The Spectral Dynamics and Noise Geometry of Muon
Pith reviewed 2026-06-27 18:30 UTC · model grok-4.3
The pith
Muon replaces matrix gradients with polar factors to flatten singular spectra while preserving directions, maximizing one-step entropy under alignment assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
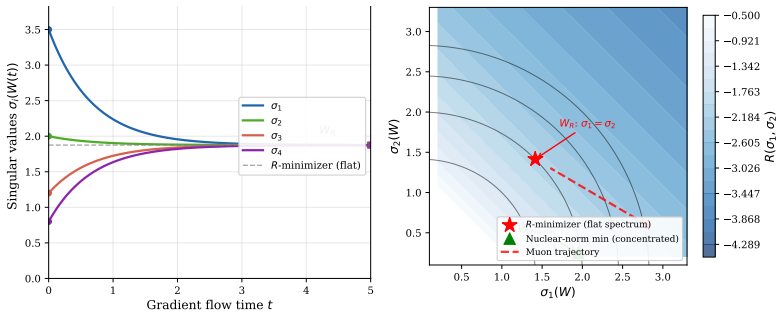
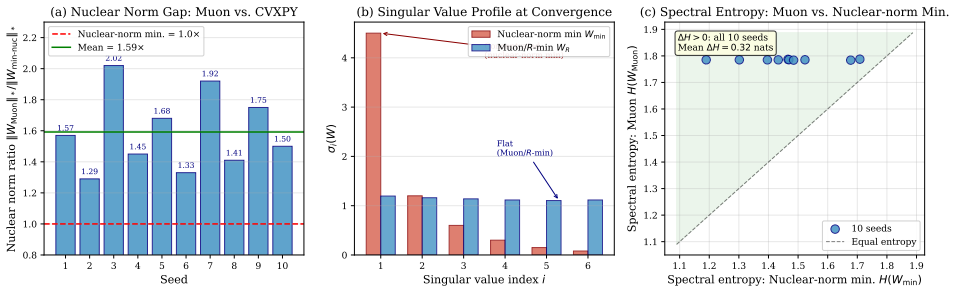
Muon replaces a matrix gradient G=UΣV^T by its polar factor UV^T. This keeps the singular directions selected by the gradient but makes the update spectrum flat. Under explicit alignment assumptions, the polar update is the one-step entropy-maximizing choice among bounded updates that use the gradient singular directions and do not adapt to the current weight spectrum. In an underdetermined regression model, exact singular-value dynamics for continuous-time Muon are derived, identifying a measurement-dependent condition under which the normalized spectrum moves toward equal nonzero singular values. This geometry rules out a common low-rank interpretation because at fixed Frobenius norm, Muon
What carries the argument
The polar factor UV^T of the gradient G=UΣV^T, which keeps singular directions from the gradient but forces a flat spectrum in the update.
If this is right
- In underdetermined regression, the normalized spectrum moves toward equal nonzero singular values under the identified measurement-dependent condition.
- At fixed Frobenius norm, Muon's state has a flat spectrum, distinct from nuclear-norm minimization which favors concentration.
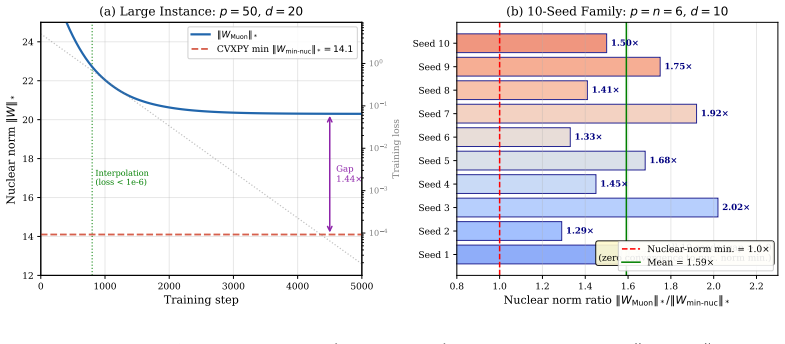
- Controlled matrix-sensing experiments recover the predicted flattening trend and separate the effect from gradient rescaling.
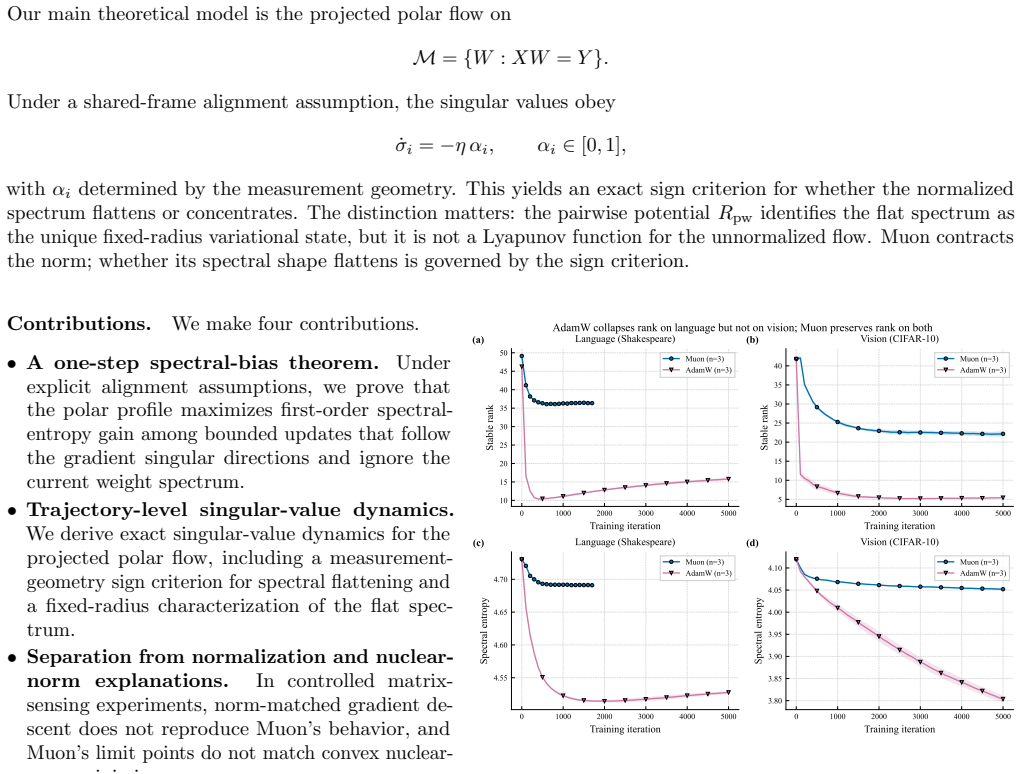
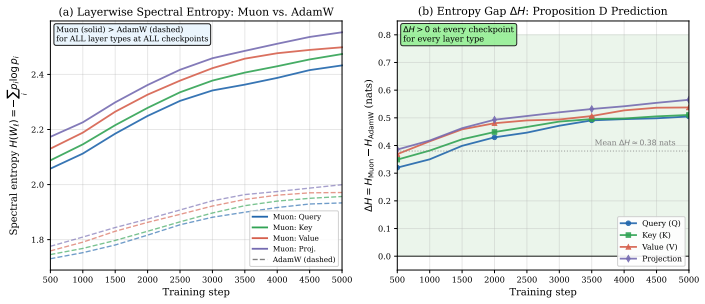
- In small NanoGPT pretraining, Muon preserves stable rank, shows a broad learning-rate plateau, and improves validation loss relative to AdamW.
- In a matched small-ViT control, the performance ranking reverses, showing the effect is regime-dependent.
Where Pith is reading between the lines
- The entropy-max property under alignment may imply Muon favors more uniform parameter usage in tasks with diverse or high-dimensional features.
- The identified dynamics could be tested in other continuous-time matrix optimizers to see if polar steps produce similar flattening.
- Regime dependence suggests checking Muon on problems where maintaining activity across many spectral directions aids generalization.
- The distinction from low-rank biases may connect to understanding when flat-spectrum updates help avoid premature concentration in training.
Load-bearing premise
The explicit alignment assumptions between weights and gradients that are required for the entropy-maximization proof.
What would settle it
Whether the singular values of weights in continuous-time Muon applied to an underdetermined regression problem flatten toward equality when the measurement-dependent condition holds.
Figures

read the original abstract
Muon replaces a matrix gradient $G=U\Sigma V^\top$ by its polar factor $UV^\top$. This keeps the singular directions selected by the gradient, but makes the update spectrum flat. We study the optimization bias created by this operation. Under explicit alignment assumptions, we prove that the polar update is the one-step entropy-maximizing choice among bounded updates that use the gradient singular directions and do not adapt to the current weight spectrum. In an underdetermined regression model, we derive exact singular-value dynamics for continuous-time Muon and identify a measurement-dependent condition under which the normalized spectrum moves toward equal nonzero singular values. This geometry also rules out a common low-rank interpretation: at fixed Frobenius norm, Muon's distinguished state has a flat spectrum, whereas nuclear-norm minimization favors spectral concentration. Controlled matrix-sensing experiments separate the effect from simple gradient rescaling, show that norm-matched gradient descent does not reproduce Muon, and recover the predicted flattening trend across broad ablations. In small NanoGPT pretraining, Muon preserves stable rank, has a broad learning-rate plateau, and improves validation loss relative to AdamW; in a matched small-ViT control, the ranking reverses. The resulting picture is regime-dependent: Muon is not universally superior, but its flat-spectrum bias can help when many spectral directions need to remain active.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies Muon, which replaces a matrix gradient G = U Σ V^T by its polar factor UV^T. Under explicit alignment assumptions, it proves this is the one-step entropy-maximizing choice among bounded updates that use the gradient's singular directions without adapting to the current weight spectrum. In an underdetermined regression model it derives exact continuous-time singular-value dynamics and a measurement-dependent condition for the normalized spectrum to flatten toward equal nonzero singular values. Experiments in matrix sensing separate the effect from gradient rescaling, while small NanoGPT and ViT pretraining runs show regime-dependent benefits for stable rank and validation loss.
Significance. If the central claims hold, the work supplies a geometric account of Muon's flat-spectrum bias that distinguishes it from both simple rescaling and nuclear-norm minimization, together with falsifiable predictions for spectral dynamics. The controlled matrix-sensing ablations and the explicit one-step optimality result under stated assumptions are strengths that would strengthen the manuscript's contribution to understanding optimization geometry in deep learning.
major comments (3)
- [Abstract] Abstract and the entropy-maximization statement: the one-step optimality result is conditioned on 'explicit alignment assumptions' whose necessity, quantitative scope (e.g., allowable misalignment angle between gradient and weight singular vectors), and verification in the experimental regimes are not supplied; without such bounds the claimed justification for the polar update does not apply when the assumptions fail even moderately.
- [§4] §4 (underdetermined regression model): the measurement-dependent condition for spectral flattening is derived within the same model used to define the dynamics; this creates a circularity risk for the prediction that the normalized spectrum moves toward equal nonzero singular values, as the condition may reduce to quantities already fixed by the regression setup.
- [Matrix-sensing experiments] Matrix-sensing experiments (controlled ablations): while they separate Muon from norm-matched gradient descent, the reported flattening trend is shown only for the specific sensing matrices and noise levels chosen; no quantitative check is given that the alignment assumptions required by the theory hold in these runs, weakening the link between the proof and the observed geometry.
minor comments (2)
- Notation for the polar factor UV^T and the singular-value dynamics should be introduced with an explicit equation number on first use to improve traceability.
- The NanoGPT and ViT results would benefit from reporting the precise hyperparameter ranges explored for the learning-rate plateau claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the alignment assumptions and their empirical verification.
read point-by-point responses
-
Referee: [Abstract] Abstract and the entropy-maximization statement: the one-step optimality result is conditioned on 'explicit alignment assumptions' whose necessity, quantitative scope (e.g., allowable misalignment angle between gradient and weight singular vectors), and verification in the experimental regimes are not supplied; without such bounds the claimed justification for the polar update does not apply when the assumptions fail even moderately.
Authors: We agree that the alignment assumptions require explicit quantification and verification. In the revision we will add a dedicated subsection deriving the necessity of the assumptions together with quantitative bounds on the allowable misalignment angle (in terms of the angle between the singular vectors of the gradient and the current weights) under which the one-step entropy-maximization result continues to hold. We will also report empirical measurements of these angles in both the matrix-sensing and pretraining experiments to confirm that the assumptions are satisfied in the reported regimes. revision: yes
-
Referee: [§4] §4 (underdetermined regression model): the measurement-dependent condition for spectral flattening is derived within the same model used to define the dynamics; this creates a circularity risk for the prediction that the normalized spectrum moves toward equal nonzero singular values, as the condition may reduce to quantities already fixed by the regression setup.
Authors: The continuous-time dynamics are derived exactly from the model, but the flattening condition is expressed solely in terms of the fixed measurement matrix and noise level; it is therefore independent of the evolving singular-value trajectory and yields a falsifiable prediction for any given sensing matrix. Nevertheless, to remove any appearance of circularity we will revise §4 to separate the model definition from the derived condition more explicitly and add a short remark on how the condition can be checked directly from the measurements. revision: partial
-
Referee: [Matrix-sensing experiments] Matrix-sensing experiments (controlled ablations): while they separate Muon from norm-matched gradient descent, the reported flattening trend is shown only for the specific sensing matrices and noise levels chosen; no quantitative check is given that the alignment assumptions required by the theory hold in these runs, weakening the link between the proof and the observed geometry.
Authors: We acknowledge the gap. In the revised manuscript we will include quantitative checks (singular-vector angles between gradient and weights) for the matrix-sensing runs, confirming that the alignment assumptions hold under the chosen sensing matrices and noise levels. This will directly tie the observed flattening to the theoretical result. revision: yes
Circularity Check
No circularity: derivations are self-contained mathematical proofs and model-specific dynamics.
full rationale
The paper states a conditional proof under explicit alignment assumptions for the entropy-maximization property and separately derives singular-value dynamics inside an underdetermined regression model, identifying a measurement-dependent flattening condition. Neither step reduces a claimed prediction to a fitted input by construction, nor relies on self-citation load-bearing, ansatz smuggling, or renaming. The alignment assumptions are external prerequisites for the one-step result rather than outputs of the same equations; the regression-model condition is derived from the model's own measurement process without circular re-use of the target flattening as an input. The overall chain therefore remains independent of its conclusions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit alignment assumptions between gradient singular directions and weights
Reference graph
Works this paper leans on
-
[1]
pAI/MSc: ML Theory Research with Humans on the Loop
Mahmoud Abdelmoneum, Pierfrancesco Beneventano, and Tomaso Poggio. pAI/MSc: ML theory research with humans on the loop. 2026. arXiv:2604.20622 [cs.AI]; DOI:https://doi.org/10.48550/arXiv.2604.20622
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.20622 2026
-
[2]
Muon: An optimizer for hidden layers in neural networks
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks. Blog post, https://kellerjordan.github.io/ posts/muon/, 2024. Reference implementation: https://github.com/KellerJordan/Muon; used in the modded- nanogpt speedrun benchmarkhttps://github.com/Kel...
2024
-
[3]
Muon is scalable for LLM training, 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, et al. Muon is scalable for LLM training, 2025
2025
-
[4]
Crockett
Lisa Messeri and Molly J. Crockett. Artificial intelligence and illusions of understanding in scientific research. Nature, 627(8002):49–58, 2024
2024
-
[5]
Agent systems for academic research automation
Pierfrancesco Beneventano, Riccardo Neumarker, Theodoros Evgeniou, Marc Gong Bacvanski, Kushagra Tiwary, Emanuele Rimoldi, Mehdi Hajoub, Yulu Gan, Qianli Liao, Mahmoud Abdelmoneum, et al. Agent systems for academic research automation. InICML 2026 AI for Science Workshop, 2026
2026
-
[6]
The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
2018
-
[7]
Implicit regularization in matrix factorization
Suriya Gunasekar, Blake Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nathan Srebro. Implicit regularization in matrix factorization. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[8]
Implicit regularization in matrix sensing via mirror descent
Fan Wu and Patrick Rebeschini. Implicit regularization in matrix sensing via mirror descent. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[9]
Characterizing implicit bias in terms of optimization geometry
Suriya Gunasekar, Jason Lee, Daniel Soudry, and Nathan Srebro. Characterizing implicit bias in terms of optimization geometry. InProceedings of the 35th International Conference on Machine Learning (ICML), 2018
2018
-
[10]
Old optimizer, new norm: An anthology, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology, 2024
2024
-
[11]
Orthogonalising gradients to speed up neural network optimisation, 2022
Mark Tuddenham, Adam Pr¨ ugel-Bennett, and Jonathan Hare. Orthogonalising gradients to speed up neural network optimisation, 2022. arXiv preprint
2022
-
[12]
A note on the convergence of Muon, 2025
Jiaxiang Li and Mingyi Hong. A note on the convergence of Muon, 2025. arXiv preprint
2025
-
[13]
Understanding gradient orthogonalization for deep learning via non-Euclidean trust-region optimization, 2025
Dmitry Kovalev. Understanding gradient orthogonalization for deep learning via non-Euclidean trust-region optimization, 2025. arXiv preprint
2025
-
[14]
Muon optimizes under spectral norm constraints, 2025
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints, 2025
2025
-
[15]
Higham.Functions of Matrices: Theory and Computation
Nicholas J. Higham.Functions of Matrices: Theory and Computation. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2008
2008
-
[16]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the Muon algorithm, 2025
2025
-
[17]
PolarGrad: A class of matrix-gradient optimizers from a unifying preconditioning perspective, 2025
Tim Tsz-Kit Lau, Qi Long, and Weijie Su. PolarGrad: A class of matrix-gradient optimizers from a unifying preconditioning perspective, 2025. 14
2025
-
[18]
When do spectral gradient updates help in deep learning?, 2025
Damek Davis and Dmitriy Drusvyatskiy. When do spectral gradient updates help in deep learning?, 2025
2025
-
[19]
On the convergence analysis of muon, 2025
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon, 2025
2025
-
[20]
David Yunis, Kumar Kshitij Patel, Samuel Wheeler, Pedro Savarese, Gal Vardi, Karen Livescu, Michael Maire, and Matthew R. Walter. Approaching deep learning through the spectral dynamics of weights, 2024
2024
-
[21]
From SGD to spectra: A theory of neural network weight dynamics, 2025
Brian Richard Olsen, Sam Fatehmanesh, Frank Xiao, Adarsh Kumarappan, and Anirudh Gajula. From SGD to spectra: A theory of neural network weight dynamics, 2025
2025
-
[22]
Implicit bias of spectral descent and Muon on multiclass separable data, 2025
Chen Fan, Mark Schmidt, and Christos Thrampoulidis. Implicit bias of spectral descent and Muon on multiclass separable data, 2025
2025
-
[23]
The implicit bias of Adam and Muon on smooth homogeneous neural networks, 2026
Eitan Gronich and Gal Vardi. The implicit bias of Adam and Muon on smooth homogeneous neural networks, 2026
2026
-
[24]
Uniform spectral growth and convergence of Muon in LoRA-style matrix factorization, 2026
Changmin Kang, Jihun Yun, Baekrok Shin, Yeseul Cho, and Chulhee Yun. Uniform spectral growth and convergence of Muon in LoRA-style matrix factorization, 2026
2026
-
[25]
How Muon’s spectral design benefits generalization: A study on imbalanced data, 2025
Bhavya Vasudeva, Puneesh Deora, Yize Zhao, Vatsal Sharan, and Christos Thrampoulidis. How Muon’s spectral design benefits generalization: A study on imbalanced data, 2025
2025
-
[26]
Convergence bound and critical batch size of muon optimizer, 2025
Naoki Sato, Hiroki Naganuma, and Hideaki Iiduka. Convergence bound and critical batch size of muon optimizer, 2025
2025
-
[27]
AdaMuon: Adaptive Muon optimizer, 2025
Chongjie Si, Debing Zhang, and Wei Shen. AdaMuon: Adaptive Muon optimizer, 2025. arXiv preprint
2025
-
[28]
OrScale: Orthogonalised optimization with layer-wise trust-ratio scaling, 2026
Yuxuan Lou and Yang You. OrScale: Orthogonalised optimization with layer-wise trust-ratio scaling, 2026. arXiv preprint
2026
-
[29]
AMUSE: Anytime Muon with stable gradient evaluation, 2026
Jueun Kim, Baekrok Shin, Jihun Yun, Beomhan Baek, Minhak Song, and Chulhee Yun. AMUSE: Anytime Muon with stable gradient evaluation, 2026. arXiv preprint
2026
-
[30]
TrasMuon: Trust-region adaptive scaling for orthogonalized momentum optimizers, 2026
Peng Cheng, Jiucheng Zang, Qingnan Li, Liheng Ma, Yufei Cui, Yingxue Zhang, Boxing Chen, Ming Jian, and Wen Tong. TrasMuon: Trust-region adaptive scaling for orthogonalized momentum optimizers, 2026. arXiv preprint
2026
-
[31]
Spectral Dynamics in Deep Networks: Feature Learning, Outlier Escape, and Learning Rate Transfer
Clarissa Lauditi, Cengiz Pehlevan, and Blake Bordelon. Spectral dynamics in deep networks: Feature learning, outlier escape, and learning rate transfer. 2026. ArXiv preprint 2605.07870. DOI 10.48550/arXiv.2605.07870
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07870 2026
-
[32]
Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J
Essential AI, Ishaan Shah, Anthony M. Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J. Shah, Khoi Nguyen, Kurt Smith, Michael Callahan, Michael Pust, Mohit Parmar, Peter Rushton, Platon Mazarakis, Ritvik Kapila, Saurabh Srivastava, Somanshu Singla, Tim Romanski, Yash Vanjani, and Ashis...
2025
-
[33]
An empirical model of large-batch training, 2018
Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training, 2018
2018
-
[34]
Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V
Samuel L. Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V. Le. Don’t decay the learning rate, increase the batch size. InProceedings of the International Conference on Learning Representations (ICLR), 2018
2018
-
[35]
How does critical batch size scale in pre-training?, 2024
Hanlin Zhang, Depen Morwani, Nikhil Vyas, Jingfeng Wu, Difan Zou, Udaya Ghai, Dean Foster, and Sham Kakade. How does critical batch size scale in pre-training?, 2024
2024
-
[36]
Critical batch size revisited: A simple empirical approach to large-batch language model training, 2025
William Merrill, Shane Arora, Dirk Groeneveld, and Hannaneh Hajishirzi. Critical batch size revisited: A simple empirical approach to large-batch language model training, 2025
2025
-
[37]
The Newton-Muon optimizer, 2026
Zhehang Du and Weijie Su. The Newton-Muon optimizer, 2026. arXiv preprint
2026
-
[38]
Muon 2: Boosting Muon via adaptive second-moment preconditioning, 2026
Ziyue Liu, Ruijie Zhang, Zhengyang Wang, Yequan Zhao, Yupeng Su, Zi Yang, and Zheng Zhang. Muon 2: Boosting Muon via adaptive second-moment preconditioning, 2026. arXiv preprint. 15
2026
-
[39]
Spectral flattening is all Muon needs: How orthogonalization controls learning rate and convergence, 2026
Tien-Phat Nguyen, Truong Nguyen, Minh-Phuc Truong, Tuc Nguyen, James Bailey, and Trung Le. Spectral flattening is all Muon needs: How orthogonalization controls learning rate and convergence, 2026. arXiv preprint
2026
-
[40]
Muon is not that special: Random or inverted spectra work just as well, 2026
Zakhar Shumaylov, Natha¨ el Da Costa, Peter Zaika, B´ alint Mucs´ anyi, Alex Massucco, Yoav Gelberg, Carola- Bibiane Sch¨ onlieb, Yarin Gal, and Philipp Hennig. Muon is not that special: Random or inverted spectra work just as well, 2026. arXiv preprint
2026
-
[41]
Tetiana Parshakova, Ahmed Khaled, Michael Crawshaw, Guillaume Garrigos, and Robert M. Gower. Muon does not converge on convex lipschitz functions, 2026. arXiv preprint
2026
-
[42]
Rethinking Muon beyond pretraining: Spectral failures and high-pass remedies for VLA and RLVR, 2026
Chongyu Fan, Gaowen Liu, Mingyi Hong, Ramana Rao Kompella, and Sijia Liu. Rethinking Muon beyond pretraining: Spectral failures and high-pass remedies for VLA and RLVR, 2026. arXiv preprint
2026
-
[43]
Southworth, Shuai Jiang, Daniel McBride, Eric C
Ben S. Southworth, Shuai Jiang, Daniel McBride, Eric C. Cyr, and Stephen Thomas. Muon in vision transformers: Optimizer-recipe interactions and gradient spectra, 2026. arXiv preprint
2026
-
[44]
When Muon optimizer meets adversarial training: A theoretical and empirical study, 2026
Jun Yan, Weiquan Huang, Jiankai Zuo, Yujian Mo, Xi Fang, Chengliang Wu, and Zeming Wei. When Muon optimizer meets adversarial training: A theoretical and empirical study, 2026. arXiv preprint
2026
-
[45]
DP-Muon: Differentially private optimization via matrix-orthogonalized momentum, 2026
Jihwan Kim and Chenglin Fan. DP-Muon: Differentially private optimization via matrix-orthogonalized momentum, 2026. arXiv preprint
2026
-
[46]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of the International Conference on Learning Representations (ICLR), 2019
2019
-
[47]
Perturbation bounds for the polar decomposition.SIAM Journal on Matrix Analysis and Applications, 14(2):588–597, 1993
Roy Mathias. Perturbation bounds for the polar decomposition.SIAM Journal on Matrix Analysis and Applications, 14(2):588–597, 1993
1993
-
[48]
G. W. Stewart and Ji-Guang Sun.Matrix Perturbation Theory. Academic Press, 1990. A Scope Comparison with Concurrent Work Table 2: Scope comparison: this paper versus concurrent work on Muon and Muon-like optimizers. Referenced from Section 3. Work Setting Main theorem Relation
1990
-
[49]
Classification Max-margin implicit bias Complementary
-
[50]
Classification Max-margin (homogeneous) Complementary
-
[51]
LoRA (reg.) Uniform spectral growth Consistent w/ Thm. 1
-
[52]
Equal-rate PC learning Consistent w/ Thm
Bilinear cls. Equal-rate PC learning Consistent w/ Thm. 1(iv)
-
[53]
LLM pretraining Practical scaling Empirical motivation
-
[54]
4 This paper Regression (MSE) Cond
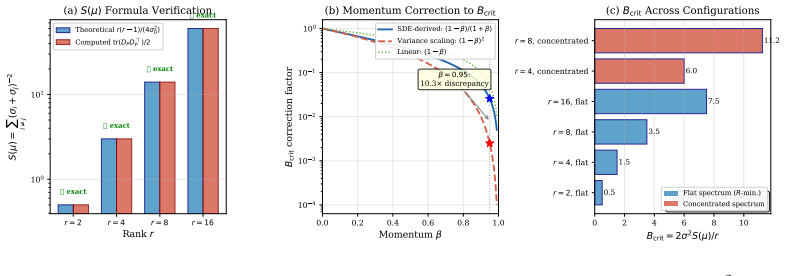
Polar-map SGD Convergence-rateB crit Complementary to Thm. 4 This paper Regression (MSE) Cond. spectral dyn. onM— B Proofs of Main Results B.1 Full Proof of Theorem 1: Spectral Dynamics We prove the four parts in order. The pairwise spectral functional is Rpw(W) =− X i̸=j log σi(W) +σ j(W) .(12) 16 Setup. W∈R m×n has SVD W = UΣV ⊤, Σ = diag(σ1, . . . , σr...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.