Towards End to End Motion Planning and Execution for Autonomous Underwater Vehicles Using Reinforcement Learning
Pith reviewed 2026-06-27 18:31 UTC · model grok-4.3
The pith
A hierarchical reinforcement learning system maps raw AUV sensor data directly to thruster commands for obstacle avoidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
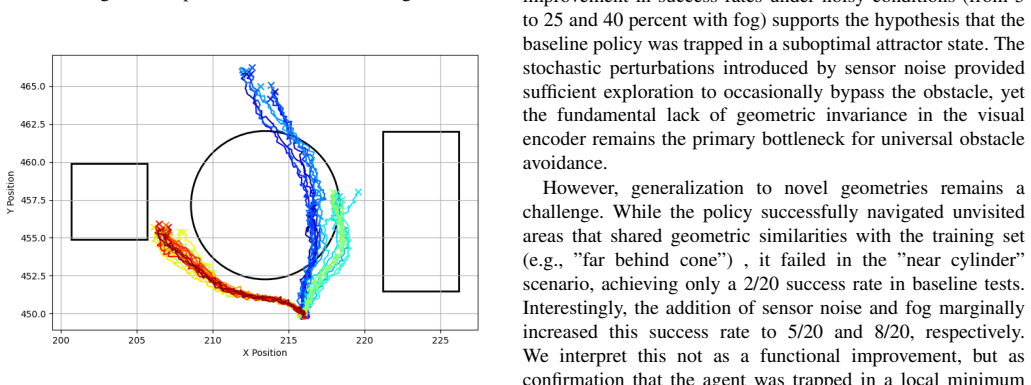
The central claim is that an end-to-end hierarchical DRL controller, trained with RLPD in a modified SERL framework for the high-level policy and SAC plus HER for the low-level policy, produces obstacle-avoiding trajectories whose lengths stay within 4 to 6 percent of an RRT* baseline while remaining robust to added sensor noise and reduced visibility.
What carries the argument
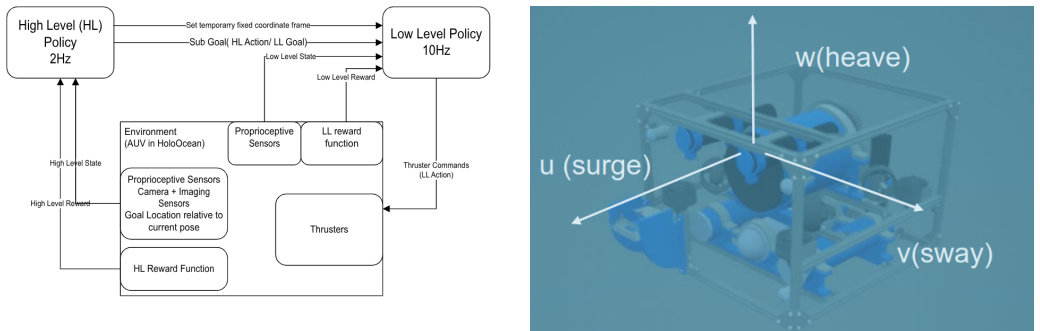
The two-layer hierarchical policy that runs a 2 Hz high-level network on stacked 84x84 camera and 100x100 sonar images plus proprioception to output spatial subgoals and a 10 Hz low-level network that converts those subgoals into thruster actions.
If this is right
- Obstacle avoidance succeeds with paths close in length to those produced by RRT* planning.
- The learned behavior tolerates simulated sensor noise and lowered visibility without retraining.
- Sample-efficient training is possible by combining prior demonstrations for the high-level policy with hindsight replay for the low-level policy.
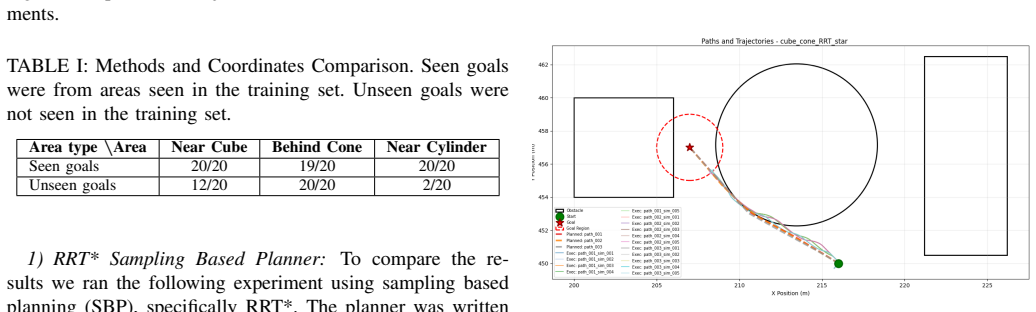
- Navigation remains reliable on obstacle geometries encountered during training but degrades on novel shapes.
Where Pith is reading between the lines
- If the simulation-to-real gap can be closed, the same architecture could cut the amount of custom software needed when moving an AUV to a new site.
- Adding more sensor types or running multiple vehicles together would be a direct next test of the same subgoal-passing structure.
- Collecting a small set of real-world demonstration trajectories could be enough to fine-tune the high-level policy for better generalization.
Load-bearing premise
Results obtained inside the HoloOcean simulator with its particular sensor and noise models will carry over to real AUV hardware and real ocean settings.
What would settle it
Deploy the trained policy on physical AUV hardware in an instrumented tank or open water with obstacles and measure whether trajectory lengths and collision rates match the simulator numbers within the same 4-6 percent band.
Figures


read the original abstract
Autonomous Underwater Vehicles (AUVs) traditionally rely on complex, heavily engineered pipelines for perception, path planning, and motion control. This paper explores the feasibility of an end-to-end Deep Reinforcement Learning (DRL) approach that maps raw sensor data directly to thruster commands, reducing manual engineering. We propose a hierarchical reinforcement learning (HRL) architecture splitting the problem into two Markov Decision Processes. A High-Level (HL) policy operating at 2Hz processes raw $84 \times 84$ pixel monocular camera frames, stacked $100 \times 100$ pixel forward-looking imaging sonar, and proprioceptive data to generate spatial subgoals. Simultaneously, a Low-Level (LL) policy operating at 10Hz converts these subgoals into thruster commands. The HL policy is trained using Reinforcement Learning from Prior Demonstrations (RLPD) within a modified Sample-Efficient Robotic Reinforcement Learning (SERL) framework, while the LL policy utilizes Soft Actor-Critic (SAC) combined with Hindsight Experience Replay (HER). Evaluated in the high-fidelity HoloOcean simulator, our method demonstrates successful obstacle avoidance, achieving trajectory lengths closely approximating (within 4% to 6% of) an $\text{RRT}^*$ planning baseline. Furthermore, the learned policy exhibits strong robustness to simulated sensor noise and decreased visibility. While the system navigates familiar geometries effectively, experiments reveal generalization limitations when encountering unvisited areas with novel obstacle shapes. Ultimately, this work demonstrates the promise of sample-efficient, end-to-end DRL for underwater navigation using minimal computational hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical deep reinforcement learning (DRL) architecture for end-to-end AUV navigation that maps raw sensor inputs (84x84 monocular camera, 100x100 sonar, proprioception) directly to thruster commands. A high-level policy at 2 Hz generates spatial subgoals via RLPD within a modified SERL framework; a low-level policy at 10 Hz converts subgoals to actions via SAC+HER. Evaluated solely in the HoloOcean simulator, the method achieves obstacle avoidance with trajectory lengths within 4-6% of an RRT* baseline and shows robustness to simulated sensor noise and reduced visibility, while noting limited generalization to novel obstacle shapes.
Significance. If the simulation results prove transferable, the work would demonstrate a viable path toward reducing heavily engineered perception-planning-control pipelines for AUVs through sample-efficient hierarchical DRL. The independent RRT* benchmarking and explicit acknowledgment of generalization limits are strengths; however, the absence of real-world validation or domain-randomization studies limits immediate impact on hardware deployment.
major comments (2)
- [Abstract] Abstract and Evaluation section: All headline performance claims (trajectory lengths within 4-6% of RRT*, robustness to sensor noise) rest exclusively on HoloOcean simulation with the described 84x84 camera + 100x100 sonar models. The central goal of reducing manual engineering pipelines requires that these results survive transfer to real AUV hardware, yet no real-world experiments, hardware-in-the-loop tests, domain-randomization ablations, or analysis of unmodeled hydrodynamic/thruster effects are provided to support this assumption.
- [Abstract] Abstract: The training procedures, hyperparameters, and statistical significance of the reported trajectory-length and robustness metrics receive limited detail, making it difficult to assess reproducibility or the precise contribution of the RLPD/SERL and SAC+HER components.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Our work presents a simulation-based study of hierarchical DRL for AUV navigation in HoloOcean, with explicit discussion of its scope and limitations. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and Evaluation section: All headline performance claims (trajectory lengths within 4-6% of RRT*, robustness to sensor noise) rest exclusively on HoloOcean simulation with the described 84x84 camera + 100x100 sonar models. The central goal of reducing manual engineering pipelines requires that these results survive transfer to real AUV hardware, yet no real-world experiments, hardware-in-the-loop tests, domain-randomization ablations, or analysis of unmodeled hydrodynamic/thruster effects are provided to support this assumption.
Authors: We agree the evaluation is confined to high-fidelity simulation and that real-world transfer remains an open question for hardware deployment. The manuscript already states the generalization limits to novel obstacle shapes. As a feasibility demonstration of end-to-end DRL in simulation (benchmarked against RRT*), we do not include real-world or domain-randomization experiments, which would require physical hardware access beyond the current scope. The simulation results still illustrate the potential to reduce engineered pipelines under the modeled conditions. revision: no
-
Referee: [Abstract] Abstract: The training procedures, hyperparameters, and statistical significance of the reported trajectory-length and robustness metrics receive limited detail, making it difficult to assess reproducibility or the precise contribution of the RLPD/SERL and SAC+HER components.
Authors: We will expand the methods and evaluation sections to provide the full set of training hyperparameters for RLPD within the modified SERL framework and for SAC+HER, along with details on the training procedures and statistical analysis (means and standard deviations across multiple random seeds) for the trajectory-length and robustness metrics. This will improve reproducibility and clarify component contributions. revision: yes
- Absence of real-world experiments, hardware-in-the-loop tests, or domain-randomization studies, as these require physical AUV hardware and resources outside the simulation-focused scope of the manuscript.
Circularity Check
No significant circularity; evaluation uses independent RRT* baseline and standard RL methods.
full rationale
The paper describes an empirical hierarchical RL architecture (HL policy at 2 Hz on camera/sonar/proprioception, LL at 10 Hz via SAC+HER) trained with RLPD/SERL and evaluated in HoloOcean simulator. Trajectory lengths are compared to an external RRT* planner (within 4-6%), with no equations, fitted parameters, or self-citations that reduce the central performance claims to inputs by construction. The derivation chain consists of standard algorithmic choices and simulator-based benchmarking against an independent baseline; no self-definitional, fitted-input, or uniqueness-imported steps appear. This is the common honest finding for simulation-only RL papers whose metrics do not loop back on themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward function weights
axioms (1)
- domain assumption The environment can be modeled as two separate MDPs for high and low level policies.
Reference graph
Works this paper leans on
-
[1]
Champion-level drone racing using deep reinforcement learning,
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforcement learning,”Nature, vol. 620, no. 7976, pp. 982–987, 2023
2023
-
[2]
Day- dreamer: World models for physical robot learning,
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg, “Day- dreamer: World models for physical robot learning,” inConference on robot learning. PMLR, 2023, pp. 2226–2240
2023
-
[3]
Serl: A software suite for sample-efficient robotic reinforcement learning,
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine, “Serl: A software suite for sample-efficient robotic reinforcement learning,” 2024
2024
-
[4]
V . H. Fernandes, A. A. Neto, and D. D. Rodrigues, “Pipeline inspection with AUV,” in2015 IEEE/OES Acoustics in Underwater Geosciences Symposium (RIO Acoustics). IEEE, 7 2015, pp. 1–5. [Online]. Available: http://dx.doi.org/10.1109/RIOACOUSTICS.2015.7473607
-
[5]
An Autonomous Underwater Vehicle Simulation With Fuzzy Sensor Fusion for Pipeline Inspection,
I.-C. Sang and W. R. Norris, “An Autonomous Underwater Vehicle Simulation With Fuzzy Sensor Fusion for Pipeline Inspection,”IEEE Sensors Journal, vol. 23, no. 8, pp. 8941–8951, apr 15 2023. [Online]. Available: http://dx.doi.org/10.1109/JSEN.2023.3250721
-
[6]
Autonomous Underwater Vehicle navigation: A review,
B. Zhang, D. Ji, S. Liu, X. Zhu, and W. Xu, “Autonomous Underwater Vehicle navigation: A review,”Ocean Engineering, vol. 273, p. 113861, 4 2023. [Online]. Available: http://dx.doi.org/10.1016/j.oceaneng.2023.113861
-
[7]
D. Chang, M. Johnson-Roberson, and J. Sun, “An Active Perception Framework for Autonomous Underwater Vehicle Navigation Under Sensor Constraints,”IEEE Transactions on Control Systems Technology, vol. 30, no. 6, pp. 2301–2316, 11 2022. [Online]. Available: http://dx.doi.org/10.1109/TCST.2021.3139307
-
[8]
M. Xanthidis, M. Kalaitzakis, N. Karapetyan, J. Johnson, N. Vitzilaios, J. M. O’Kane, and I. Rekleitis, “Aquavis: A Perception-Aware Autonomous Navigation Framework for Underwater Vehicles,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, sep 27 2021, pp. 5410–5417. [Online]. Available: http://dx.doi.org/10.1109/IR...
-
[9]
Autonomous Underwater Navigation and Optical Mapping in Unknown Natural Environments,
J. Hern ´andez, K. Isteni ˇc, N. Gracias, N. Palomeras, R. Campos, E. Vidal, R. Garc ´ıa, and M. Carreras, “Autonomous Underwater Navigation and Optical Mapping in Unknown Natural Environments,” Sensors, vol. 16, no. 8, p. 1174, jul 26 2016. [Online]. Available: http://dx.doi.org/10.3390/s16081174
-
[10]
Advancements in Sensor Fusion for Underwater SLAM: A Review on Enhanced Navigation and Environmental Perception,
F. F. R. Merveille, B. Jia, Z. Xu, and B. Fred, “Advancements in Sensor Fusion for Underwater SLAM: A Review on Enhanced Navigation and Environmental Perception,”Sensors, vol. 24, no. 23, p. 7490, nov 24
-
[11]
Available: http://dx.doi.org/10.3390/s24237490
[Online]. Available: http://dx.doi.org/10.3390/s24237490
-
[12]
A review of sensor fusion techniques for underwater vehicle navigation,
T. Nicosevici, R. Garcia, M. Carreras, and M. Villanueva, “A review of sensor fusion techniques for underwater vehicle navigation,” inOceans ’04 MTS/IEEE Techno-Ocean ’04 (IEEE Cat. No.04CH37600), vol. 3. IEEE, 2004, pp. 1600–1605. [Online]. Available: http://dx.doi.org/10.1109/OCEANS.2004.1406361
-
[13]
Visually augmented navigation in an unstructured environment using a delayed state history,
R. Eustice, O. Pizarro, and H. Singh, “Visually augmented navigation in an unstructured environment using a delayed state history,”IEEE Inter- national Conference on Robotics and Automation, 2004. Proceedings. ICRA ’04. 2004, 2004
2004
-
[14]
Y . Noguchi and T. Maki, “Path Planning Method Based on Artificial Potential Field and Reinforcement Learning for Intervention AUVs,” in2019 IEEE Underwater Technology (UT). IEEE, 4 2019, pp. 1–6. [Online]. Available: http://dx.doi.org/10.1109/UT.2019.8734314
-
[15]
A Multi-Source- Data-Assisted AUV for Path Cruising: An Energy-Efficient DDPG Approach,
T. Xing, X. Wang, K. Ding, K. Ni, and Q. Zhou, “A Multi-Source- Data-Assisted AUV for Path Cruising: An Energy-Efficient DDPG Approach,”Remote Sensing, vol. 15, no. 23, p. 5607, dec 2 2023. [Online]. Available: http://dx.doi.org/10.3390/rs15235607
-
[16]
Auv obstacle avoidance planning based on deep reinforcement learning,
J. Yuan, H. Wang, H. Zhang, C. Lin, D. Yu, and C. Li, “Auv obstacle avoidance planning based on deep reinforcement learning,”Journal of Marine Science and Engineering, vol. 9, no. 11, p. 1166, 2021
2021
-
[17]
Comprehensive Ocean Information-Enabled AUV Motion Planning Based on Reinforcement Learning,
Y . Li, X. He, Z. Lu, P. Jing, and Y . Su, “Comprehensive Ocean Information-Enabled AUV Motion Planning Based on Reinforcement Learning,”Remote Sensing, vol. 15, no. 12, p. 3077, jun 12 2023. [Online]. Available: http://dx.doi.org/10.3390/rs15123077
-
[18]
H. Wu, S. Song, Y . Hsu, K. You, and C. Wu, “End-to-end sensorimotor control problems of AUVs with deep reinforcement learning,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 11 2019, pp. 5869–5874. [Online]. Available: http://dx.doi.org/10.1109/IROS40897.2019.8967612
-
[19]
L. Cai, K. Chang, and Y . Girdhar, “Learning to Swim: Reinforcement Learning for 6-DOF Control of Thruster-driven Autonomous Underwater Vehicles,”arXiv.org, 2024. [Online]. Available: https://arxiv.org/abs/2410.00120
arXiv 2024
-
[20]
End-to-End AUV Local Motion Planning Method Based on Deep Reinforcement Learning,
X. Lyu, Y . Sun, L. Wang, J. Tan, and L. Zhang, “End-to-End AUV Local Motion Planning Method Based on Deep Reinforcement Learning,” Journal of Marine Science and Engineering, vol. 11, no. 9, p. 1796, sep 14 2023. [Online]. Available: http://dx.doi.org/10.3390/jmse11091796
-
[21]
Path planning of autonomous underwater vehicle in unknown environment based on improved deep reinforcement learning,
Z. Tang, X. Cao, Z. Zhou, Z. Zhang, C. Xu, and J. Dou, “Path planning of autonomous underwater vehicle in unknown environment based on improved deep reinforcement learning,”Ocean Engineering, vol. 301, p. 117547, 2024
2024
-
[22]
Efficient online reinforcement learning with offline data,
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine, “Efficient online reinforcement learning with offline data,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 1577–1594
2023
-
[23]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. PMLR, 2018, pp. 1861–1870
2018
-
[24]
Hindsight experience replay,
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, O. Pieter Abbeel, and W. Zaremba, “Hindsight experience replay,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[25]
Stable-baselines3: Reliable reinforcement learning implementations,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning implementations,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021. [Online]. Available: http://jmlr.org/papers/v22/20- 1364.html
2021
-
[26]
Holoocean: Realistic sonar simulation,
E. Potokar, K. Lay, K. Norman, D. Benham, T. B. Neilsen, M. Kaess, and J. G. Mangelson, “Holoocean: Realistic sonar simulation,” in2022 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2022, pp. 8450–8456
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.