An Empirical Comparison of General Context-Free Parsers
Pith reviewed 2026-06-27 17:53 UTC · model grok-4.3
The pith
Generalized parsers like GLR incur only a 3x median slowdown over LR(1) on deterministic grammars.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
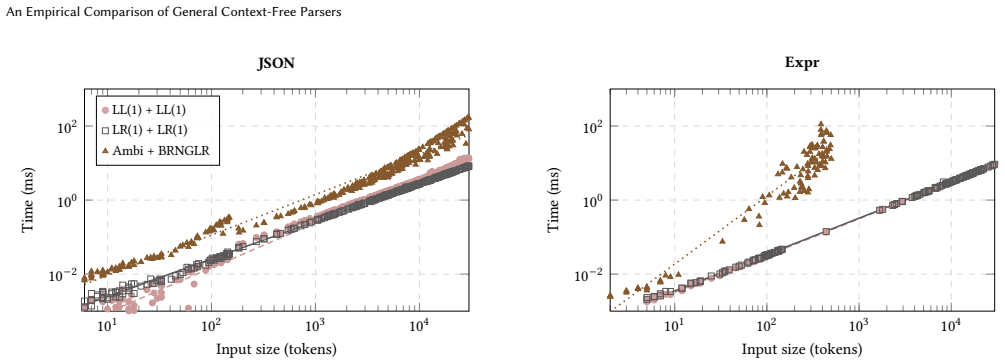
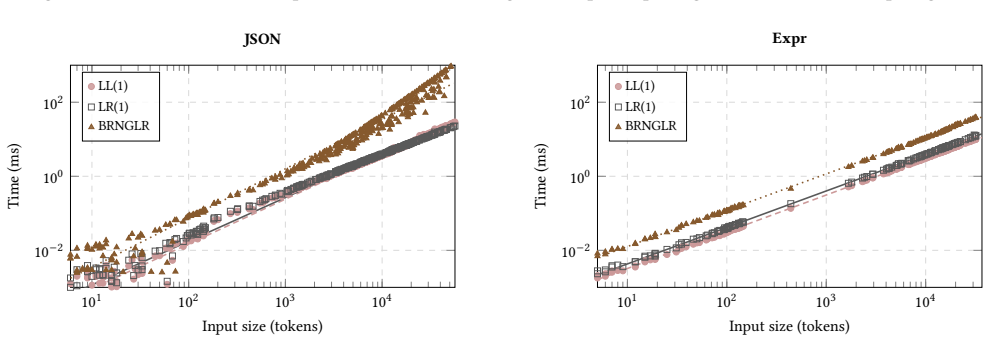
On deterministic grammars the GLR family incurs only a 3x median slowdown over LR(1), with narrow and predictable variance; among the generalized algorithms tested, GLR is the clear performance winner and therefore a practical default choice for software engineering tools.
What carries the argument
A single Rust codebase that implements six generalized parsers and two deterministic baselines with shared data structures and identical parse-tree extraction, then measures them on the same 22 grammars.
If this is right
- GLR becomes a practical default parser for language servers, static analyzers, and fuzzers.
- Language designers can retain more expressive grammars without rewriting them to fit deterministic constraints.
- The performance cost of moving from deterministic to general parsing is both small and predictable on real-world inputs.
- Variance across inputs stays narrow enough that worst-case behavior remains usable in practice.
Where Pith is reading between the lines
- Tool builders could safely replace hand-written deterministic parsers with GLR in new projects and expect modest, stable overhead.
- The same benchmark setup could be reused to test whether the 3x factor holds for even larger or more ambiguous grammars.
- If the result generalizes, ambiguity-handling features in general parsers become available at acceptable cost for everyday use.
Load-bearing premise
The six Rust implementations are comparably optimized and the 22 grammars plus shared extraction code measure algorithmic cost rather than coding artifacts.
What would settle it
A deterministic grammar on which any GLR variant exceeds a 10x slowdown relative to LR(1) while the other measured algorithms remain competitive.
Figures


read the original abstract
Parsing underpins a vast range of software engineering tasks, from compilers and static analyzers to language servers and fuzz testing tools. Yet most parsers deployed in practice are deterministic (LL or LR), forcing developers not only to contort their grammars to fit the parser, but to simplify the very languages they design sacrificing expressiveness for the sake of parseability. General context-free parsers eliminate this constraint. Yet, despite decades of algorithmic development, no rigorous head-to-head comparison exists across the major families of parsing algorithms. We present the first unified, controlled benchmark of six generalized parsing algorithms: CYK, Valiant, Earley, GLL, RNGLR, and BRNGLR, plus deterministic LL(1) and LR(1) baselines, all implemented in Rust with shared data structures and parse-tree extraction, and evaluated across 22 grammars ranging from simple expressions to full C++ and Java. Our results show that the cost of generality is lower than widely assumed. On deterministic grammars, the GLR family incurs only a 3x median slowdown over LR(1), with a narrow and predictable variance. GLR is the clear performance winner among generalized parsers and a practical default choice for software engineering tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first unified benchmark of six generalized context-free parsers (CYK, Valiant, Earley, GLL, RNGLR, BRNGLR) plus LL(1) and LR(1) baselines, all implemented in Rust with shared data structures and parse-tree extraction code. Evaluated on 22 grammars from simple expressions to full C++ and Java, the central claim is that on deterministic grammars the GLR family incurs only a 3x median slowdown over LR(1) with narrow and predictable variance, making GLR the clear performance winner among generalized parsers and a practical default for software engineering tools.
Significance. If the measurements isolate algorithmic cost, the results would be significant for the field by quantifying the modest overhead of generality and providing a controlled head-to-head dataset that could guide parser selection in compilers, analyzers, and language servers. The use of a single Rust framework with shared components is a methodological strength that supports reproducibility of the comparison.
major comments (2)
- [Implementation and Experimental Setup] Implementation section: the headline claim that GLR incurs only a 3x median slowdown (and is the clear winner) rests on the assumption that the six generalized parsers received equivalent optimization effort, data-structure choices, and constant-factor tuning. The manuscript notes shared data structures and parse-tree extraction but supplies no profiling data, effort logs, or verification that coding artifacts were controlled, leaving open the possibility that measured differences reflect implementation rather than algorithm.
- [Results] Results section (performance tables): the statements of 'narrow and predictable variance' for GLR on deterministic grammars require explicit reporting of per-grammar statistics (e.g., interquartile range or standard deviation across the 22 grammars) and confirmation that no post-hoc result filtering occurred; without these, the variance claim cannot be assessed independently of the raw timing data.
minor comments (2)
- [Experimental Setup] Grammar selection criteria should be stated more explicitly (e.g., size, ambiguity level, or source) to support replication and evaluation of how representative the 22 grammars are.
- [Abstract] The abstract's assertion that 'no rigorous head-to-head comparison exists' should be tempered with citations to prior empirical parser studies for context.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Implementation and Experimental Setup] Implementation section: the headline claim that GLR incurs only a 3x median slowdown (and is the clear winner) rests on the assumption that the six generalized parsers received equivalent optimization effort, data-structure choices, and constant-factor tuning. The manuscript notes shared data structures and parse-tree extraction but supplies no profiling data, effort logs, or verification that coding artifacts were controlled, leaving open the possibility that measured differences reflect implementation rather than algorithm.
Authors: All six generalized parsers, along with the baselines, were implemented by the same team within a unified Rust framework specifically to control for implementation differences. Shared components include grammar representation, input handling, and parse tree extraction code. While detailed effort logs and per-parser profiling data were not collected, the design of the benchmark emphasizes algorithmic isolation through this shared infrastructure. We will revise the Implementation section to include a more detailed description of the development process and uniform tuning strategies applied across all parsers to further address this concern. revision: yes
-
Referee: [Results] Results section (performance tables): the statements of 'narrow and predictable variance' for GLR on deterministic grammars require explicit reporting of per-grammar statistics (e.g., interquartile range or standard deviation across the 22 grammars) and confirmation that no post-hoc result filtering occurred; without these, the variance claim cannot be assessed independently of the raw timing data.
Authors: We confirm that no post-hoc filtering was applied; all 22 grammars were evaluated and reported. The raw data is available in the supplementary materials. To make the variance claim more robust and independently verifiable, we will add explicit per-grammar statistics, including the interquartile range and standard deviation of the slowdown factors for the GLR family on deterministic grammars, in a revised Results section or as an additional table. revision: yes
Circularity Check
No circularity: pure empirical benchmark with no derivations
full rationale
The paper reports runtime measurements from Rust implementations of six generalized parsers plus LR(1)/LL(1) baselines across 22 grammars. No equations, first-principles derivations, fitted parameters, or predictions appear in the abstract or described content. All claims rest on direct observations of execution time rather than quantities defined in terms of other quantities within the paper. Self-citations (if any) concern prior algorithmic descriptions and do not form a load-bearing chain that reduces the benchmark results to the inputs by construction. The experiment is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ali Afroozeh and Anastasia Izmaylova. 2015. Faster, Practical GLL Parsing. In Proc. Int. Conf. Compiler Construction (CC). Springer, 89–108. https://doi.org/10. 1007/978-3-662-46663-6_5
2015
-
[2]
Ali Afroozeh and Anastasia Izmaylova. 2015. One Parser to Rule Them All. InProc. ACM Symp. New Ideas, New Paradigms, Refl. Program. Softw. (Onward!). 151–170. https://doi.org/10.1145/2814228.2814242
-
[3]
V. L. Arlazarov, E. A. Dinic, M. A. Kronrod, and I. A. Faradjev. 1970. On econom- ical construction of the transitive closure of an oriented graph.Soviet Mathe- matics Doklady11, 5 (1970), 1209–1210
1970
-
[4]
J. Aycock. 2002. Practical Earley Parsing.Comput. J.45, 6 (June 2002), 620–630. https://doi.org/10.1093/comjnl/45.6.620
-
[5]
Max Brunsfeld et al. 2024. Tree-sitter. Zenodo. https://doi.org/10.5281/zenodo. 4619183 Version 0.25.3
-
[6]
Igor Dejanović. 2022. Parglare: A LR/GLR parser for Python.Science of Computer Programming214 (2022), 102734. https://doi.org/10.1016/j.scico.2021.102734
-
[7]
Jay Earley. 1970. An Efficient Context-Free Parsing Algorithm.Commun. ACM 13, 2 (Feb. 1970), 94–102. https://doi.org/10.1145/362007.362035
-
[8]
2021.Enumerating and analyzing 40+ non-V8 JavaScript implemen- tations
Phil Eaton. 2021.Enumerating and analyzing 40+ non-V8 JavaScript implemen- tations. https://notes.eatonphil.com/javascript-implementations.html
2021
-
[9]
2021.Parser generators vs
Phil Eaton. 2021.Parser generators vs. handwritten parsers: surveying major lan- guage implementations in 2021. https://notes.eatonphil.com/parser-generators- vs-handwritten-parsers-survey-2021.html
2021
-
[10]
Giorgios Economopoulos, Paul Klint, and Jurgen Vinju. 2009. Faster Scan- nerless GLR Parsing. InCompiler Construction, Oege de Moor and Michael I. Schwartzbach (Eds.). Springer, Berlin, Heidelberg, 126–141. https://doi.org/10. 1007/978-3-642-00722-4_10
2009
-
[11]
2006.Generalised LR Parsing Algorithms
Giorgios Robert Economopoulos. 2006.Generalised LR Parsing Algorithms. Ph. D. Dissertation. Royal Holloway, University of London
2006
-
[12]
Bryan Ford. 2004. Parsing Expression Grammars: A Recognition-based Syntac- tic Foundation.SIGPLAN Not.39, 1 (Jan. 2004), 111–122. https://doi.org/10.1145/ 982962.964011
arXiv 2004
-
[13]
json parser
GitHub. 2026. Search Results for “json parser” Repositories. https://github. com/search?q=json+parser&type=repositories. Accessed: March 2026. Returns 29,800+ repositories
2026
-
[14]
Dick Grune and Ceriel J. H. Jacobs. 2008. Introduction to Parsing. InParsing Techniques: A Practical Guide. Springer New York, New York, NY, 61–102. https: //doi.org/10.1007/978-0-387-68954-8_3
-
[15]
Adrian Johnstone. 2023. A Reference GLL Implementation. InProc. ACM SIG- PLAN Int. Conf. Softw. Lang. Eng. (SLE). 43–55. https://doi.org/10.1145/3623476. 3623521
-
[16]
Adrian Johnstone, Elizabeth Scott, and Giorgios Economopoulos. 2006. Evaluat- ing GLR Parsing Algorithms.Sci. Comput. Program.61, 3 (Aug. 2006), 228–244. https://doi.org/10.1016/j.scico.2006.04.004
-
[17]
2023.Parsing: a Timeline
Jeffrey Kegler. 2023.Parsing: a Timeline. https://jeffreykegler.github.io/ personal/timeline_v3 Revision 9, 6 July 2023. Accessed: 2026-03-27
2023
-
[18]
Lukas Kirschner, Ezekiel Soremekun, Rahul Gopinath, and Andreas Zeller. 2022. Input repair via synthesis and lightweight error feedback.arXiv preprint arXiv:2208.08235(2022)
arXiv 2022
-
[19]
Paul Klint, Ralf Lämmel, and Chris Verhoef. 2005. Toward an engineering disci- pline for grammarware.ACM Transactions on Software Engineering and Method- ology (TOSEM)14, 3 (2005), 331–380
2005
-
[20]
Donald E. Knuth. 1965. On the Translation of Languages from Left to Right. Inform. Control8, 6 (Dec. 1965), 607–639. https://doi.org/10.1016/S0019-9958(65) 90426-2
-
[21]
Ralf Lämmel. 2001. Grammar testing. InInternational Conference on Fundamen- tal Approaches to Software Engineering. Springer, 201–216
2001
-
[22]
LangSec Workshop. 2026. Language-theoretic Security (LangSec). https:// langsec.org/. Accessed: March 2026
2026
-
[23]
Joop M. I. M. Leo. 1991. A General Context-Free Parsing Algorithm Running in Linear Time on Every LR(𝑘) Grammar without Using Lookahead.Theoret. Comput. Sci.82, 1 (May 1991), 165–176. https://doi.org/10.1016/0304-3975(91) 90180-A
-
[24]
Scott McPeak and George C. Necula. 2004. Elkhound: A Fast, Practical GLR Parser Generator. InProc. Int. Conf. Compiler Construction (CC). Springer, 73–88. https://doi.org/10.1007/978-3-540-24723-4_6
-
[25]
Terence Parr, Sam Harwell, and Kathleen Fisher. 2014. Adaptive LL(*) Parsing: The Power of Dynamic Analysis.SIGPLAN Not.49, 10 (Oct. 2014), 579–598. https://doi.org/10.1145/2714064.2660202
-
[26]
D. J. Salomon and G. V. Cormack. 1989. Scannerless NSLR(1) parsing of pro- gramming languages.SIGPLAN Not.24, 7 (June 1989), 170–178. https://doi.org/ 10.1145/74818.74833
-
[27]
Elizabeth Scott and Adrian Johnstone. 2006. Right Nulled GLR Parsers.ACM Trans. Program. Lang. Syst.28, 4 (July 2006), 577–618. https://doi.org/10.1145/ 1146809.1146810
arXiv 2006
-
[28]
Elizabeth Scott and Adrian Johnstone. 2010. GLL Parsing.Electron. Notes Theor. Comput. Sci.253, 7 (Sept. 2010), 177–189. https://doi.org/10.1016/j.entcs.2010. 08.041
-
[29]
Elizabeth Scott and Adrian Johnstone. 2016. Structuring the GLL parsing algo- rithm for performance.Science of Computer Programming125 (Sept. 2016), 1–22. https://doi.org/10.1016/j.scico.2016.04.003
-
[30]
Elizabeth Scott and Adrian Johnstone. 2026. Earley Table Traversing Parsers. Sci. Comput. Program.247 (Jan. 2026), 103335. https://doi.org/10.1016/j.scico. 2025.103335
-
[31]
Elizabeth Scott, Adrian Johnstone, and Rob Economopoulos. 2007. BRNGLR: A Cubic Tomita-style GLR Parsing Algorithm.Acta Inform.44, 6 (Oct. 2007), 427–461. https://doi.org/10.1007/s00236-007-0054-z
-
[32]
Volker Strassen. 1969. Gaussian Elimination is not Optimal.Numer. Math.13, 4 (Aug. 1969), 354–356. https://doi.org/10.1007/BF02165411
-
[33]
1986.Efficient Parsing for Natural Language
Masaru Tomita. 1986.Efficient Parsing for Natural Language. Springer, Boston, MA. https://doi.org/10.1007/978-1-4757-1885-0
-
[34]
2011.Parsing: The Solved Problem That Isn’t
Laurence Tratt. 2011.Parsing: The Solved Problem That Isn’t. https://tratt.net/ laurie/blog/2011/parsing_the_solved_problem_that_isnt.html
2011
-
[35]
Leslie G. Valiant. 1975. General Context-Free Recognition in Less than Cubic Time.J. Comput. System Sci.10, 2 (April 1975), 308–315. https://doi.org/10.1016/ S0022-0000(75)80046-8
1975
-
[36]
Mark van den Brand. [n. d.]. Current Parsing Techniques in Software Reno- vation Considered Harmful. https://www.cs.vu.nl/~x/ref/ref.html. Accessed: 2026-03-18
2026
-
[37]
Mark G. J. Van Den Brand, Jeroen Scheerder, Jurgen J. Vinju, and Eelco Visser. 2002.Disambiguation Filters for Scannerless Generalized LR Parsers. Lecture Notes in Computer Science, Vol. 2304. Springer Berlin Heidelberg, Berlin, Hei- delberg, 143–158. https://doi.org/10.1007/3-540-45937-5_12
-
[38]
Mark G. J. van den Brand, A. Sellink, and C. Verhoef. 1998. Current Parsing Techniques in Software Renovation Considered Harmful. InProc. Int. Workshop Program Comprehension (IWPC). 108
1998
-
[39]
2019.thomwiggers/m4ri-rust v0.3.2
Thom Wiggers and Renovate Bot. 2019.thomwiggers/m4ri-rust v0.3.2. https: //doi.org/10.5281/zenodo.3377514
-
[40]
Daniel H. Younger. 1967. Recognition and Parsing of Context-Free Languages in Time𝑛 3.Inform. Control10, 2 (Feb. 1967), 189–208. https://doi.org/10.1016/ S0019-9958(67)80007-X
1967
-
[41]
Andreas Zeller, Rahul Gopinath, Marcel Böhme, Gordon Fraser, and Chris- tian Holler. 2024. Fuzzing with Grammars. InThe Fuzzing Book. CISPA Helmholtz Center for Information Security. https://www.fuzzingbook.org/ html/Grammars.html Retrieved 2024-06-30 18:31:28+02:00
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.