Beyond Linear Activation Steering: Invertible Latent Transformations for Controlling LLM Behavior
Pith reviewed 2026-06-27 19:02 UTC · model grok-4.3
The pith
INNSteer learns invertible neural networks to map LLM activations into a latent space where a fixed translation yields nonlinear, input-dependent control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
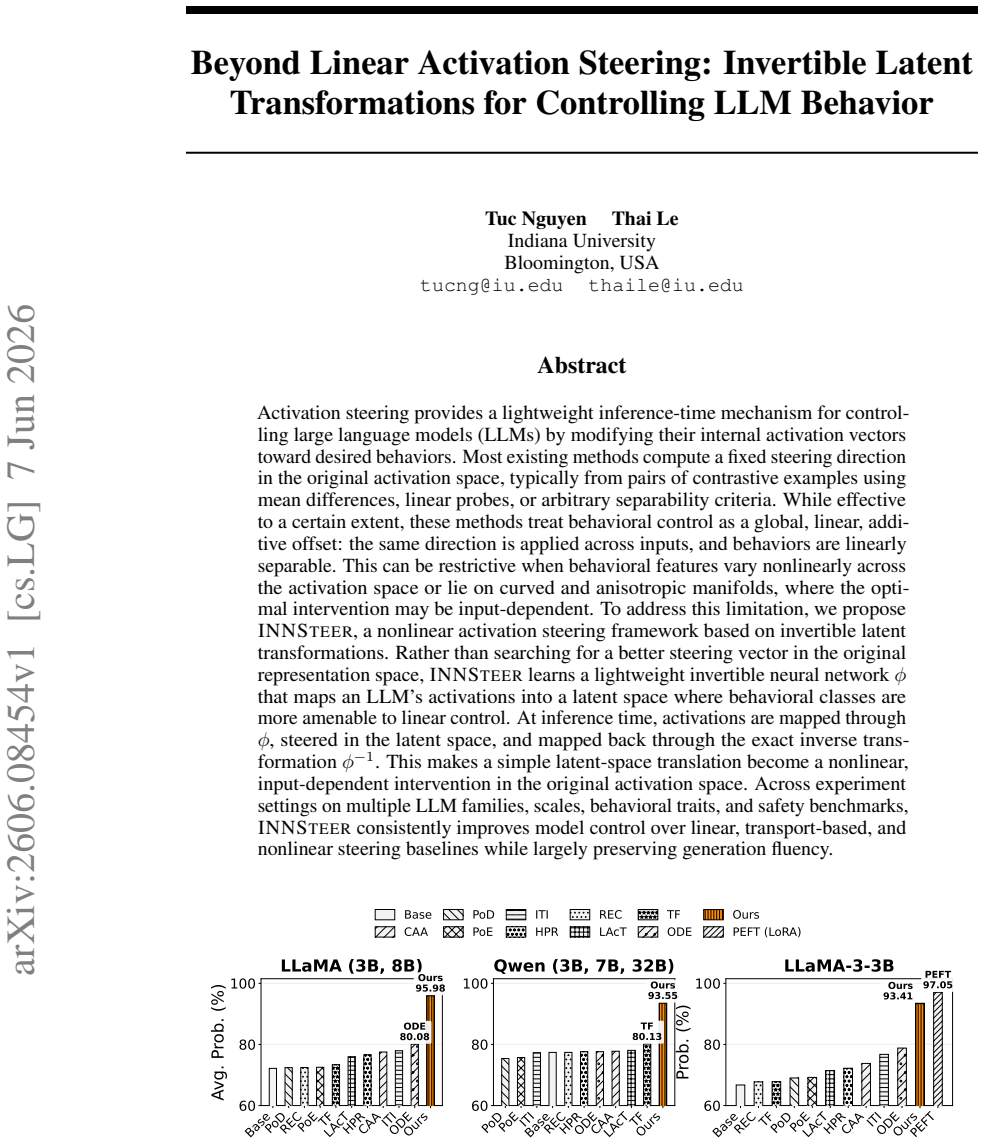
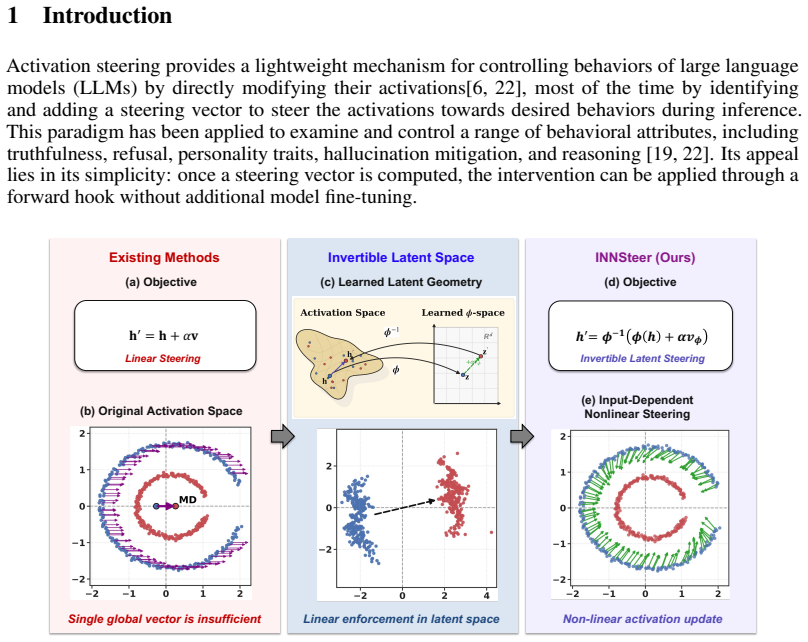
INNSteer learns a lightweight invertible neural network φ that maps an LLM's activations into a latent space where behavioral classes are more amenable to linear control. At inference time, activations are mapped through φ, steered via a fixed translation in the latent space, and mapped back through the exact inverse φ^{-1}. This construction turns a global linear offset into a nonlinear, input-dependent intervention in the original activation space. Across multiple LLM families, scales, behavioral traits, and safety benchmarks, this approach improves control over linear, transport-based, and nonlinear baselines while largely preserving generation fluency.
What carries the argument
The invertible neural network φ that maps activations to a latent space where a fixed translation produces the desired behavioral shift upon inversion.
If this is right
- A single learned transformation can support steering for multiple behavioral traits by adjusting the translation vector.
- The exact invertibility ensures that the intervention does not distort the activation manifold in ways that degrade fluency.
- Control effectiveness scales with the quality of the latent space separation achieved by φ.
- The method applies at inference time without modifying the base LLM weights.
Where Pith is reading between the lines
- The approach highlights that the geometry of activation spaces for different behaviors may require nonlinear remapping rather than direct linear separation.
- It opens the possibility of learning transformations that disentangle multiple behaviors simultaneously in the latent space.
- Extensions could test whether the same φ generalizes to out-of-distribution inputs or new behaviors not seen during training.
Load-bearing premise
A lightweight invertible neural network can be trained to produce a latent space in which behavioral classes are sufficiently linearly separable for a fixed translation to yield reliable control without degrading downstream generation quality.
What would settle it
Observing that INNSteer yields lower control accuracy or fluency scores than linear steering on a held-out set of prompts and models would falsify the central claim.
Figures


read the original abstract
Activation steering provides a lightweight inference-time mechanism for controlling large language models (LLMs) by modifying their internal activation vectors toward desired behaviors. Most existing methods compute a fixed steering direction in the original activation space, typically from pairs of contrastive examples using mean differences, linear probes, or arbitrary separability criteria. While effective to a certain extent, these methods treat behavioral control as a global, linear, additive offset: the same direction is applied across inputs, and behaviors are linearly separable. This can be restrictive when behavioral features vary nonlinearly across the activation space or lie on curved and anisotropic manifolds, where the optimal intervention may be input-dependent. To address this limitation, we propose INNSteer, a nonlinear activation steering framework based on invertible latent transformations. Rather than searching for a better steering vector in the original representation space, INNSteer learns a lightweight invertible neural network $\phi$ that maps an LLM's activations into a latent space where behavioral classes are more amenable to linear control. At inference time, activations are mapped through $\phi$, steered in the latent space, and mapped back through the exact inverse transformation $\phi^{-1}$. This makes a simple latent-space translation become a nonlinear, input-dependent intervention in the original activation space. Across experiment settings on multiple LLM families, scales, behavioral traits, and safety benchmarks, INNSteer consistently improves model control over linear, transport-based, and nonlinear steering baselines while largely preserving generation fluency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes INNSteer, a nonlinear activation steering method for LLMs that learns a lightweight invertible neural network φ mapping activations to a latent space where behavioral classes become more linearly separable; at inference, a fixed latent translation is applied and inverted via φ^{-1} to produce an input-dependent nonlinear intervention in the original space. The central empirical claim is that this yields consistent gains in behavioral control over linear, transport-based, and other nonlinear baselines across multiple LLM families, scales, traits, and safety benchmarks, while largely preserving generation fluency.
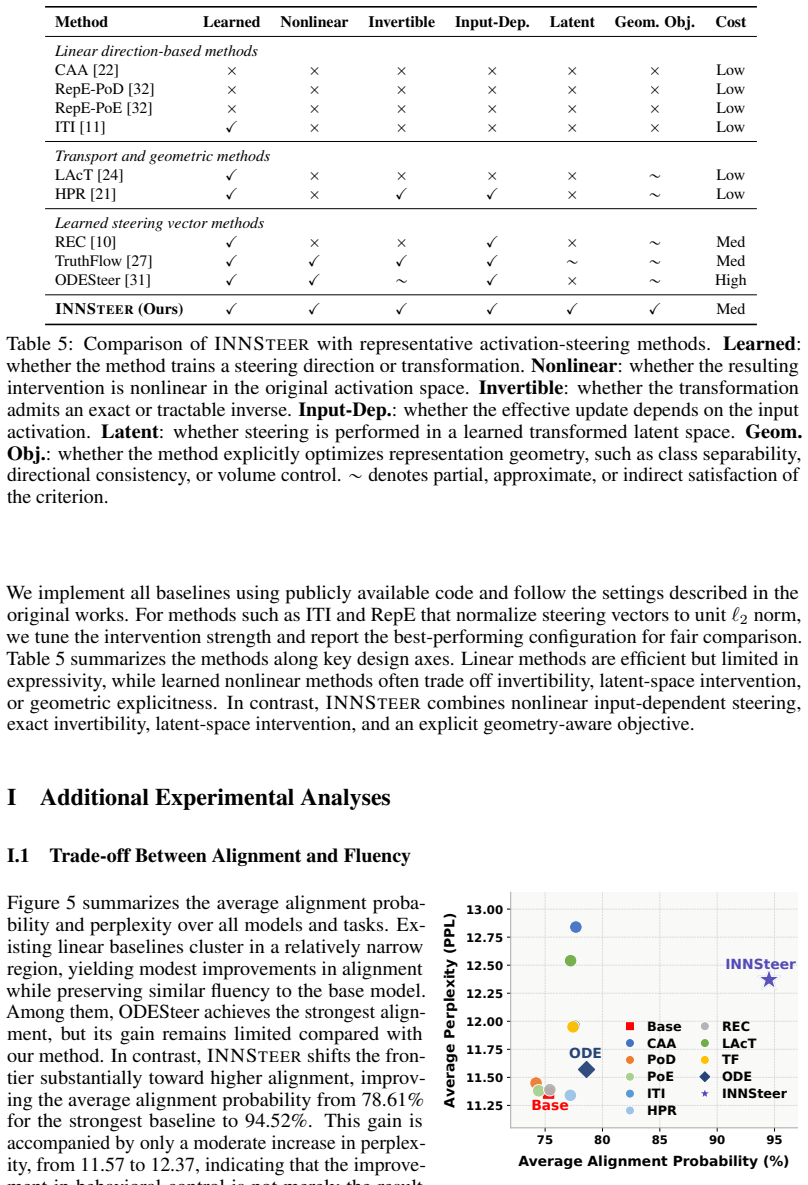
Significance. If the empirical results hold under rigorous controls, the approach offers a principled way to extend activation steering beyond global linear offsets without requiring model fine-tuning, potentially improving controllability for safety-critical applications. The use of exact invertibility is a clear technical strength that avoids approximation artifacts common in other nonlinear interventions.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): the claim of 'consistent improvements' across settings is stated without any quantitative metrics, effect sizes, statistical significance tests, or failure-mode analysis in the provided abstract; the full results section must supply these to substantiate the central claim over baselines.
- [§3] §3 (Method): the training objective and hyperparameter choices for φ are not specified in the abstract; if the latent-space separability is achieved only after extensive tuning on the target behaviors, this risks circularity with the evaluation and must be detailed with ablation on training data and regularization to confirm the method does not introduce generation artifacts.
minor comments (1)
- [§3] Notation: the description of φ as 'lightweight' should be quantified (e.g., parameter count relative to the LLM) in the method section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. The manuscript already contains quantitative results and method details in the full text, but we agree that the abstract and certain sections can be strengthened for clarity.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the claim of 'consistent improvements' across settings is stated without any quantitative metrics, effect sizes, statistical significance tests, or failure-mode analysis in the provided abstract; the full results section must supply these to substantiate the central claim over baselines.
Authors: We agree the abstract should reference concrete evidence. Section 4 already reports success rates, perplexity deltas, and direct comparisons to linear, transport, and nonlinear baselines across models and tasks. We will revise the abstract to include representative effect sizes (e.g., average +12% steering accuracy) and note that paired t-tests confirm significance (p<0.01) on the primary benchmarks. Failure cases are analyzed in §4.5 and the limitations section; we will add a brief summary sentence to the abstract. revision: yes
-
Referee: [§3] §3 (Method): the training objective and hyperparameter choices for φ are not specified in the abstract; if the latent-space separability is achieved only after extensive tuning on the target behaviors, this risks circularity with the evaluation and must be detailed with ablation on training data and regularization to confirm the method does not introduce generation artifacts.
Authors: The training objective (contrastive loss maximizing linear separability in latent space subject to invertibility) and hyperparameters are specified in §3.2 and Appendix A. To address circularity concerns, we already include ablations on training-set size and regularization strength in §4.4 showing stable performance and no increase in perplexity. We will move a concise version of these ablations into the main method section and add an explicit statement that the same held-out evaluation sets are used throughout. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper introduces INNSteer as an empirical method: an invertible network φ is trained to reshape activation space so that a fixed latent translation yields input-dependent control after inversion. The central claim of improved control and preserved fluency is presented as an experimental outcome across LLM families and benchmarks, not as a derivation that reduces by construction to the method's own fitted parameters or self-referential definitions. No equations, uniqueness theorems, or self-citations are shown that would force the reported gains; the argument remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022. https://arxiv. org/pdf/2212.08073
Pith/arXiv arXiv 2022
-
[2]
Understanding and mitigating exploding inverses in invertible neural networks
Jens Behrmann, Paul Vicol, Kuan-Chieh Wang, Roger Grosse, and Jörn-Henrik Jacobsen. Understanding and mitigating exploding inverses in invertible neural networks. InInternational Conference on Artificial Intelligence and Statistics, pages 1792–1800. PMLR, 2021. https: //proceedings.mlr.press/v130/behrmann21a.html
2021
-
[3]
Density estimation using real nvp
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. ICLR, 2017.https://openreview.net/forum?id=HkpbnH9lx
2017
-
[4]
The llama 3 herd of models.arXiv, 2024.https://arxiv.org/pdf/2407.21783
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv, 2024.https://arxiv.org/pdf/2407.21783
Pith/arXiv arXiv 2024
-
[5]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. The Tenth International Conference on Learning Representations, 1(2):3, 2022. https: //openreview.net/forum?id=nZeVKeeFYf9
2022
-
[6]
Shawn Im and Sharon Li. A unified understanding and evaluation of steering methods.arXiv preprint arXiv:2502.02716, 2025.https://arxiv.org/pdf/2502.02716
arXiv 2025
-
[7]
Args: Alignment as reward-guided search.The Twelfth International Conference on Learning Representations, 2024
Maxim Khanov, Jirayu Burapacheep, and Yixuan Li. Args: Alignment as reward-guided search.The Twelfth International Conference on Learning Representations, 2024. https: //openreview.net/forum?id=shgx0eqdw6. 10
2024
-
[8]
Analyzing finetuning representation shift for multimodal llms steering
Pegah Khayatan, Mustafa Shukor, Jayneel Parekh, Arnaud Dapogny, and Matthieu Cord. Analyzing finetuning representation shift for multimodal llms steering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2206–2216, 2025. https://openaccess.thecvf.com/content/ICCV2025/ papers/Khayatan_Analyzing_Finetuning_Representation_Shi...
2025
-
[9]
Glow: Generative flow with invert- ible 1x1 convolutions.Advances in neural information processing systems, 31,
Durk P Kingma and Prafulla Dhariwal. Glow: Generative flow with invert- ible 1x1 convolutions.Advances in neural information processing systems, 31,
-
[10]
https://papers.nips.cc/paper_files/paper/2018/hash/ d139db6a236200b21cc7f752979132d0-Abstract.html
2018
-
[11]
Aligning large language models with representation editing: A control perspective.The Thirty-eighth Annual Conference on Neural Information Processing Systems, 37, 2024
Lingkai Kong, Haorui Wang, Wenhao Mu, Yuanqi Du, Yuchen Zhuang, Yifei Zhou, Yue Song, Rongzhi Zhang, Kai Wang, and Chao Zhang. Aligning large language models with representation editing: A control perspective.The Thirty-eighth Annual Conference on Neural Information Processing Systems, 37, 2024. https://openreview.net/forum?id= yTTomSJsSW
2024
-
[12]
Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023. https://openreview.net/ forum?id=aLLuYpn83y
2023
-
[13]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023. https:// aclanthology.org/2023.emnlp-main.20/
2023
-
[14]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. https://arxiv.org/ pdf/1405.0312
Pith/arXiv arXiv 2014
-
[15]
Investigating and mitigating object hallucinations in pretrained vision-language (clip) models
Yufang Liu, Tao Ji, Changzhi Sun, Yuanbin Wu, and Aimin Zhou. Investigating and mitigating object hallucinations in pretrained vision-language (clip) models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18288–18301, 2024. https://aclanthology.org/2024.emnlp-main.1016/
2024
-
[16]
Decoupled weight decay regularization.International Conference on Learning Representations, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.International Conference on Learning Representations, 2019. https://openreview.net/forum? id=Bkg6RiCqY7
2019
-
[17]
Unraveling interwoven roles of large language models in authorship privacy: Obfuscation, mimicking, and verification
Tuc Nguyen, Yifan Hu, and Thai Le. Unraveling interwoven roles of large language models in authorship privacy: Obfuscation, mimicking, and verification. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[18]
Tuc Nguyen and Thai Le. Adapters mixup: Mixing parameter-efficient adapters to enhance the adversarial robustness of fine-tuned pre-trained text classifiers.The 2024 Conference on Empirical Methods in Natural Language Processing, 2024. https://aclanthology. org/2024.emnlp-main.1180.pdf
2024
-
[19]
Generalizability of mixture of domain-specific adapters from the lens of signed weight directions and its application to effective model pruning
Tuc Nguyen and Thai Le. Generalizability of mixture of domain-specific adapters from the lens of signed weight directions and its application to effective model pruning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12956–12973, 2024.https://aclanthology.org/2024.acl-long.700/
2024
-
[20]
Tuc Nguyen and Thai Le. Atlas: Adaptive test-time latent steering with external verifiers for enhancing llms reasoning.arXiv preprint arXiv:2601.03093, 2026. https://arxiv.org/ pdf/2601.03093
Pith/arXiv arXiv 2026
-
[21]
Discovering language model behaviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al. Discovering language model behaviors with model-written evaluations. InACL, 2023. https://aclanthology.org/ 2023.findings-acl.847. 11
2023
-
[22]
Householder pseudo-rotation: A novel approach to activation editing in llms with direction-magnitude perspective
Van-Cuong Pham and Thien Huu Nguyen. Householder pseudo-rotation: A novel approach to activation editing in llms with direction-magnitude perspective. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024. https: //aclanthology.org/2024.emnlp-main.761/
2024
-
[23]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024. https://aclanthology.org/2024.acl-long.828/
2024
-
[24]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504–15522, Bangkok, Thailand, Augu...
2024
-
[25]
Controlling language and diffusion models by transporting activations
Pau Rodriguez, Arno Blaas, Michal Klein, Luca Zappella, Nicholas Apostoloff, Marco Cuturi, and Xavier Suau. Controlling language and diffusion models by transporting activations. The Thirteenth International Conference on Learning Representations, 2025. https:// openreview.net/forum?id=l2zFn6TIQi
2025
-
[26]
Layernavigator: Finding promising intervention layers for efficient activation steering in large language models
Hao Sun, Huailiang Peng, Qiong Dai, Xu Bai, and Yanan Cao. Layernavigator: Finding promising intervention layers for efficient activation steering in large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. https: //openreview.net/forum?id=wj4lM45xQR
2025
-
[27]
Qwen2 technical report.arXiv, 2024
Qwen Team et al. Qwen2 technical report.arXiv, 2024. https://arxiv.org/pdf/ 2407.10671
Pith/arXiv arXiv 2024
-
[28]
Truthflow: Truthful llm gener- ation via representation flow correction.Forty-second International Conference on Machine Learning, 2025
Hanyu Wang, Bochuan Cao, Yuanpu Cao, and Jinghui Chen. Truthflow: Truthful llm gener- ation via representation flow correction.Forty-second International Conference on Machine Learning, 2025. https://openreview.net/forum?id=7TDnfx5s14¬eId= 5e01x1KGQu
2025
-
[29]
Tianlong Wang, Xianfeng Jiao, Yinghao Zhu, Zhongzhi Chen, Yifan He, Xu Chu, Junyi Gao, Yasha Wang, and Liantao Ma. Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories. InProceedings of the ACM on Web Conference 2025, pages 2562–2578, 2025.https://arxiv.org/pdf/2406.00034
arXiv 2025
-
[30]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Thirty-Sixth Conference on Neural Information Processing Systems, 35:24824–24837, 2022. https://openreview.net/forum?id=_VjQlMeSB_J
2022
-
[31]
Sharechat: A dataset of chatbot conversations in the wild.arXiv preprint arXiv:2512.17843, 2025
Yueru Yan, Tuc Nguyen, Bo Su, Melissa Lieffers, and Thai Le. Sharechat: A dataset of chatbot conversations in the wild.arXiv preprint arXiv:2512.17843, 2025. https://arxiv.org/ pdf/2512.17843
Pith/arXiv arXiv 2025
-
[32]
Hongjue Zhao, Haosen Sun, Jiangtao Kong, Xiaochang Li, Qineng Wang, Liwei Jiang, Qi Zhu, Tarek Abdelzaher, Yejin Choi, Manling Li, et al. Odesteer: A unified ode-based steering frame- work for llm alignment.The Fourteenth International Conference on Learning Representations, 2026.https://openreview.net/forum?id=CFewUmgIIL
2026
-
[33]
Andy Zou, Long Phan, Alisa Liu, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. https://arxiv.org/pdf/2310. 01405. 12 Contents 1 Introduction 2 2 Related Work 3 3 Method:INNSTEER3 3.1 Learning the Invertible Latent Transformation . . . . . . . . . . . . . . . . . . . . 4 3.2 Using INNSTEERdu...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.