APEX4: Efficient Pure W4A4 LLM Inference via Intra-SM Compute Rebalancing
Pith reviewed 2026-06-30 11:05 UTC · model grok-4.3
The pith
APEX4 shows that W4A4 LLM inference speed depends on matching dequantization work to each GPU's Tensor Core versus CUDA Core throughput ratio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
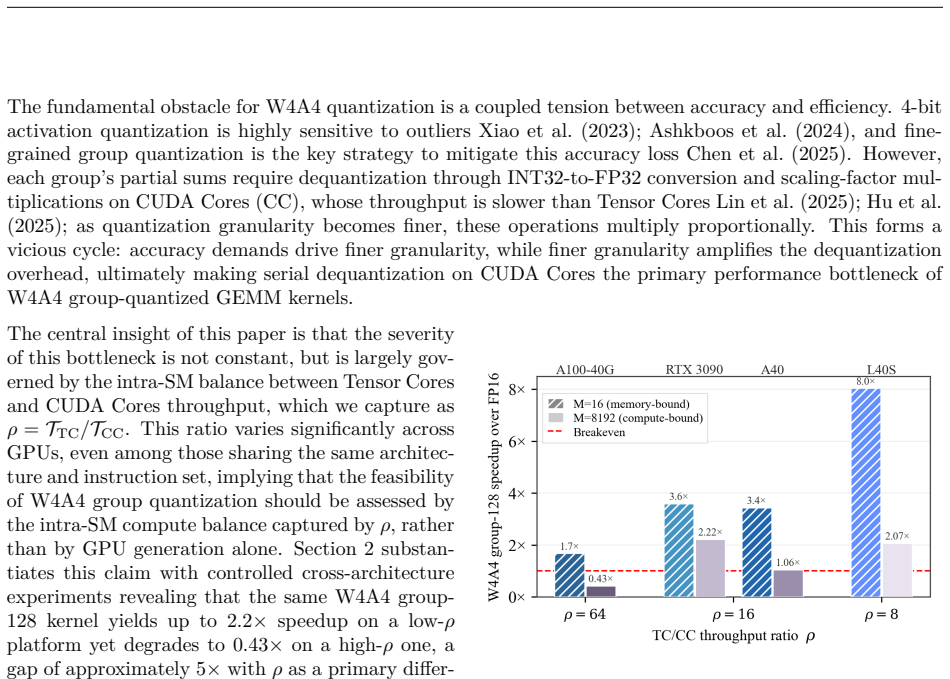
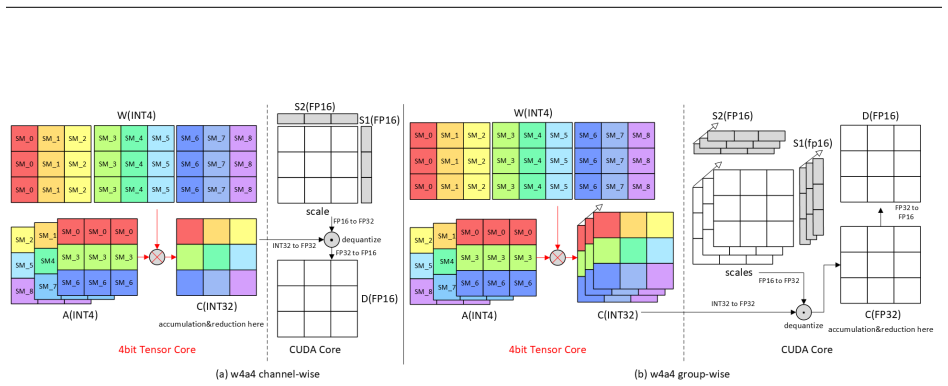
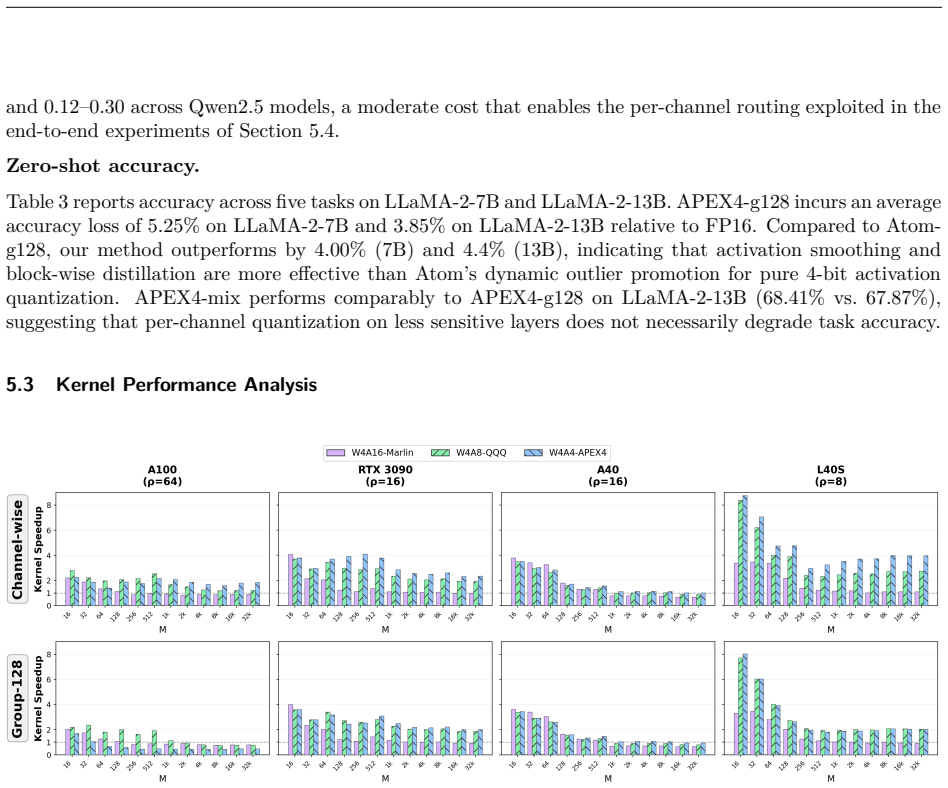
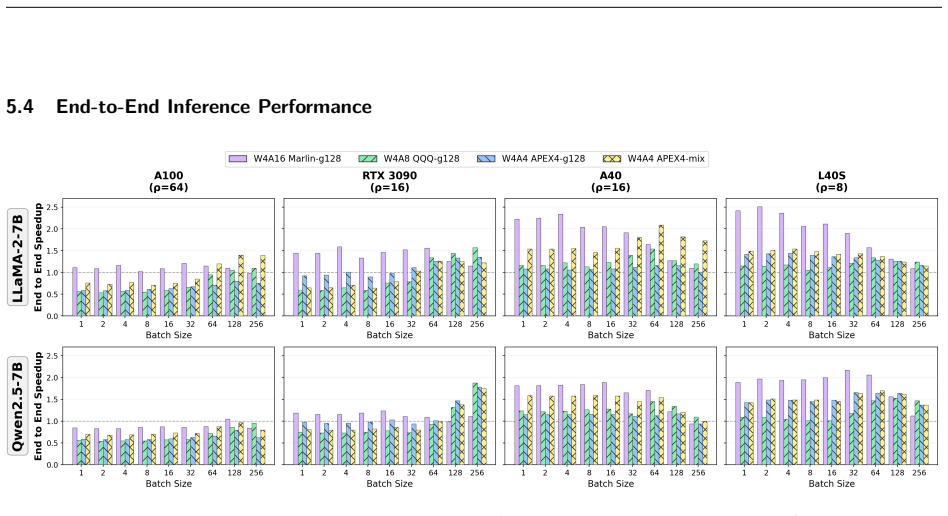
The central claim is that the Tensor Cores to CUDA Cores throughput ratio ρ governs W4A4 kernel behavior: the same g128 kernel yields 2.0–2.5× speedup on RTX 3090 (ρ=16) yet only 0.43–0.47× on A100 (ρ=64) in compute-bound cases. Guided by this platform dependence, APEX4 co-designs pure INT4 GEMM kernels with ρ-aware granularity adaptation that removes the dequantization bottleneck, delivering perplexity within 0.63 of FP16 on LLaMA-2-70B, 4.0–4.4% higher zero-shot accuracy than W4Ax Atom-g128, and measured end-to-end speedups of 1.66× on L40S, 1.78× on RTX 3090, 2.09× on A40, and 1.20–1.40× on A100 via mixed mode.
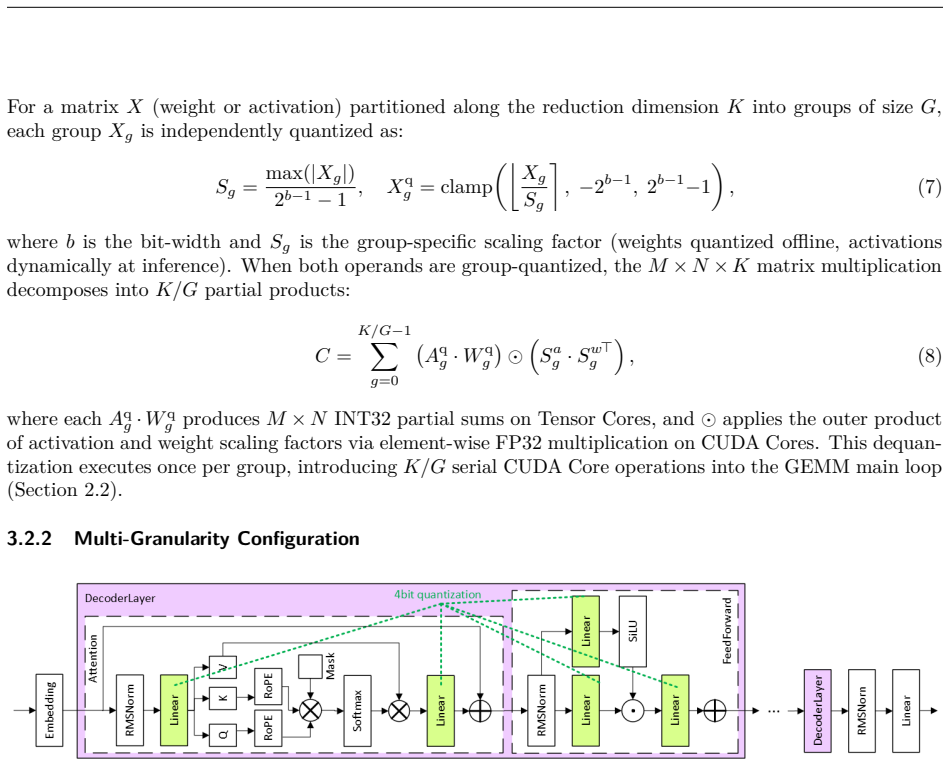
What carries the argument
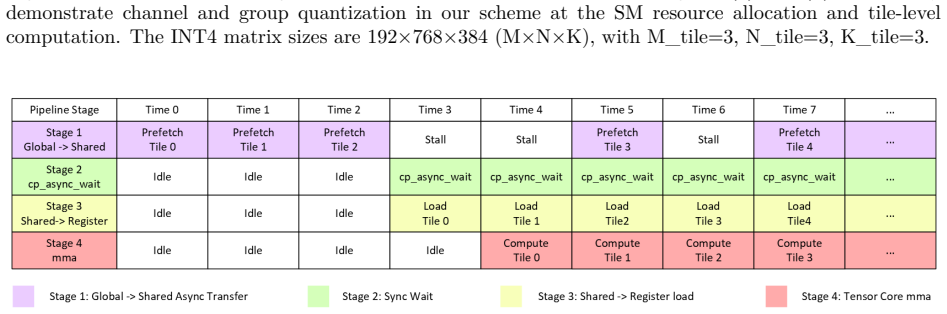
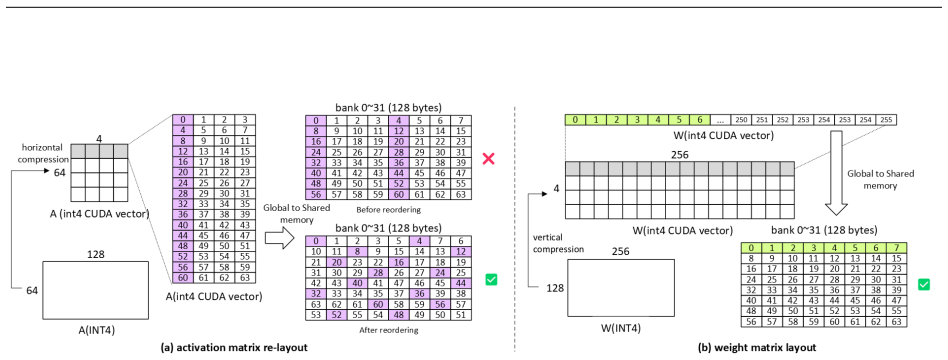
ρ-aware granularity adaptation that rebalances intra-SM work between Tensor Core matrix multiplies and CUDA Core dequantization in pure INT4 GEMM kernels
If this is right
- Pure W4A4 inference becomes viable without mixed-precision fallbacks once granularity is chosen to match a GPU's ρ value.
- Unmodified vLLM deployments obtain up to 2.09× end-to-end latency reduction on GPUs whose ρ lies near 16.
- A mixed-granularity mode recovers 1.20–1.40× speedup on high-ρ platforms such as A100 while still using mostly INT4 arithmetic.
- Quantization kernel design should treat the Tensor-to-CUDA core throughput ratio as a first-class tuning parameter rather than assuming uniform hardware behavior.
Where Pith is reading between the lines
- Future GPU architectures could reduce the need for such adaptation by shipping more balanced Tensor Core and CUDA Core throughputs.
- The same rebalancing logic could be applied to other low-precision formats or to accelerators whose matrix and scalar units have mismatched speeds.
- Platform-specific granularity tables may become a standard part of LLM serving stacks as more quantized kernels are deployed across heterogeneous hardware.
Load-bearing premise
The throughput ratio between Tensor Cores and CUDA Cores is the dominant hardware factor that decides whether dequantization overhead prevents pure W4A4 kernels from being faster than mixed-precision baselines.
What would settle it
A controlled benchmark on a new GPU architecture in which measured ρ fails to predict the observed W4A4 kernel speedup or slowdown relative to mixed-precision baselines would falsify the claim.
Figures

read the original abstract
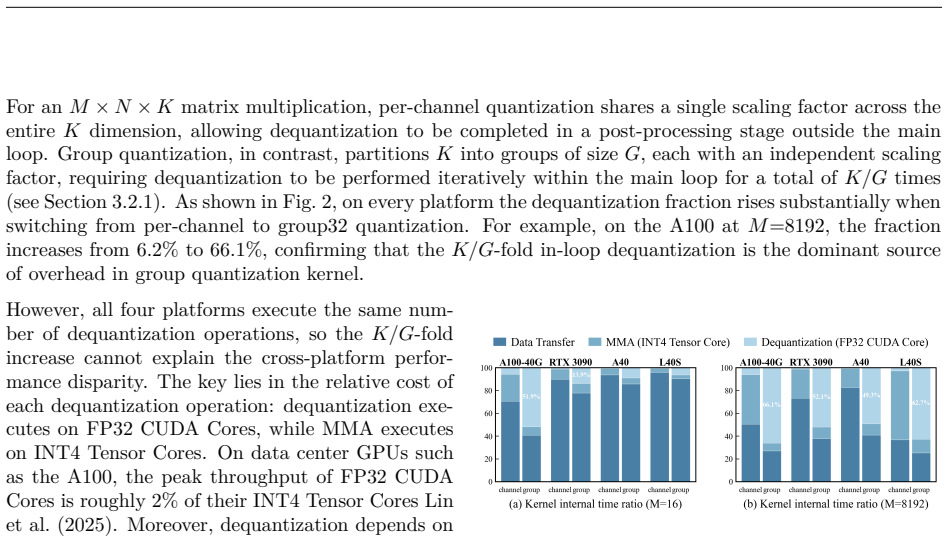
W4A4 quantization promises full utilization of INT4 Tensor Cores, yet group dequantization overhead on CUDA Cores has driven existing systems to mixed-precision fallbacks. We present the first systematic study of how intra-SM compute balance governs this bottleneck. Through controlled benchmarks across four GPUs from Ampere and Ada architectures, we identify the Tensor Cores to CUDA Cores throughput ratio ($\rho$) as the primary hardware indicator: the W4A4-g128 kernel yields $2.0$--$2.5\times$ speedup on RTX~3090 ($\rho=16$) yet degrades to $0.43$--$0.47\times$ on A100 ($\rho=64$) in compute-bond scenarios, establishing W4A4 viability as platform-dependent rather than universally infeasible. Guided by this finding, we build \textbf{APEX4}, which co-designs pure INT4 GEMM kernels with $\rho$-aware granularity adaptation to mitigate the CUDA Cores dequantization bottleneck. APEX4 achieves perplexity within 0.63 of FP16 on LLaMA-2-70B and outperforms W4Ax Atom-g128 by 4.0\%--4.4\% in zero-shot accuracy. Deployed as a drop-in replacement in unmodified vLLM, it delivers up to $1.66\times$ end-to-end speedup on L40S ($\rho=8$), and $1.78\times$ on RTX~3090 ($\rho=16$), $2.09\times$ on A40 ($\rho=16$), while recovering A100 ($\rho=64$) to $1.20$--$1.40\times$ via the mixed-granularity mode. Our code is available at https://github.com/APEX4-W4A4/APEX4-W4A4.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the Tensor Cores to CUDA Cores throughput ratio ρ is the primary hardware parameter governing the W4A4 dequantization bottleneck on CUDA Cores. Through controlled benchmarks on four Ampere/Ada GPUs, the authors show that pure W4A4-g128 kernels deliver 2.0–2.5× speedup on low-ρ platforms (e.g., RTX 3090, ρ=16) but degrade on high-ρ platforms (A100, ρ=64). They introduce APEX4, which co-designs pure INT4 GEMM kernels with ρ-aware granularity adaptation (g128 and mixed modes) to mitigate the bottleneck. The system achieves perplexity within 0.63 of FP16 on LLaMA-2-70B, 4.0–4.4% higher zero-shot accuracy than W4Ax Atom-g128, and end-to-end speedups up to 2.09× on A40 (ρ=16) and 1.66× on L40S (ρ=8), recovering 1.20–1.40× on A100 via mixed mode. The implementation is released as a drop-in for vLLM with public code.
Significance. If the results hold, the work establishes that pure W4A4 inference is platform-dependent rather than universally infeasible, with ρ providing a concrete, measurable indicator for granularity adaptation. The direct hardware measurements of ρ across architectures (rather than fitted parameters) and the open-source kernels at https://github.com/APEX4-W4A4/APEX4-W4A4 constitute verifiable contributions to systems for quantized LLM inference. The empirical demonstration of accuracy-speedup trade-offs under unmodified vLLM strengthens the practical relevance.
minor comments (2)
- [Abstract] Abstract: the end-to-end speedup claims list specific ρ values and GPUs but omit workload parameters (batch size, sequence length, or model configuration) that produce the peak numbers; adding these would improve reproducibility.
- [Implementation] The description of how the mixed-granularity mode switches between g128 and finer granularity could be expanded with a short pseudocode or decision rule based on measured ρ to clarify the adaptation logic.
Simulated Author's Rebuttal
We thank the referee for the thorough and positive review, which accurately captures the core contributions of APEX4 regarding the role of the Tensor Core to CUDA Core throughput ratio ρ and the resulting platform-dependent viability of pure W4A4 inference. The recommendation for minor revision is appreciated. No specific major comments were listed in the report, so we provide no point-by-point responses below.
Circularity Check
No significant circularity identified
full rationale
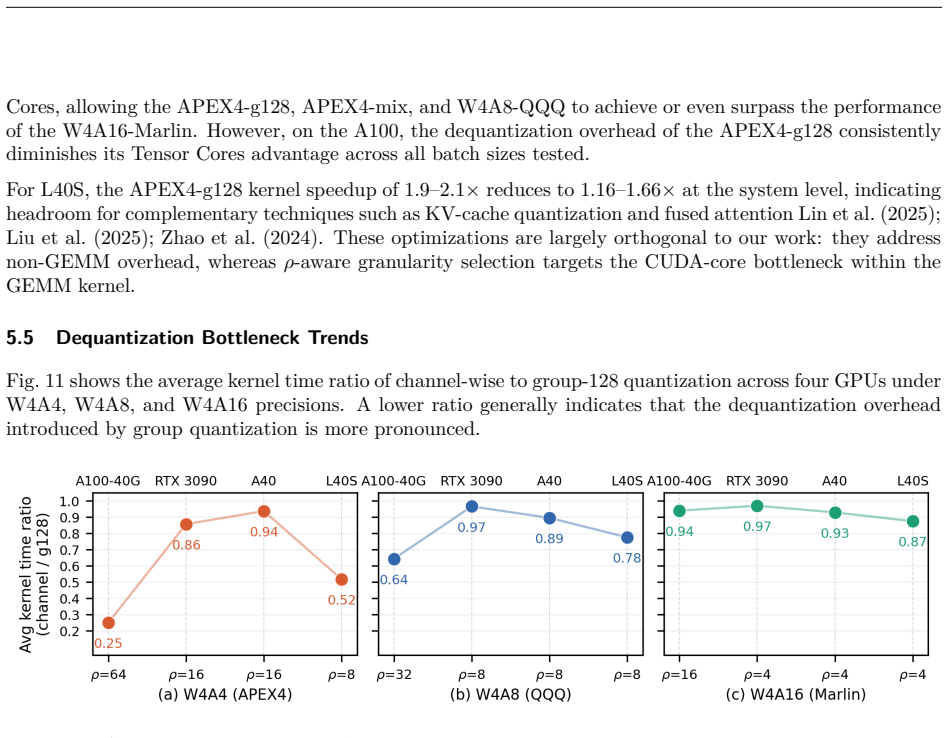
The paper's central results consist of direct hardware measurements of kernel speedups, perplexity, and accuracy on specific GPUs (A40, RTX 3090, A100, L40S) with stated ρ values. The identification of ρ as the governing parameter is presented as an empirical outcome of controlled cross-architecture benchmarks rather than a fitted model or self-referential definition. No equations, predictions, or uniqueness claims reduce by construction to parameters fitted on the same data; the mixed-granularity mode and granularity adaptation are described as engineering responses to the measured platform dependence. The work is therefore self-contained against external benchmarks with no load-bearing self-citation or definitional loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- granularity modes (g128 and mixed)
axioms (1)
- domain assumption Tensor Core to CUDA Core throughput ratio ρ is the dominant factor controlling dequantization overhead in W4A4 kernels
Reference graph
Works this paper leans on
-
[1]
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Wenqi Shao and Mengzhao Chen and Zhaoyang Zhang and Peng Xu and Lirui Zhao and Zhiqian Li and Kaipeng Zhang and Peng Gao and Yu Qiao and Ping Luo , booktitle =
-
[5]
2025 , pages =
Huanqi Hu and Bowen Xiao and Shixuan Sun and Jianian Yin and Zhexi Zhang and Xiang Luo and Chengquan Jiang and Weiqi Xu and Xiaoying Jia and Xin Liu and Minyi Guo , booktitle =. 2025 , pages =
2025
- [6]
-
[7]
Frantar and R
E. Frantar and R. L. Castro and J. Chen and others. Marlin: Mixed-precision auto-regressive parallel inference on large language models. Proceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming
-
[8]
arXiv preprint arXiv:2505.14302 , year=
Scaling law for quantization-aware training , author=. arXiv preprint arXiv:2505.14302 , year=
-
[9]
arXiv preprint arXiv:2406.09904 , year=
Qqq: Quality quattuor-bit quantization for large language models , author=. arXiv preprint arXiv:2406.09904 , year=
-
[10]
Proceedings of Machine Learning and Systems , volume=
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving , author=. Proceedings of Machine Learning and Systems , volume=
-
[11]
Liu and L
L. Liu and L. Cheng and H. Ren and others. COMET: Towards Practical W4A4KV4 LLMs Serving. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems
-
[12]
Zhao and C
Y. Zhao and C. Y. Lin and K. Zhu and others. Atom: Low-bit quantization for efficient and accurate llm serving. Proceedings of Machine Learning and Systems
-
[13]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Gptq: Accurate post-training quantization for generative pre-trained transformers , author=. arXiv preprint arXiv:2210.17323 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lin and J
J. Lin and J. Tang and H. Tang and others. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Proceedings of Machine Learning and Systems
-
[15]
Chee and Y
J. Chee and Y. Cai and V. Kuleshov and others. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems
-
[16]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[17]
2024 IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA) , pages=
Low-bit CUTLASS GEMM Template Auto-tuning using Neural Network , author=. 2024 IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA) , pages=. 2024 , organization=
2024
-
[18]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Language Models are Few-Shot Learners
Language models are few-shot learners , author=. arXiv preprint arXiv:2005.14165 , volume=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[21]
int8 (): 8-bit matrix multiplication for transformers at scale , author=
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale , author=. Advances in neural information processing systems , volume=
-
[22]
Advances in Neural Information Processing Systems , volume=
Quarot: Outlier-free 4-bit inference in rotated llms , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Turboquant: Online vector quantization with near-optimal distortion rate , author=. arXiv preprint arXiv:2504.19874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International conference on machine learning , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[25]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[28]
Pointer Sentinel Mixture Models
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[30]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[32]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[33]
2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS) , pages=
Benchmarking and dissecting the nvidia hopper gpu architecture , author=. 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS) , pages=. 2024 , organization=
2024
-
[34]
2025 , howpublished =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.