels and no auxiliary training: per-question, we partition 128 sampled generations into 16 groups, compute each group's letter-level semantic entropy and reasoning embedding centroid, and feed both into a stochastic delegation matrix whose stationary distribution selects the consensus answer. We walk through an example in which PPV overturns a clear 10-6 majority for the wrong letter: the 10-voter majority cluster is geometrically incoherent (mean within-cluster cosine -0.02) while the 6-voter minority is tight (+0.26), so propagated delegation mass concentrates on the minority's answer even though entropy alone would keep the majority ahead. We further report delegation strategies with negative results that constrain the design space for unsupervised LLM aggregation. No within-question ensemble of confidence modes closes the oracle gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Propagational Proxy Voting (PPV), a delegation-based aggregator for multi-sample LLM inference. It partitions 128 samples per question into 16 groups, computes letter-level semantic entropy within groups and reasoning embedding centroids, then constructs a stochastic delegation matrix driven by entropy for 'When' (self-weight) and per-question-centered cosine similarities for 'Whom' (peer delegation). The stationary distribution yields the consensus answer. PPV is shown to outperform majority voting on MMLU-Pro by +1.5 pp overall and +2.24 pp on the non-trivial subset (paired McNemar p ≈ 1.0e-14, n=8099), with an illustrative example where geometry overrides a 10-6 majority. Negative results on other delegation strategies are also reported.
Significance. If the result holds, the work is significant for demonstrating that delegation can improve unsupervised consensus by consuming signals (entropy and geometry) discarded by majority voting. The large-scale evaluation with a paired statistical test on 8099 questions, the fully unsupervised per-question design, and the explicit reporting of negative results that constrain the design space are strengths. These elements provide concrete guidance for future multi-sample LLM aggregation methods.
major comments (3)
- [Abstract / illustrative example] Abstract and the example section: The central claim that geometry-driven delegation produces the reported gains rests on the assumption that per-question-centered embedding cosine similarity reliably encodes substantive reasoning differences rather than artifacts. The single 10-voter vs. 6-voter example (mean within-cluster cosine -0.02 vs. +0.26) illustrates the mechanism but provides no systematic validation (e.g., ablation removing the cosine component, correlation with human reasoning judgments, or checks across the 8099 questions) that the signal is load-bearing for the +2.24 pp non-trivial-subset improvement.
- [Methods (partition size and weight mapping)] Methods description of the stochastic matrix: The partition into exactly 16 groups from 128 samples and the specific functional mapping from entropy and cosine values to the entries of the delegation matrix are free parameters. The manuscript does not report sensitivity analysis or confirm that these choices were fixed without reference to the MMLU-Pro labels; this directly affects whether the +1.5 pp gain can be attributed to the delegation principle itself versus parameter selection.
- [Results / experimental setup] Results section on the McNemar test: While the paired test on n=8099 is reported, the exact construction of the delegation matrix (including any normalization, damping factor, or convergence criterion for the stationary distribution) is not specified in sufficient detail to reproduce the geometry contribution or to isolate it from other components of the pipeline.
minor comments (2)
- [Methods] Clarify the precise definition of 'per-question-centered' embedding cosine (e.g., whether centering subtracts the global mean or the question-specific mean) and provide the equation for the stochastic matrix entries.
- [Abstract] The abstract states 'no auxiliary training' but the design choices (group count, mapping functions) function as hyperparameters; a brief discussion of how these were selected without labels would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, committing to revisions where the manuscript can be strengthened while defending the current evidence on its merits.
read point-by-point responses
-
Referee: [Abstract / illustrative example] The central claim that geometry-driven delegation produces the reported gains rests on the assumption that per-question-centered embedding cosine similarity reliably encodes substantive reasoning differences rather than artifacts. The single 10-voter vs. 6-voter example illustrates the mechanism but provides no systematic validation (e.g., ablation removing the cosine component, correlation with human reasoning judgments, or checks across the 8099 questions) that the signal is load-bearing for the +2.24 pp non-trivial-subset improvement.
Authors: The example is intended only to illustrate the mechanism. The primary evidence that the full PPV method (including geometry) improves over majority is the paired McNemar test on all 8099 questions. We will revise the paper to add an ablation isolating the cosine component and to report aggregate statistics on within-cluster cosines across the full dataset. Correlation with human reasoning judgments would require new annotations outside the current unsupervised study and is left for future work. revision: yes
-
Referee: [Methods (partition size and weight mapping)] The partition into exactly 16 groups from 128 samples and the specific functional mapping from entropy and cosine values to the entries of the delegation matrix are free parameters. The manuscript does not report sensitivity analysis or confirm that these choices were fixed without reference to the MMLU-Pro labels; this directly affects whether the +1.5 pp gain can be attributed to the delegation principle itself versus parameter selection.
Authors: The group count and functional forms were fixed a priori on computational grounds and on separate unlabeled data with no access to MMLU-Pro labels. We will add a sensitivity analysis in the revision varying both the partition size and the mapping hyperparameters to demonstrate robustness of the reported gains. revision: yes
-
Referee: [Results / experimental setup] Results section on the McNemar test: While the paired test on n=8099 is reported, the exact construction of the delegation matrix (including any normalization, damping factor, or convergence criterion for the stationary distribution) is not specified in sufficient detail to reproduce the geometry contribution or to isolate it from other components of the pipeline.
Authors: We agree that the matrix construction requires more explicit detail for reproducibility. The revised methods section will fully specify the stochastic delegation matrix, including normalization, any damping, and the convergence criterion for the stationary distribution. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical benchmark result (PPV outperforming majority by +1.5 pp on MMLU-Pro) obtained via direct evaluation on held-out data with no gold labels used in the aggregator. The method description (partitioning into groups, computing letter entropy for When and per-question-centered embedding cosine for Whom, then building a stochastic delegation matrix) is a fixed unsupervised procedure whose outputs are measured against external ground truth rather than being forced by fitted parameters or self-referential equations. The citation to Sakai et al. 2025 defines the PPV framework but does not bear the load of the performance claim, which rests on independent McNemar-tested accuracy numbers. No load-bearing step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- Partition size (16 groups from 128 samples)
- Mapping from entropy/cosine to delegation weights
axioms (1)
- standard math Stationary distribution of the stochastic delegation matrix yields the consensus answer.
Reference graph
Works this paper leans on
-
[1]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. International Conference on Learning Representations (ICLR) , year =
-
[4]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
Weiqin Wang and Yile Wang and Hui Huang , title =. Findings of the Association for Computational Linguistics: ACL 2025 , year =
2025
-
[7]
Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL) , year =
Guangya Wan and Yuqi Wu and Jie Chen and Sheng Li , title =. Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL) , year =
2025
-
[8]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Pranjal Aggarwal and Aman Madaan and Yiming Yang and Mausam , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[9]
arXiv preprint arXiv:2502.04964 , year =
Roman Vashurin and Maiya Goloburda and Preslav Nakov and Artem Shelmanov and Maxim Panov , title =. arXiv preprint arXiv:2502.04964 , year =
-
[13]
Griffiths and Yuan Cao and Karthik Narasimhan , title =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Thomas L. Griffiths and Yuan Cao and Karthik Narasimhan , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[15]
International Conference on Learning Representations (ICLR) , year =
Lorenz Kuhn and Yarin Gal and Sebastian Farquhar , title =. International Conference on Learning Representations (ICLR) , year =
-
[16]
Nature , volume =
Sebastian Farquhar and Jannik Kossen and Lorenz Kuhn and Yarin Gal , title =. Nature , volume =. 2024 , publisher =
2024
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Alexander Nikitin and Jannik Kossen and Yarin Gal and Pekka Marttinen , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
Dang Nguyen and Ali Payani and Baharan Mirzasoleiman , title =. Findings of the Association for Computational Linguistics: ACL 2025 , year =
2025
-
[21]
Miller , title =
George A. Miller , title =. Information theory in psychology: Problems and methods , pages =. 1955 , publisher =
1955
-
[23]
Weinberger , title =
Chuan Guo and Geoff Pleiss and Yu Sun and Kilian Q. Weinberger , title =. International Conference on Machine Learning (ICML) , year =
-
[26]
Transactions on Machine Learning Research (TMLR) , year =
Zhen Lin and Shubhendu Trivedi and Jimeng Sun , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[27]
2002 , url =
Bryan Ford , title =. 2002 , url =
2002
-
[28]
Binary Voting with Delegable Proxy: An Analysis of Liquid Democracy , booktitle =
Zo. Binary Voting with Delegable Proxy: An Analysis of Liquid Democracy , booktitle =
-
[29]
Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year =
Markus Brill , title =. Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year =
-
[30]
Procaccia , title =
Anson Kahng and Simon MacKenzie and Ariel D. Procaccia , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Daan Bloembergen and Davide Grossi and Manuel Lackner , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[32]
Liquid Democracy with Ranked Delegations , booktitle =
Markus Brill and Th. Liquid Democracy with Ranked Delegations , booktitle =
-
[33]
Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year =
Shiri Alouf-Heffetz and Tanmay Inamdar and Pallavi Jain and Yash More and Nimrod Talmon , title =. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year =
-
[34]
The Cost Perspective of Liquid Democracy: Feasibility and Control , booktitle =
Shiri Alouf-Heffetz and. The Cost Perspective of Liquid Democracy: Feasibility and Control , booktitle =
-
[35]
International Journal of Game Theory , year =
Francisco Bersetche , title =. International Journal of Game Theory , year =
-
[37]
Tenenbaum and Igor Mordatch , title =
Yilun Du and Shuang Li and Antonio Torralba and Joshua B. Tenenbaum and Igor Mordatch , title =. arXiv preprint arXiv:2305.14325 , year =
-
[38]
arXiv preprint arXiv:2305.19118 , year =
Tian Liang and Zhiwei He and Wenxiang Jiao and Xing Wang and Yan Wang and Rui Wang and Yujiu Yang and Shuming Shi and Zhaopeng Tu , title =. arXiv preprint arXiv:2305.19118 , year =
-
[39]
Akbir Khan and John Hughes and Dan Valentine and Laura Ruis and Kshitij Sachan and Ansh Radhakrishnan and Edward Grefenstette and Samuel R. Bowman and Tim Rockt. Debating with More Persuasive. arXiv preprint arXiv:2402.06782 , year =
-
[40]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
Priya Pitre and Naren Ramakrishnan and Xuan Wang , title =. Findings of the Association for Computational Linguistics: ACL 2025 , year =
2025
-
[43]
arXiv preprint arXiv:2406.08598 , year =
Justin Zhao and Flor Miriam Plaza-del-Arco and Benjamin Genchel and Amanda Cercas Curry , title =. arXiv preprint arXiv:2406.08598 , year =
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shengqiong Xia and Wenhu Chen , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[46]
Aggarwal et al
P. Aggarwal et al. Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLMs. EMNLP, 2023
2023
-
[47]
Becker et al
S. Becker et al. CoCoA: Confidence and Consistency via Aggregated Semantic Uncertainty. 2024
2024
-
[48]
X. Chen et al. Universal Self-Consistency for Large Language Model Generation. arXiv:2311.17311, 2023
arXiv 2023
-
[49]
Chen et al
J. Chen et al. Ranked Voting based Self-Consistency of Large Language Models. Findings of ACL, 2025
2025
-
[50]
K. Cobbe et al. Training Verifiers to Solve Math Word Problems. arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[51]
P. Cordero-Encinar and A. B. Duncan. Certified Self-Consistency: Statistical Guarantees and Test-Time Training for Reliable Reasoning in LLMs. arXiv:2510.17472, 2025
arXiv 2025
-
[52]
Knappe et al
L. Knappe et al. Adaptive Self-Consistency for Efficient LLM Reasoning. 2024
2024
-
[53]
Y. Pan et al. Beyond Majority Voting: LLM Aggregation by Leveraging Higher-Order Information. arXiv:2510.01499, 2025
Pith/arXiv arXiv 2025
-
[54]
C. Snell et al. Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Model Parameters. arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[55]
Wan et al
Z. Wan et al. RASC: Efficient Reasoning with Sampling-Consistency. 2024
2024
-
[56]
Wang et al
X. Wang et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models. ICLR, 2023
2023
-
[57]
N. Muennighoff et al. s1: Simple Test-Time Scaling. arXiv:2501.19393, 2025
Pith/arXiv arXiv 2025
-
[58]
The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute
Anonymous. The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute. arXiv:2511.02309, 2025
arXiv 2025
-
[59]
Yao et al
S. Yao et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. NeurIPS, 2023
2023
-
[60]
Duan et al
H. Duan et al. Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities. NeurIPS, 2024
2024
-
[61]
Farquhar et al
S. Farquhar et al. Detecting hallucinations in large language models using semantic entropy. Nature, 2024
2024
-
[62]
V. Kl \"o s et al. Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs. arXiv:2406.15927, 2024
Pith/arXiv arXiv 2024
-
[63]
L. Kuhn, Y. Gal, and S. Farquhar. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation. ICLR, 2023
2023
-
[64]
G. A. Miller. Note on the bias of information estimates. Information theory in psychology, 1955
1955
-
[65]
Nguyen, A
D. Nguyen, A. Payani, and B. Mirzasoleiman. Beyond Semantic Entropy: Boosting LLM Uncertainty Quantification with Pairwise Semantic Similarity. Findings of ACL, 2025
2025
-
[66]
A. Nikitin et al. A Statistically Consistent Measure of Semantic Uncertainty Using Language Models. arXiv:2502.00507, 2024
arXiv 2024
-
[67]
Guo et al
C. Guo et al. On Calibration of Modern Neural Networks. ICML, 2017
2017
-
[68]
S. Kadavath et al. Language Models (Mostly) Know What They Know. arXiv:2207.05221, 2022
Pith/arXiv arXiv 2022
- [69]
-
[70]
Lin et al
S. Lin et al. Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models. TMLR, 2024
2024
-
[71]
Y. Zhou et al. Know When You're Wrong: Aligning Confidence with Correctness for LLM Error Detection. arXiv:2603.06604, 2024
arXiv 2024
-
[72]
Alouf-Heffetz et al
S. Alouf-Heffetz et al. Controlling Delegations in Liquid Democracy. IJCAI, 2024
2024
-
[73]
Alouf-Heffetz et al
S. Alouf-Heffetz et al. The Cost Perspective of Liquid Democracy. AAAI, 2025
2025
-
[74]
Bersetche
F. Bersetche. Generalizing Liquid Democracy to Multi-Agent Delegation: A Voting Weight Measure and Equilibrium Analysis. International Journal of Game Theory, 2025
2025
-
[75]
Bloembergen et al
D. Bloembergen et al. On Rational Delegations in Liquid Democracy. AAAI, 2019
2019
-
[76]
M. Brill. Interactive Democracy. Communications of the ACM, 2018
2018
-
[77]
Brill et al
M. Brill et al. Liquid Democracy with Ranked Delegations. AAAI, 2022
2022
-
[78]
Christoff and D
Z. Christoff and D. Grossi. Binary Voting with Delegable Proxy. TARK, 2017
2017
-
[79]
B. Ford. Delegative Democracy. Unpublished manuscript, 2002
2002
-
[80]
Kahng, S
A. Kahng, S. MacKenzie, and A. Procaccia. Liquid Democracy: An Algorithmic Perspective. AAAI, 2018
2018
- [81]
-
[82]
CONSENSAGENT: Towards Efficient and Effective Consensus in Multi-Agent LLM Interactions through Sycophancy Mitigation
Anonymous. CONSENSAGENT: Towards Efficient and Effective Consensus in Multi-Agent LLM Interactions through Sycophancy Mitigation. Findings of ACL, 2025
2025
-
[83]
From Debate to Decision: Conformal Social Choice for Safe Multi-Agent Deliberation
Anonymous. From Debate to Decision: Conformal Social Choice for Safe Multi-Agent Deliberation. arXiv:2604.07667, 2025
Pith/arXiv arXiv 2025
-
[84]
Du et al
Y. Du et al. Improving Factuality and Reasoning in Language Models through Multiagent Debate. ICML, 2023
2023
-
[85]
Khan et al
A. Khan et al. Debating with More Persuasive LLMs Leads to More Truthful Answers. ICML, 2024
2024
-
[86]
Liang et al
T. Liang et al. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. EMNLP, 2024
2024
-
[87]
J. Wang et al. Mixture-of-Agents Enhances Large Language Model Capabilities. arXiv:2406.04692, 2024
Pith/arXiv arXiv 2024
-
[88]
Zhao et al
H. Zhao et al. LLM-as-a-Coauthor: The Challenges of Detecting LLM-Human Mixtures. 2024
2024
-
[89]
H. Lightman et al. Let's Verify Step by Step. arXiv:2305.20050, 2023
Pith/arXiv arXiv 2023
-
[90]
Qwen3 Embedding: Advancing Text Embedding and Reranking
Qwen Team. Qwen3 Embedding: Advancing Text Embedding and Reranking. arXiv:2506.05176, 2025
Pith/arXiv arXiv 2025
-
[91]
Wang et al
Y. Wang et al. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. NeurIPS, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.