EinSort: Sorting is All We Need for Tensorizing LLM
Pith reviewed 2026-06-27 18:29 UTC · model grok-4.3
The pith
Sorting the indices of a tensor uncovers its hidden low-rank structure for better LLM compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
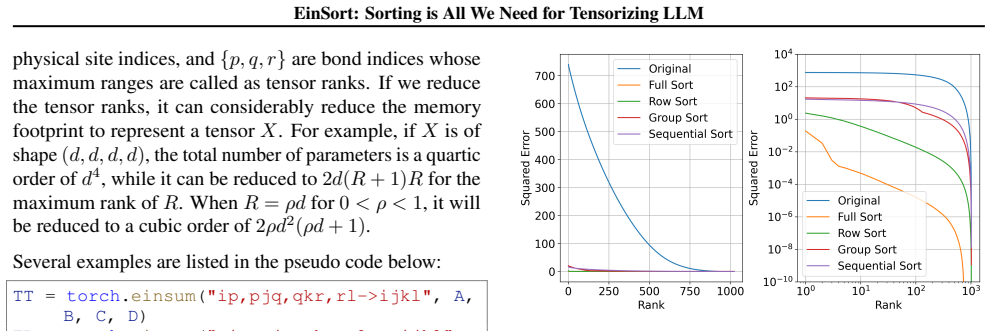
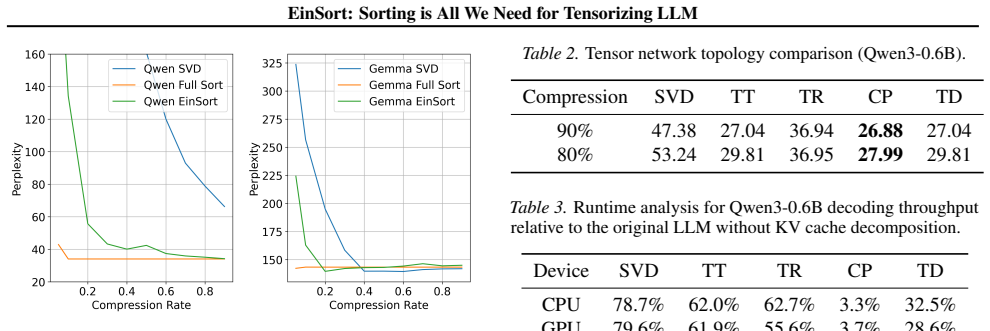
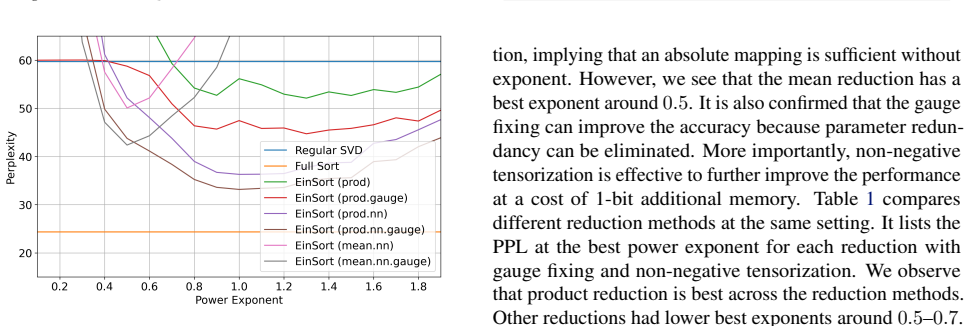
The central claim is that an adaptive tensorization procedure based on index ordering by sorting reliably discovers inherent low-rank structure inside the otherwise unstructured weight tensors of large language models, leading to higher-fidelity reconstructions when the resulting tensor networks are used for weight and KV-cache compression.
What carries the argument
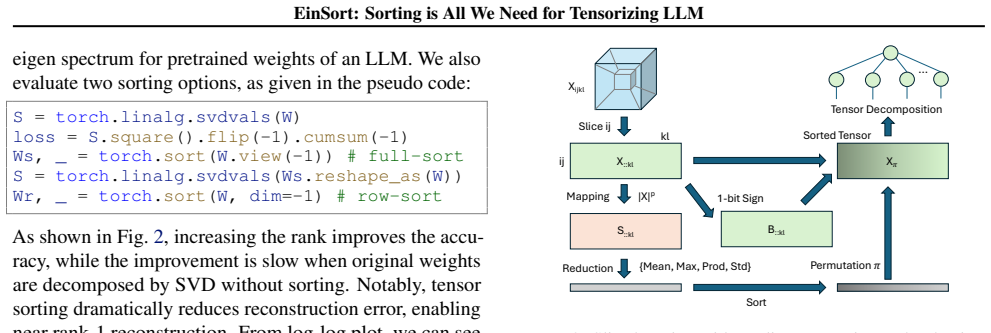
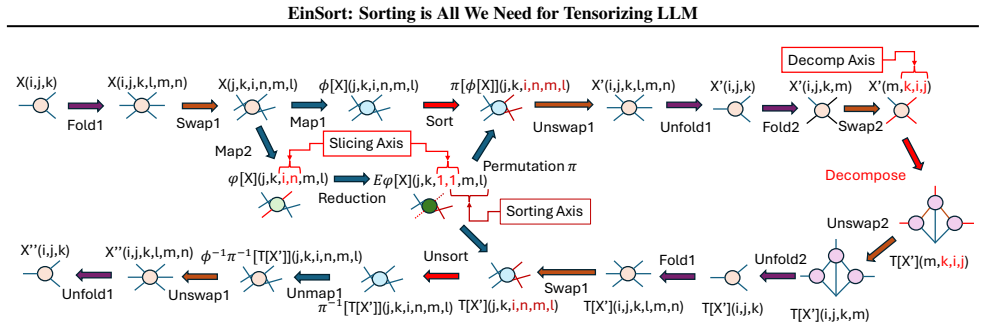
EinSort, the sorting-based index reordering step that adaptively permutes tensor modes to expose low-rank structure before tensor-network decomposition.
If this is right
- Tensor networks can represent LLM weights at lower error for a given compression ratio once indices are sorted.
- KV-cache tensors in transformer inference also admit better compression under the same reordering.
- The method works without requiring changes to model architecture or additional training.
Where Pith is reading between the lines
- The success of sorting suggests that index order in weight tensors is not arbitrary and may reflect training dynamics or architectural symmetries.
- Similar permutation-based preprocessing could be tested on other tensor formats such as attention matrices or embedding tables.
- If the reordering effect holds across scales, it may reduce the search space needed when designing tensor topologies for new models.
Load-bearing premise
Reordering a tensor's indices by sorting will consistently make its low-rank structure visible even when the original weight values appear unstructured.
What would settle it
Running the same tensor decomposition on LLM weight tensors with and without the sorting step and finding that reconstruction error does not decrease, or increases, for multiple models and decomposition ranks.
Figures

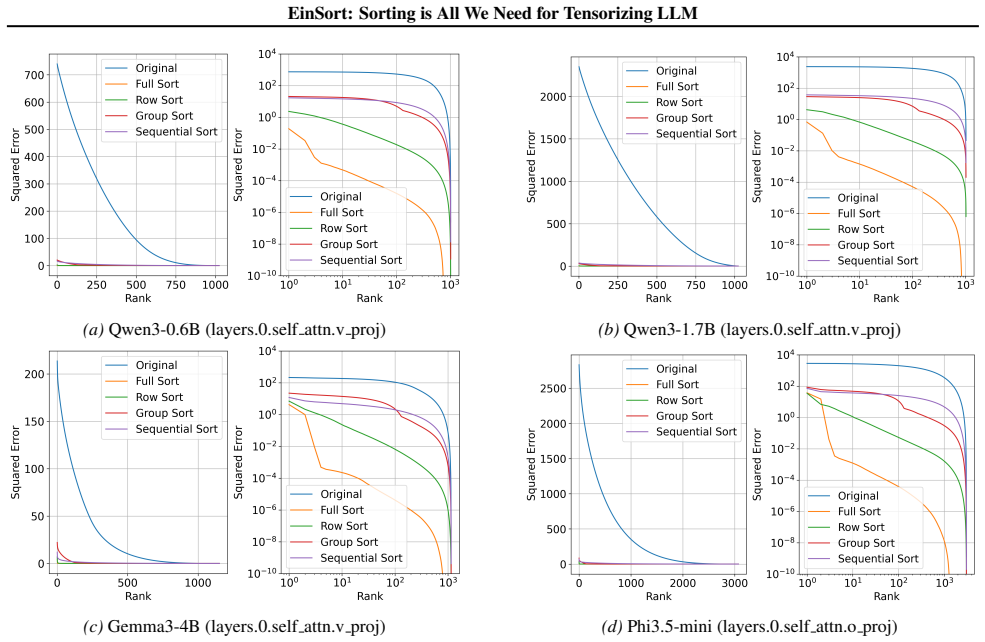
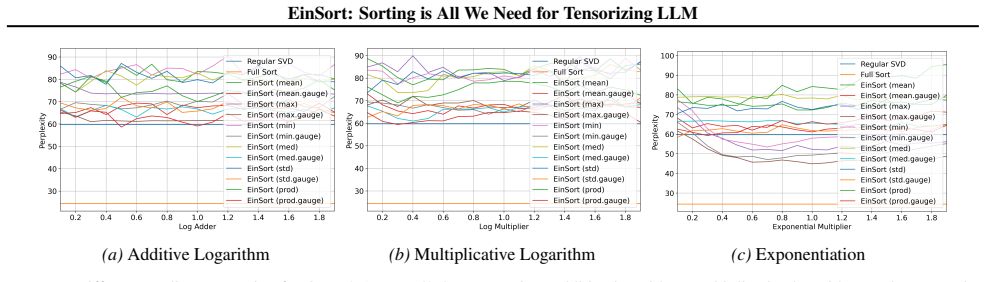
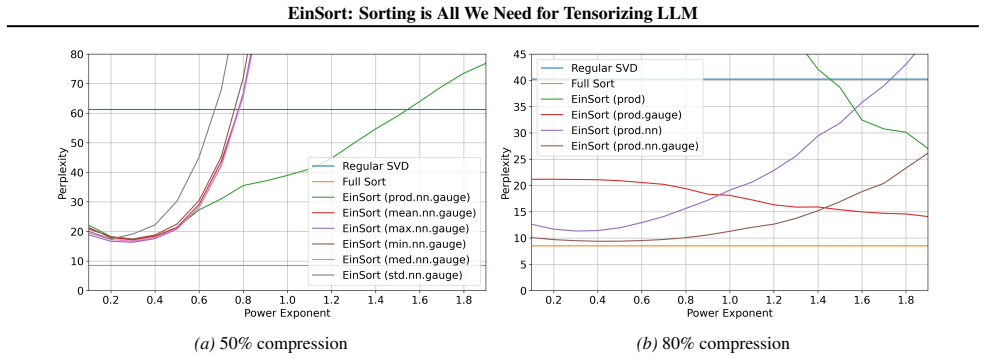
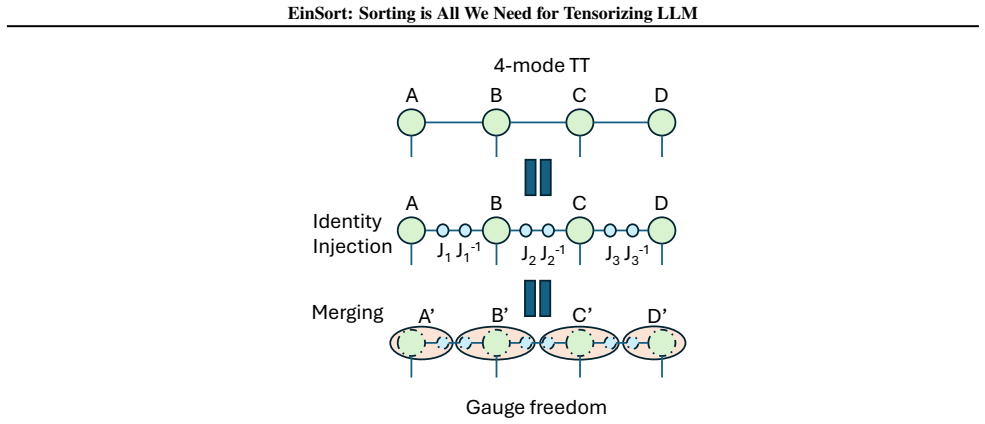
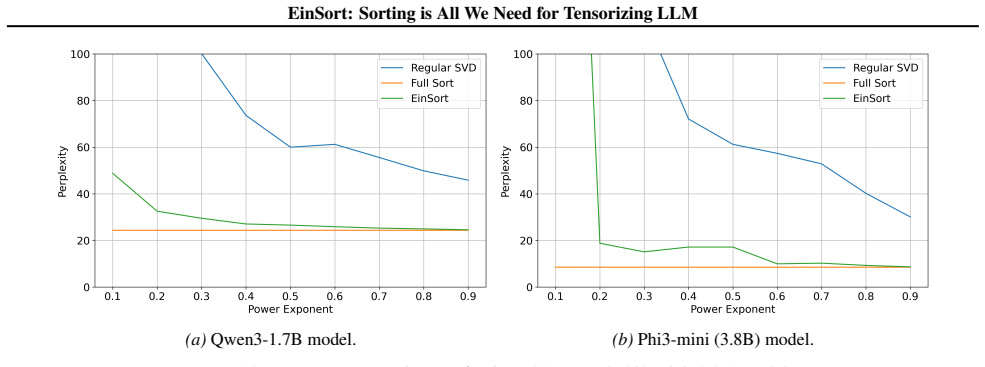
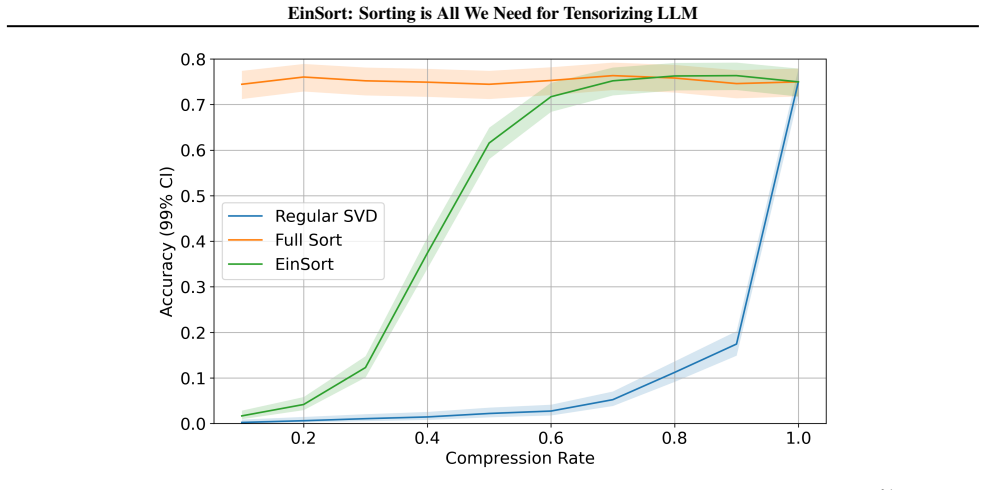
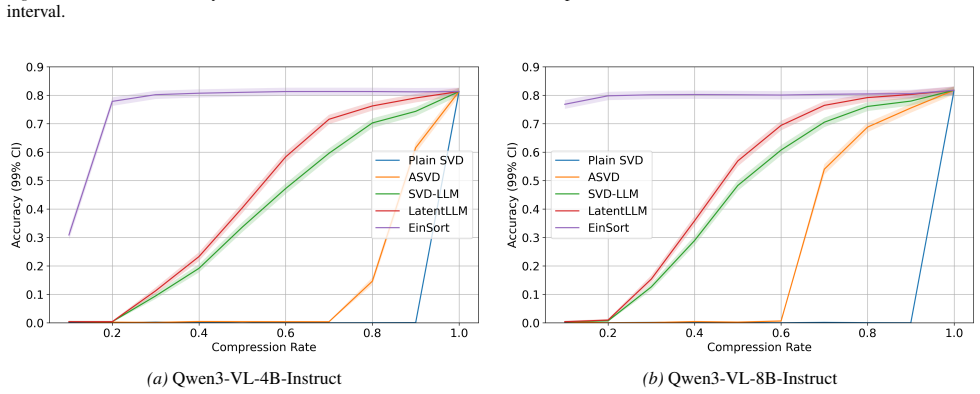

read the original abstract
Tensor networks provide efficient representations for compressing large neural networks. By carefully designing shapes and topologies, they can significantly reduce memory and computational costs. However, identifying implicit low-rank structures in large foundation models remains challenging due to their enormous scale and un-structured weight distributions. We propose an adaptive tensorization method that discovers inherent low-rank structure in a target tensor by index ordering. Experiments on weight and KV-cache compression demonstrate improved reconstruction quality compared to baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EinSort, an adaptive tensorization method for LLMs that discovers inherent low-rank structure in target tensors via index ordering (sorting). Experiments on weight and KV-cache compression are claimed to show improved reconstruction quality relative to baselines.
Significance. If the central claim holds under detailed scrutiny, the approach would supply a notably simple mechanism (index sorting) for exposing usable low-rank structure in the unstructured weights typical of foundation models, thereby easing the design burden for tensor-network compression and potentially lowering memory and compute costs.
minor comments (1)
- The provided text consists solely of the abstract; without access to the full manuscript, algorithms, experimental protocols, quantitative results, or error analysis, no technical evaluation of the method or its empirical support is possible.
Simulated Author's Rebuttal
We thank the referee for their review and for acknowledging the potential significance of a simple index-sorting mechanism for exposing low-rank structure in foundation-model weights. The recommendation is listed as uncertain with no specific major comments provided in the report. We therefore stand by the manuscript as submitted while remaining available to address any additional questions or clarifications the referee may have.
Circularity Check
No significant circularity identified
full rationale
The abstract and available context present a methodological proposal for adaptive tensorization via index ordering to discover low-rank structure, without any derivations, equations, fitted parameters, or self-citations that reduce claims to inputs by construction. No load-bearing steps are described that would qualify under the enumerated circularity patterns, making the derivation self-contained as an empirical suggestion rather than a tautological re-expression of prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Weight tensors of large foundation models contain exploitable low-rank structure once indices are suitably reordered.
Reference graph
Works this paper leans on
-
[1]
Abdin, M., Aneja, J., Behl, H., Bubeck, S., Eldan, R., Gunasekar, S., Harrison, M., Hewett, R. J., Javaheripi, M., Kauffmann, P., et al. Phi-4 technical report. arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abouelenin, A., Ashfaq, A., Atkinson, A., Awadalla, H., Bach, N., Bao, J., Benhaim, A., Cai, M., Chaudhary, V., Chen, C., et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of- LoRAs . arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
TQCompressor : improving tensor decomposition methods in neural networks via permutations
Abronin, V., Naumov, A., Mazur, D., Bystrov, D., Tsarova, K., Melnikov, A., Dolgov, S., Brasher, R., and Perelshein, M. TQCompressor : improving tensor decomposition methods in neural networks via permutations. In 2024 IEEE 7th International Conference on Multimedia Information Processing and Retrieval (MIPR), pp.\ 503--506. IEEE, 2024
2024
-
[4]
Phi-4-reasoning-vision- 15B technical report
Aneja, J., Harrison, M., Joshi, N., LaBonte, T., Langford, J., and Salinas, E. Phi-4-reasoning-vision- 15B technical report. arXiv preprint arXiv:2603.03975, 2026
-
[5]
Arai, Y. and Ichikawa, Y. Quantization error propagation: Revisiting layer-wise post-training quantization. arXiv preprint arXiv:2504.09629, 2025
-
[6]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al. V-JEPA 2 : Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Available: https://arxiv.org/abs/2401.00625
Bai, G., Chai, Z., Ling, C., Wang, S., Lu, J., Zhang, N., Shi, T., Yu, Z., Zhu, M., Zhang, Y., et al. Beyond efficiency: A systematic survey of resource-efficient large language models. arXiv preprint arXiv:2401.00625, 2024 a
-
[8]
SparseLLM : Towards global pruning for pre-trained language models
Bai, G., Li, Y., Ling, C., Kim, K., and Zhao, L. SparseLLM : Towards global pruning for pre-trained language models. arXiv preprint arXiv:2402.17946, 2024 b
-
[9]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3-VL technical report. arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
LoTR : Low tensor rank weight adaptation
Bershatsky, D., Cherniuk, D., Daulbaev, T., Mikhalev, A., and Oseledets, I. LoTR : Low tensor rank weight adaptation. arXiv preprint arXiv:2402.01376, 2024
-
[11]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A. S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., et al. PaliGemma : A versatile 3B VLM for transfer. arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
K., Hachtel, G
Brayton, R. K., Hachtel, G. D., McMullen, C., and Sangiovanni-Vincentelli, A. Logic minimization algorithms for VLSI synthesis , volume 2. Springer Science & Business Media, 1984
1984
-
[13]
Pyramid KV : Dynamic KV cache compression based on pyramidal information funneling
Cai, Z., Zhang, Y., Gao, B., Liu, Y., Li, Y., Liu, T., Lu, K., Xiong, W., Dong, Y., Hu, J., and Xiao, W. Pyramid KV : Dynamic KV cache compression based on pyramidal information funneling. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=ayi7qezU87
2025
-
[14]
arXiv preprint arXiv:2407.21118 , year=
Chang, C.-C., Lin, W.-C., Lin, C.-Y., Chen, C.-Y., Hu, Y.-F., Wang, P.-S., Huang, N.-C., Ceze, L., Abdelfattah, M. S., and Wu, K.-C. Palu: Compressing KV -cache with low-rank projection. arXiv preprint arXiv:2407.21118, 2024
-
[15]
One-for-all: Generalized LoRA for parameter-efficient fine-tuning
Chavan, A., Liu, Z., Gupta, D., Xing, E., and Shen, Z. One-for-all: Generalized LoRA for parameter-efficient fine-tuning. arXiv preprint arXiv:2306.07967, 2023
-
[16]
SuperLoRA : Parameter-efficient unified adaptation for large vision models
Chen, X., Liu, J., Wang, Y., Wang, P., Brand, M., Wang, G., and Koike-Akino, T. SuperLoRA : Parameter-efficient unified adaptation for large vision models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 8050--8055, 2024 a
2024
-
[17]
QuanTA : Efficient high-rank fine-tuning of LLMs with quantum-informed tensor adaptation
Chen, Z., Dangovski, R., Loh, C., Dugan, O., Luo, D., and Solja c i \'c , M. QuanTA : Efficient high-rank fine-tuning of LLMs with quantum-informed tensor adaptation. Advances in Neural Information Processing Systems, 37: 0 92210--92245, 2024 b
2024
-
[18]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. URL https://arxiv. org/abs/2110.14168, 9, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
David, H. A. and Nagaraja, H. N. Order statistics. John Wiley & Sons, 2004
2004
-
[20]
Predicting parameters in deep learning
Denil, M., Shakibi, B., Dinh, L., Ranzato, M., and De Freitas, N. Predicting parameters in deep learning. Advances in neural information processing systems, 26, 2013
2013
-
[21]
L., Zaremba, W., Bruna, J., LeCun, Y., and Fergus, R
Denton, E. L., Zaremba, W., Bruna, J., LeCun, Y., and Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. Advances in neural information processing systems, 27, 2014
2014
-
[22]
DaViT : Dual attention vision transformers
Ding, M., Xiao, B., Codella, N., Luo, P., Wang, J., and Yuan, L. DaViT : Dual attention vision transformers. In European conference on computer vision, pp.\ 74--92. Springer, 2022
2022
-
[23]
Learning to prune deep neural networks via layer-wise optimal brain surgeon
Dong, X., Chen, S., and Pan, S. Learning to prune deep neural networks via layer-wise optimal brain surgeon. Advances in neural information processing systems, 30, 2017
2017
-
[24]
W., and Keutzer, K
Dong, Z., Yao, Z., Gholami, A., Mahoney, M. W., and Keutzer, K. HAWQ : Hessian aware quantization of neural networks with mixed-precision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 293--302, 2019
2019
-
[25]
Edalati, A., Tahaei, M., Kobyzev, I., Nia, V. P., Clark, J. J., and Rezagholizadeh, M. KronA : Parameter efficient tuning with kronecker adapter. arXiv preprint arXiv:2212.10650, 2022
-
[26]
Gauge fixing, canonical forms, and optimal truncations in tensor networks with closed loops
Evenbly, G. Gauge fixing, canonical forms, and optimal truncations in tensor networks with closed loops. Physical Review B, 98 0 (8): 0 085155, 2018
2018
-
[27]
and Alistarh, D
Frantar, E. and Alistarh, D. SparseGPT : Massive language models can be accurately pruned in one-shot. In International Conference on Machine Learning, pp.\ 10323--10337. PMLR, 2023
2023
-
[28]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. GPTQ : Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
S., Thomas, A., Spector, B., Poli, M., Rudra, A., and R \'e , C
Fu, D., Arora, S., Grogan, J., Johnson, I., Eyuboglu, E. S., Thomas, A., Spector, B., Poli, M., Rudra, A., and R \'e , C. Monarch mixer: A simple sub-quadratic GEMM -based architecture. Advances in Neural Information Processing Systems, 36: 0 77546--77603, 2023
2023
-
[30]
Gemma Team , Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram \'e , A., Rivi \`e re, M., et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Stochastic Optimization of Sorting Networks via Continuous Relaxations
Grover, A., Wang, E., Zweig, A., and Ermon, S. Stochastic optimization of sorting networks via continuous relaxations. arXiv preprint arXiv:1903.08850, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[32]
Phi-3 safety post-training: Aligning language models with a ``break-fix'' cycle
Haider, E., Perez-Becker, D., Portet, T., Madan, P., Garg, A., Ashfaq, A., Majercak, D., Wen, W., Kim, D., Yang, Z., et al. Phi-3 safety post-training: Aligning language models with a ``break-fix'' cycle. arXiv preprint arXiv:2407.13833, 2024
-
[33]
Optimal brain surgeon: Extensions and performance comparisons
Hassibi, B., Stork, D., and Wolff, G. Optimal brain surgeon: Extensions and performance comparisons. Advances in neural information processing systems, 6, 1993
1993
-
[34]
LoRA +: Efficient low rank adaptation of large models
Hayou, S., Ghosh, N., and Yu, B. LoRA +: Efficient low rank adaptation of large models. In International Conference on Machine Learning, 2024
2024
-
[35]
Hsieh, C.-Y., Li, C.-L., Yeh, C.-K., Nakhost, H., Fujii, Y., Ratner, A., Krishna, R., Lee, C.-Y., and Pfister, T. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2021
2021
-
[37]
B., and Stoudenmire, E
Huggins, W., Patil, P., Mitchell, B., Whaley, K. B., and Stoudenmire, E. M. Towards quantum machine learning with tensor networks. Quantum Science and technology, 4 0 (2): 0 024001, 2019
2019
-
[38]
PC-LoRA : Low-rank adaptation for progressive model compression with knowledge distillation
Hwang, I., Park, H., Lee, Y., Yang, J., and Maeng, S. PC-LoRA : Low-rank adaptation for progressive model compression with knowledge distillation. arXiv preprint arXiv:2406.09117, 2024
-
[39]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al. _ 0.5 : a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Speeding up Convolutional Neural Networks with Low Rank Expansions
Jaderberg, M., Vedaldi, A., and Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv preprint arXiv:1405.3866, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[41]
M., Bommarito, M
Katz, D. M., Bommarito, M. J., Gao, S., and Arredondo, P. GPT -4 passes the bar exam. Philosophical Transactions of the Royal Society A, 382 0 (2270): 0 20230254, 2024
2024
-
[42]
-moe: Test-time pruning as micro-grained mixture-of-experts
Koike-Akino, T., Liu, J., and Wang, Y. -moe: Test-time pruning as micro-grained mixture-of-experts. arXiv preprint arXiv:2505.18451, 2025 a
-
[43]
Koike-Akino, T., Tonin, F., Wu, Y., Wu, F. Z., Candogan, L. N., and Cevher, V. Quantum-PEFT : Ultra parameter-efficient fine-tuning. arXiv preprint arXiv:2503.05431, 2025 b
-
[44]
P., and Brand, M
Koike-Akino, T., Chen, X., Liu, J., Wang, Y., Wang, P. P., and Brand, M. LatentLLM : Activation-aware transform to multi-head latent attention. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 22644--22652, 2026 a
2026
-
[45]
TTQ : Activation-aware test-time quantization to accelerate LLM inference on the fly
Koike-Akino, T., Liu, J., and Wang, Y. TTQ : Activation-aware test-time quantization to accelerate LLM inference on the fly. arXiv preprint arXiv:2603.19296, 2026 b
-
[46]
Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition
Lebedev, V., Ganin, Y., Rakhuba, M., Oseledets, I., and Lempitsky, V. Speeding-up convolutional neural networks using fine-tuned CP -decomposition. arXiv preprint arXiv:1412.6553, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
Optimal brain damage
LeCun, Y., Denker, J., and Solla, S. Optimal brain damage. Advances in neural information processing systems, 2, 1989
1989
-
[48]
Lehmer, D. H. Teaching combinatorial tricks to a computer. In Proceedings of Symposia in Applied Mathematics, pp.\ 179--193. American Mathematical Society, 1960
1960
-
[49]
Reversible simulation of irreversible computation
Li, M., Tromp, J., and Vit \'a nyi, P. Reversible simulation of irreversible computation. Physica D: Nonlinear Phenomena, 120 0 (1-2): 0 168--176, 1998
1998
-
[50]
Optimal brain decomposition for accurate LLM low-rank approximation
Li, Y., Lee, D., Yin, R., and Panda, P. Optimal brain decomposition for accurate LLM low-rank approximation. arXiv preprint arXiv:2604.00821, 2026
-
[51]
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Lin, B., Tang, Z., Ye, Y., Cui, J., Zhu, B., Jin, P., Zhang, J., Ning, M., and Yuan, L. MoE-LlaVa : Mixture of experts for large vision-language models. arXiv preprint arXiv:2401.15947, 2024 a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Lin, J., Tang, J., Tang, H., Yang, S., Dang, X., and Han, S. AWQ : Activation-aware weight quantization for LLM compression and acceleration. arXiv preprint arXiv:2306.00978, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.-M., Wang, W.-C., Xiao, G., Dang, X., Gan, C., and Han, S. AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration. Proceedings of Machine Learning and Systems, 6: 0 87--100, 2024 b
2024
-
[54]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. DeepSeek -v3 technical report. arXiv preprint arXiv:2412.19437, 2024 a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
LIBERO : Benchmarking knowledge transfer for lifelong robot learning
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., and Stone, P. LIBERO : Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36: 0 44776--44791, 2023 a
2023
-
[56]
LoDA : Low-dimensional adaptation of large language models
Liu, J., Koike-Akino, T., Wang, P., Brand, M., Wang, Y., and Parsons, K. LoDA : Low-dimensional adaptation of large language models. In NeurIPS’23 Workshop on on Efficient Natural Language and Speech Processing, 2023 b
2023
-
[57]
AWP : Activation-aware weight pruning and quantization with projected gradient descent
Liu, J., Koike-Akino, T., Wang, Y., Mansour, H., and Brand, M. AWP : Activation-aware weight pruning and quantization with projected gradient descent. arXiv preprint arXiv:2506.10205, 2025
-
[58]
KIVI : A tuning-free asymmetric 2bit quantization for KV cache
Liu, Z., Yuan, J., Jin, H., Zhong, S., Xu, Z., Braverman, V., Chen, B., and Hu, X. KIVI : A tuning-free asymmetric 2bit quantization for KV cache. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of ...
2024
-
[59]
An adaptive tensor-train decomposition approach for efficient deep neural network compression
Luo, S., Liu, M., Yu, Y., Ren, S., and Bai, Y. An adaptive tensor-train decomposition approach for efficient deep neural network compression. arXiv preprint arXiv:2408.01534, 2024
-
[60]
McCluskey, E. J. Minimization of Boolean functions. The Bell System Technical Journal, 35 0 (6): 0 1417--1444, 1956
1956
-
[61]
Learning Latent Permutations with Gumbel-Sinkhorn Networks
Mena, G., Belanger, D., Linderman, S., and Snoek, J. Learning latent permutations with Gumbel - Sinkhorn networks. arXiv preprint arXiv:1802.08665, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[63]
Novikov, A., Podoprikhin, D., Osokin, A., and Vetrov, D. P. Tensorizing neural networks. Advances in neural information processing systems, 28, 2015
2015
-
[64]
A practical introduction to tensor networks: Matrix product states and projected entangled pair states
Or \'u s, R. A practical introduction to tensor networks: Matrix product states and projected entangled pair states. Annals of physics, 349: 0 117--158, 2014
2014
-
[65]
PyTorch : An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al. PyTorch : An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019
2019
-
[66]
and Xie, S
Peebles, W. and Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 4195--4205, 2023
2023
-
[67]
Stable low-rank tensor decomposition for compression of convolutional neural network
Phan, A.-H., Sobolev, K., Sozykin, K., Ermilov, D., Gusak, J., Tichavsk \`y , P., Glukhov, V., Oseledets, I., and Cichocki, A. Stable low-rank tensor decomposition for compression of convolutional neural network. In European Conference on Computer Vision, pp.\ 522--539. Springer, 2020
2020
-
[68]
and Eisenschlos, J
Prillo, S. and Eisenschlos, J. SoftSort : A continuous relaxation for the argsort operator. In International Conference on Machine Learning, pp.\ 7793--7802. PMLR, 2020
2020
-
[69]
TensorNetwork: A Library for Physics and Machine Learning
Roberts, C., Milsted, A., Ganahl, M., Zalcman, A., Fontaine, B., Zou, Y., Hidary, J., Vidal, G., and Leichenauer, S. TensorNetwork : A library for physics and machine learning. arXiv preprint arXiv:1905.01330, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[70]
Compressing large language models using low rank and low precision decomposition
Saha, R., Sagan, N., Srivastava, V., Goldsmith, A., and Pilanci, M. Compressing large language models using low rank and low precision decomposition. Advances in Neural Information Processing Systems, 37: 0 88981--89018, 2024
2024
-
[71]
N., Kingsbury, B., Sindhwani, V., Arisoy, E., and Ramabhadran, B
Sainath, T. N., Kingsbury, B., Sindhwani, V., Arisoy, E., and Ramabhadran, B. Low-rank matrix factorization for deep neural network training with high-dimensional output targets. In 2013 IEEE international conference on acoustics, speech and signal processing, pp.\ 6655--6659. IEEE, 2013
2013
-
[72]
Eigen attention: Attention in low-rank space for KV cache compression
Saxena, U., Saha, G., Choudhary, S., and Roy, K. Eigen attention: Attention in low-rank space for KV cache compression. arXiv preprint arXiv:2408.05646, 2024
-
[73]
The density-matrix renormalization group in the age of matrix product states
Schollw \"o ck, U. The density-matrix renormalization group in the age of matrix product states. Annals of physics, 326 0 (1): 0 96--192, 2011
2011
-
[74]
A., and Etzioni, O
Schwartz, R., Dodge, J., Smith, N. A., and Etzioni, O. Green AI . Communications of the ACM, 63 0 (12): 0 54--63, 2020
2020
-
[75]
D., De Lathauwer, L., Fu, X., Huang, K., Papalexakis, E
Sidiropoulos, N. D., De Lathauwer, L., Fu, X., Huang, K., Papalexakis, E. E., and Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Transactions on signal processing, 65 0 (13): 0 3551--3582, 2017
2017
-
[76]
Towards VQA models that can read
Singh, A., Natarjan, V., Shah, M., Jiang, Y., Chen, X., Parikh, D., and Rohrbach, M. Towards VQA models that can read. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 8317--8326, 2019
2019
- [77]
-
[78]
Sun, J., Zhang, W., Qi, Z., Ren, S., Liu, Z., Zhu, H., Sun, G., Jin, X., and Chen, Z. VLA-JEPA : Enhancing vision-language-action model with latent world model. arXiv preprint arXiv:2602.10098, 2026
-
[79]
Sun, M., Liu, Z., Bair, A., and Kolter, J. Z. A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Takeshita, O. Y. Permutation polynomial interleavers: An algebraic-geometric perspective. IEEE Transactions on Information Theory, 53 0 (6): 0 2116--2132, 2007
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.