Explaining Black-Box Language Models: Learning to Optimize Linguistically-Structured Word Subsets
Pith reviewed 2026-06-27 18:32 UTC · model grok-4.3
The pith
An amortized policy trained with policy gradients and graph knowledge selects small word subsets that explain black-box language models more effectively than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a single learned selection policy, optimized to maximize predictive fidelity on the chosen words while incorporating graph-based linguistic structure, yields word subsets that are simultaneously more informative to the black-box model and more aligned with human linguistic intuition than subsets produced by existing explanation techniques.
What carries the argument
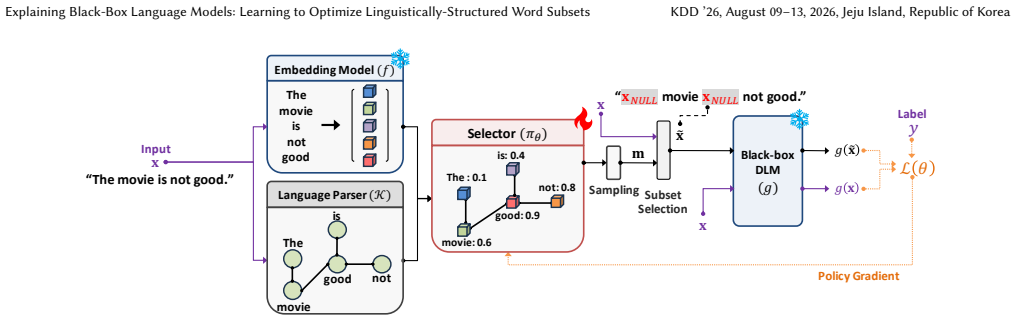
Amortized selection policy trained via REINFORCE policy gradients that incorporates graph-structured knowledge to enforce linguistic coherence during discrete word selection.
If this is right
- Explanations become available in one forward pass after a single training run, without repeated queries or gradient access.
- The same policy works across different black-box models and datasets once trained.
- Selected subsets preserve enough signal for the original prediction while respecting linguistic relations.
- Performance holds even against methods given oracle gradients, establishing a stronger benchmark.
Where Pith is reading between the lines
- The same amortized policy approach could be tested on structured inputs other than text if analogous graph knowledge is supplied.
- Human-subject studies could check whether the linguistically coherent subsets actually increase user trust or decision quality in deployed systems.
- The method opens the possibility of jointly optimizing for model fidelity and additional human priors beyond graphs.
- If the policy generalizes across domains, it could reduce the need for model-specific explanation engineering.
Load-bearing premise
Graph-structured knowledge can be integrated into the selection policy so that the resulting subsets remain both predictive for the model and meaningful to humans.
What would settle it
On held-out inputs, measure whether subsets chosen by the policy produce lower model accuracy when fed alone or show weaker overlap with human-annotated salient words than subsets from the strongest baseline.
Figures

read the original abstract
As deep language models (DLMs) are increasingly deployed in high-stakes domains such as healthcare, understanding their decision rationale becomes paramount for ensuring trust, safety, and accountability. However, achieving this vital level of interpretability is particularly challenging when these DLMs operate as black-box systems (e.g., via APIs), where access to internal model states (e.g., parameters, gradients) is restricted. Despite numerous efforts, existing explanation methods often fail to concurrently satisfy three key desiderata: (i) inference-time efficiency, (ii) black-box compatibility without inducing out-of-distribution behavior, and (iii) comprehensible explanations grounded in the input's linguistic structure. To address these challenges, we propose a method that explains predictions of DLMs by selecting a small, informative subset of input words. We formulate this as an amortized optimization problem, enabling efficient one-shot inference without the need for input-specific search. Our selection policy is trained via REINFORCE-style policy gradients, allowing discrete word selection in a fully gradient-free setting. To enhance interpretability and align with human linguistic intuition, we integrate graph-structured knowledge into this selection process, fostering linguistically coherent subsets that result in explanations both highly informative and cognitively meaningful to end-users. We evaluated our method on diverse DLM architectures and multiple real-world datasets. It consistently identifies word subsets with enhanced discriminative power and stronger alignment with linguistically salient cues, outperforming both conventional black-box compatible methods and gradient-based approaches that are given oracle access to the black-box model's gradients for a more challenging benchmark. Our code is available at here.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an amortized REINFORCE policy-gradient method to select small word subsets from input text that explain predictions of black-box deep language models. Graph-structured knowledge (dependency parses and external relations) is integrated into the selection policy to encourage linguistically coherent subsets. The approach is claimed to satisfy inference-time efficiency, black-box compatibility, and human-aligned interpretability, and is reported to outperform both standard black-box explanation baselines and oracle-gradient methods across multiple DLM architectures and real-world datasets.
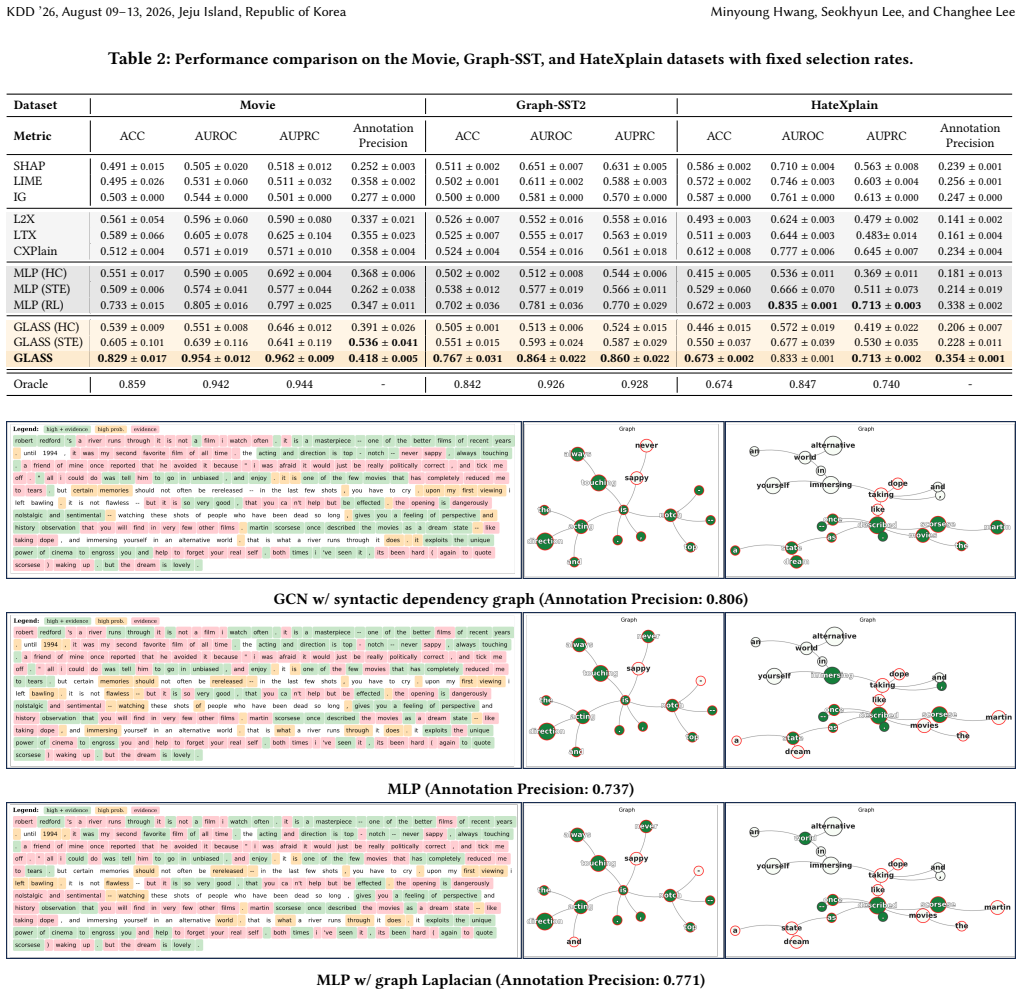
Significance. If the empirical results hold under the reported controls for subset size, architecture, and dataset, the work would provide a practical, gradient-free explanation technique that produces subsets with both high fidelity to the black-box model and improved linguistic coherence. The amortized formulation and explicit use of graph knowledge distinguish it from prior search-based or gradient-dependent methods and could be useful in API-only deployment settings.
minor comments (2)
- The code-availability statement reads “Our code is available at here.”; replace the placeholder with the actual repository URL or remove the sentence if the repository is not yet public.
- § on evaluation metrics: the coherence and human-alignment scores are described at a high level; a short additional paragraph clarifying the exact automatic metrics (e.g., dependency-parse overlap, external-relation coverage) and the human-study protocol would improve reproducibility without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the core contributions of our amortized policy-gradient method with graph-structured linguistic knowledge for black-box DLM explanations.
Circularity Check
No significant circularity detected
full rationale
The paper formulates an amortized REINFORCE policy for selecting word subsets, augmented by graph-structured knowledge from dependency parses and external relations. The abstract and skeptic summary describe the training procedure, policy network integration, black-box constraint, and evaluation metrics (fidelity, coherence, human alignment) with sufficient independent technical detail. No equations are provided that reduce any claimed prediction or result to a fitted quantity defined by the same experiment. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on empirical comparisons with controls for subset size and multiple architectures, which are externally falsifiable and not forced by construction. This is a standard non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Andrea Agiollo, Luciano Cavalcante Siebert, Pradeep K Murukannaiah, and An- drea Omicini. 2024. From large language models to small logic programs: building global explanations from disagreeing local post-hoc explainers.Autonomous Agents and Multi-Agent Systems38, 2 (2024), 32
2024
-
[2]
Gabor Angeli, Melvin Jose Johnson Premkumar, and Christopher D. Manning
-
[3]
Leveraging Linguistic Structure For Open Domain Information Extraction. InProceedings of the 53rd Annual Meeting of the Association for Computational Lin- guistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Chengqing Zong and Michael Strube (Eds.). Association for Computational Linguistics, Beijing, ...
-
[4]
Timothy Baldwin, Paul Cook, Marco Lui, Andrew MacKinlay, and Li Wang. 2013. How Noisy Social Media Text, How Diffrnt Social Media Sources?. InProceedings of the Sixth International Joint Conference on Natural Language Processing, Ruslan Mitkov and Jong C. Park (Eds.). Asian Federation of Natural Language Processing, Nagoya, Japan, 356–364. https://aclanth...
2013
-
[5]
Oren Barkan, Yuval Asher, Amit Eshel, Yehonatan Elisha, and Noam Koenigstein
-
[6]
In2023 IEEE International Conference on Data Mining (ICDM)
Learning to explain: A model-agnostic framework for explaining black box models. In2023 IEEE International Conference on Data Mining (ICDM). IEEE, 944–949
-
[7]
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A pretrained language model for scientific text.arXiv preprint arXiv:1903.10676(2019)
arXiv 2019
-
[8]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432(2013)
Pith/arXiv arXiv 2013
-
[9]
Alexander Binder, Grégoire Montavon, Sebastian Lapuschkin, Klaus-Robert Müller, and Wojciech Samek. 2016. Layer-wise relevance propagation for neural networks with local renormalization layers. InArtificial Neural Networks and Machine Learning–ICANN 2016: 25th International Conference on Artificial Neural Networks, Barcelona, Spain, September 6-9, 2016, P...
2016
-
[10]
Bowman, Jon Gauthier, Abhinav Rastogi, Raghav Gupta, Christo- pher D
Samuel R. Bowman, Jon Gauthier, Abhinav Rastogi, Raghav Gupta, Christo- pher D. Manning, and Christopher Potts. 2016. A Fast Unified Model for Parsing and Sentence Understanding. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Katrin Erk and Noah A. Smith (Eds.). Association for Computatio...
-
[11]
Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, and Ion Androutsopoulos. 2020. LEGAL-BERT: The Muppets straight out of Law School. InFindings of the Association for Computational Linguistics: EMNLP 2020, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 2898–2904. doi:10.18653/v1/2...
-
[12]
Jianbo Chen, Le Song, Martin Wainwright, and Michael Jordan. 2018. Learning to explain: An information-theoretic perspective on model interpretation. In International conference on machine learning. PMLR, 883–892
2018
-
[13]
Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. 2017. Automated hate speech detection and the problem of offensive language. In Proceedings of the international AAAI conference on web and social media, Vol. 11. 512–515
2017
-
[14]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[15]
Timothy Dozat and Christopher D. Manning. 2017. Deep Biaffine Attention for Neural Dependency Parsing. InInternational Conference on Learning Representa- tions. https://openreview.net/forum?id=Hk95PK9le
2017
-
[16]
Jacob Eisenstein. 2013. What to do about bad language on the internet. InPro- ceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff (Eds.). Association for Computational Lin- guistics, Atlanta, Georgia, 359–369. http...
2013
-
[17]
David Embick, Alec Marantz, Yasushi Miyashita, Wayne O’Neil, and Kuniyoshi L Sakai. 2000. A syntactic specialization for Broca’s area.Proceedings of the National Academy of Sciences97, 11 (2000), 6150–6154
2000
-
[18]
Joseph Enguehard. 2023. Sequential integrated gradients: a simple but effective method for explaining language models.arXiv preprint arXiv:2305.15853(2023)
arXiv 2023
-
[19]
Nils Feldhus, Robert Schwarzenberg, and Sebastian Möller. 2021. Thermostat: A large collection of NLP model explanations and analysis tools.arXiv preprint arXiv:2108.13961(2021)
arXiv 2021
-
[20]
Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 249–256
2010
-
[21]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
-
[22]
Peter Hase, Harry Xie, and Mohit Bansal. 2021. The out-of-distribution problem in explainability and search methods for feature importance explanations.Advances in neural information processing systems34 (2021), 3650–3666
2021
-
[23]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. {DEBERTA}: {DECODING}-{ENHANCED} {BERT} {WITH} {DISENTANGLED} {ATTENTION}. InInternational Conference on Learning Representations. https://openreview.net/ forum?id=XPZIaotutsD
2021
-
[24]
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, Adriane Boyd, et al
-
[25]
spaCy: Industrial-strength natural language processing in python. (2020)
2020
-
[26]
Anette Hulth. 2003. Improved automatic keyword extraction given more linguistic knowledge. InProceedings of the 2003 conference on Empirical methods in natural language processing. 216–223
2003
-
[27]
Neil Jethani, Mukund Sudarshan, Yindalon Aphinyanaphongs, and Rajesh Ran- ganath. 2021. Have we learned to explain?: How interpretability methods can learn to encode predictions in their interpretations.. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 1459–1467
2021
-
[28]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
Pith/arXiv arXiv 2014
-
[29]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. InInternational Conference on Learning Repre- sentations. https://openreview.net/forum?id=SJU4ayYgl
2017
-
[30]
Mayank Kulkarni, Debanjan Mahata, Ravneet Arora, and Rajarshi Bhowmik
-
[31]
InFindings of the Association for Computational Linguistics: NAACL 2022
Learning rich representation of keyphrases from text. InFindings of the Association for Computational Linguistics: NAACL 2022. 891–906
2022
-
[32]
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics36, 4 (2020), 1234–1240
2020
-
[33]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, ...
-
[34]
Zhongli Li, Qingyu Zhou, Chao Li, Ke Xu, and Yunbo Cao. 2021. Improving BERT with Syntax-aware Local Attention. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Eds.). Association for Computational Linguistics, Online, 645–653. doi:10.18653/v1/2021.findings-acl.57
-
[35]
Faming Liang, Qizhai Li, and Lei Zhou. 2018. Bayesian neural networks for selection of drug sensitive genes.J. Amer. Statist. Assoc.113, 523 (2018), 955–972
2018
-
[36]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[37]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
Pith/arXiv arXiv 2019
-
[38]
Christos Louizos, Max Welling, and Diederik P Kingma. 2017. Learning sparse neural networks through 𝐿_0regularization.arXiv preprint arXiv:1712.01312 (2017)
Pith/arXiv arXiv 2017
-
[39]
Tameem Adel Luisa M Zintgraf, Taco S Cohen and Max Welling. 2019. Visualizing Deep Neural Network Decisions: Prediction Difference Analysis. InIn Proceedings of the 7th International Conference on Learning Representations (ICLR 2019)
2019
-
[40]
Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions.Advances in neural information processing systems30 (2017)
2017
-
[41]
Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. 2011. Learning word vectors for sentiment analysis. InProceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies. 142–150
2011
-
[42]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. 2017. The Concrete Distribu- tion: A Continuous Relaxation of Discrete Random Variables. InInternational Con- ference on Learning Representations. https://openreview.net/forum?id=S1jE5L5gl
2017
-
[43]
Andreas Madsen, Sarath Chandar, and Siva Reddy. 2024. Are self-explanations from Large Language Models faithful?. InFindings of the Association for Compu- tational Linguistics: ACL 2024. 295–337
2024
-
[44]
Binny Mathew, Punyajoy Saha, Seid Muhie Yimam, Chris Biemann, Pawan Goyal, and Animesh Mukherjee. 2021. HateXplain: A Benchmark Dataset for Explainable Explaining Black-Box Language Models: Learning to Optimize Linguistically-Structured Word Subsets KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Hate Speech Detection. (2021)
2021
-
[45]
Toufik Mechouma, Ismail Biskri, and Serge Robert. 2025. VLG-BERT: Towards Better Interpretability in LLMs through Visual and Linguistic Grounding. In Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities, Mika Hämäläinen, Emily Öhman, Yuri Bizzoni, So Miya- gawa, and Khalid Alnajjar (Eds.). Association for C...
-
[46]
Ralph-Axel Müller, Natalia Kleinhans, and Eric Courchesne. 2003. Linguistic theory and neuroimaging evidence: an fMRI study of Broca’s area in lexical semantics.Neuropsychologia41, 9 (2003), 1199–1207. doi:10.1016/S0028-3932(03) 00045-9
-
[47]
Hardt, M., Recht, B., and Singer, Y
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Ex- treme Summarization. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (Eds.). Association for Com...
-
[48]
Nelson, Imen El Karoui, Kristof Giber, Xiaofang Yang, Lau- rent Cohen, Hilda Koopman, Sydney S
Matthew J. Nelson, Imen El Karoui, Kristof Giber, Xiaofang Yang, Lau- rent Cohen, Hilda Koopman, Sydney S. Cash, Lionel Naccache, John T. Hale, Christophe Pallier, and Stanislas Dehaene. 2017. Neurophysiologi- cal dynamics of phrase-structure building during sentence processing.Pro- ceedings of the National Academy of Sciences114, 18 (2017), E3669–E3678. ...
-
[49]
Pranoy Panda, Sai Srinivas Kancheti, and Vineeth N Balasubramanian. 2021. Instance-wise causal feature selection for model interpretation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1756–1759
2021
-
[50]
Max Paulus, Dami Choi, Daniel Tarlow, Andreas Krause, and Chris J Maddison
-
[51]
Gradient estimation with stochastic softmax tricks.Advances in Neural Information Processing Systems33 (2020), 5691–5704
2020
-
[52]
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global Vectors for Word Representation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Alessandro Moschitti, Bo Pang, and Walter Daelemans (Eds.). Association for Computational Linguistics, Doha, Qatar, 1532–1543. doi:10.3115/v1/D14-1162
-
[53]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[54]
Why should i trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " Why should i trust you?" Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1135–1144
2016
-
[55]
Soumya Sanyal and Xiang Ren. 2021. Discretized integrated gradients for ex- plaining language models.arXiv preprint arXiv:2108.13654(2021)
arXiv 2021
-
[56]
Laurent Sartran, Samuel Barrett, Adhiguna Kuncoro, Miloš Stanojević, Phil Blunsom, and Chris Dyer. 2022. Transformer Grammars: Augmenting Trans- former Language Models with Syntactic Inductive Biases at Scale.Trans- actions of the Association for Computational Linguistics10 (2022), 1423–1439. doi:10.1162/tacl_a_00526
-
[57]
Patrick Schwab and Walter Karlen. 2019. Cxplain: Causal explanations for model interpretation under uncertainty.Advances in neural information processing systems32 (2019)
2019
-
[58]
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. 2017. Learning im- portant features through propagating activation differences. InInternational conference on machine learning. PMlR, 3145–3153
2017
-
[59]
Xuelin Situ, Ingrid Zukerman, Cecile Paris, Sameen Maruf, and Gholamreza Haf- fari. 2021. Learning to explain: Generating stable explanations fast. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 5340–5355
2021
-
[60]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. InProceedings of the 2013 Con- ference on Empirical Methods in Natural Language Processing, David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and ...
2013
-
[61]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. InInternational conference on machine learning. PMLR, 3319– 3328
2017
-
[62]
Nelvin Tan, James Asikin Cheung, Yu-Ching Shih, Dong Yang, and Amol Salunkhe
-
[63]
Does Using Counterfactual Help LLMs Explain Textual Importance in Classification?arXiv preprint arXiv:2510.04031(2025)
arXiv 2025
-
[64]
Kristina Toutanova, Danqi Chen, Patrick Pantel, Hoifung Poon, Pallavi Choud- hury, and Michael Gamon. 2015. Representing Text for Joint Embedding of Text and Knowledge Bases. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lluís Màrquez, Chris Callison-Burch, and Jian Su (Eds.). Association for Computational Lingu...
-
[65]
Shikhar Vashishth, Manik Bhandari, Prateek Yadav, Piyush Rai, Chiranjib Bhat- tacharyya, and Partha Talukdar. 2018. Incorporating syntactic and semantic information in word embeddings using graph convolutional networks.arXiv preprint arXiv:1809.04283(2018)
Pith/arXiv arXiv 2018
-
[66]
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning8 (1992), 229–256
1992
-
[67]
Zhitao Ying, Dylan Bourgeois, Jiaxuan You, Marinka Zitnik, and Jure Leskovec
-
[68]
Gnnexplainer: Generating explanations for graph neural networks.Ad- vances in neural information processing systems32 (2019)
2019
-
[69]
Jinsung Yoon, James Jordon, and Mihaela van der Schaar. 2019. INVASE: Instance- wise Variable Selection using Neural Networks. InInternational Conference on Learning Representations. https://openreview.net/forum?id=BJg_roAcK7
2019
-
[70]
Hao Yuan, Haiyang Yu, Shurui Gui, and Shuiwang Ji. 2022. Explainability in graph neural networks: A taxonomic survey.IEEE transactions on pattern analysis and machine intelligence45, 5 (2022), 5782–5799
2022
-
[71]
Omar Zaidan and Jason Eisner. 2008. Modeling annotators: A generative approach to learning from annotator rationales. InProceedings of the 2008 conference on Empirical methods in natural language processing. 31–40
2008
-
[72]
Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding con- volutional networks. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13. Springer, 818–833
2014
-
[73]
Weinberger, and Yoav Artzi
Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi
-
[74]
the” 0.900 0.966 0.968 Replace with“,
BERTScore: Evaluating Text Generation with BERT. InInternational Confer- ence on Learning Representations. https://openreview.net/forum?id=SkeHuCVFDr A Details about Formal Derivations A.1 Extension to Regression Tasks To extend our framework to regression tasks, we modify the lossℓ𝑦 to reflect the change in the prediction error based on the black-box DLM...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.