SoK: Reconstruction Attacks on Synthetic Tabular Data (Insights from Winning the NIST CRC)
Pith reviewed 2026-06-27 19:11 UTC · model grok-4.3
The pith
The choice of synthetic data generator determines reconstruction risk far more than the choice of attack method.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reconstruction attacks recover hidden attribute values for individuals given a synthetic table and a few known quasi-identifiers. The work shows that differences among the nine synthetic data generators account for substantially more variance in attack success than differences among the fourteen attacks; differential privacy reduces risk only for budgets ε ≲ 1 and then plateaus; de-identification methods without synthesis are the most vulnerable; and a new test reveals that most reconstruction success reflects learning the underlying distribution rather than memorizing specific training rows.
What carries the argument
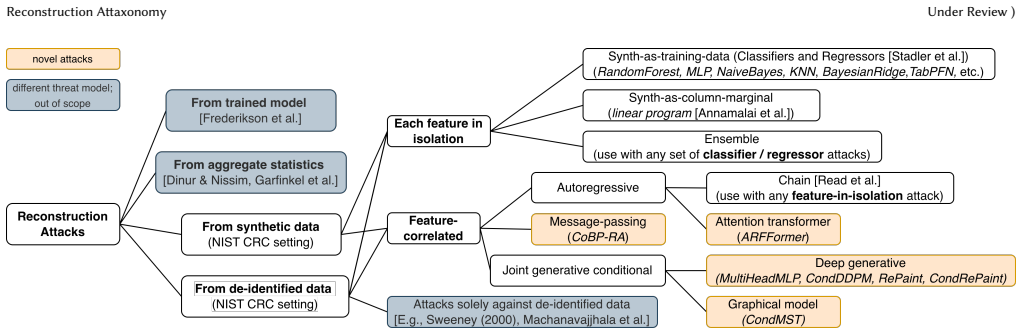
A taxonomy of reconstruction attacks classified by the structural cues they use, paired with a memorization test that separates distributional reconstruction from training-record memorization and a reduction that places reconstruction and membership inference on one numeric scale.
If this is right
- Efforts to reduce reconstruction risk should prioritize selection or improvement of the synthetic data generator rather than selection of a particular attack defense.
- Differential privacy supplies meaningful protection only when the privacy budget remains small; larger budgets add little beyond the generator's native capacity.
- Plain de-identification without any synthesis step leaves releases most exposed to attribute recovery.
- Risk is concentrated on atypical records, so defenses that specifically limit leakage on outliers would address most of the measured harm.
- Most measured reconstruction reflects learning of the data distribution, so techniques that improve distributional fidelity without increasing memorization can lower risk.
Where Pith is reading between the lines
- Deployments may need to benchmark several candidate generators on their own data before release rather than relying on published average-case rankings.
- Generator design could target reduced leakage specifically on records that deviate from the learned distribution.
- The same generator-dominance pattern may appear when the taxonomy is extended to other data types such as graphs or sequences.
- Organizations could adopt the memorization test as a routine pre-release check to decide whether a given synthetic release is safe enough for their risk tolerance.
Load-bearing premise
The five benchmark datasets and nine SDG methods are representative enough that the observed dominance of generator choice over attack choice will generalize to other real-world tabular releases and generators.
What would settle it
A new tabular dataset and tenth generator in which swapping the attack changes success rates by a larger margin than swapping the generator would falsify the dominance claim.
Figures

read the original abstract
Synthetic data is increasingly promoted as a privacy-preserving substitute for releasing sensitive tabular records, yet its central adversarial threat ("reconstruction", the recovery of an individual's hidden attribute values from a synthetic release and a handful of known quasi-identifiers) has been studied only in scattered, hard-to-compare settings. We present the first systematization of reconstruction (equivalently, attribute inference) attacks on de-identified and synthetic tabular data. We contribute a taxonomy that organizes attacks by the structure they exploit; the most systematic empirical evaluation to date, pitting fourteen attacks against nine synthetic data generation (SDG) methods across five benchmark datasets; and a set of new attacks that fill gaps in the taxonomy, one of which (CoBP-RA) is the strongest attack we measure. Crucially, we introduce a methodology for interpreting what attack success means: a memorization test that distinguishes reconstruction of the population distribution from memorization of training records, and a reduction that places reconstruction and membership inference on a single comparable scale. Our findings: the choice of SDG method governs risk far more than the choice of attack; differential privacy protects mainly at small budgets ($\varepsilon\lesssim1$), above which protection plateaus, bounded by the synthesizer's capacity rather than its noise; de-identification methods are the most exposed; and most reconstruction reflects distributional structure rather than memorization, concentrating individual risk on atypical records. The attacks and infrastructure are externally validated by our first-place finish among all red teams in the 2025 \textit{National Institute of Standards and Technology} (NIST) Collaborative Research Cycle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a Systematization of Knowledge on reconstruction (attribute inference) attacks against synthetic tabular data. It contributes a taxonomy of attacks by exploited structure, the largest empirical study to date (14 attacks vs. 9 SDG methods on 5 benchmark datasets), new attacks including CoBP-RA as the strongest measured, and two interpretive methodologies (a memorization test distinguishing population distribution learning from training-record memorization, plus a reduction placing reconstruction and membership inference on a common scale). The central empirical claims are that SDG method choice dominates risk over attack choice, differential privacy is protective mainly for ε≲1 and plateaus thereafter (bounded by synthesizer capacity), de-identification methods are most exposed, and most observed reconstruction reflects distributional structure rather than memorization (concentrating risk on atypical records). All findings are externally validated by the authors' first-place finish among red teams in the 2025 NIST Collaborative Research Cycle.
Significance. If the comparative rankings and DP-plateau observations hold under the reported conditions, the work supplies actionable guidance for synthetic data release: practitioners should prioritize generator selection and recognize the limited marginal value of DP beyond small budgets. The scale of the evaluation, the NIST competition validation, and the explicit memorization test are concrete strengths that elevate the contribution beyond prior scattered studies.
major comments (2)
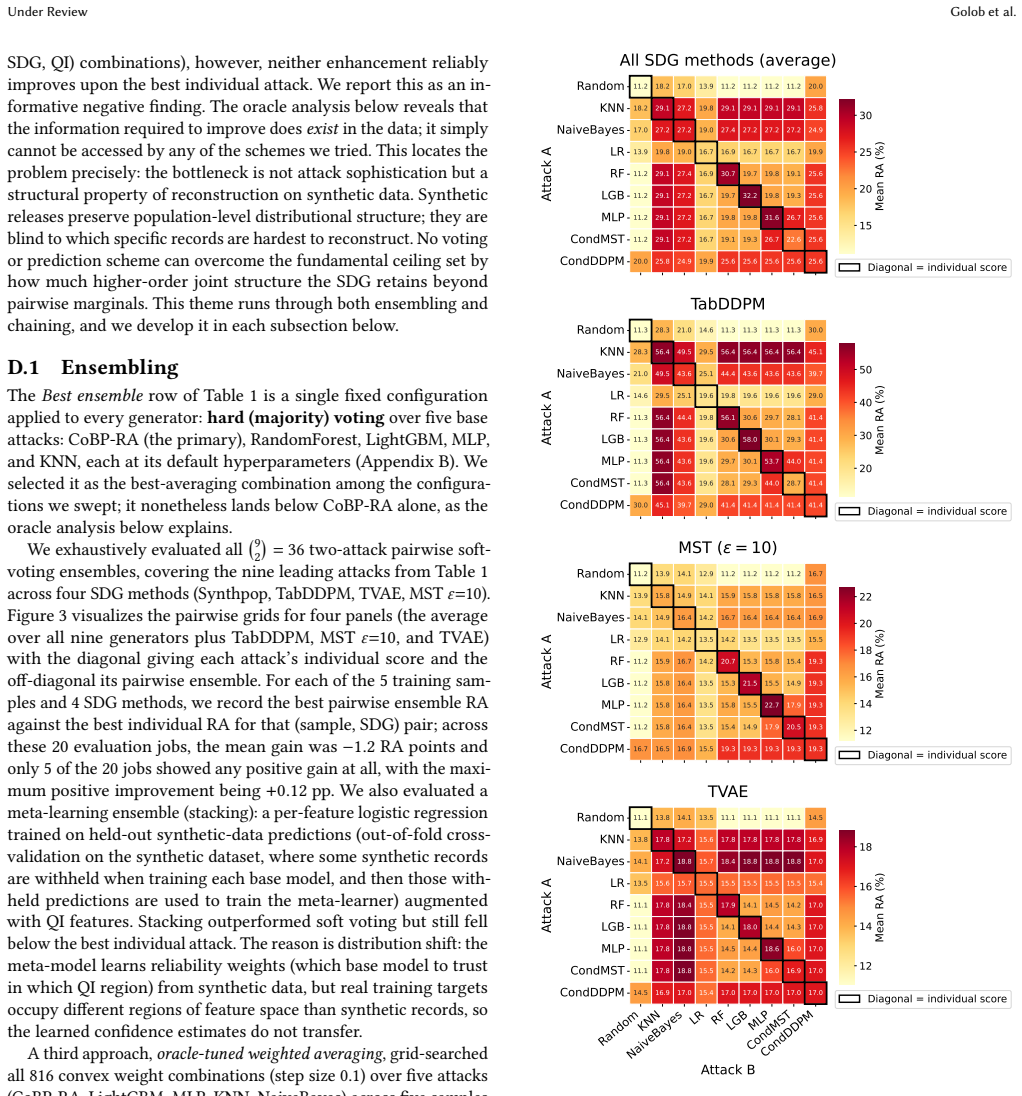
- [Abstract / empirical evaluation] Abstract and empirical evaluation section: the central claim that 'the choice of SDG method governs risk far more than the choice of attack' rests on variance comparisons across the nine generators and five datasets. The manuscript does not report statistical significance tests, error bars, or explicit data-exclusion rules, leaving open the possibility that the observed dominance is sensitive to post-hoc selection or to shared properties of the chosen benchmarks (low dimensionality, particular correlation structures).
- [Findings / DP analysis] Findings paragraph: the claim that DP protection 'plateaus, bounded by the synthesizer's capacity rather than its noise' for ε≳1 is load-bearing for the practical takeaway. Without a sensitivity analysis that varies synthesizer capacity independently of the privacy mechanism, or explicit controls for the interaction between ε and generator architecture, it is unclear whether the plateau is an artifact of the nine chosen methods.
minor comments (2)
- [Taxonomy section] The taxonomy and attack descriptions would benefit from a single summary table listing each attack, the structure it exploits, and whether it is new or adapted from prior work.
- [Figures] Figure captions for the attack-success heatmaps should explicitly state the metric (e.g., precision@K, AUC) and whether results are averaged over multiple random seeds or data splits.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with clarifications and commitments to revision.
read point-by-point responses
-
Referee: [Abstract / empirical evaluation] Abstract and empirical evaluation section: the central claim that 'the choice of SDG method governs risk far more than the choice of attack' rests on variance comparisons across the nine generators and five datasets. The manuscript does not report statistical significance tests, error bars, or explicit data-exclusion rules, leaving open the possibility that the observed dominance is sensitive to post-hoc selection or to shared properties of the chosen benchmarks (low dimensionality, particular correlation structures).
Authors: We agree that the absence of formal statistical tests and error bars leaves the variance comparison open to the concerns raised. The dominance pattern is consistent across all five datasets and fourteen attacks and receives external corroboration from our first-place NIST CRC result, but this does not substitute for quantitative support. In revision we will add error bars (multiple seeds), report variance decomposition (e.g., ANOVA or eta-squared) between generator and attack factors, and state explicit data-exclusion rules. These additions will be included without changing the reported ordering or conclusions. revision: yes
-
Referee: [Findings / DP analysis] Findings paragraph: the claim that DP protection 'plateaus, bounded by the synthesizer's capacity rather than its noise' for ε≳1 is load-bearing for the practical takeaway. Without a sensitivity analysis that varies synthesizer capacity independently of the privacy mechanism, or explicit controls for the interaction between ε and generator architecture, it is unclear whether the plateau is an artifact of the nine chosen methods.
Authors: The plateau is observed uniformly across the DP variants among the nine generators, which already span different architectures and capacities. We nevertheless accept that an explicit sensitivity analysis isolating capacity would strengthen the claim. In the revision we will add a dedicated paragraph discussing capacity–ε interactions, reference any available external evidence on capacity limits, and note the limitation that a fully orthogonal capacity sweep was outside the scope of the current study. The core observation will be qualified accordingly. revision: partial
Circularity Check
No circularity: empirical results rest on external benchmarks and cross-method comparisons
full rationale
The paper's load-bearing claims (SDG method dominates attack choice; DP plateaus above ε≲1 bounded by synthesizer capacity) are direct outputs of pitting 14 attacks against 9 generators on 5 datasets, with external validation via first-place NIST CRC finish. No equations or results reduce by construction to fitted parameters, self-definitions, or self-citation chains; the taxonomy, new attacks, and memorization test are independent contributions whose success is measured against held-out competition outcomes rather than internal fits. Representativeness concerns affect generalization but do not create circularity in the reported derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
John M Abowd. 2018. The U.S. Census Bureau Adopts Differential Privacy. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2867
2018
-
[2]
John M Abowd, Robert Ashmead, Ryan Cumings-Menon, Simson Garfinkel, Micah Heineck, Christine Heiss, Robert Johns, Daniel Kifer, Philip Leclerc, Ash- win Machanavajjhala, Brett Moran, William Sexton, Matthew Spence, and Pavel Zhuravlev. 2022. The 2020 Census Disclosure Avoidance System TopDown Al- gorithm.Harvard Data Science Review(2022). doi:10.1162/9960...
-
[3]
Tristan Allard, Louis Béziaud, and Sébastien Gambs. 2023. SNAKE challenge: Sanitization algorithms under attack. InProceedings of the 32nd ACM international conference on information and knowledge management. 5010–5014
2023
-
[4]
Meenatchi Sundaram Muthu Selva Annamalai, Andrea Gadotti, and Luc Rocher
-
[5]
In33rd USENIX security symposium (USENIX security 24)
A linear reconstruction approach for attribute inference attacks against synthetic data. In33rd USENIX security symposium (USENIX security 24). 2351– 2368
-
[6]
Assefa, Danial Dervovic, Mahmoud Mahfouz, Robert E
Samuel A. Assefa, Danial Dervovic, Mahmoud Mahfouz, Robert E. Tillman, Prashant Reddy, and Manuela Veloso. 2020. Generating Synthetic Data in Finance: 13 Under Review Golob et al. Opportunities, Challenges and Pitfalls. InProceedings of the First ACM Interna- tional Conference on AI in Finance (ICAIF). ACM. doi:10.1145/3383455.3422554
-
[7]
Eugene Bagdasaryan, Omid Poursaeed, and Vitaly Shmatikov. 2019. Differential privacy has disparate impact on model accuracy.Advances in neural information processing systems32 (2019)
2019
-
[8]
Barry Becker and Ronny Kohavi. 1996. Adult Data Set. https://archive.ics.uci. edu/ml/datasets/adult. doi:10.24432/C5XW20 UCI Machine Learning Repository
-
[9]
Stanley, and Evan Totty
Gary Benedetto, Jordan C. Stanley, and Evan Totty. 2018.The Creation and Use of the SIPP Synthetic Beta v7.0. Working Paper. U.S. Census Bureau
2018
-
[10]
Leo Breiman. 2001. Random Forests.Machine Learning45, 1 (2001), 5–32
2001
-
[11]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. 2022. Membership inference attacks from first principles. In2022 IEEE symposium on security and privacy (SP). IEEE, 1897–1914
2022
-
[12]
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. 2023. Extract- ing Training Data from Diffusion Models. In32nd USENIX Security Symposium (USENIX Security 23). 5253–5270
2023
-
[13]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Rafique. 2021. Extracting Training Data from Large Language Models. In30th USENIX Security Symposium (USENIX Security 21). 2633–2650
2021
-
[14]
Centers for Disease Control and Prevention. 2015. CDC Diabetes Health In- dicators Dataset. https://archive.ics.uci.edu/dataset/891/cdc+diabetes+health+ indicators. Behavioral Risk Factor Surveillance System (BRFSS)
2015
-
[15]
Chen Chen, Lingjuan Lyu, Han Yu, and Gang Chen. 2024. Practical Attribute Reconstruction Attack Against Federated Learning.IEEE Transactions on Big Data10, 6 (2024), 851–863. doi:10.1109/TBDATA.2022.3159236
- [16]
-
[17]
Hakan Demirtas. 2018. Flexible imputation of missing data.Journal of statistical software85 (2018), 1–5
2018
-
[18]
Travis Dick, Cynthia Dwork, Michael Kearns, Terrance Liu, Aaron Roth, Giuseppe Vietri, and Zhiwei Steven Wu. 2023. Confidence-ranked reconstruction of census microdata from published statistics.Proceedings of the National Academy of Sciences120, 8 (2023), e2218605120
2023
-
[19]
Irit Dinur and Kobbi Nissim. 2003. Revealing information while preserving privacy. InProceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART sym- posium on Principles of database systems. 202–210
2003
-
[20]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Cali- brating Noise to Sensitivity in Private Data Analysis. InProceedings of the Third Conference on Theory of Cryptography (TCC). Springer, 265–284
2006
-
[21]
Cynthia Dwork and Aaron Roth. 2014. The algorithmic foundations of differential privacy.Foundations and Trends®in Theoretical Computer Science9, 3–4 (2014), 211–407
2014
-
[22]
Cynthia Dwork, Adam Smith, Thomas Steinke, and Jonathan Ullman. 2017. Ex- posed! a survey of attacks on private data.Annual Review of Statistics and Its Application4, 1 (2017), 61–84
2017
-
[23]
Khaled El Emam, Elizabeth Jonker, Luk Arbuckle, and Bradley Malin. 2011. A systematic review of re-identification attacks on health data.PloS One6, 12 (2011), e28071
2011
-
[24]
Khaled El Emam, Lucy Mosquera, and Jason Bass. 2020. Evaluating Identity Dis- closure Risk in Fully Synthetic Health Data: Model Development and Validation. Journal of Medical Internet Research22, 11 (2020), e23139. doi:10.2196/23139
-
[25]
Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. 2015. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. 1322–1333
2015
-
[26]
On the (In)Security of LLM app stores,
Georgi Ganev and Emiliano De Cristofaro. 2025. The Inadequacy of Similarity- Based Privacy Metrics: Privacy Attacks Against “Truly Anonymous” Synthetic Datasets. In2025 IEEE Symposium on Security and Privacy (SP). 4007–4025. doi:10. 1109/SP61157.2025.00218 ISSN: 2375-1207
-
[27]
Simson L Garfinkel, John M Abowd, and Christian Martindale. 2019. Understand- ing Database Reconstruction Attacks on Public Data.Commun. ACM62, 3 (2019), 46–53
2019
-
[28]
Matteo Giomi, Franziska Boenisch, Christoph Wehmeyer, and Borbála Tasnádi
-
[29]
Proceedings on Privacy Enhancing Technologies(2023)
A Unified Framework for Quantifying Privacy Risk in Synthetic Data. Proceedings on Privacy Enhancing Technologies(2023)
2023
- [30]
-
[31]
Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. 2019. LOGAN: Membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies1 (2019), 133–152
2019
-
[32]
Benjamin Hilprecht, Martin Härterich, and Daniel Bernau. 2019. Monte carlo and reconstruction membership inference attacks against generative models. Proceedings on Privacy Enhancing Technologies2019, 4 (2019), 232–249
2019
-
[33]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems, Vol. 33. 6840–6851
2020
-
[34]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. 2023. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. InInternational Conference on Learning Representations (ICLR)
2023
-
[35]
Florimond Houssiau, James Jordon, Samuel N Cohen, Owen Daniel, Andrew Elliott, James Geddes, Callum Mole, Camila Rangel-Smith, and Lukasz Szpruch
- [36]
-
[37]
Yuzheng Hu, Fan Wu, Qinbin Li, Yunhui Long, Gonzalo Garrido, Chang Ge, Bolin Ding, David Forsyth, Bo Li, and Dawn Song. 2024. SoK: privacy-preserving data synthesis. In2024 IEEE symposium on security and privacy (SP). 4696–4713
2024
-
[38]
Bargav Jayaraman and David Evans. 2022. Are attribute inference attacks just imputation?. InProceedings of the 2022 ACM SIGSAC conference on computer and communications security. 1569–1582
2022
- [39]
-
[40]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems30 (2017)
2017
-
[41]
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. 2023. Tabddpm: Modelling tabular data with diffusion models. InInternational confer- ence on machine learning. PMLR, 17564–17579
2023
-
[42]
Zinan Lin, Ashish Khetan, Giulia Fanti, and Sewoong Oh. 2018. PacGAN: The power of two samples in generative adversarial networks. InAdvances in Neural Information Processing Systems, Vol. 31
2018
-
[43]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion proba- bilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11461–11471
2022
- [44]
-
[45]
Ashwin Machanavajjhala, Daniel Kifer, Johannes Gehrke, and Muthuramakr- ishnan Venkitasubramaniam. 2007. ℓ-Diversity: Privacy Beyond 𝑘-Anonymity. ACM Transactions on Knowledge Discovery from Data1, 1 (2007), 3
2007
- [46]
- [47]
-
[48]
Ryan McKenna, Daniel Sheldon, and Gerome Miklau. 2019. Graphical-model based estimation and inference for differential privacy. InInternational conference on machine learning. PMLR, 4435–4444
2019
-
[49]
Matthieu Meeus, Florent Guepin, Ana-Maria Creţu, and Yves-Alexandre de Mon- tjoye. 2023. Achilles’ heels: vulnerable record identification in synthetic data publishing. InEuropean symposium on research in computer security. Springer, 380–399
2023
-
[50]
Richard A. Moore. 1996.Controlled data-swapping techniques for masking pub- lic use microdata sets. Technical Report RR 96/04. U.S. Bureau of the Census, Statistical Research Division
1996
-
[51]
Krishnamurty Muralidhar and Josep Domingo-Ferrer. 2023. Database recon- struction is not so easy and is different from reidentification.Journal of Official Statistics39, 3 (2023), 381–398. Publisher: SAGE Publications Sage UK: London, England
2023
-
[52]
Arvind Narayanan and Vitaly Shmatikov. 2008. Robust De-Anonymization of Large Sparse Datasets. In2008 IEEE Symposium on Security and Privacy (SP). IEEE, 111–125
2008
-
[53]
National Institute of Standards and Technology. 2018. NIST Differential Privacy Synthetic Data Challenge (Arizona Dataset). https://www.nist.gov/ctl/pscr/open- innovation-prize-challenges. Synthetic census-like dataset
2018
-
[54]
National Institute of Standards and Technology. 2018. NIST Synthetic Data Challenge: Survey of Business Owners (SBO). https://www.nist.gov/ctl/pscr/ open-innovation-prize-challenges. Synthetic business transaction dataset
2018
-
[55]
Beata Nowok, Gillian M Raab, and Chris Dibben. 2016. synthpop: Bespoke creation of synthetic data in R.Journal of statistical software74 (2016), 1–26
2016
-
[56]
Jesse Read, Bernhard Pfahringer, Geoff Holmes, and Eibe Frank. 2011. Classifier chains for multi-label classification.Machine Learning85, 3 (2011), 333–359. doi:10.1007/s10994-011-5256-5
-
[57]
Luc Rocher, Julien M Hendrickx, and Yves-Alexandre De Montjoye. 2019. Esti- mating the success of re-identifications in incomplete datasets using generative models.Nature Communications10, 1 (2019), 3069
2019
-
[58]
Pierangela Samarati. 2001. Protecting Respondents’ Identities in Microdata Release.IEEE Transactions on Knowledge and Data Engineering13, 6 (2001), 1010–1027. doi:10.1109/69.971193 14 Reconstruction Attaxonomy Under Review )
-
[59]
scikit-learn developers. 2024. California Housing Dataset. https://scikit-learn.org/ stable/modules/generated/sklearn.datasets.fetch_california_housing.html. De- rived from 1990 US Census data
2024
-
[60]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Mem- bership inference attacks against machine learning models. In2017 IEEE Sympo- sium on Security and Privacy (SP). IEEE, 3–18
2017
-
[61]
Theresa Stadler, Bristena Oprisanu, and Carmela Troncoso. 2022. Synthetic data–anonymisation groundhog day. In31st USENIX security symposium (USENIX security 22). 1451–1468
2022
-
[62]
Daniel J Stekhoven and Peter Bühlmann. 2012. MissForest—non-parametric missing value imputation for mixed-type data.Bioinformatics28, 1 (2012), 112– 118
2012
-
[63]
Jonathan AC Sterne, Ian R White, John B Carlin, Michael Spratt, Patrick Royston, Michael G Kenward, Angela M Wood, and James R Carpenter. 2009. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls.Bmj338 (2009)
2009
-
[64]
2000.Simple Demographics Often Identify People Uniquely
Latanya Sweeney. 2000.Simple Demographics Often Identify People Uniquely. Technical Report LIDAP-WP4. Carnegie Mellon University, Data Privacy Labora- tory
2000
-
[65]
Latanya Sweeney. 2002. k-anonymity: A model for protecting privacy.Interna- tional Journal of Uncertainty, Fuzziness and Knowledge-Based Systems(2002)
2002
-
[66]
Matthias Templ, Alexander Kowarik, and Bernhard Meindl. 2015. Statistical Disclosure Control for Micro-Data Using the R Package sdcMicro.Journal of Statistical Software67, 4 (2015), 1–36
2015
-
[67]
Department of Health and Human Services, Office for Civil Rights
U.S. Department of Health and Human Services, Office for Civil Rights. 2012. Guidance Regarding Methods for De-identification of Protected Health Informa- tion in Accordance with the HIPAA Privacy Rule. https://www.hhs.gov/hipaa/for- professionals/special-topics/de-identification/index.html
2012
- [68]
-
[69]
Stef Van Buuren and Karin Groothuis-Oudshoorn. 2011. mice: Multivariate imputation by chained equations in R.Journal of statistical software45 (2011), 1–67
2011
-
[70]
Jason Walonoski, Mark Kramer, Joseph Nichols, Andre Quina, Chris Moesel, Dylan Hall, Carlton Duffett, Kudakwashe Dube, Thomas Gallagher, and Scott McLachlan. 2018. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. Journal of the American Medical Informatics Association25...
-
[71]
David S Watson, Kristin Blesch, Jan Kapar, and Marvin N Wright. 2023. Ad- versarial random forests for density estimation and generative modeling. In International conference on artificial intelligence and statistics. PMLR, 5357–5375
2023
-
[72]
2001.Elements of Statistical Disclosure Control
Leon Willenborg and Ton de Waal. 2001.Elements of Statistical Disclosure Control. Springer, New York
2001
-
[73]
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni
-
[74]
Modeling tabular data using conditional gan.Advances in neural information processing systems32 (2019)
2019
-
[75]
M Yaghini, B Kulynych, G Cherubin, M Veale, and C Troncoso. 2022. Disparate vulnerability to membership inference attacks.Proceedings on Privacy Enhancing Technologies2022, 1 (2022), 460–480
2022
-
[76]
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting. In2018 IEEE 31st Computer Security Foundations Symposium (CSF). IEEE, 268–282
2018
-
[77]
Jinsung Yoon, James Jordon, and Mihaela Schaar. 2018. Gain: Missing data impu- tation using generative adversarial nets. InInternational conference on machine learning. PMLR, 5689–5698
2018
-
[78]
Jun Zhang, Graham Cormode, Cecilia M Procopiuc, Divesh Srivastava, and Xi- aokui Xiao. 2017. PrivBayes: Private data release via Bayesian networks.ACM Transactions on Database Systems (TODS)42, 4 (2017), 1–41
2017
-
[79]
adversar- ial
Benjamin Zi Hao Zhao, Aviral Agrawal, Catisha Coburn, Hassan Jameel Asghar, Raghav Bhaskar, Mohamed Ali Kaafar, Darren Webb, and Peter Dickinson. 2021. On the (in) feasibility of attribute inference attacks on machine learning models. In2021 IEEE european symposium on security and privacy (EuroS&P). IEEE, 232– 251. A Preliminaries A.1 Dataset Details The ...
2021
-
[80]
+ demo”) also appear in QIbeh.; similarly, the six “ + large
CoBP-RA wraps the same25-tree forest with belief propagation over an MST of pairwise synthetic marginals (local PMI from the 100nearest synthetic neighbours, Laplace smoothing 𝛼=10−6); its continuous variant quantile-bins each hidden feature into20bins and switches to global PMI. The diffusion attacks (CondDDPM, Con- dRePaint, CondDDPMWithMLP) share one M...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.