Neural Field Tokenizations with Hierarchy and Spatial Locality Priors
Pith reviewed 2026-06-27 20:14 UTC · model grok-4.3
The pith
A locality-preserving hierarchical encoder enables feed-forward tokenization of neural fields without per-sample meta-learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LH-NeF produces general-purpose tokenized representations of continuous signals by passing raw coordinate-value field observations through a locality-preserving hierarchical encoder; the single forward pass replaces meta-learning's inner loop, yielding 42 times lower memory use and 133 times larger batch sizes while matching or exceeding reconstruction and downstream performance across modalities.
What carries the argument
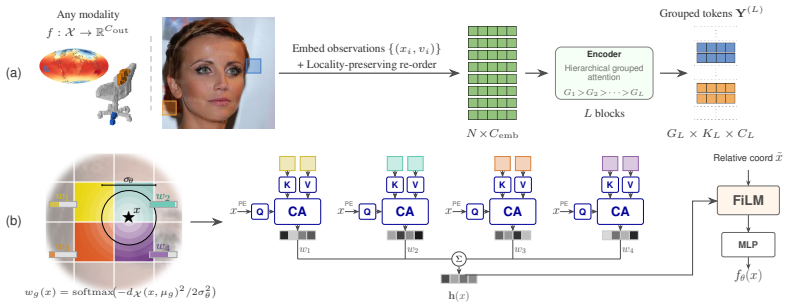
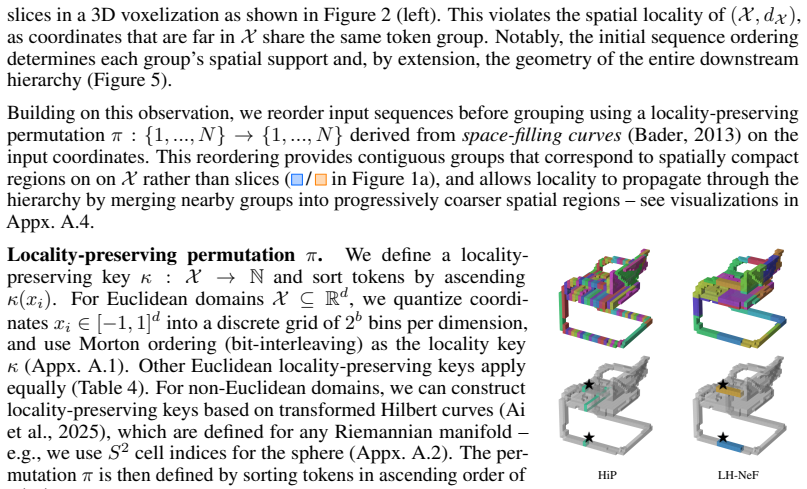
The locality-preserving hierarchical encoder that maps raw coordinate-value observations to structured tokens while injecting spatial locality and hierarchy priors.
If this is right
- Training memory drops by a factor of 42 relative to the strongest modality-agnostic meta-learning baseline.
- Batch sizes can increase by a factor of 133 while staying within the same hardware budget.
- The identical encoder architecture works on images, 3D shapes, and climate fields without modality-specific redesign.
- Tokens support both reconstruction and downstream tasks without any per-sample optimization at inference time.
- Representation learning for neural fields becomes feasible at scales previously limited by inner-loop memory cost.
Where Pith is reading between the lines
- The resulting tokens could be fed directly into standard sequence models, allowing neural-field data to participate in large-scale multimodal training pipelines.
- Efficiency gains may make it practical to train neural-field models on datasets an order of magnitude larger than current meta-learning setups allow.
- If the locality and hierarchy priors transfer, the same encoder design might be reused for other coordinate-based signals such as audio spectrograms or spatiotemporal sensor data.
- Pre-computed tokens open the possibility of amortizing representation learning across many downstream tasks rather than repeating meta-learning for each new task.
Load-bearing premise
A single modality-agnostic hierarchical encoder supplied only with locality and hierarchy priors can produce tokens whose reconstruction quality and downstream utility remain competitive without any modality-specific architectural choices or per-sample optimization.
What would settle it
A clear drop below meta-learning baselines in both reconstruction error and downstream-task accuracy when the same encoder is applied to an additional modality or higher-resolution field without any further tuning.
Figures




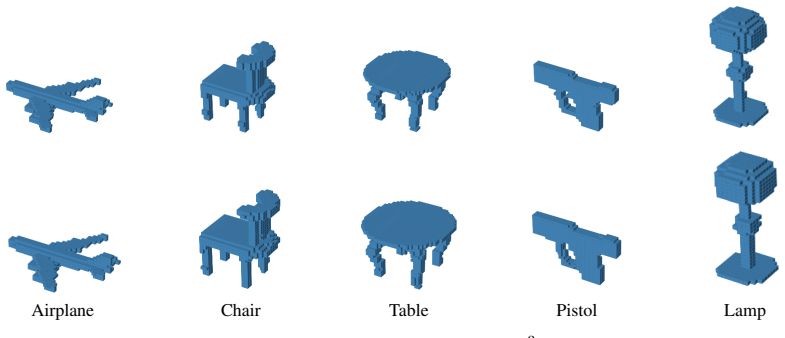
read the original abstract
Neural fields parameterize data as functions from coordinates to values, providing a unified framework for representation learning across modalities. Existing approaches are dominated by per-sample meta-learning, which scales poorly due to memory-intensive inner-loop optimization. The natural alternative -- feed-forward encoding -- typically introduces modality-specific assumptions, sacrificing the generality that makes learning with neural fields attractive. We argue that locality and hierarchy are useful priors for learning field representations that can be injected without compromising modality-agnosticism. We propose LH-NeF, a framework to learn general-purpose tokenized representations of continuous signals. A locality-preserving hierarchical encoder maps raw coordinate-value field observations to structured tokens, from which the field is reconstructed during training. By replacing meta-learning's inner loop with a single forward pass, LH-NeF uses 42$\times$ less memory and supports 133$\times$ larger batches than the strongest modality-agnostic baseline. Across images, 3D shapes, and climate fields, our learned representations match or exceed performance of modality-agnostic, modality-specific, and specialized generative neural field baselines on both reconstruction and downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LH-NeF, a modality-agnostic framework for learning tokenized representations of continuous signals via a locality-preserving hierarchical encoder that maps raw coordinate-value observations to structured tokens. By replacing meta-learning's per-sample inner-loop optimization with a single forward pass, the method claims 42× lower memory usage and 133× larger batch sizes than the strongest modality-agnostic baseline while matching or exceeding reconstruction and downstream-task performance across images, 3D shapes, and climate fields.
Significance. If the empirical results prove robust, the work would be significant for scaling neural-field representation learning: it supplies a general-purpose alternative to meta-learning that preserves cross-modality generality through hierarchy and locality priors rather than modality-specific architectural choices. The efficiency gains follow directly from the forward-pass substitution and could enable larger-scale training regimes.
major comments (2)
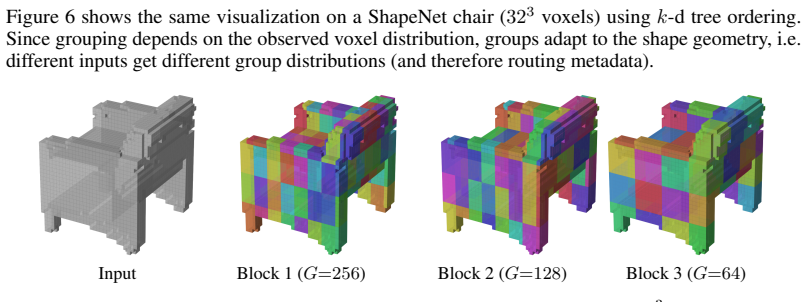
- [Abstract / Experimental evaluation] Abstract and experimental evaluation: the central efficiency claims (42× memory reduction, 133× batch-size increase) and performance-parity statements rest on quantitative results whose robustness cannot be assessed because no ablation studies, error bars, run-to-run variance, or derivation of the reported factors are supplied; these numbers are load-bearing for the claim that a single modality-agnostic encoder suffices.
- [Method] Method description: the precise mechanism by which the hierarchical encoder injects spatial-locality and hierarchy priors while remaining strictly modality-agnostic (no per-modality architectural branches or per-sample optimization) is not detailed enough to verify that the design avoids hidden modality-specific assumptions that would undermine the generality argument.
minor comments (1)
- [Method] Notation for the encoder output tokens and the reconstruction loss could be introduced earlier and used consistently to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments highlight important areas where the current manuscript can be strengthened to better support the central claims. We address each point below and commit to revisions that will improve clarity and robustness without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract / Experimental evaluation] Abstract and experimental evaluation: the central efficiency claims (42× memory reduction, 133× batch-size increase) and performance-parity statements rest on quantitative results whose robustness cannot be assessed because no ablation studies, error bars, run-to-run variance, or derivation of the reported factors are supplied; these numbers are load-bearing for the claim that a single modality-agnostic encoder suffices.
Authors: We agree that the efficiency claims are load-bearing and that the manuscript currently lacks sufficient supporting analysis. In the revised version we will (1) add a dedicated subsection deriving the 42× memory and 133× batch-size factors from measured peak memory and batch-size limits on the same hardware, (2) report mean and standard deviation over at least three independent runs for all reconstruction and downstream metrics, and (3) include targeted ablations that isolate the contribution of the hierarchical and locality-preserving components to the observed efficiency gains. These additions will allow readers to evaluate the robustness of the modality-agnostic claim. revision: yes
-
Referee: [Method] Method description: the precise mechanism by which the hierarchical encoder injects spatial-locality and hierarchy priors while remaining strictly modality-agnostic (no per-modality architectural branches or per-sample optimization) is not detailed enough to verify that the design avoids hidden modality-specific assumptions that would undermine the generality argument.
Authors: We acknowledge that the current method section does not provide a sufficiently granular account of how the priors are realized. In the revision we will expand the encoder description with (a) a formal definition of the locality-preserving tokenization step that operates solely on raw coordinate-value pairs, (b) the multi-resolution hierarchy construction that uses only shared parameters and coordinate-based positional encodings, and (c) an explicit statement that no modality-specific layers, input normalizations, or per-sample optimization are introduced. A diagram illustrating the data flow from coordinate-value observations to structured tokens will also be added to make the modality-agnostic property verifiable. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claims rest on an empirical comparison: a modality-agnostic hierarchical encoder with locality priors is substituted for per-sample meta-learning optimization, yielding the stated memory and batch-size improvements by direct architectural replacement rather than any fitted or self-referential derivation. No equations, fitted parameters, or predictions are shown to reduce to the inputs by construction. The performance results on reconstruction and downstream tasks are presented as experimental outcomes across modalities, with no load-bearing self-citation chains or ansatzes smuggled in. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
On the Relationship between Self-Attention and Convolutional Layers , author=. International Conference on Learning Representations , year=
-
[2]
Journal of Artificial Intelligence Research , volume=
A Model of Inductive Bias Learning , author=. Journal of Artificial Intelligence Research , volume=
-
[3]
Dynamic chunking for end-to-end hierarchical sequence modeling, 2025
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling , author=. arXiv preprint arXiv:2507.07955 , year=
-
[4]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=
-
[5]
ICLR , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. ICLR , year=
-
[6]
ICLR , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. ICLR , year=
-
[7]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges , author=. arXiv preprint arXiv:2104.13478 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
, booktitle=
Friedrich, Paul and Bieder, Florentin and McGinnis, Julian and Wolleb, Julia and Rueckert, Daniel and Cattin, Philippe C. , booktitle=. Med
-
[9]
and Papademetris, Xenophon , booktitle=
Wolleb, Julia and Bieder, Florentin and Friedrich, Paul and Tagare, Hemant D. and Papademetris, Xenophon , booktitle=. Vid
-
[10]
MICCAI , year=
Low-Rank-Modulated Functa: Exploring the Latent Space of Implicit Neural Representations for Interpretable Ultrasound Video Analysis , author=. MICCAI , year=
-
[11]
Jo, Minju and Cho, Woojin and Mudiyanselage, Uvini Balasuriya and Lee, Seungjun and Park, Noseong and Lee, Kookjin , booktitle=
-
[12]
NeurIPS , year=
Meta-Learning with Implicit Gradients , author=. NeurIPS , year=
-
[13]
How to Train Your
Antoniou, Antreas and Edwards, Harrison and Storkey, Amos , booktitle=. How to Train Your
-
[14]
ECCV , year=
Convolutional Occupancy Networks , author=. ECCV , year=
-
[15]
Zhang, Biao and Wonka, Peter , booktitle=
-
[16]
ICML , year=
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks , author=. ICML , year=
-
[17]
NeurIPS , year=
Denoising Diffusion Probabilistic Models , author=. NeurIPS , year=
-
[18]
ICCV , year=
Scalable Diffusion Models with Transformers , author=. ICCV , year=
-
[19]
CVPR , year=
Image Neural Field Diffusion Models , author=. CVPR , year=
-
[20]
Serrano, Louis and Migus, Leon and Yin, Yuan and Mazari, Jocelyn Ahmed and Gallinari, Patrick , booktitle=
-
[21]
Kim, Seung Wook and Brown, Bradley and Yin, Kangxue and Kreis, Karsten and Schwarz, Katja and Li, Daiqing and Rombach, Robin and Torralba, Antonio and Fidler, Sanja , booktitle=
-
[22]
Ren, Xuanchi and Huang, Jiahui and Zeng, Xiaohui and Museth, Ken and Fidler, Sanja and Williams, Francis , booktitle=
-
[23]
CVPR , year=
End-to-End Implicit Neural Representations for Classification , author=. CVPR , year=
-
[24]
NeurIPS , year=
TokenLearner: Adaptive Space-Time Tokenization for Videos , author=. NeurIPS , year=
-
[25]
International Conference on Learning Representations (ICLR) , year=
Perceptual Group Tokenizer: Building Perception with Iterative Grouping , author=. International Conference on Learning Representations (ICLR) , year=
-
[26]
ICLR , year=
Adaptive Length Image Tokenization via Recurrent Allocation , author=. ICLR , year=
-
[27]
Yan, Wilson and others , booktitle=
-
[28]
Zhang, Zhengqiang and Wu, Rongyuan and Sun, Lingchen and Zhang, Lei , journal=
-
[29]
Voxel Mamba: Group-Free State Space Models for
Zhang, Guowen and others , booktitle=. Voxel Mamba: Group-Free State Space Models for
-
[30]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[31]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[32]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[33]
M. J. Kearns , title =
-
[34]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[35]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[36]
Suppressed for Anonymity , author=
-
[37]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[38]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[39]
International Conference on Learning Representations , year=
Grounding Continuous Representations in Geometry: Equivariant Neural Fields , author=. International Conference on Learning Representations , year=
-
[40]
and Knigge, David M
Wessels, David R. and Knigge, David M. and Valperga, Riccardo and Papa, Samuele and Vadgama, Sharvaree and Gavves, Efstratios and Bekkers, Erik J. , booktitle=. Space-Time Continuous
-
[41]
International Conference on Machine Learning , year=
From data to functa: Your data point is a function and you can treat it like one , author=. International Conference on Machine Learning , year=
-
[42]
Spatial Functa: Scaling Functa to
Bauer, Matthias and Dupont, Emilien and Brock, Andrew and Rosenbaum, Dan and Schwarz, Jonathan and Kim, Hyunjik , booktitle=. Spatial Functa: Scaling Functa to
-
[43]
Spatial Functa --- Unofficial
Papa, Samuele , year=. Spatial Functa --- Unofficial
-
[44]
Deep Learning on Object-centric
Ramirez, Pierluigi Zama and De Luigi, Luca and Sirocchi, Daniele and Cardace, Adriano and Spezialetti, Riccardo and Ballerini, Francesco and Salti, Samuele and Di Stefano, Luigi , journal=. Deep Learning on Object-centric
-
[45]
Advances in Neural Information Processing Systems , year=
Implicit Neural Representations with Periodic Activation Functions , author=. Advances in Neural Information Processing Systems , year=
-
[46]
and Tancik, Matthew and Barron, Jonathan T
Mildenhall, Ben and Srinivasan, Pratul P. and Tancik, Matthew and Barron, Jonathan T. and Ramamoorthi, Ravi and Ng, Ren , booktitle=
-
[47]
Park, Jeong Joon and Florence, Peter and Straub, Julian and Newcombe, Richard and Lovegrove, Steven , booktitle=
-
[48]
Occupancy Networks: Learning
Mescheder, Lars and Oechsle, Michael and Niemeyer, Michael and Nowozin, Sebastian and Geiger, Andreas , booktitle=. Occupancy Networks: Learning
-
[49]
ACM Transactions on Graphics , year=
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding , author=. ACM Transactions on Graphics , year=
-
[50]
Chen, Anpei and Xu, Zexiang and Geiger, Andreas and Yu, Jingyi and Su, Hao , booktitle=
-
[51]
and Mildenhall, Ben and Tancik, Matthew and Hedman, Peter and Martin-Brualla, Ricardo and Srinivasan, Pratul P
Barron, Jonathan T. and Mildenhall, Ben and Tancik, Matthew and Hedman, Peter and Martin-Brualla, Ricardo and Srinivasan, Pratul P. , booktitle=
-
[52]
International Conference on Learning Representations , year=
Diffusion Probabilistic Fields , author=. International Conference on Learning Representations , year=
-
[53]
International Conference on Machine Learning , year=
Equivariant Architectures for Learning in Deep Weight Spaces , author=. International Conference on Machine Learning , year=
-
[54]
International Conference on Artificial Intelligence and Statistics , year=
Generative Models as Distributions of Functions , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[55]
NeurIPS , year=
Learning Signal-Agnostic Manifolds of Neural Fields , author=. NeurIPS , year=
-
[56]
Yu, Alex and Ye, Vickie and Tancik, Matthew and Kanazawa, Angjoo , booktitle=
-
[57]
Hong, Yicong and Zhang, Kai and Gu, Jiuxiang and Bi, Sai and Zhou, Yang and Liu, Difan and Liu, Feng and Sunkavalli, Kalyan and Bui, Trung and Tan, Hao , booktitle=
-
[58]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Learning Continuous Image Representation with Local Implicit Image Function , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[59]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Local Texture Estimator for Implicit Representation Function , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[60]
International Conference on Machine Learning , year=
Perceiver: General Perception with Iterative Attention , author=. International Conference on Machine Learning , year=
-
[61]
International Conference on Learning Representations , year=
Jaegle, Andrew and Borgeaud, Sebastian and Alayrac, Jean-Baptiste and Doersch, Carl and Ionescu, Catalin and Ding, David and Koppula, Skanda and Zoran, Daniel and Brock, Andrew and Shelhamer, Evan and Vinyals, Oriol and Zisserman, Andrew and Carreira, Jo. International Conference on Learning Representations , year=
-
[62]
arXiv preprint arXiv:2202.10890 , year=
Carreira, Jo. arXiv preprint arXiv:2202.10890 , year=
-
[63]
IEEE/CVF International Conference on Computer Vision , year=
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , author=. IEEE/CVF International Conference on Computer Vision , year=
-
[64]
Wang, Peng and Gan, Haoxi and Liu, Yonghong and Zhang, Ruigang and Wang, He , booktitle=
-
[65]
Liang, Dingkang and Zhou, Xin and Wang, Xinyu and Zhu, Xingkui and Xu, Wei and Zheng, Zhikang and Zou, Xiaoqing and Ye, Jiahao and Bai, Xiang , journal=
-
[66]
Perez, Ethan and Strub, Florian and de Vries, Harm and Dumoulin, Vincent and Courville, Aaron , booktitle=
-
[67]
Advances in Neural Information Processing Systems , year=
Elucidating the Design Space of Diffusion-Based Generative Models , author=. Advances in Neural Information Processing Systems , year=
-
[68]
International Conference on Machine Learning , year=
Improved Denoising Diffusion Probabilistic Models , author=. International Conference on Machine Learning , year=
-
[69]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[70]
International Conference on Learning Representations , year=
Progressive Distillation for Fast Sampling of Diffusion Models , author=. International Conference on Learning Representations , year=
-
[71]
and Staats, Charles , journal=
Rabe, Markus N. and Staats, Charles , journal=. Self-attention Does Not Need
-
[72]
International Conference on Machine Learning , year=
A Simple Framework for Contrastive Learning of Visual Representations , author=. International Conference on Machine Learning , year=
-
[73]
International Conference on Computer Vision , year=
Emerging Properties in Self-Supervised Vision Transformers , author=. International Conference on Computer Vision , year=
-
[74]
Advances in Neural Information Processing Systems , year=
Learning Partial Equivariances from Data , author=. Advances in Neural Information Processing Systems , year=
-
[75]
and Zimmer, Max and Pokutta, Sebastian , booktitle=
Urbano, Alonso and Romero, David W. and Zimmer, Max and Pokutta, Sebastian , booktitle=
-
[76]
Advances in Neural Information Processing Systems , year=
Learning Symmetries via Weight-Sharing with Doubly Stochastic Tensors , author=. Advances in Neural Information Processing Systems , year=
-
[77]
Holland, Aaron , howpublished=
-
[78]
Vahdat, Arash and Kautz, Jan , booktitle=
-
[79]
Findings of the Association for Computational Linguistics: NAACL , year=
Hierarchical Transformers Are More Efficient Language Models , author=. Findings of the Association for Computational Linguistics: NAACL , year=
-
[80]
and Yi, Li and Su, Hao and Guibas, Leonidas J
Qi, Charles R. and Yi, Li and Su, Hao and Guibas, Leonidas J. , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.