The Confidence Trap: Calibration Attacks for Graph Neural Networks
Pith reviewed 2026-06-27 18:59 UTC · model grok-4.3
The pith
UGCA increases Expected Calibration Error in GNNs while preserving classification accuracy via targeted edge perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
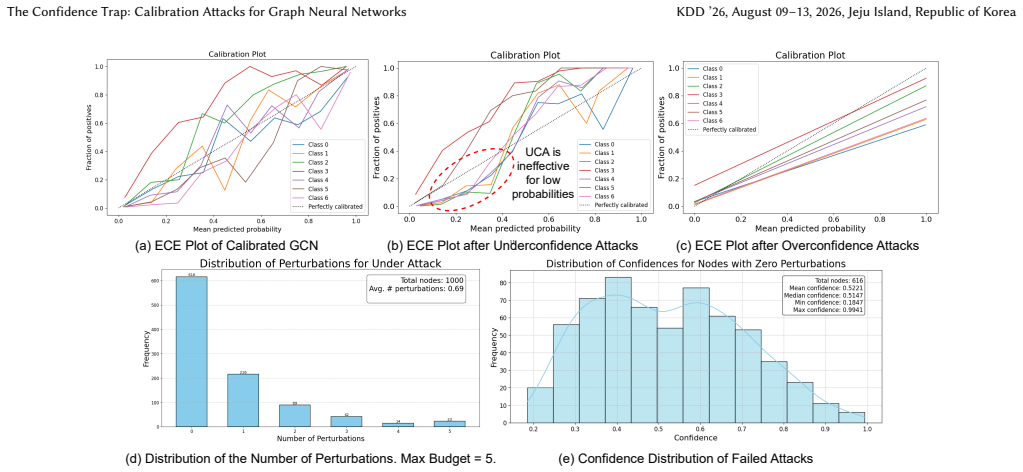
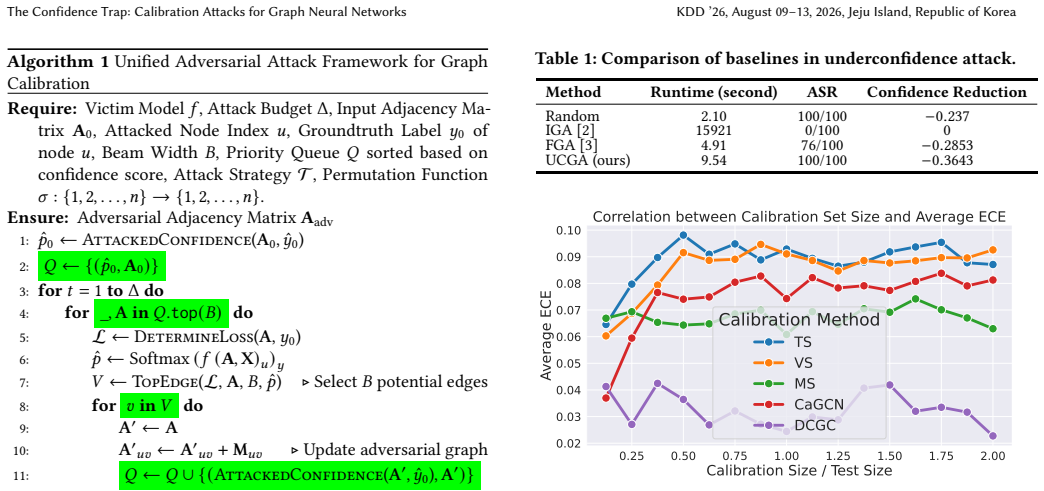
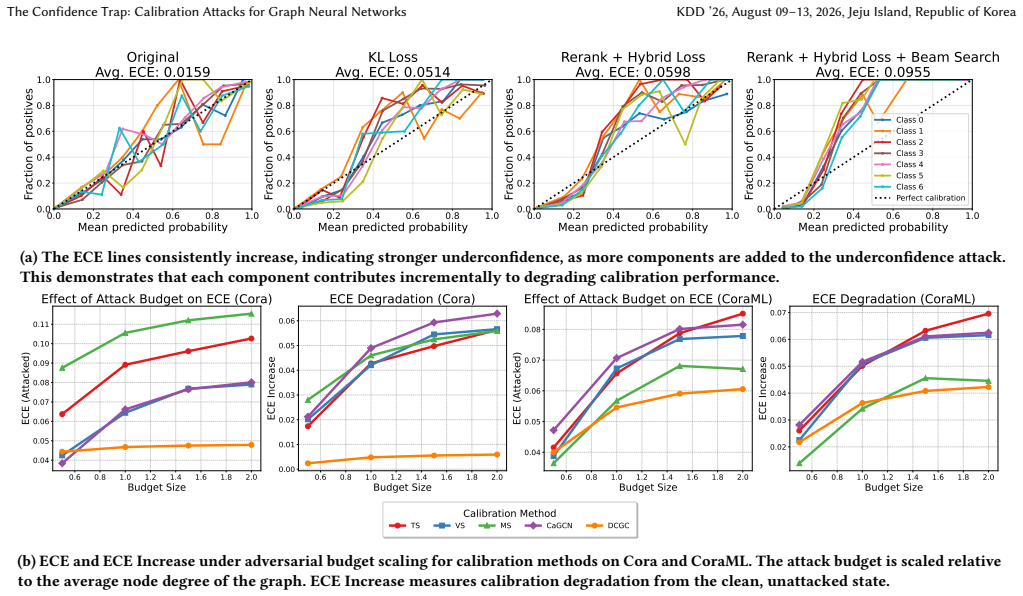
The central claim is that the Unified Graph Calibration Attack (UGCA) framework, which applies a KL-divergence loss to encourage uniform predictive distributions, a reranking mechanism and hybrid loss to avoid label flips, and beam search to explore perturbations, substantially raises Expected Calibration Error on GNNs while keeping classification accuracy unchanged. The paper further claims that models with stronger generalization or trained on higher-complexity datasets exhibit greater susceptibility under this threat model.
What carries the argument
UGCA is the central mechanism: a white-box attack on graph structure that combines KL-divergence loss for uniform outputs, reranking and hybrid loss for label stability, and beam search to optimize discrete edge changes.
If this is right
- Calibrated GNNs remain vulnerable to structural attacks that target confidence distributions without changing predicted labels.
- Models with higher classification accuracy become more susceptible to calibration attacks.
- Datasets with larger numbers of classes increase the calibration vulnerability of trained GNNs.
- The attack succeeds while preserving accuracy, indicating it isolates calibration as a distinct failure mode.
Where Pith is reading between the lines
- Calibration methods for GNNs may need explicit robustness terms against edge perturbations to remain reliable in practice.
- The reported link between accuracy and vulnerability suggests that scaling model performance could inadvertently heighten calibration risks on complex label sets.
- Similar attack strategies could be examined on non-GNN graph models or in settings with only black-box access to predictions.
Load-bearing premise
The reranking mechanism and hybrid loss can reduce unintended label flips from GNN sensitivity to edge perturbations without reducing the attack's ability to increase calibration error.
What would settle it
An experiment on standard GNN benchmarks in which UGCA perturbations produce no measurable rise in Expected Calibration Error or cause a drop in classification accuracy would falsify the central claim.
Figures

read the original abstract
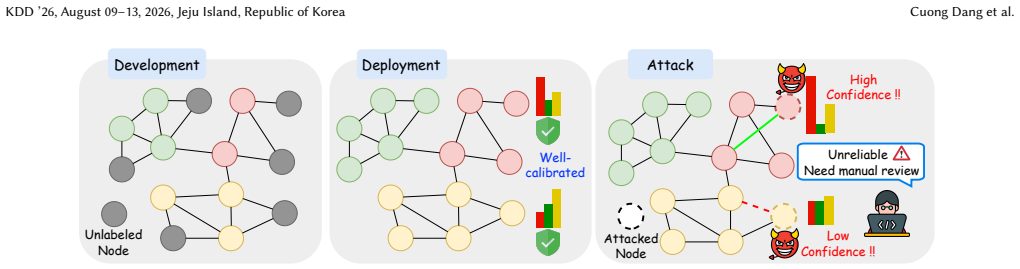
While confidence calibration is essential for trustworthy decision-making in safety-critical applications, the robustness of calibrated GNNs to adversarial structural perturbations remains largely unexplored. However, studying calibration attacks on graphs presents unique technical challenges: (1) the discrete nature of graph structures complicates gradient-based optimization, (2) existing underconfidence objectives fail to drive predictions toward uniform distributions, and (3) GNNs are highly sensitive to edge perturbations, often causing unintended label changes that violate attack constraints. To address these challenges, we propose a \textbf{Unified Graph Calibration Attack (UGCA)} framework designed for \textbf{worst-case (white-box) analysis} of GNN calibration robustness. UGCA introduces a KL-divergence loss to encourage uniform predictive distributions, a reranking mechanism to reduce label flipping, a hybrid loss to recover labels when violations occur, and beam search to explore a broader adversarial search space. We further provide theoretical insights linking model generalization, dataset complexity, and calibration vulnerability, showing that models with higher accuracy or trained on datasets with more classes are more susceptible under this threat model. Extensive experiments demonstrate that UGCA substantially increases Expected Calibration Error while preserving classification accuracy. Our code is publicly available at https://github.com/CaptainCuong/Graph-Calibration-Attack.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Unified Graph Calibration Attack (UGCA) framework to evaluate the robustness of calibrated Graph Neural Networks (GNNs) under white-box structural perturbations. UGCA uses a KL-divergence objective to push predictive distributions toward uniformity, combined with a reranking mechanism, hybrid loss for label recovery, and beam search to handle discrete graph edits while aiming to preserve node labels. The authors claim this increases Expected Calibration Error (ECE) substantially without accuracy loss, supported by experiments across models and datasets, and provide theoretical insights linking higher model accuracy or greater dataset class count to increased vulnerability.
Significance. If the empirical results and theoretical links hold after addressing the interaction between attack components, the work would demonstrate a previously unexplored vulnerability in GNN calibration to edge perturbations, relevant for safety-critical graph applications. The public code release at the cited GitHub repository is a clear strength enabling reproducibility. The theoretical connections between generalization, dataset complexity, and calibration susceptibility could inform future robust calibration methods if rigorously derived.
major comments (3)
- [§3.3] §3.3 (hybrid loss and reranking): the description states that the hybrid loss recovers labels when violations occur and reranking reduces flips, but it is unclear whether these mechanisms constrain the KL objective enough to limit ECE gains; this is load-bearing for the central claim that ECE rises substantially while accuracy is preserved, as the skeptic concern about the components dominating the attack remains unaddressed by ablations or analysis.
- [§5] §5 (theoretical insights): the claimed links between higher accuracy, more classes, and susceptibility are presented as insights but lack explicit derivations or theorems showing how they follow from the threat model; without this, the connections risk being post-hoc interpretations of the empirical results rather than predictive.
- [Table 2] Table 2 or equivalent results table: the reported ECE increases must be shown with controls confirming that the reranking/hybrid components do not simply revert predictions toward the clean high-confidence outputs; current presentation does not isolate their effect on the KL-driven uniformity.
minor comments (2)
- [§3] Notation for the beam search width and KL temperature parameters should be defined consistently in the methods and used in the experimental setup description.
- [Abstract] The abstract mentions 'theoretical insights' but the introduction does not preview the specific form of these insights (e.g., whether they are bounds or correlations).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the UGCA framework, which highlights important areas for clarification and strengthening. We address each major comment point by point below, agreeing where revisions are warranted to improve rigor.
read point-by-point responses
-
Referee: [§3.3] §3.3 (hybrid loss and reranking): the description states that the hybrid loss recovers labels when violations occur and reranking reduces flips, but it is unclear whether these mechanisms constrain the KL objective enough to limit ECE gains; this is load-bearing for the central claim that ECE rises substantially while accuracy is preserved, as the skeptic concern about the components dominating the attack remains unaddressed by ablations or analysis.
Authors: We agree that the interaction between components requires explicit validation to confirm the KL objective is the primary driver of ECE increases. In the revised manuscript, we will add ablation studies (e.g., variants with and without reranking/hybrid loss) to isolate effects and demonstrate that ECE gains are attributable to the KL-divergence term while the other mechanisms primarily enforce label preservation. revision: yes
-
Referee: [§5] §5 (theoretical insights): the claimed links between higher accuracy, more classes, and susceptibility are presented as insights but lack explicit derivations or theorems showing how they follow from the threat model; without this, the connections risk being post-hoc interpretations of the empirical results rather than predictive.
Authors: The links are derived from properties of the threat model (KL objective under edge perturbations) and observed empirical patterns. We will add a formal proposition in the revision that derives the relationship between accuracy, class count, and vulnerability from the attack objective, moving beyond post-hoc interpretation. revision: partial
-
Referee: [Table 2] Table 2 or equivalent results table: the reported ECE increases must be shown with controls confirming that the reranking/hybrid components do not simply revert predictions toward the clean high-confidence outputs; current presentation does not isolate their effect on the KL-driven uniformity.
Authors: We will augment the results in Table 2 (or add a supplementary table) with control experiments comparing full UGCA to ablated versions, explicitly isolating the KL objective's effect on predictive uniformity and ECE while showing the components do not revert to clean-model behavior. revision: yes
Circularity Check
No circularity; empirical attack with independent validation
full rationale
The paper introduces UGCA as an empirical attack method using KL loss, reranking, hybrid loss, and beam search to increase ECE on GNNs while preserving accuracy. It reports experiments and theoretical links between accuracy, dataset complexity, and vulnerability, but these are not derived from equations that reduce to fitted inputs or self-citations. No self-definitional steps, fitted predictions, or load-bearing self-citations appear in the provided text; the code release allows external reproduction, keeping the central claims independent of any internal circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GNNs are highly sensitive to edge perturbations, often causing unintended label changes that violate attack constraints
Reference graph
Works this paper leans on
-
[1]
Ali Al-Lawati, Jason Lucas, Zhiwei Zhang, Prasenjit Mitra, and Suhang Wang
- [2]
-
[3]
Jinyin Chen, Ziqiang Shi, Yangyang Wu, Xuanheng Xu, and Haibin Zheng. 2018. Link prediction adversarial attack.arXiv preprint arXiv:1810.01110(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Jinyin Chen, Yangyang Wu, Xuanheng Xu, Yixian Chen, Haibin Zheng, and Qi Xuan. 2018. Fast Gradient Attack on Network Embedding.arXiv preprint arXiv:1809.02797(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Sikai Chen, Jiqian Dong, Paul Ha, Yujie Li, and Samuel Labi. 2021. Graph neural network and reinforcement learning for multi-agent cooperative control of con- nected autonomous vehicles.Computer-Aided Civil and Infrastructure Engineering (2021)
2021
-
[6]
Sadia Sultana Chowa, Sami Azam, Sidratul Montaha, Israt Jahan Payel, Md Ra- had Islam Bhuiyan, Md Zahid Hasan, and Mirjam Jonkman. 2023. Graph neural network-based breast cancer diagnosis using ultrasound images with optimized graph construction integrating the medically significant features.Journal of Cancer Research and Clinical Oncology(2023)
2023
-
[7]
Dang Cuong, Dung Le, and Thai Le. 2024. A Curious Case of Searching for the Correlation between Training Data and Adversarial Robustness of Transformer Textual Models. InFindings of the Association for Computational Linguistics: ACL
2024
-
[8]
Dang Cao Cuong. 2023. Score-based Diffusion Model for Conformer Generation. In2023 International Conference on Information Technology (ICIT). IEEE, 788–793
2023
-
[9]
Hanjun Dai, Hui Li, Tian Tian, Xin Huang, Lin Wang, Jun Zhu, and Le Song. 2018. Adversarial Attack on Graph Structured Data. InICML
2018
-
[10]
Cornelius Emde, Francesco Pinto, Thomas Lukasiewicz, Philip Torr, and Adel Bibi
-
[11]
InICML AdvML-Frontiers Workshop
Certified Calibration: Bounding Worst-Case Calibration under Adversarial Attacks. InICML AdvML-Frontiers Workshop
-
[12]
Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin
-
[13]
Graph neural networks for social recommendation. InWWW
-
[14]
Ido Galil and Ran El-Yaniv. 2021. Disrupting Deep Uncertainty Estimation With- out Harming Accuracy. InNeurIPS
2021
-
[15]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On Calibration of Modern Neural Networks. InICML
2017
-
[16]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. InNeurIPS
2017
-
[17]
Hans Hao-Hsun Hsu, Yuesong Shen, Christian Tomani, and Daniel Cremers. 2022. What Makes Graph Neural Networks Miscalibrated?. InNeurIPS
2022
-
[18]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. InNeurIPS
2020
-
[19]
Bowen Jiang, Zhijun Zhuang, Shreyas S Shivakumar, and Camillo J Taylor. 2025. Enhancing scene graph generation with hierarchical relationships and common- sense knowledge. InW ACV
2025
-
[20]
Thomas N Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. InICLR
2017
-
[21]
Anna-Kathrin Kopetzki, Bertrand Charpentier, Daniel Zügner, Sandhya Giri, and Stephan Günnemann. 2021. Evaluating robustness of predictive uncertainty estimation: Are Dirichlet-based models reliable?. InICML
2021
-
[22]
Aounon Kumar, Alexander Levine, Soheil Feizi, and Tom Goldstein. 2020. Certi- fying Confidence via Randomized Smoothing. InNeurIPS
2020
-
[23]
Minhua Lin, Zhiwei Zhang, Enyan Dai, Zongyu Wu, Yilong Wang, Xiang Zhang, and Suhang Wang. 2025. Are You Using Reliable Graph Prompts? Trojan Prompt Attacks on Graph Neural Networks. InKDD
2025
-
[24]
Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning Entity and Relation Embeddings for Knowledge Graph Completion. InAAAI
2015
-
[25]
Chengyi Liu, Jiahao Zhang, Shijie Wang, Wenqi Fan, and Qing Li. 2025. Score- based Generative Diffusion Models for Social Recommendations.TKDE(2025)
2025
-
[26]
Jiale Liu, Jiahao Zhang, and Suhang Wang. 2026. Exposing Privacy Risks in Graph Retrieval-Augmented Generation. InACL Findings
2026
-
[27]
Zhiwei Liu, Yingtong Dou, Philip S Yu, Yutong Deng, and Hao Peng. 2020. Alle- viating the Inconsistency Problem of Applying Graph Neural Network to Fraud Detection. InSIGIR
2020
-
[28]
Haitong Luo, Fali Wang, Weiyao Zhang, Xianren Zhang, Zhiwei Zhang, Tianxiang Zhao, Minhua Lin, Jiahao Zhang, Hui Liu, Xianfeng Tang, et al. 2026. Graphs for LLMs: A Survey of Graph-Assisted Large Language Models. InACL Findings
2026
-
[29]
Shuai Ma, Ying Lei, Xinru Wang, Chengbo Zheng, Chuhan Shi, Ming Yin, and Xiaojuan Ma. 2023. Who should i trust: Ai or myself? leveraging human and ai correctness likelihood to promote appropriate trust in ai-assisted decision- making. InCHI
2023
-
[30]
Shuai Ma, Xinru Wang, Ying Lei, Chuhan Shi, Ming Yin, and Xiaojuan Ma
-
[31]
Are you really sure?
“Are you really sure?” Understanding the effects of human self-confidence calibration in AI-assisted decision making. InCHI
-
[32]
Alireza Mehrtash, William M Wells, Clare M Tempany, Purang Abolmaesumi, and Tina Kapur. 2020. Confidence calibration and predictive uncertainty estimation for deep medical image segmentation.IEEE TMI(2020)
2020
- [33]
- [34]
-
[35]
Stephen Obadinma, Xiaodan Zhu, and Hongyu Guo. 2024. Calibration Attacks: A Comprehensive Study of Adversarial Attacks on Model Confidence.TMLR (2024)
2024
-
[36]
Showmick Guha Paul, Arpa Saha, Md Zahid Hasan, Sheak Rashed Haider Noori, and Ahmed Moustafa. 2024. A Systematic Review of Graph Neural Network in Healthcare-Based Applications: Recent Advances, Trends, and Future Directions. IEEE Access(2024)
2024
-
[37]
Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. DeepWalk: Online Learn- ing of Social Representations. InKDD
2014
-
[38]
Aravind Sankar, Yozen Liu, Jun Yu, and Neil Shah. 2021. Graph neural networks for friend ranking in large-scale social platforms. InWWW
2021
-
[39]
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. 2008. Collective Classification in Network Data.AI magazine (2008)
2008
-
[40]
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. 2018. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Boshi Tang, Zhiyong Wu, Xixin Wu, Qiaochu Huang, Jun Chen, Shun Lei, and Helen Meng. 2024. Simcalib: Graph neural network calibration based on similarity between nodes. InAAAI
2024
-
[42]
Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei
-
[43]
LINE: Large-scale Information Network Embedding. InWWW
-
[44]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2018. Graph Attention Networks. InICLR
2018
-
[45]
Min Wang, Hao Yang, and Qing Cheng. 2022. GCL: Graph Calibration Loss for Trustworthy Graph Neural Network. InACM MM
2022
-
[46]
Xiao Wang, Hongrui Liu, Chuan Shi, and Cheng Yang. 2021. Be Confident! Towards Trustworthy Graph Neural Networks via Confidence Calibration. In NeurIPS
2021
-
[47]
Yuyang Wang, Jianren Wang, Zhonglin Cao, and Amir Barati Farimani. 2022. Molecular contrastive learning of representations via graph neural networks. Nature Machine Intelligence(2022)
2022
-
[48]
Yilong Wang, Jiahao Zhang, Tianxiang Zhao, and Suhang Wang. 2025. Towards Reliable GNNs: Adversarial Calibration Learning for Confidence Estimation. In CIKM
2025
-
[49]
Junjie Xu, Jiahao Zhang, Mangal Prakash, Xiang Zhang, and Suhang Wang
-
[50]
InNeurIPS
DualEqui: A Dual-Space Hierarchical Equivariant Network for Large Biomolecules. InNeurIPS
-
[51]
Cheng Yang, Chengdong Yang, Chuan Shi, Yawen Li, Zhiqiang Zhang, and Jun Zhou. 2024. Calibrating Graph Neural Networks from a Data-centric Perspective. InWWW
2024
-
[52]
Shuhua Yang, Jiahao Zhang, Yilong Wang, Dongwon Lee, and Suhang Wang
-
[53]
Query-Efficient Agentic Graph Extraction Attacks on GraphRAG Systems. InACL
-
[54]
Huimin Zeng, Zhenrui Yue, Yang Zhang, Lanyu Shang, and Dong Wang. 2023. Manipulating Out-Domain Uncertainty Estimation in Deep Neural Networks via Targeted Clean-Label Poisoning. InCIKM
2023
-
[55]
Jiahao Zhang. 2024. Graph unlearning with efficient partial retraining. InWWW
2024
- [56]
-
[57]
Jiahao Zhang, Yilong Wang, Zhiwei Zhang, Xiaorui Liu, and Suhang Wang. 2026. Unlearning Inversion Attacks for Graph Neural Networks. InWSDM
2026
-
[58]
Jiahao Zhang, Rui Xue, Wenqi Fan, Xin Xu, Qing Li, Jian Pei, and Xiaorui Liu. 2024. Linear-time graph neural networks for scalable recommendations. InWWW
2024
-
[59]
Muhan Zhang and Yixin Chen. 2018. Link Prediction Based on Graph Neural Networks. InNeurIPS
2018
-
[60]
Yuang Zhang, Haonan An, Zhengru Fang, Guowen Xu, Yuan Zhou, Xianhao Chen, and Yuguang Fang. 2024. SmartCooper: Vehicular Collaborative Perception with Adaptive Fusion and Judger Mechanism. InICRA
2024
-
[61]
Xiaojin Zhu and Zoubin Ghahramani. 2002. Learning from Labeled and Unlabeled Data with Label Propagation.ProQuest number: information to all users(2002)
2002
-
[62]
Dingyi Zhuang, Chonghe Jiang, Yunhan Zheng, Shenhao Wang, and Jinhua Zhao
-
[63]
GETS: Ensemble Temperature Scaling for Calibration in Graph Neural Networks. InICLR
-
[64]
Daniel Zügner, Amir Akbarnejad, and Stephan Günnemann. 2018. Adversarial Attacks on Neural Networks for Graph Data. InKDD
2018
-
[65]
Daniel Zügner and Stephan Günnemann. 2019. Adversarial Attacks on Graph Neural Networks via Meta Learning. InICLR. The Confidence Trap: Calibration Attacks for Graph Neural Networks KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Appendix A Details of the Attack Algorithm Algorithm 2Naive Graph Calibration Attack Require: Victim Model 𝑓 , Atta...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.