Mind Your Steps: A General Learning Framework for Accurate Humanoid Foothold Tracking
Pith reviewed 2026-06-27 19:32 UTC · model grok-4.3
The pith
Dynamically sampling footstep goals during training produces a terrain-agnostic 3D foothold-tracking policy that serves as a standalone low-level controller.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
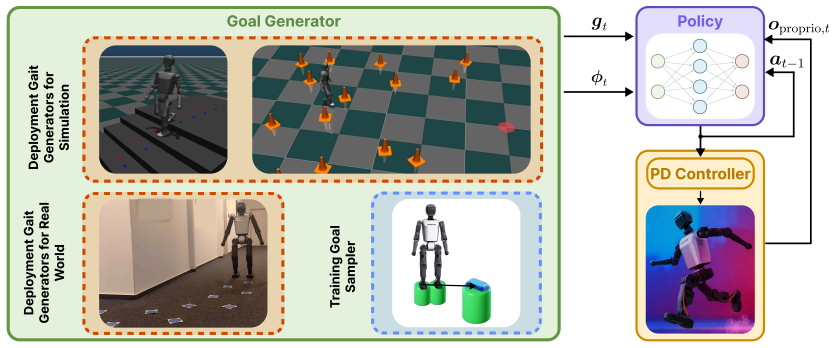
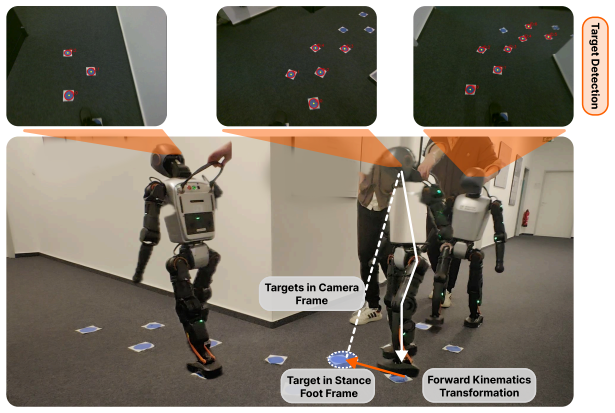
By dynamically providing footstep support through a goal sampler, this method enables the learned policy to be agnostic to specific terrains. Our new target representation effectively mitigates challenges arising in the real world, such as noisy and inaccurate pose estimation and foot contact estimation. Designed for direct real-world transfer, our policy acts as a standalone low-level controller that can be seamlessly paired with various high-level foothold generators.
What carries the argument
The goal sampler that supplies varying footstep targets on the fly during training, paired with a revised target representation that accounts for sensor noise.
If this is right
- The policy supports locomotion on unseen terrains without retraining.
- It can be combined with different high-level generators for varied navigation or manipulation tasks.
- Accurate explicit foothold control reduces unsafe steps such as landing on obstacles or other feet.
- The same low-level controller can be reused across multiple downstream applications without pipeline redesign.
Where Pith is reading between the lines
- The approach could simplify integration of vision-based or planning-based foothold generators by removing the need to retrain the locomotion layer each time.
- If the target representation proves robust to larger noise levels, the same policy might be deployed on platforms with lower-cost sensors.
- Extending the goal sampler to include dynamic obstacles during training could further improve safety in crowded settings.
Load-bearing premise
Dynamic sampling of footstep support during training will produce a policy that stays effective and terrain-agnostic when paired later with arbitrary real-world planners and noisy sensor data.
What would settle it
Pair the trained policy with a high-level planner never used in training, run it on a physical humanoid in an environment with realistic pose-estimation noise, and check whether foothold placement errors exceed the tolerance needed for stable walking.
Figures



read the original abstract
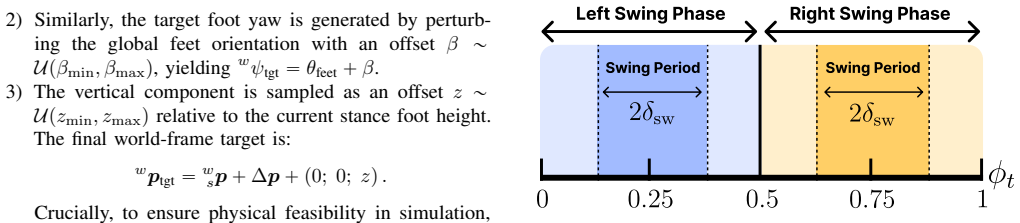
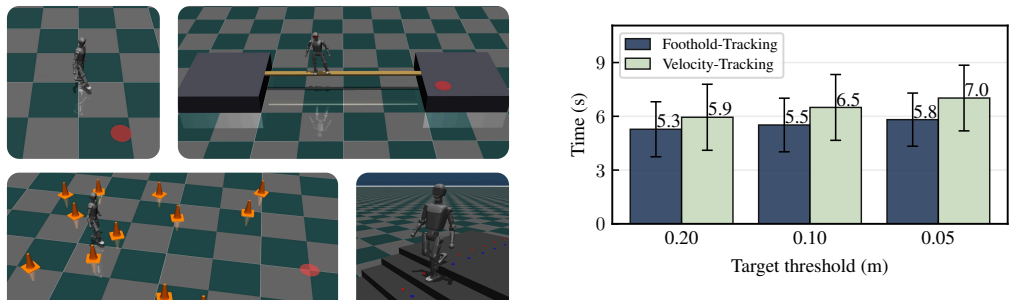
Enabling humanoid robots to operate in complex, dynamic environments remains a critical challenge, fundamentally limited by the ability to navigate robustly, safely, and accurately. While reinforcement learning with velocity-commanded policies has achieved remarkable robustness in humanoid locomotion, this approach lacks explicit control of the foothold placement, leading to unsafe behavior, such as stepping onto human feet, or imprecise navigation, hindering the following manipulation task. Conversely, explicit foothold-tracking policies offer a promising alternative by directly being commanded with target foot poses. However, existing approaches are often limited by unrealistic state assumptions, compromising real-world deployment, or they are part of staged pipelines, making them tied to specific downstream tasks. In this work, we introduce a novel, lightweight framework for training general-purpose 3D foothold-tracking policies. By dynamically providing footstep support through a goal sampler, this method enables the learned policy to be agnostic to specific terrains. Our new target representation effectively mitigates challenges arising in the real world, such as noisy and inaccurate pose estimation and foot contact estimation. Designed for direct real-world transfer, our policy acts as a standalone low-level controller that can be seamlessly paired with various high-level foothold generators. We demonstrate the effectiveness of our framework through extensive experiments in simulation and in the real world. By coupling our policy with different upstream planners, we achieve natural and accurate locomotion in challenging settings, paving the way for loco-manipulation tasks in complex environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a reinforcement learning framework for training general-purpose 3D foothold-tracking policies for humanoid robots. By dynamically sampling footstep support via a goal sampler during training, the policy is made terrain-agnostic. A new target representation is proposed to improve robustness against noisy pose estimation and foot contact estimation. The policy is presented as a standalone low-level controller that can be paired with arbitrary high-level foothold generators, with effectiveness shown via experiments in simulation and the real world.
Significance. If the experimental validation holds, the framework could enable more modular and flexible humanoid control architectures, allowing low-level foothold tracking to be decoupled from specific terrain types or planner designs. This modularity, combined with explicit handling of real-world noise, would support safer and more precise locomotion in dynamic settings and facilitate downstream loco-manipulation tasks.
major comments (2)
- [Abstract] Abstract: The central claims of terrain-agnostic behavior via the goal sampler and noise robustness via the new target representation rest on experiments in simulation and real world, yet the abstract (and framework design paragraph) provides no quantitative metrics, ablation details, or error analysis to support transfer performance or robustness under arbitrary planners and sensor noise.
- [Abstract] Abstract, paragraph on framework design: The assumption that dynamic goal sampling during training produces a policy that remains effective when deployed with arbitrary real-world high-level planners and noisy sensor data is load-bearing for the standalone-controller claim but is not accompanied by specific transfer results, coverage analysis of the sampler, or robustness tests.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that incorporating quantitative metrics and references to transfer results will strengthen the presentation of our claims and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of terrain-agnostic behavior via the goal sampler and noise robustness via the new target representation rest on experiments in simulation and real world, yet the abstract (and framework design paragraph) provides no quantitative metrics, ablation details, or error analysis to support transfer performance or robustness under arbitrary planners and sensor noise.
Authors: We agree that the abstract would benefit from quantitative support. The full manuscript (Sections IV and V) reports simulation and real-world experiments with specific metrics on tracking accuracy, success rates under sensor noise, and ablations of the goal sampler and target representation. We will revise the abstract to include representative quantitative results (e.g., tracking errors and robustness under noisy pose/contact estimation) that substantiate the terrain-agnostic and standalone-controller claims. revision: yes
-
Referee: [Abstract] Abstract, paragraph on framework design: The assumption that dynamic goal sampling during training produces a policy that remains effective when deployed with arbitrary real-world high-level planners and noisy sensor data is load-bearing for the standalone-controller claim but is not accompanied by specific transfer results, coverage analysis of the sampler, or robustness tests.
Authors: The dynamic goal sampler is intended to promote generalization by exposing the policy to diverse footstep supports during training. The manuscript demonstrates this via real-world deployment with multiple distinct high-level planners and under realistic sensor noise. We will update the abstract's framework paragraph to briefly reference these transfer results and robustness outcomes. Coverage of the sampler is analyzed in the methods through the distribution of sampled goals. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical RL training framework for humanoid foothold tracking that relies on a goal sampler and a new target representation. Effectiveness is evaluated via external simulation and hardware experiments rather than any self-referential definitions or fitted quantities renamed as predictions. No equations, derivations, or load-bearing self-citations appear in the provided text that would reduce the central claims to inputs by construction; the approach remains self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Legged locomotion in challenging terrains using egocentric vision
Ananye Agarwal, Ashish Kumar, Jitendra Malik, and Deepak Pathak. Legged locomotion in challenging terrains using egocentric vision. InConference on robot learning, pages 403–415. PMLR, 2023
2023
-
[2]
Locomujoco: A comprehensive imitation learning benchmark for locomotion
Firas Al-Hafez, Guoping Zhao, Jan Peters, and Davide Tateo. Locomujoco: A comprehensive imitation learning benchmark for locomotion. In6th Robot Learning Workshop, NeurIPS, 2023
2023
-
[3]
Lingfan Bao, Joseph Humphreys, Tianhu Peng, and Chengxu Zhou. Deep reinforcement learning for bipedal locomotion: A brief survey.arXiv preprint arXiv:2404.17070, 2024
arXiv 2024
-
[4]
Qingwei Ben, Botian Xu, Kailin Li, Feiyu Jia, Wentao Zhang, Jingping Wang, Jingbo Wang, Dahua Lin, and Jiangmiao Pang. Gallant: V oxel grid-based humanoid locomotion and local-navigation across 3d constrained terrains.arXiv preprint arXiv:2511.14625, 2025
arXiv 2025
-
[5]
Extreme parkour with legged robots
Xuxin Cheng, Kexin Shi, Ananye Agarwal, and Deepak Pathak. Extreme parkour with legged robots. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11443–11450. IEEE, 2024
2024
-
[6]
Perceptive locomotion through whole-body mpc and optimal region selection.IEEE Access, 2025
Thomas Corb `eres, Carlos Mastalli, Wolfgang Merkt, Jaehyun Shim, Ioannis Havoutis, Maurice Fallon, Nicolas Mansard, Thomas Flayols, Sethu Vijayakumar, and Steve Tonneau. Perceptive locomotion through whole-body mpc and optimal region selection.IEEE Access, 2025
2025
-
[7]
Sim-to-real learning of footstep-constrained bipedal dynamic walking
Helei Duan, Ashish Malik, Jeremy Dao, Aseem Saxena, Kevin Green, Jonah Siekmann, Alan Fern, and Jonathan Hurst. Sim-to-real learning of footstep-constrained bipedal dynamic walking. In2022 International Conference on Robotics and Automation (ICRA), pages 10428–10434. IEEE, 2022
2022
-
[8]
Rloc: Terrain-aware legged locomotion using reinforcement learning and optimal control.IEEE Transactions on Robotics, 38(5):2908–2927, 2022
Siddhant Gangapurwala, Mathieu Geisert, Romeo Or- solino, Maurice Fallon, and Ioannis Havoutis. Rloc: Terrain-aware legged locomotion using reinforcement learning and optimal control.IEEE Transactions on Robotics, 38(5):2908–2927, 2022
2022
-
[9]
Perceptive locomotion through nonlinear model-predictive control.IEEE Trans
Ruben Grandia, Fabian Jenelten, Shaohui Yang, Farbod Farshidian, and Marco Hutter. Perceptive locomotion through nonlinear model-predictive control.IEEE Trans. Robotics, 39(5):3402–3421, 2023
2023
-
[10]
Griffin, Georg Wiedebach, Stephen McCrory, Sylvain Bertrand, Inho Lee, and Jerry E
Robert J. Griffin, Georg Wiedebach, Stephen McCrory, Sylvain Bertrand, Inho Lee, and Jerry E. Pratt. Footstep planning for autonomous walking over rough terrain. In 19th IEEE-RAS International Conference on Humanoid Robots, Humanoids 2019, Toronto, ON, Canada, October 15-17, 2019, pages 9–16. IEEE, 2019
2019
-
[11]
Attention-based map encoding for learning generalized legged locomotion
Junzhe He, Chong Zhang, Fabian Jenelten, Ruben Grandia, Moritz B ¨acher, and Marco Hutter. Attention-based map encoding for learning generalized legged locomotion. Science Robotics, 10(105):eadv3604, 2025
2025
-
[12]
Tairan He, Chong Zhang, Wenli Xiao, Guanqi He, Changliu Liu, and Guanya Shi. Agile but safe: Learning collision-free high-speed legged locomotion.arXiv preprint arXiv:2401.17583, 2024
arXiv 2024
-
[13]
Anytime search-based footstep planning with suboptimality bounds
Armin Hornung, Andrew Dornbush, Maxim Likhachev, and Maren Bennewitz. Anytime search-based footstep planning with suboptimality bounds. In2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012), pages 674–679. IEEE, 2012
2012
-
[14]
TianChen Huang, Runchen Xu, Yu Wang, Wei Gao, and Shiwu Zhang. Traversing narrow paths: A two-stage reinforcement learning framework for robust and safe humanoid walking.arXiv preprint arXiv:2508.20661, 2025
arXiv 2025
-
[15]
Perceptive locomotion in rough terrain–online foothold optimization.IEEE Robotics and Automation Letters, 5(4):5370–5376, 2020
Fabian Jenelten, Takahiro Miki, Aravind E Vijayan, Marko Bjelonic, and Marco Hutter. Perceptive locomotion in rough terrain–online foothold optimization.IEEE Robotics and Automation Letters, 5(4):5370–5376, 2020
2020
-
[16]
Tamols: Terrain-aware motion optimization for legged systems.IEEE Transactions on Robotics, 38 (6):3395–3413, 2022
Fabian Jenelten, Ruben Grandia, Farbod Farshidian, and Marco Hutter. Tamols: Terrain-aware motion optimization for legged systems.IEEE Transactions on Robotics, 38 (6):3395–3413, 2022
2022
-
[17]
Dtc: Deep tracking control.Science Robotics, 9 (86):eadh5401, 2024
Fabian Jenelten, Junzhe He, Farbod Farshidian, and Marco Hutter. Dtc: Deep tracking control.Science Robotics, 9 (86):eadh5401, 2024
2024
-
[18]
Residual reinforcement learning for robot control
Tobias Johannink, Shikhar Bahl, Ashvin Nair, Jianlan Luo, Avinash Kumar, Matthias Loskyll, Juan Aparicio Ojea, Eugen Solowjow, and Sergey Levine. Residual reinforcement learning for robot control. In2019 inter- national conference on robotics and automation (ICRA), pages 6023–6029. IEEE, 2019
2019
-
[19]
Biped walking pattern generation by using preview control of zero-moment point
Shuuji Kajita, Fumio Kanehiro, Kenji Kaneko, Kiyoshi Fujiwara, Kensuke Harada, Kazuhito Yokoi, and Hirohisa Hirukawa. Biped walking pattern generation by using preview control of zero-moment point. In2003 IEEE international conference on robotics and automation (Cat. No. 03CH37422), volume 2, pages 1620–1626. IEEE, 2003
2003
-
[20]
Rma: Rapid motor adaptation for legged robots
Ashish Kumar, Zipeng Fu, Deepak Pathak, and Jitendra Malik. Rma: Rapid motor adaptation for legged robots. arXiv preprint arXiv:2107.04034, 2021
Pith/arXiv arXiv 2021
-
[21]
Inte- grating model-based footstep planning with model-free reinforcement learning for dynamic legged locomotion
Ho Jae Lee, Seungwoo Hong, and Sangbae Kim. Inte- grating model-based footstep planning with model-free reinforcement learning for dynamic legged locomotion. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11248–11255. IEEE, 2024
2024
-
[22]
Learning quadrupedal loco- motion over challenging terrain.Science robotics, 5(47): eabc5986, 2020
Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning quadrupedal loco- motion over challenging terrain.Science robotics, 5(47): eabc5986, 2020
2020
-
[23]
Junfeng Long, Zirui Wang, Quanyi Li, Jiawei Gao, Liu Cao, and Jiangmiao Pang. Hybrid internal model: Learning agile legged locomotion with simulated robot response.arXiv preprint arXiv:2312.11460, 2023
arXiv 2023
-
[24]
Rapid locomotion via reinforcement learning.The International Journal of Robotics Research, 43(4):572–587, 2024
Gabriel B Margolis, Ge Yang, Kartik Paigwar, Tao Chen, and Pulkit Agrawal. Rapid locomotion via reinforcement learning.The International Journal of Robotics Research, 43(4):572–587, 2024
2024
-
[25]
Motion planning for quadrupedal locomotion: Coupled planning, terrain mapping, and whole-body control.IEEE Transactions on Robotics, 36(6):1635–1648, 2020
Carlos Mastalli, Ioannis Havoutis, Michele Focchi, Dar- win G Caldwell, and Claudio Semini. Motion planning for quadrupedal locomotion: Coupled planning, terrain mapping, and whole-body control.IEEE Transactions on Robotics, 36(6):1635–1648, 2020
2020
-
[26]
Receding- horizon perceptive trajectory optimization for dynamic legged locomotion with learned initialization
Oliwier Melon, Romeo Orsolino, David Surovik, Mathieu Geisert, Ioannis Havoutis, and Maurice Fallon. Receding- horizon perceptive trajectory optimization for dynamic legged locomotion with learned initialization. In2021 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 9805–9811. IEEE, 2021
2021
-
[27]
Learning robust perceptive locomotion for quadrupedal robots in the wild.Science robotics, 7(62):eabk2822, 2022
Takahiro Miki, Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning robust perceptive locomotion for quadrupedal robots in the wild.Science robotics, 7(62):eabk2822, 2022
2022
-
[28]
Efficient terrain map using planar regions for footstep planning on humanoid robots
Bhavyansh Mishra, Duncan Calvert, Sylvain Bertrand, Jerry Pratt, Hakki Erhan Sevil, and Robert Griffin. Efficient terrain map using planar regions for footstep planning on humanoid robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 8044–8050. IEEE, 2024
2024
-
[29]
I Nahrendra, Byeongho Yu, and Hyun Myung. Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning.arXiv preprint arXiv:2301.10602, 2023
arXiv 2023
-
[30]
Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research, 21 (181):1–50, 2020
Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E Taylor, and Peter Stone. Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research, 21 (181):1–50, 2020
2020
-
[31]
Safesteps: Learning safer footstep planning policies for legged robots via model- based priors
Shafeef Omar, Lorenzo Amatucci, Victor Barasuol, Giulio Turrisi, and Claudio Semini. Safesteps: Learning safer footstep planning policies for legged robots via model- based priors. In2023 IEEE-RAS 22nd International Conference on Humanoid Robots (Humanoids), pages 1–8. IEEE, 2023
2023
-
[32]
Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning.Acm transactions on graphics (tog), 36(4):1–13, 2017
Xue Bin Peng, Glen Berseth, KangKang Yin, and Michiel Van De Panne. Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning.Acm transactions on graphics (tog), 36(4):1–13, 2017
2017
-
[33]
Lerrel Pinto, Marcin Andrychowicz, Peter Welinder, Wojciech Zaremba, and Pieter Abbeel. Asymmetric actor critic for image-based robot learning. InProceedings of Robotics: Science and Systems, Pittsburgh, Pennsylvania, June 2018. doi: 10.15607/RSS.2018.XIV .008
-
[34]
Capture point: A step toward humanoid push recovery
Jerry Pratt, John Carff, Sergey Drakunov, and Ambarish Goswami. Capture point: A step toward humanoid push recovery. In2006 6th IEEE-RAS international conference on humanoid robots, pages 200–207. Ieee, 2006
2006
-
[35]
Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming
Martin L. Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley Series in Probability and Statistics. John Wiley & Sons, 2014
2014
-
[36]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[37]
Sim-to-real learning of all common bipedal gaits via periodic reward composition
Jonah Siekmann, Yesh Godse, Alan Fern, and Jonathan Hurst. Sim-to-real learning of all common bipedal gaits via periodic reward composition. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 7309–7315. IEEE, 2021
2021
-
[38]
Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
Tom Silver, Kelsey Allen, Josh Tenenbaum, and Leslie Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
Pith/arXiv arXiv 2018
-
[39]
Learning bipedal walking on planned footsteps for humanoid robots
Rohan P Singh, Mehdi Benallegue, Mitsuharu Morisawa, Rafael Cisneros, and Fumio Kanehiro. Learning bipedal walking on planned footsteps for humanoid robots. In 2022 IEEE-RAS 21st International Conference on Hu- manoid Robots (Humanoids), pages 686–693. IEEE, 2022
2022
-
[40]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforce- ment learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[41]
Deepgait: Planning and control of quadrupedal gaits using deep reinforcement learning.IEEE Robotics and Automation Letters, 5(2): 3699–3706, 2020
Vassilios Tsounis, Mitja Alge, Joonho Lee, Farbod Farshidian, and Marco Hutter. Deepgait: Planning and control of quadrupedal gaits using deep reinforcement learning.IEEE Robotics and Automation Letters, 5(2): 3699–3706, 2020
2020
-
[42]
Beamdojo: Learning agile humanoid locomotion on sparse footholds
Huayi Wang, Zirui Wang, Junli Ren, Qingwei Ben, Tao Huang, Weinan Zhang, and Jiangmiao Pang. Beamdojo: Learning agile humanoid locomotion on sparse footholds. Robotics: Science and Systems (RSS), 2025
2025
-
[43]
Gait and trajectory optimization for legged systems through phase-based end-effector parameterization.IEEE Robotics and Automation Letters, 3(3):1560–1567, 2018
Alexander W Winkler, C Dario Bellicoso, Marco Hutter, and Jonas Buchli. Gait and trajectory optimization for legged systems through phase-based end-effector parameterization.IEEE Robotics and Automation Letters, 3(3):1560–1567, 2018
2018
-
[44]
Allsteps: curriculum-driven learning of stepping stone skills
Zhaoming Xie, Hung Yu Ling, Nam Hee Kim, and Michiel Van De Panne. Allsteps: curriculum-driven learning of stepping stone skills. InComputer Graphics Forum, volume 39, pages 213–224. Wiley Online Library, 2020
2020
-
[45]
Glide: Generalizable quadrupedal locomotion in diverse environments with a centroidal model
Zhaoming Xie, Xingye Da, Buck Babich, Animesh Garg, and Michiel van de Panne. Glide: Generalizable quadrupedal locomotion in diverse environments with a centroidal model. InInternational workshop on the algorithmic foundations of robotics, pages 523–539. Springer, 2022
2022
-
[46]
Neural volumetric memory for visual locomotion control
Ruihan Yang, Ge Yang, and Xiaolong Wang. Neural volumetric memory for visual locomotion control. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1430–1440, 2023
2023
-
[47]
Ruiqi Yu, Qianshi Wang, Yizhen Wang, Zhicheng Wang, Jun Wu, and Qiuguo Zhu. Walking with terrain reconstruc- tion: Learning to traverse risky sparse footholds.arXiv preprint arXiv:2409.15692, 2024
arXiv 2024
-
[48]
Visual-locomotion: Learning to walk on complex terrains with vision
Wenhao Yu, Deepali Jain, Alejandro Escontrela, Atil Iscen, Peng Xu, Erwin Coumans, Sehoon Ha, Jie Tan, and Tingnan Zhang. Visual-locomotion: Learning to walk on complex terrains with vision. In5th Annual Conference on Robot Learning, 2021
2021
-
[49]
Two steps is enough: No need to plan far ahead for walking balance
Petr Zaytsev, S Javad Hasaneini, and Andy Ruina. Two steps is enough: No need to plan far ahead for walking balance. In2015 IEEE International Conference on Robotics and Automation (ICRA), pages 6295–6300. IEEE, 2015
2015
-
[50]
Learning agile locomotion on risky terrains
Chong Zhang, Nikita Rudin, David Hoeller, and Marco Hutter. Learning agile locomotion on risky terrains. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11864–11871. IEEE, 2024
2024
-
[51]
Robot parkour learning.arXiv preprint arXiv:2309.05665, 2023
Ziwen Zhuang, Zipeng Fu, Jianren Wang, Christo- pher Atkeson, Soeren Schwertfeger, Chelsea Finn, and Hang Zhao. Robot parkour learning.arXiv preprint arXiv:2309.05665, 2023. APPENDIX Here, we present additional details for the experiments presented in the main paper. All the media reporting videos for the real-world experiment and the simulated ones can b...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.