Parameter Tuning with Generalization Guarantees for GPU-Accelerated Linear Programming
Pith reviewed 2026-06-27 17:55 UTC · model grok-4.3
The pith
Hyperparameter tuning for the PDLP linear programming solver comes with polynomial sample complexity generalization guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By capturing the behavior of the PDLP solution trajectory as a function of its hyperparameters through analysis of PDHG and the specialized techniques, the work obtains polynomial sample complexity guarantees for learning those hyperparameters using data-driven algorithm design.
What carries the argument
Structural analysis of PDLP that models the solution trajectory as a function of the hyperparameters including preconditioning, adaptive step sizes, averaging, adaptive restarts, and smoothed primal weight updates.
If this is right
- Linear sample complexity guarantees hold for learning step size and primal weight in the base PDHG algorithm.
- Polynomial sample complexity guarantees extend to the complete collection of techniques inside PDLP.
- Data-driven tuning becomes feasible for solver-grade implementations of complex first-order methods.
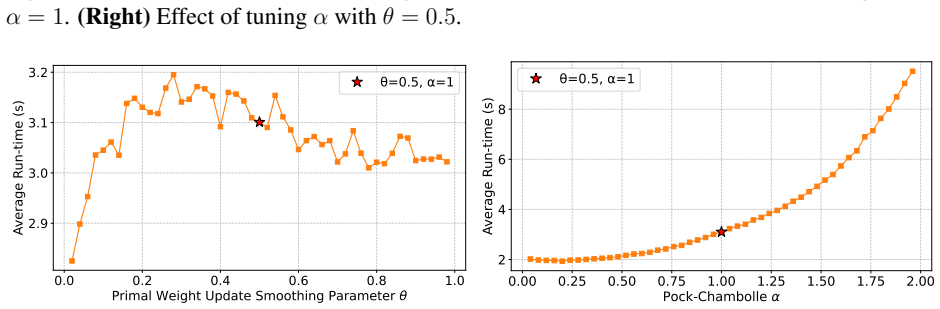
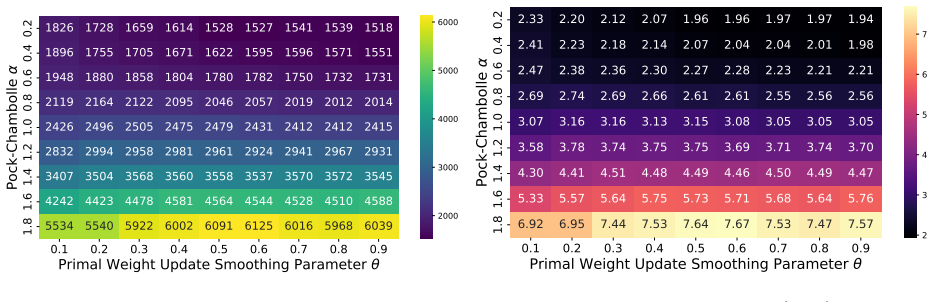
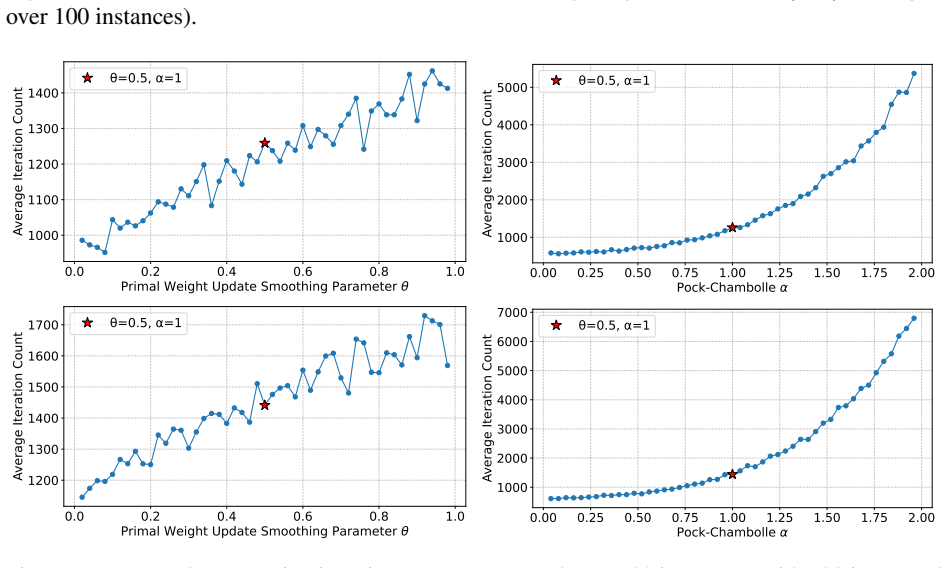
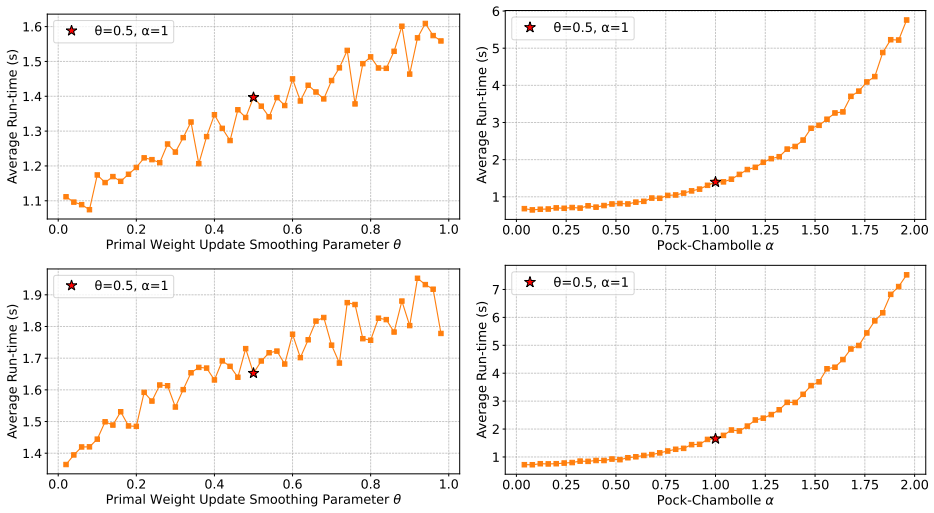
- Proof-of-concept experiments confirm that performance depends on careful hyperparameter choice.
Where Pith is reading between the lines
- Similar trajectory analysis could support tuning in other first-order solvers that share PDHG as a core routine.
- The approach may reduce manual trial-and-error in production deployments of GPU-accelerated optimization code.
- Bounds could be tightened further by incorporating instance-specific features into the learning procedure.
Load-bearing premise
The structural analysis of PDLP accurately models how its full set of techniques affects the solution trajectory as a function of the hyperparameters.
What would settle it
A test set of linear programming instances where the generalization error of hyperparameters learned from training data exceeds the polynomial bound derived in the analysis.
Figures
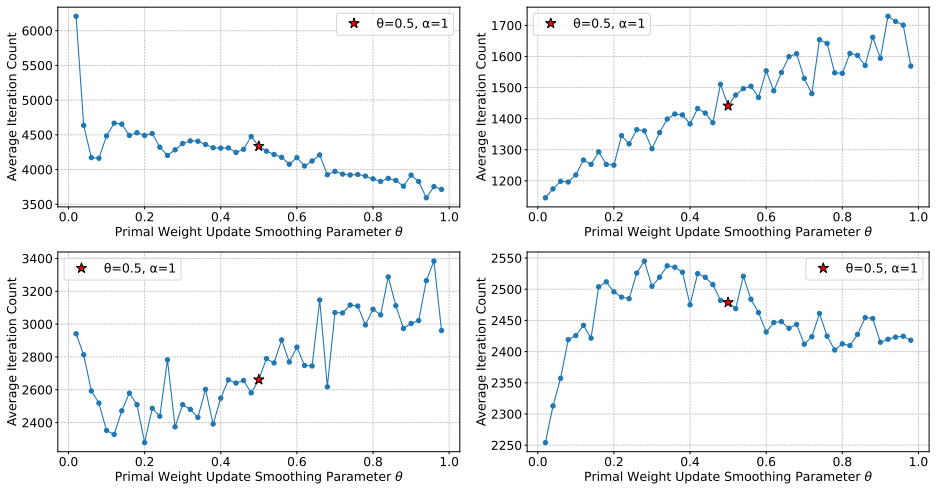
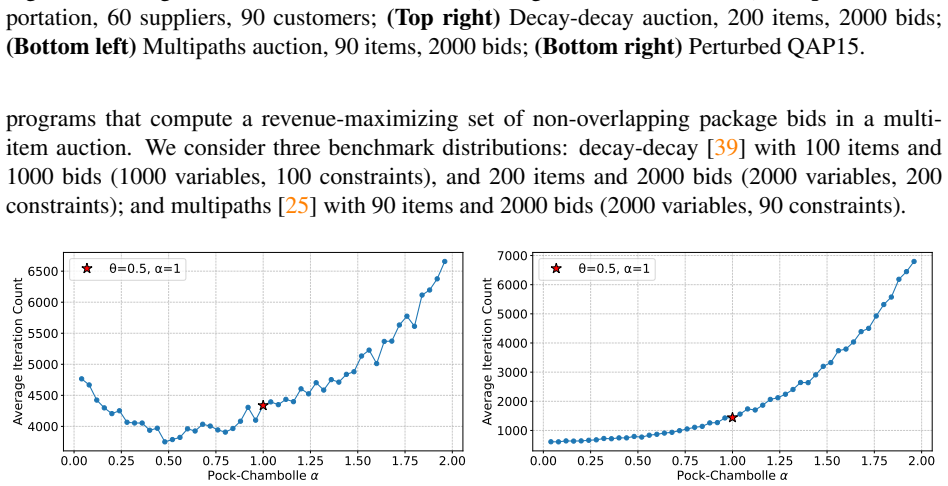
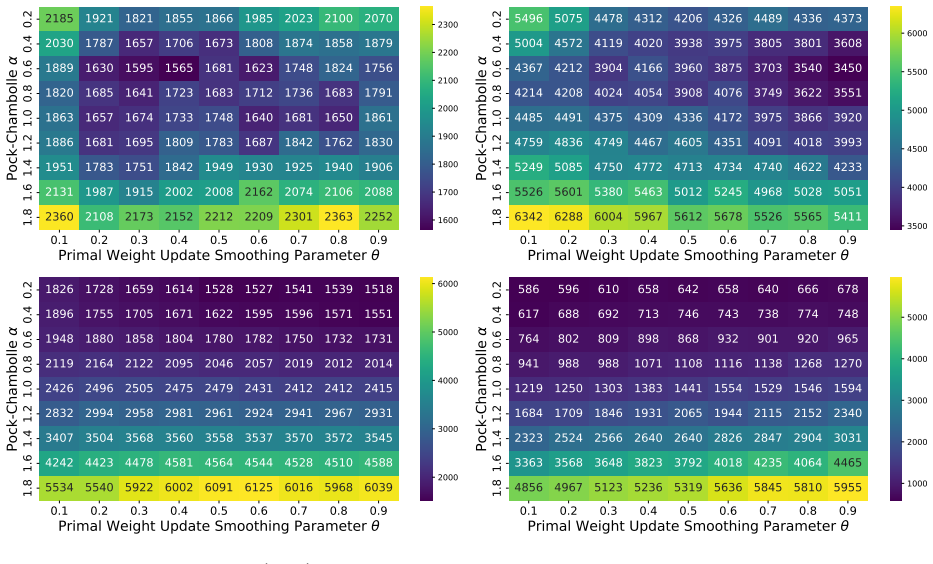
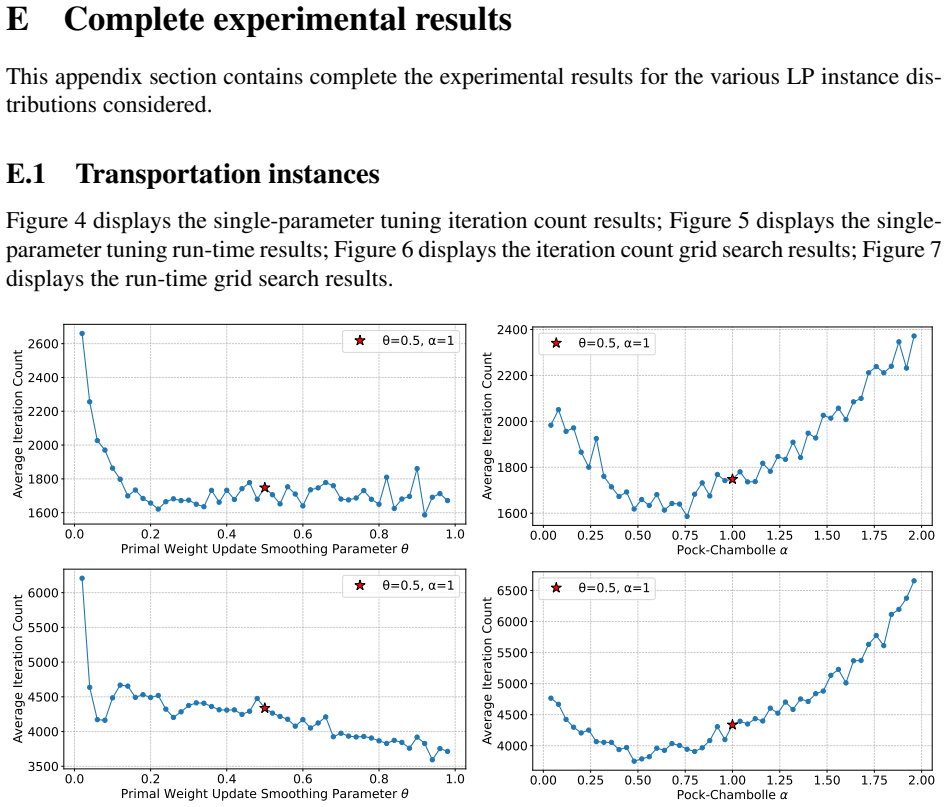
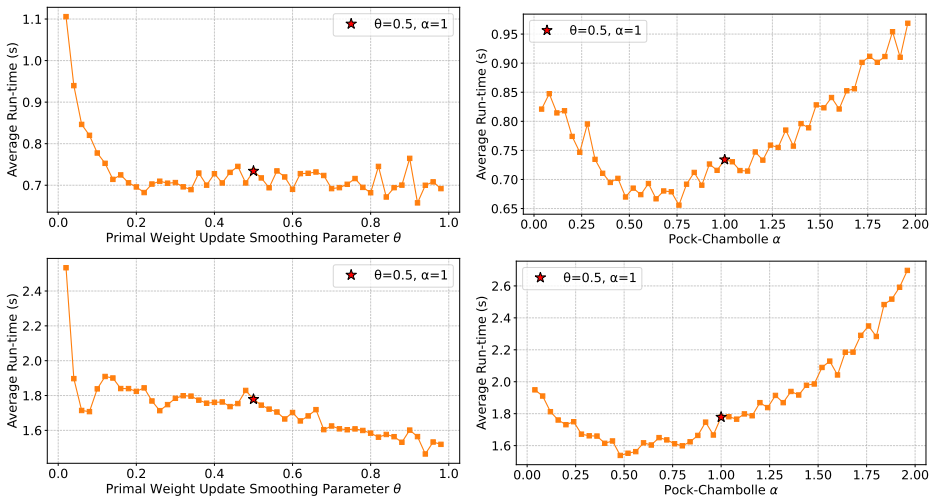
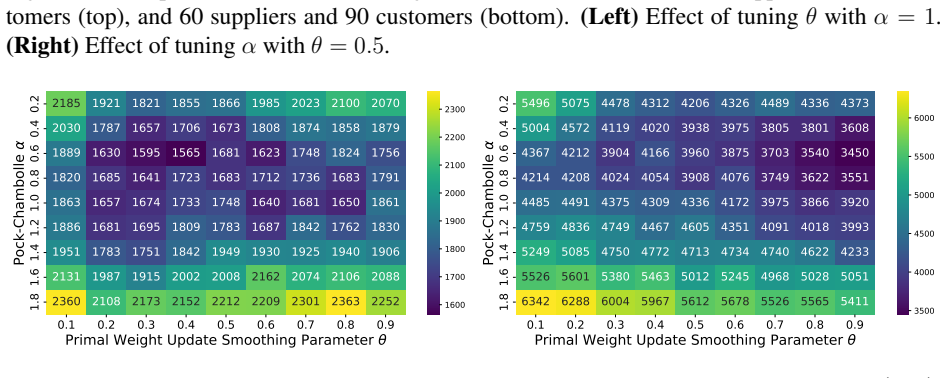
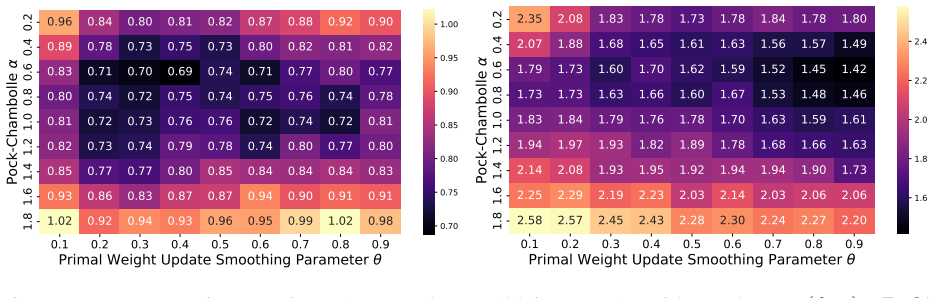
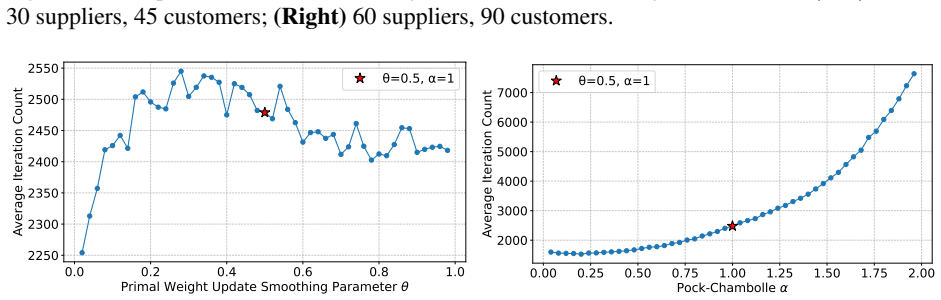
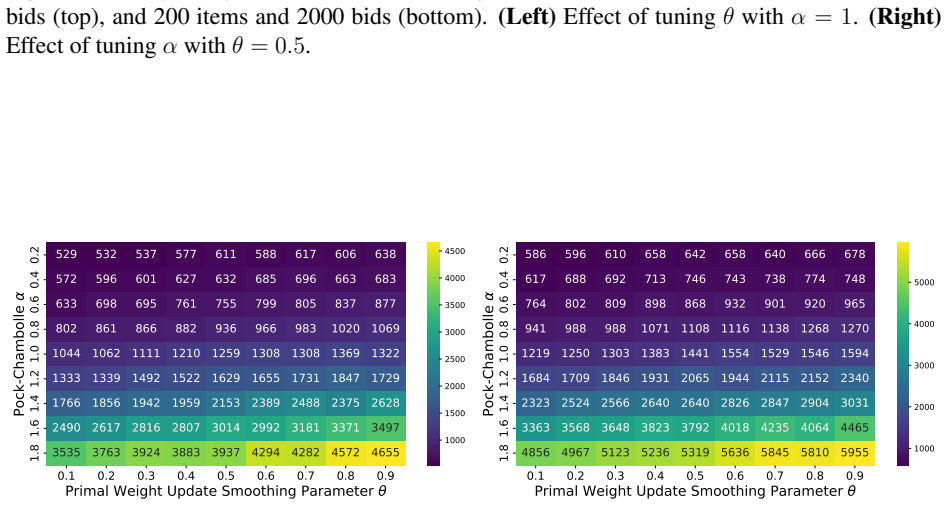
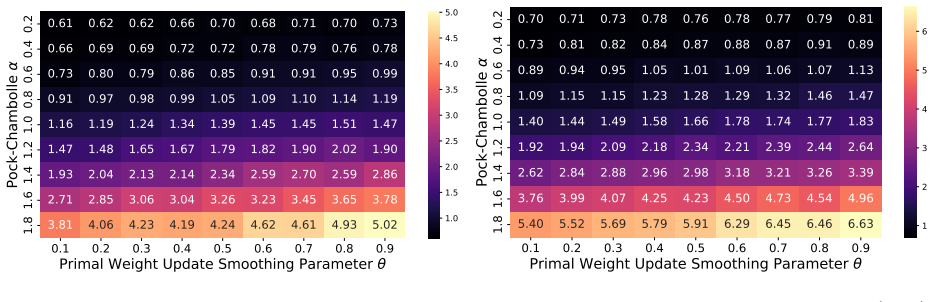
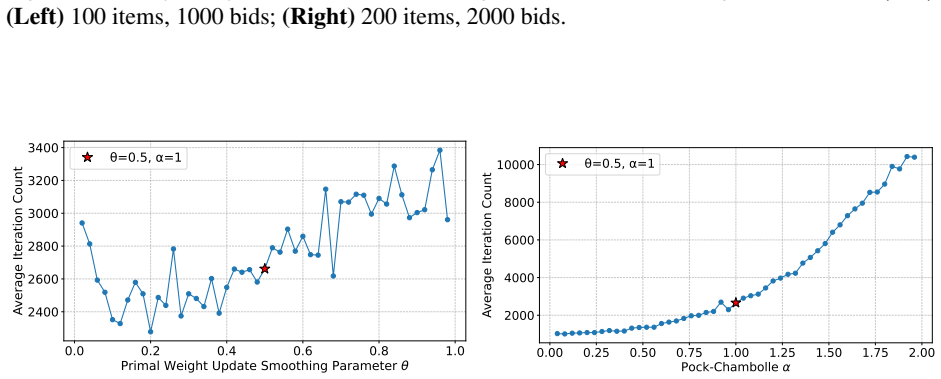
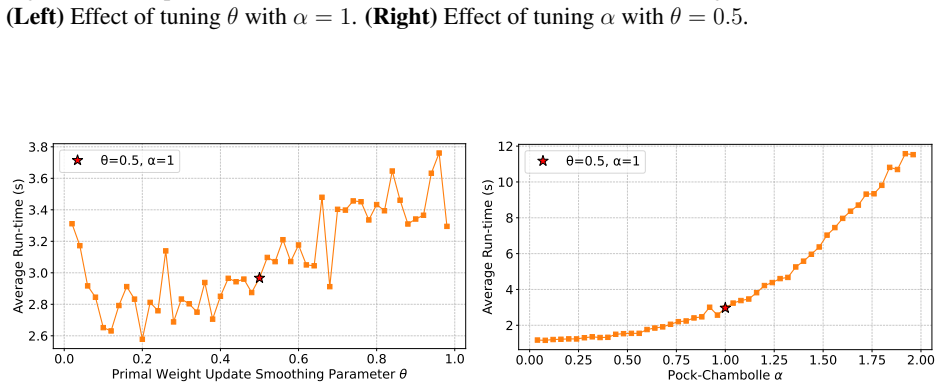
read the original abstract
Recent research has developed practical, parallelizable first-order methods for large scale linear programming, but performance is highly dependent on hyperparameter selection. We derive generalization guarantees for hyperparameter tuning within (cu)PDLP, a state-of-the-art first-order LP solver designed for modern hardware. First, we pin down the behavior of PDHG, the primal-dual hybrid gradient algorithm that underlies PDLP, as a function of its step size and primal weight, leading to linear sample complexity guarantees for learning those parameters. We then conduct a structural analysis of PDLP, which augments PDHG with several specialized techniques like preconditioning, adaptive step sizes, averaging, adaptive restarts, and smoothed primal weight updates. Our analysis captures the behavior of the solution trajectory as a function of the hyperparameters and leverages recent advances in data-driven algorithm design to obtain polynomial sample complexity guarantees for learning those hyperparameters. Finally, we conduct proof-of-concept experiments that demonstrate the need for data-driven PDLP parameter tuning. Our results showcase the versatility of the data-driven algorithm design toolkit for principled hyperparameter tuning within solver-grade implementations of complex modern optimization algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives generalization guarantees for hyperparameter tuning in the (cu)PDLP first-order LP solver. It first establishes linear sample complexity for tuning the step size and primal weight of the underlying PDHG algorithm, then performs a structural analysis of the full PDLP (incorporating preconditioning, adaptive step sizes, averaging, adaptive restarts, and smoothed primal weight updates) to obtain polynomial sample complexity via data-driven algorithm design tools, and concludes with proof-of-concept experiments demonstrating the need for such tuning.
Significance. If the structural analysis rigorously controls trajectory sensitivity, the result would meaningfully extend data-driven algorithm design to practical, GPU-accelerated solvers by supplying polynomial-sample guarantees for complex, adaptive first-order methods; this is a non-trivial bridge between theoretical generalization bounds and solver-grade implementations.
major comments (2)
- [Abstract (structural analysis of PDLP)] Abstract (structural analysis of PDLP): the claim that the analysis 'captures the behavior of the solution trajectory' under adaptive restarts and smoothed primal weight updates to deliver polynomial sample complexity is load-bearing. Adaptive restarts are triggered by instance-dependent duality-gap conditions; without explicit lemmas bounding the Lipschitz constant or covering number of the induced performance map (e.g., duality gap after fixed iterations) with respect to the hyperparameters, it is unclear whether the Rademacher complexity remains polynomial rather than super-polynomial in problem size or conditioning.
- [PDHG analysis paragraph] PDHG analysis paragraph: the linear sample complexity guarantee for step size and primal weight is asserted after 'pinning down the behavior,' yet the manuscript provides no displayed equations or key regularity conditions (e.g., how the convergence rate or duality gap depends on these two parameters) that would allow verification that the function class indeed admits linear rather than higher sample complexity.
minor comments (2)
- The experiments are labeled 'proof-of-concept'; adding quantitative tables (e.g., duality-gap improvement versus default parameters across instance classes) and explicit baseline comparisons would clarify the practical impact.
- Notation for the performance metric (e.g., which quantity is being bounded—duality gap, feasibility violation, or iteration count) should be introduced once and used consistently when stating the sample-complexity results.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our generalization results. We address each major comment below and will incorporate clarifications in a revised version.
read point-by-point responses
-
Referee: [Abstract (structural analysis of PDLP)] Abstract (structural analysis of PDLP): the claim that the analysis 'captures the behavior of the solution trajectory' under adaptive restarts and smoothed primal weight updates to deliver polynomial sample complexity is load-bearing. Adaptive restarts are triggered by instance-dependent duality-gap conditions; without explicit lemmas bounding the Lipschitz constant or covering number of the induced performance map (e.g., duality gap after fixed iterations) with respect to the hyperparameters, it is unclear whether the Rademacher complexity remains polynomial rather than super-polynomial in problem size or conditioning.
Authors: The structural analysis in Sections 4 and 5 does bound the sensitivity of the solution trajectory (including under adaptive restarts triggered by duality-gap conditions and smoothed primal-weight updates) by establishing that the performance map from hyperparameters to duality gap after a fixed iteration count is Lipschitz continuous with a constant whose dependence on problem parameters yields polynomial covering numbers. This is achieved by composing the Lipschitz properties of each PDLP component (preconditioning, adaptive steps, averaging, restarts, and smoothing) and applying the data-driven algorithm design framework. To make the key regularity conditions and Lipschitz bounds more immediately verifiable, we will add an explicit summarizing lemma in the revision. revision: yes
-
Referee: [PDHG analysis paragraph] PDHG analysis paragraph: the linear sample complexity guarantee for step size and primal weight is asserted after 'pinning down the behavior,' yet the manuscript provides no displayed equations or key regularity conditions (e.g., how the convergence rate or duality gap depends on these two parameters) that would allow verification that the function class indeed admits linear rather than higher sample complexity.
Authors: We agree that the PDHG section would benefit from greater explicitness. The linear sample complexity follows from deriving that the duality gap after T iterations is Lipschitz in the step size and primal weight (with a Lipschitz constant linear in T and independent of instance size under standard boundedness assumptions on the LP), which places the function class in a regime where standard Rademacher bounds yield linear sample complexity. We will insert the key displayed equations for the duality-gap dependence and the associated regularity conditions in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation relies on new structural analysis and external data-driven design results
full rationale
The paper's core chain derives a new structural model of PDLP's trajectory (including adaptive restarts and smoothed updates) as a function of hyperparameters, then applies existing data-driven algorithm design tools for polynomial sample complexity. No equations or claims reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations. The PDHG linear-complexity step and PDLP augmentation are presented as independent analysis, with experiments as separate validation. This matches the default non-circular case.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The behavior of PDHG and PDLP can be captured as a function of the listed hyperparameters for the purpose of generalization analysis.
Reference graph
Works this paper leans on
-
[1]
Improved linear programming-based lower bounds for the quadratic assignment problem.DIMACS series in discrete mathematics and theoretical computer science, 16:43–77, 1994
Warren P Adams and Terri A Johnson. Improved linear programming-based lower bounds for the quadratic assignment problem.DIMACS series in discrete mathematics and theoretical computer science, 16:43–77, 1994
1994
-
[2]
Practical large-scale linear programming using primal- dual hybrid gradient.Advances in Neural Information Processing Systems, 34:20243–20257, 2021
David Applegate, Mateo D ´ıaz, Oliver Hinder, Haihao Lu, Miles Lubin, Brendan O’Donoghue, and Warren Schudy. Practical large-scale linear programming using primal- dual hybrid gradient.Advances in Neural Information Processing Systems, 34:20243–20257, 2021
2021
-
[3]
Data-driven algorithm design
Maria-Florina Balcan. Data-driven algorithm design. In Tim Roughgarden, editor,Beyond the Worst-Case Analysis of Algorithms. Cambridge University Press, 2020
2020
-
[4]
Learning accurate and interpretable decision trees
Maria-Florina Balcan and Dravyansh Sharma. Learning accurate and interpretable decision trees. InThe 40th Conference on Uncertainty in Artificial Intelligence, 2024. 12
2024
-
[5]
Learning within an instance for designing high-revenue combinatorial auctions
Maria-Florina Balcan, Siddharth Prasad, and Tuomas Sandholm. Learning within an instance for designing high-revenue combinatorial auctions. InProceedings of the Thirtieth Interna- tional Joint Conference on Artificial Intelligence, pages 31–37, 2021
2021
-
[6]
Sample complexity of tree search configuration: Cutting planes and beyond.Advances in Neural Information Processing Systems, 34:4015–4027, 2021
Maria-Florina Balcan, Siddharth Prasad, Tuomas Sandholm, and Ellen Vitercik. Sample complexity of tree search configuration: Cutting planes and beyond.Advances in Neural Information Processing Systems, 34:4015–4027, 2021
2021
-
[7]
Improved sample complexity bounds for branch-and-cut
Maria-Florina Balcan, Siddharth Prasad, Tuomas Sandholm, and Ellen Vitercik. Improved sample complexity bounds for branch-and-cut. In28th International Conference on Princi- ples and Practice of Constraint Programming, 2022
2022
-
[8]
Structural analysis of branch-and-cut and the learnability of gomory mixed integer cuts.Advances in Neural Information Processing Systems, 35:33890–33903, 2022
Maria-Florina Balcan, Siddharth Prasad, Tuomas Sandholm, and Ellen Vitercik. Structural analysis of branch-and-cut and the learnability of gomory mixed integer cuts.Advances in Neural Information Processing Systems, 35:33890–33903, 2022
2022
-
[9]
New bounds for hyperparameter tuning of regression problems across instances.Advances in Neural Information Processing Systems, 36:80066–80078, 2023
Maria-Florina Balcan, Anh Nguyen, and Dravyansh Sharma. New bounds for hyperparameter tuning of regression problems across instances.Advances in Neural Information Processing Systems, 36:80066–80078, 2023
2023
-
[10]
How much data is sufficient to learn high-performing algorithms?Journal of the ACM, 71(5):1–58, 2024
Maria-Florina Balcan, Dan Deblasio, Travis Dick, Carl Kingsford, Tuomas Sandholm, and Ellen Vitercik. How much data is sufficient to learn high-performing algorithms?Journal of the ACM, 71(5):1–58, 2024
2024
-
[11]
Algorithm configuration for structured Pfaffian settings.Transactions on Machine Learning Research, 2025
Maria-Florina Balcan, Anh Tuan Nguyen, and Dravyansh Sharma. Algorithm configuration for structured Pfaffian settings.Transactions on Machine Learning Research, 2025. ISSN 2835-8856
2025
-
[12]
Sample complexity of data-driven tuning of model hyperparameters in neural networks with structured parameter- dependent dual function
Maria-Florina Balcan, Anh Tuan Nguyen, and Dravyansh Sharma. Sample complexity of data-driven tuning of model hyperparameters in neural networks with structured parameter- dependent dual function. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[13]
Increasing revenue in effi- cient combinatorial auctions by learning to generate artificial competition
Maria-Florina Balcan, Siddharth Prasad, and Tuomas Sandholm. Increasing revenue in effi- cient combinatorial auctions by learning to generate artificial competition. InProceedings of the AAAI conference on artificial intelligence, volume 39, pages 13572–13580, 2025
2025
-
[14]
Generalization guarantees for multi-item profit maximization: Pricing, auctions, and randomized mechanisms.Operations Research, 73(2):648–663, 2025
Maria-Florina Balcan, Tuomas Sandholm, and Ellen Vitercik. Generalization guarantees for multi-item profit maximization: Pricing, auctions, and randomized mechanisms.Operations Research, 73(2):648–663, 2025
2025
-
[15]
Generalization bounds for data-driven numerical linear algebra
Peter Bartlett, Piotr Indyk, and Tal Wagner. Generalization bounds for data-driven numerical linear algebra. InConference on Learning Theory, pages 2013–2040. PMLR, 2022
2013
-
[16]
A first-order primal-dual algorithm for convex prob- lems with applications to imaging.Journal of mathematical imaging and vision, 40(1):120– 145, 2011
Antonin Chambolle and Thomas Pock. A first-order primal-dual algorithm for convex prob- lems with applications to imaging.Journal of mathematical imaging and vision, 40(1):120– 145, 2011. 13
2011
-
[17]
On the ergodic convergence rates of a first-order primal–dual algorithm.Mathematical Programming, 159(1):253–287, 2016
Antonin Chambolle and Thomas Pock. On the ergodic convergence rates of a first-order primal–dual algorithm.Mathematical Programming, 159(1):253–287, 2016
2016
-
[18]
Generalization guarantees for learning score-based branch-and-cut policies in integer programming
Hongyu Cheng and Amitabh Basu. Generalization guarantees for learning score-based branch-and-cut policies in integer programming. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[19]
Sample com- plexity of algorithm selection using neural networks and its applications to branch-and-cut
Hongyu Cheng, Sammy Khalife, Barbara Fiedorowicz, and Amitabh Basu. Sample com- plexity of algorithm selection using neural networks and its applications to branch-and-cut. Advances in Neural Information Processing Systems, 37:25036–25060, 2024
2024
-
[20]
Last fifty years of integer linear programming: A focus on recent practical advances.European Journal of Operational Research, 324(3):707–731, 2025
Franc ¸ois Clautiaux and Ivana Ljubi´c. Last fifty years of integer linear programming: A focus on recent practical advances.European Journal of Operational Research, 324(3):707–731, 2025
2025
-
[21]
A restarted primal-dual hybrid conjugate gradient method for large-scale quadratic program- ming.INFORMS Journal on Computing, 2025
Yicheng Huang, Wanyu Zhang, Hongpei Li, Dongdong Ge, Huikang Liu, and Yinyu Ye. A restarted primal-dual hybrid conjugate gradient method for large-scale quadratic program- ming.INFORMS Journal on Computing, 2025
2025
-
[22]
Learning to generate projections for reducing di- mensionality of heterogeneous linear programming problems
Tomoharu Iwata and Shinsaku Sakaue. Learning to generate projections for reducing di- mensionality of heterogeneous linear programming problems. InForty-second International Conference on Machine Learning, 2025
2025
-
[23]
American Mathematical Soc., 1991
Askold G Khovanskii.Fewnomials, volume 88. American Mathematical Soc., 1991
1991
-
[24]
Provably Data-driven Lagrangian Relaxation for Mixed Integer Linear Programming
Tung Quoc Le, Anh Tuan Nguyen, and Viet Anh Nguyen. Provably data-driven lagrangian relaxation for mixed integer linear programming.arXiv preprint arXiv:2605.19052, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Towards a universal test suite for combinatorial auction algorithms
Kevin Leyton-Brown, Mark Pearson, and Yoav Shoham. Towards a universal test suite for combinatorial auction algorithms. InProceedings of the 2nd ACM Conference on Electronic Commerce, pages 66–76, 2000
2000
-
[26]
Restarted Halpern PDHG for linear programming.arXiv preprint arXiv:2407.16144, 2024
Haihao Lu and Jinwen Yang. Restarted Halpern PDHG for linear programming.arXiv preprint arXiv:2407.16144, 2024
-
[27]
Haihao Lu and Jinwen Yang. cuPDLP. jl: A GPU implementation of restarted primal-dual hybrid gradient for linear programming in julia.Operations Research, 73(6):3440–3452, 2025
2025
-
[28]
Haihao Lu and Jinwen Yang. An overview of GPU-based first-order methods for linear programming and extensions.arXiv preprint arXiv:2506.02174, 2025
-
[29]
A practical and optimal first-order method for large-scale con- vex quadratic programming: H
Haihao Lu and Jinwen Yang. A practical and optimal first-order method for large-scale con- vex quadratic programming: H. lu, j. yang.Mathematical Programming, 215(1):771–808, 2026
2026
-
[30]
MPAX: Mathematical programming in JAX
Haihao Lu, Zedong Peng, and Jinwen Yang. MPAX: Mathematical programming in JAX. arXiv preprint arXiv:2412.09734, 2024. 14
-
[31]
Haihao Lu, Zedong Peng, and Jinwen Yang. cuPDLPx: A further enhanced GPU-based first-order solver for linear programming.arXiv preprint arXiv:2507.14051, 2025
-
[32]
A competitive GPU-accelerated LP solver in PyTorch, 2025
Muhammad Maaz. A competitive GPU-accelerated LP solver in PyTorch, 2025. URL https://www.mmaaz.ca/writings/pdlp.html
2025
-
[33]
Latest progress in optimization software
Hans D Mittelmann. Latest progress in optimization software. InINFORMS Annual Meeting, 2025
2025
-
[34]
Provably data-driven projection method for quadratic programming
Anh Tuan Nguyen and Viet Anh Nguyen. Provably data-driven projection method for quadratic programming. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 24541–24548, 2026
2026
-
[35]
Diagonal preconditioning for first order primal-dual algorithms in convex optimization
Thomas Pock and Antonin Chambolle. Diagonal preconditioning for first order primal-dual algorithms in convex optimization. In2011 International Conference on Computer Vision, pages 1762–1769. IEEE, 2011
2011
-
[36]
Springer Science & Business Media, 2012
David Pollard.Convergence of stochastic processes. Springer Science & Business Media, 2012
2012
-
[37]
A scaling algorithm to equilibrate both rows and columns norms in matrices
Daniel Ruiz. A scaling algorithm to equilibrate both rows and columns norms in matrices. Technical report, CM-P00040415, 2001
2001
-
[38]
Generalization bound and learning methods for data-driven projections in linear programming.Advances in Neural Information Processing Systems, 37: 12825–12846, 2024
Shinsaku Sakaue and Taihei Oki. Generalization bound and learning methods for data-driven projections in linear programming.Advances in Neural Information Processing Systems, 37: 12825–12846, 2024
2024
-
[39]
Winner determination in combinatorial auction generalizations
Tuomas Sandholm, Subhash Suri, Andrew Gilpin, and David Levine. Winner determination in combinatorial auction generalizations. InProceedings of the First International Confer- ence on Autonomous Agents and Multiagent Systems, pages 69–76, 2002
2002
-
[40]
Gradient descent with provably tuned learning-rate schedules.Twenty- Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS), 2026
Dravyansh Sharma. Gradient descent with provably tuned learning-rate schedules.Twenty- Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS), 2026
2026
-
[41]
Lower bounds for approximation by nonlinear manifolds.Transactions of the American Mathematical Society, 133(1):167–178, 1968
Hugh E Warren. Lower bounds for approximation by nonlinear manifolds.Transactions of the American Mathematical Society, 133(1):167–178, 1968. 15 A Additional Related Work First order methods for mathematical programmingPDLP and its GPU-accelerated counter- part cuPDLP have been further improved with cuPDLPx [31], which uses a different averaging scheme ba...
1968
-
[42]
for every instancex∈X, every row norm and column norm used in the final Pock–Chambolle scaling step of Algorithm 2 is strictly positive
-
[43]
there is a uniform boundbηmax on the input step sizebηpassed into each call to Algorithm 3 during the truncated execution (for example, the one prescribed by Lemma B.1)
-
[44]
Define Bmax := log bηmax κA log 1 1−(ST) −0.3 , and let UΘ,A ={u θ,α :X→Z|(θ, α)∈Θ×A}
writing eK(α)for the preconditioned matrix produced by Algorithm 2, the quantity κA := sup α∈A ∥eK(α)∥2 is finite. Define Bmax := log bηmax κA log 1 1−(ST) −0.3 , and let UΘ,A ={u θ,α :X→Z|(θ, α)∈Θ×A}. LetL=|{i:ℓ i >−∞}|,U=|{i:u i <∞}|, andm:=m 1 +m 2, and define Kfull θ,α :=ST Bmax(L+U+m 1 + 3) + 7 + 2S. Then there exist parametersq, M,∆, k F...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.