Rank Intervals for Leaderboards: A Hierarchical Framework for Model Evaluation
Pith reviewed 2026-06-27 17:53 UTC · model grok-4.3
The pith
A hierarchical framework yields statistically valid rank intervals for models on multi-task leaderboards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
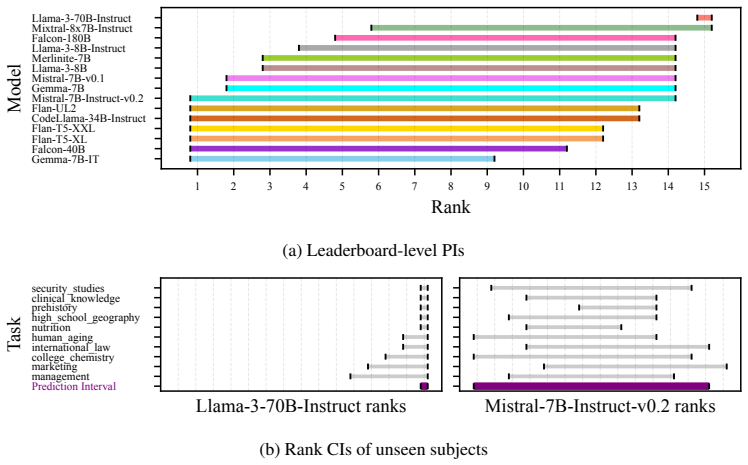
The paper establishes a hierarchical framework that first derives task-level rank confidence intervals through pairwise comparisons of model performances, then applies a conformal prediction procedure to these intervals to obtain leaderboard-level rank prediction intervals that maintain statistical validity for both observed tasks and new tasks.
What carries the argument
The hierarchical framework that combines pairwise-comparison task-level rank intervals with conformal prediction for leaderboard-level intervals.
If this is right
- Task-level intervals quantify rank uncertainty for each observed task with statistical guarantees.
- Leaderboard intervals provide coverage for aggregate ranks while incorporating cross-task variability.
- The same procedure supplies prediction intervals usable on new tasks not seen during evaluation.
- Experiments confirm validity and informativeness on simulated data plus TabArena and PromptEval benchmarks.
Where Pith is reading between the lines
- Leaderboards could display intervals rather than single ranks, altering how model superiority is communicated.
- The method could extend to other multi-task evaluation settings where variability across domains matters.
- Interval width might serve as a signal for selecting which additional tasks to evaluate next.
Load-bearing premise
The conformal prediction step applied to aggregated task-level rank intervals produces valid prediction intervals for leaderboard ranks on both observed and new tasks.
What would settle it
An experiment on held-out tasks where the constructed leaderboard rank intervals contain the true ranks at a rate below the nominal coverage level, such as below 90 percent for nominal 90 percent intervals.
Figures

read the original abstract
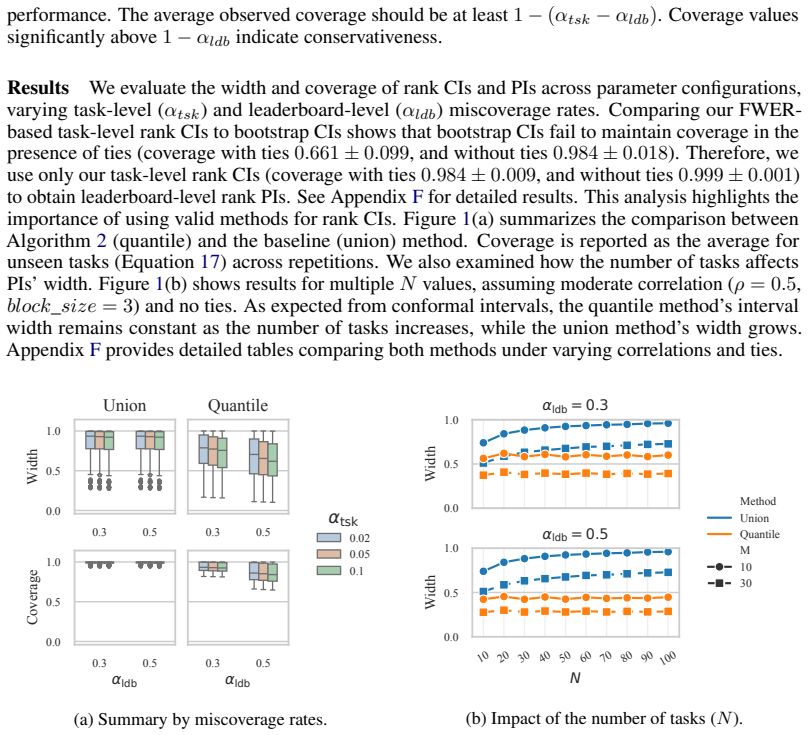
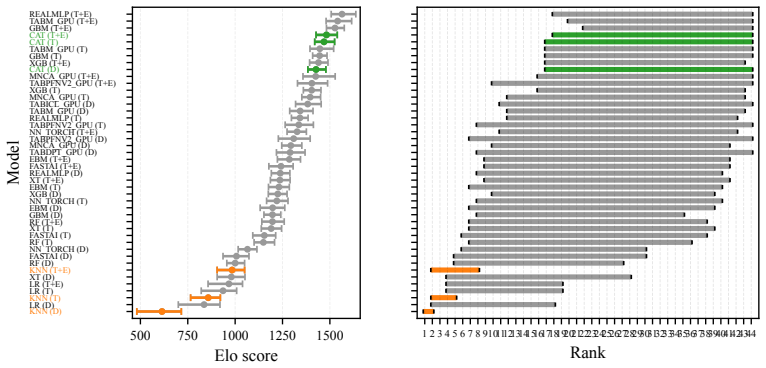
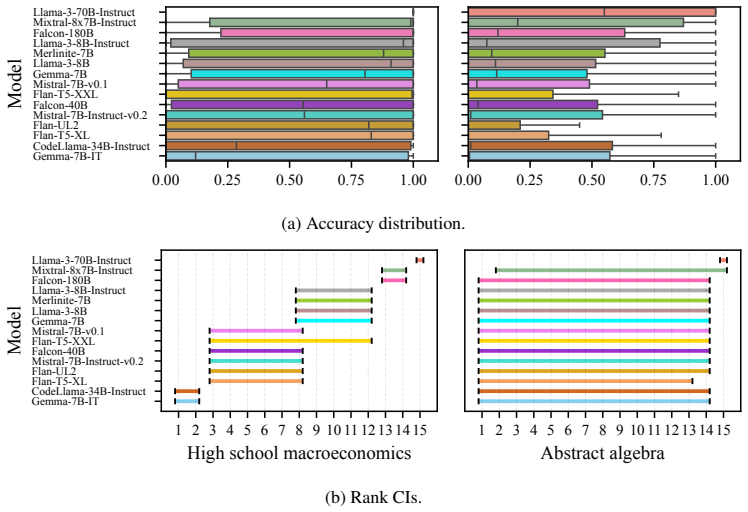
Pretrained models are often evaluated on multi-task leaderboards to measure their applicability in diverse contexts. However, current methods for aggregating performance across tasks into leaderboard-level rankings do not address the uncertainty and variability at the task level. While recent works have proposed interval-based model rankings, the principled aggregation of uncertainty from individual tasks to leaderboard-level rankings remains unaddressed, and variation in models' performance across tasks is frequently obscured. In this work, we introduce a hierarchical framework that constructs model rank intervals with statistical guarantees at both levels: task-level rank confidence intervals from pairwise comparisons, and leaderboard-level rank prediction intervals using a conformal approach. This enables reliable quantification of model rank for each observed task and for new potential tasks. Experiments on simulated data and the TabArena and PromptEval (MMLU) benchmarks show that our method yields statistically valid and informative intervals, enabling reliable, uncertainty-aware model ranking on leaderboards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a hierarchical framework for model evaluation on multi-task leaderboards. Task-level rank confidence intervals are constructed from pairwise comparisons with statistical guarantees, while leaderboard-level rank prediction intervals are obtained via a conformal prediction procedure applied to the aggregated task-level results. This is intended to enable uncertainty-aware rankings for both observed tasks and new tasks. Experiments on simulated data, TabArena, and PromptEval (MMLU) are reported to demonstrate validity and informativeness of the intervals.
Significance. If the coverage guarantees hold, the work would provide a principled way to quantify uncertainty in leaderboard rankings, addressing the lack of task-level variability in current aggregation methods. The hierarchical use of conformal prediction for rank intervals could be a useful addition to the model evaluation toolkit, particularly if the approach yields non-vacuous intervals on real benchmarks.
major comments (2)
- [Conformal prediction procedure for leaderboard ranks (likely §4 or §5)] The central claim for new-task leaderboard ranks requires that the conformal procedure, applied after aggregating task-level intervals, produces valid prediction intervals. This rests on exchangeability (or i.i.d.) between the observed tasks used for calibration and any new tasks. The manuscript does not establish this for heterogeneous benchmarks (e.g., MMLU vs. TabArena) nor provide a robustness argument or sensitivity analysis when task difficulty or domain distributions differ; without this, the guarantees for unseen tasks are not supported.
- [Hierarchical framework description and conformal aggregation step] It is unclear how the conformalization step preserves coverage after the hierarchical aggregation of pairwise rank intervals. If the task-level intervals are themselves random and the aggregation introduces dependence, the standard conformal validity argument may not apply directly to the final leaderboard ranks.
minor comments (2)
- [Abstract and §1] The abstract and introduction should more explicitly distinguish confidence intervals (task level) from prediction intervals (leaderboard level) to avoid reader confusion.
- [Method sections] Include a clear statement of all assumptions (including exchangeability) in the main text rather than only in supplementary material.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We respond point by point to the major concerns, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: The central claim for new-task leaderboard ranks requires that the conformal procedure, applied after aggregating task-level intervals, produces valid prediction intervals. This rests on exchangeability (or i.i.d.) between the observed tasks used for calibration and any new tasks. The manuscript does not establish this for heterogeneous benchmarks (e.g., MMLU vs. TabArena) nor provide a robustness argument or sensitivity analysis when task difficulty or domain distributions differ; without this, the guarantees for unseen tasks are not supported.
Authors: We agree the exchangeability assumption is central and not explicitly justified for heterogeneous benchmarks. The framework assumes new tasks are exchangeable with calibration tasks drawn from the same benchmark distribution; cross-benchmark use (MMLU to TabArena) would require separate calibration sets. In revision we will add an explicit statement of this assumption together with a sensitivity analysis demonstrating empirical coverage under controlled shifts in task difficulty and domain. revision: yes
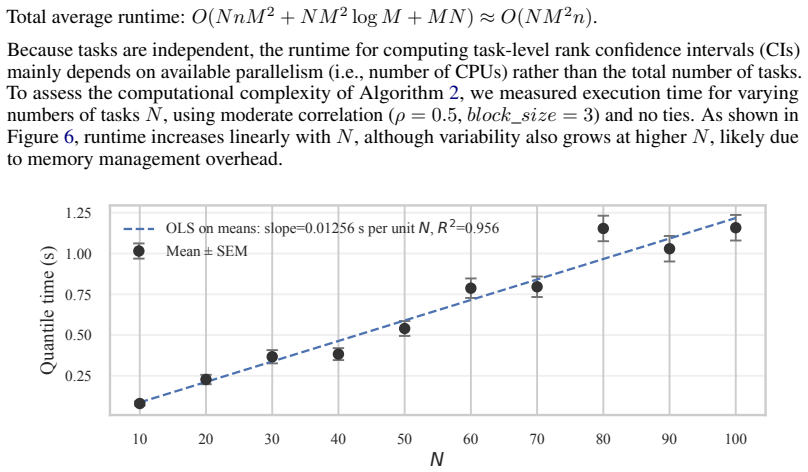
-
Referee: It is unclear how the conformalization step preserves coverage after the hierarchical aggregation of pairwise rank intervals. If the task-level intervals are themselves random and the aggregation introduces dependence, the standard conformal validity argument may not apply directly to the final leaderboard ranks.
Authors: The conformal scores are computed on the final leaderboard-level rank statistics obtained after aggregation; the standard conformal guarantee applies to the exchangeable sequence of these aggregated scores. Dependence induced by the task-level intervals is internal to each score and does not violate the marginal coverage result provided the calibration and test instances remain exchangeable. We will revise §4 to include a concise proof sketch clarifying this point. revision: partial
Circularity Check
No significant circularity; derivation applies standard external methods
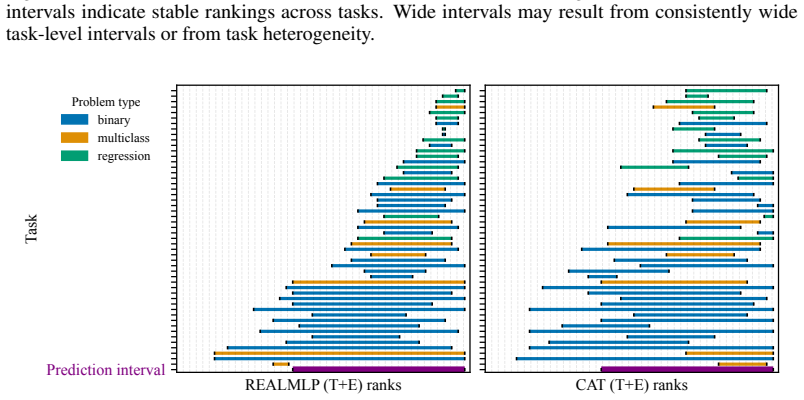
full rationale
The paper constructs task-level rank intervals via pairwise comparisons and then applies a conformal prediction procedure for leaderboard-level intervals. No quoted step reduces a claimed prediction or guarantee to a fitted parameter or self-citation by construction. Conformal prediction is invoked as a known technique whose validity properties are external to the paper; the hierarchical aggregation does not rename or smuggle in its own inputs. The framework is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
From Forecasting Leaderboards to Deployment Decisions: A Fail-Closed Certification Protocol
Presents a fail-closed certification protocol for determining when forecasting leaderboard winners are deployment-actionable, using a traffic dataset to show friction-induced reversals and an audit to prevent overclaiming.
Reference graph
Works this paper leans on
-
[1]
Samuel Ackerman, Eitan Farchi, Orna Raz, and Assaf Toledo. Statistical multi-metric evaluation and visualization of llm system predictive performance.arXiv preprint arXiv:2501.18243, 2025
arXiv 2025
-
[2]
Diaa Al Mohamad, Erik van Zwet, Aldo Solari, and Jelle Goeman. Simultaneous confidence intervals for ranks using the partitioning principle.Electronic Journal of Statistics, 15(1): 3109–3134, 2021. doi: 10.1214/21-EJS1847
-
[3]
Simultaneous confidence intervals for ranks with application to ranking institutions.Biometrics, 78(1):238–247, 2022
Diaa Al Mohamad, Jelle J Goeman, and Erik W van Zwet. Simultaneous confidence intervals for ranks with application to ranking institutions.Biometrics, 78(1):238–247, 2022
2022
-
[4]
A statistical framework for ranking llm-based chatbots.arXiv preprint arXiv:2412.18407, 2024
Siavash Ameli, Siyuan Zhuang, Ion Stoica, and Michael W Mahoney. A statistical framework for ranking llm-based chatbots.arXiv preprint arXiv:2412.18407, 2024
arXiv 2024
-
[5]
Split-sample strategies for avoiding false discoveries
Michael L Anderson and Jeremy Magruder. Split-sample strategies for avoiding false discoveries. Technical report, National Bureau of Economic Research, 2017
2017
-
[6]
Prompt-dependent ranking of large language models with uncertainty quantification.arXiv e-prints, pages arXiv–2603, 2026
Angel Rodrigo Avelar Menendez, Yufeng Liu, and Xiaowu Dai. Prompt-dependent ranking of large language models with uncertainty quantification.arXiv e-prints, pages arXiv–2603, 2026
2026
-
[7]
False discovery rate–adjusted multiple confidence intervals for selected parameters.Journal of the American Statistical Association, 100(469): 71–81, 2005
Yoav Benjamini and Daniel Yekutieli. False discovery rate–adjusted multiple confidence intervals for selected parameters.Journal of the American Statistical Association, 100(469): 71–81, 2005
2005
-
[8]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[9]
Towards robust comparisons of nlp models: A case study
Vicente Ivan Sanchez Carmona, Shanshan Jiang, and Bin Dong. Towards robust comparisons of nlp models: A case study. InProceedings of the 31st International Conference on Computational Linguistics, pages 4973–4979, 2025
2025
-
[10]
Onrina Chandra and Min-ge Xie. Finite-sample valid rank confidence sets for a broad class of statistical and machine learning models.arXiv preprint arXiv:2512.00316, 2025
arXiv 2025
-
[11]
Denis Chetverikov, Magne Mogstad, Pawel Morgen, Joseph Romano, Azeem Shaikh, and Daniel Wilhelm. csranks: an r package for estimation and inference involving ranks.arXiv preprint arXiv:2401.15205, 2024
arXiv 2024
-
[12]
Chatbot arena: An open platform for evaluating llms by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning, 2024
2024
-
[13]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
2006
-
[14]
Replicability analysis for natural language processing: Testing significance with multiple datasets.Transactions of the Association for Computational Linguistics, 5:471–486, 2017
Rotem Dror, Gili Baumer, Marina Bogomolov, and Roi Reichart. Replicability analysis for natural language processing: Testing significance with multiple datasets.Transactions of the Association for Computational Linguistics, 5:471–486, 2017. URL https://aclanthology. org/Q17-1034
2017
-
[15]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, Frank Hutter, et al. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791, 2025
Pith/arXiv arXiv 2025
-
[16]
Ranking the scores of algorithms with confidence
Adrien Foucart, Arthur Elskens, and Christine Decaestecker. Ranking the scores of algorithms with confidence. InESANN 2025 proceedings, pages 431–436, 2025. 10
2025
-
[17]
Open llm leaderboard v2
Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open llm leaderboard v2. https://huggingface.co/spaces/open-llm-leaderboard/open_ llm_leaderboard, 2024
2024
-
[18]
Prompt-to-leaderboard: Prompt-adaptive llm evaluations
Evan Frick, Connor Chen, Joseph Tennyson, Tianle Li, Wei-Lin Chiang, Anastasios Nikolas Angelopoulos, and Ion Stoica. Prompt-to-leaderboard: Prompt-adaptive llm evaluations. In Forty-second International Conference on Machine Learning, 2025
2025
-
[19]
Merging uncertainty sets via majority vote.arXiv preprint arXiv:2401.09379, 2024
Matteo Gasparin and Aaditya Ramdas. Merging uncertainty sets via majority vote.arXiv preprint arXiv:2401.09379, 2024
arXiv 2024
-
[20]
Lmems for post-hoc analysis of hpo benchmarking.arXiv preprint arXiv:2408.02533, 2024
Anton Geburek, Neeratyoy Mallik, Danny Stoll, Xavier Bouthillier, and Frank Hutter. Lmems for post-hoc analysis of hpo benchmarking.arXiv preprint arXiv:2408.02533, 2024
arXiv 2024
-
[21]
David Heineman, Valentin Hofmann, Ian Magnusson, Yuling Gu, Noah A Smith, Hannaneh Hajishirzi, Kyle Lo, and Jesse Dodge. Signal and noise: A framework for reducing uncertainty in language model evaluation.arXiv preprint arXiv:2508.13144, 2025
arXiv 2025
-
[22]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[23]
Confidence intervals for ranks
Sture Holm. Confidence intervals for ranks. Technical report, Uppsala University, 2013
2013
-
[24]
Minji Jung, Minjae Lee, Yejin Kim, Sarang Choi, and Minsuk Kahng. Who defines" best"? to- wards interactive, user-defined evaluation of llm leaderboards.arXiv preprint arXiv:2604.21769, 2026
Pith/arXiv arXiv 2026
-
[25]
Distribution-free predictive inference for regression.Journal of the American Statistical Associ- ation, 113(523):1094–1111, 2018
Jing Lei, Max G’Sell, Alessandro Rinaldo, Ryan J Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression.Journal of the American Statistical Associ- ation, 113(523):1094–1111, 2018
2018
-
[26]
Prediction sets and conformal inference with interval outcomes.arXiv preprint arXiv:2501.10117, 2025
Weiguang Liu, Áureo de Paula, and Elie Tamer. Prediction sets and conformal inference with interval outcomes.arXiv preprint arXiv:2501.10117, 2025. URL https://arxiv.org/abs/ 2501.10117
arXiv 2025
-
[27]
Rachel Longjohn, Giri Gopalan, and Emily Casleton. Statistical uncertainty quantification for ag- gregate performance metrics in machine learning benchmarks.arXiv preprint arXiv:2501.04234, 2025
arXiv 2025
-
[28]
Adding error bars to evals: A statistical approach to language model evaluations
Evan Miller. Adding error bars to evals: A statistical approach to language model evaluations. arXiv preprint arXiv:2411.00640, 2024
arXiv 2024
-
[29]
How robust are model rankings: A leaderboard customization approach for equitable evaluation
Swaroop Mishra and Anjana Arunkumar. How robust are model rankings: A leaderboard customization approach for equitable evaluation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13561–13569, 2021
2021
-
[30]
Efficient multi-prompt evaluation of llms.Advances in Neural Information Processing Systems, 37:22483–22512, 2024
Felipe M Polo, Ronald Xu, Lucas Weber, Mírian Silva, Onkar Bhardwaj, Leshem Choshen, Allysson F de Oliveira, Yuekai Sun, and Mikhail Yurochkin. Efficient multi-prompt evaluation of llms.Advances in Neural Information Processing Systems, 37:22483–22512, 2024
2024
-
[31]
The robustness of the one-sample t-test over the pearson system.Journal of Statistical Computation and Simulation, 9(2):133–149, 1979
Harry O Posten. The robustness of the one-sample t-test over the pearson system.Journal of Statistical Computation and Simulation, 9(2):133–149, 1979
1979
-
[32]
Uncertainty in ranking.arXiv preprint arXiv:2107.03459, 2021
Justin Rising. Uncertainty in ranking.arXiv preprint arXiv:2107.03459, 2021
arXiv 2021
-
[33]
Arena-lite: Efficient and reliable large language model evaluation via tournament-based direct comparisons
Seonil Son, Ju-Min Oh, Heegon Jin, Cheolhun Jang, Jeongbeom Jeong, and Kuntae Kim. Arena-lite: Efficient and reliable large language model evaluation via tournament-based direct comparisons. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7068–7086, 2025
2025
-
[34]
Evaluating passenger segment sensitivity and reliability in airline satisfaction ai systems
Miloš Stojanovic and Milena Nikolic. Evaluating passenger segment sensitivity and reliability in airline satisfaction ai systems. In2026 XXV International Symposium INFOTEH-JAHORINA (INFOTEH), Jahorina, Bosnia and Herzegovina, March 2026. URL https://infoteh.etf. ues.rs.ba/zbornik/2026/radovi/343.pdf. 11
2026
-
[35]
Ranking with confidence for large scale comparison data
Filipa Valdeira and Cláudia Soares. Ranking with confidence for large scale comparison data. InProceedings of the 2025 SIAM International Conference on Data Mining (SDM), pages 223–232. SIAM, 2025
2025
-
[36]
Springer, 2005
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, 2005
2005
-
[37]
Zebin Wang, Yi Han, Ethan X Fang, Lan Wang, and Junwei Lu. Confidence diagram of nonparametric ranking for uncertainty assessment in large language models evaluation.arXiv preprint arXiv:2412.05506, 2024
arXiv 2024
-
[38]
Academic press, 2011
Rand R Wilcox.Introduction to robust estimation and hypothesis testing. Academic press, 2011
2011
-
[39]
Comparing two dependent groups
Rand R Wilcox. Comparing two dependent groups. InA Guide to Robust Statistical Methods, pages 83–96. Springer, 2023. 12 A Ranking implementation Details A.1 Task-level rank CIs Here we provide more details regarding our method for constructing task-level rank CIs, as well as a discussion of alternative choices. Statistical testsThroughout this paper, we u...
2023
-
[40]
Across all tasks, this requiresO(N nM 2)
P-Value Computation: Computing pairwise paired t-tests for all model combinations on a single task takesO(nM 2). Across all tasks, this requiresO(N nM 2)
-
[41]
Across all tasks, this step requiresO(N M 2 logM)
Task-level rank CIs(Algorithm 1): For marginal rank CIs, applying the step-down FWER control requires sorting M−1 p-values for each of the M models, yielding O(M 2 logM) per task. Across all tasks, this step requiresO(N M 2 logM)
-
[42]
rank spread
Leaderboard-level rank PIs(Algorithm 2): A straightforward approach would require sorting the per-task bounds, with a runtime ofO(M NlogN) . However, our implementation leverages optimized selection algorithms (via NumPy and Pandas) for quantile identification, avoiding full sorting and reducing the average runtime toO(M N). 13 Total average runtime:O(N n...
2025
-
[43]
It covers the true rankr ∗ j with high probabilityP r∗ j ⊆[L ∗ j , U ∗ j ] ≥1−α tsk
-
[44]
,[LN j , U N j ] because all inter- vals are derived from the same estimation method applied to independent and identically distributed tasks
It is exchangeable with the task-level rank CIs [L1 j , U1 j ], . . . ,[LN j , U N j ] because all inter- vals are derived from the same estimation method applied to independent and identically distributed tasks. Due to property (1), it suffices to show that P [L∗ j , U ∗ j ]⊆[L j, Uj] ≥1−α ldb. By applying the union bound, we then obtain the desired cove...
-
[45]
Selecting a subset of tasks based on domain knowledge, which can be done at any stage without affecting the validity of the task-level rank CIs
-
[46]
Filtering tasks whose rank intervals exceed a predefined width threshold
-
[47]
In Section 4.2, Figure 3, we show that some models are better on regression tasks, while other outperform on multiclass classification
Grouping similar tasks, such as clustering them by their top-k models, and then computing task-level CIs for each cluster. In Section 4.2, Figure 3, we show that some models are better on regression tasks, while other outperform on multiclass classification. While comparing all models across all datasets is occasionally of interest, practitioners often fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.