Beyond Pass Rate: A Multilingual, Execution-Grounded Evaluation of Open Code LLMs
Pith reviewed 2026-06-27 18:17 UTC · model grok-4.3
The pith
Open code LLMs reach only 23.64 percent mean correctness on LeetCode tasks across 12 languages, well below the 57.2 percent human acceptance baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
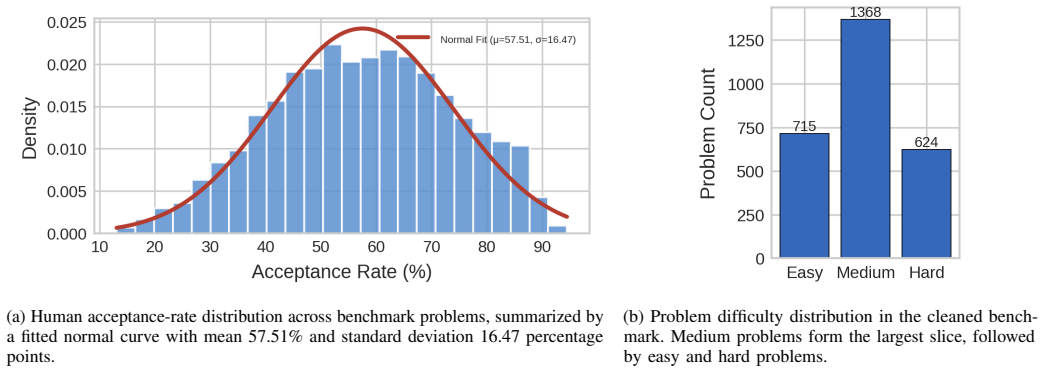
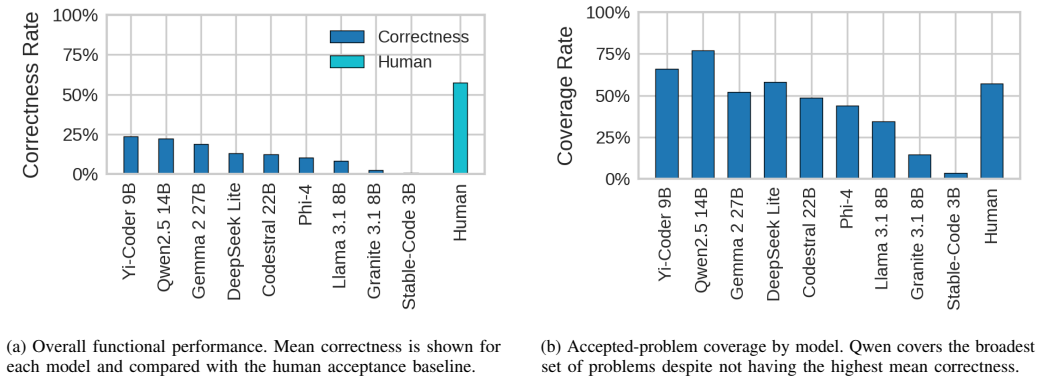
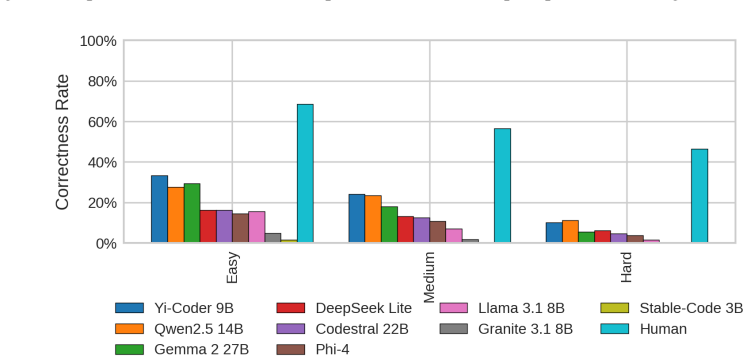
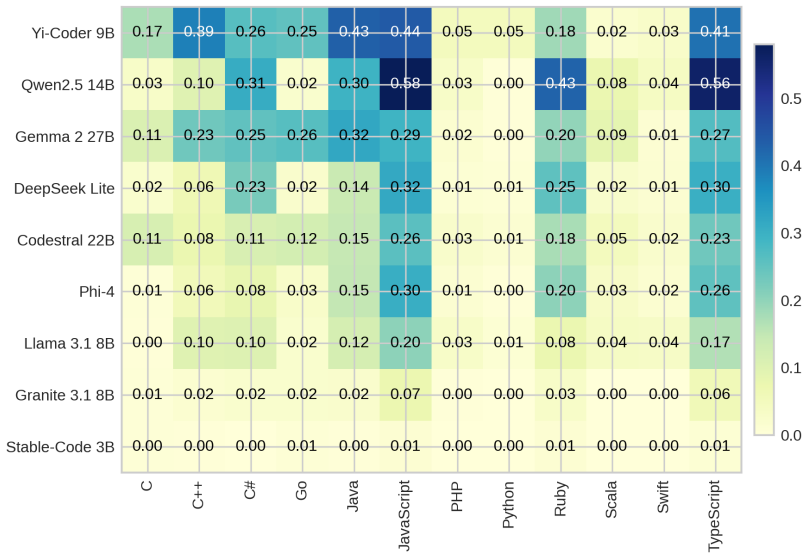
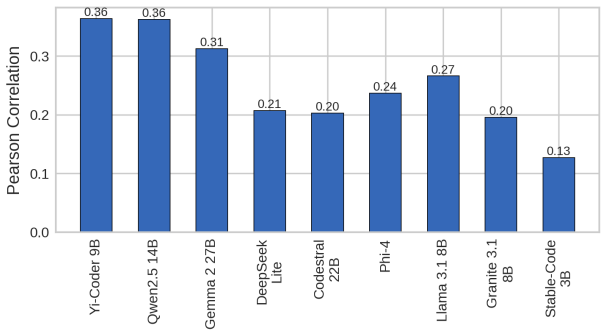
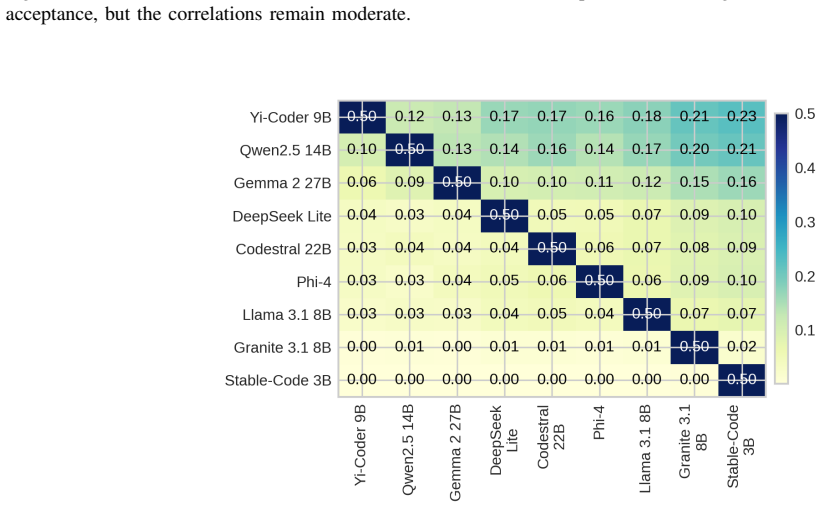
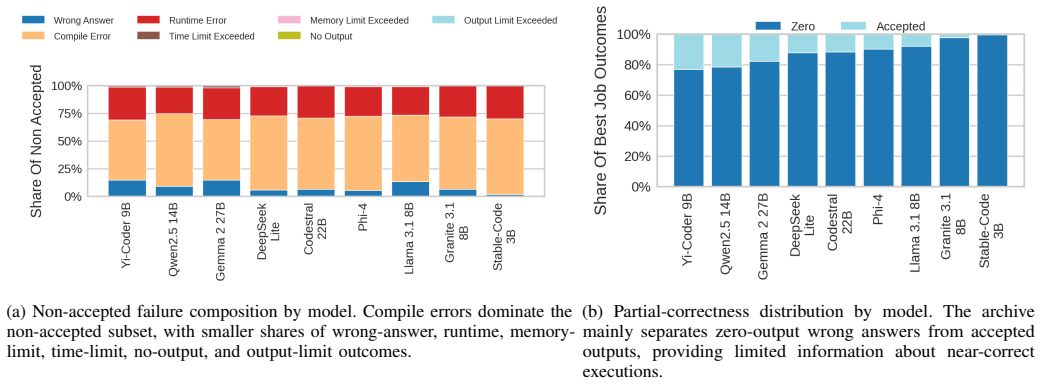
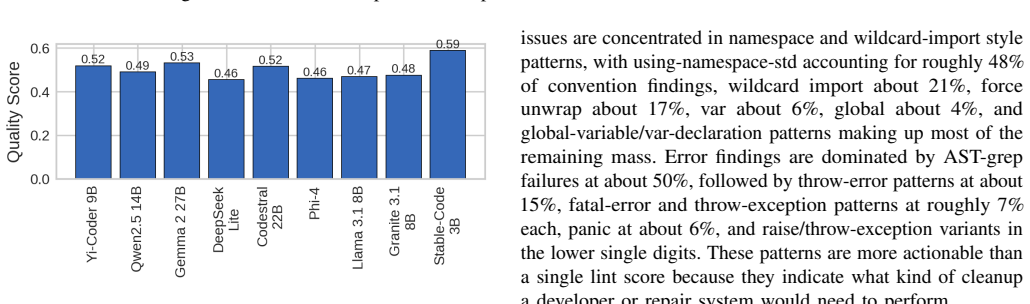
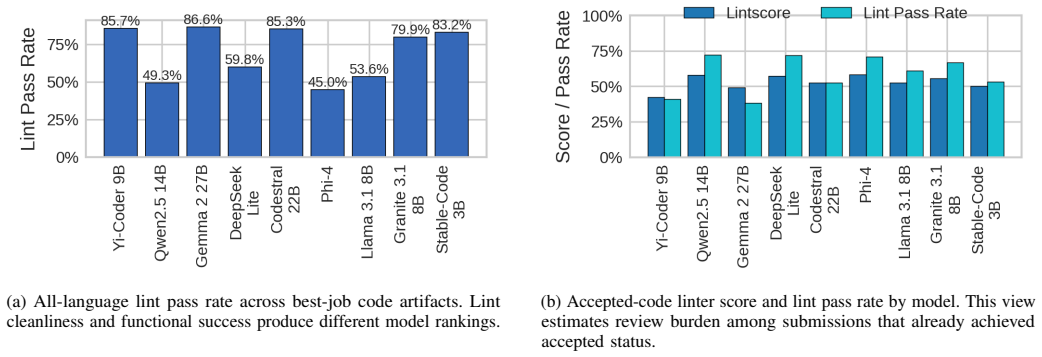
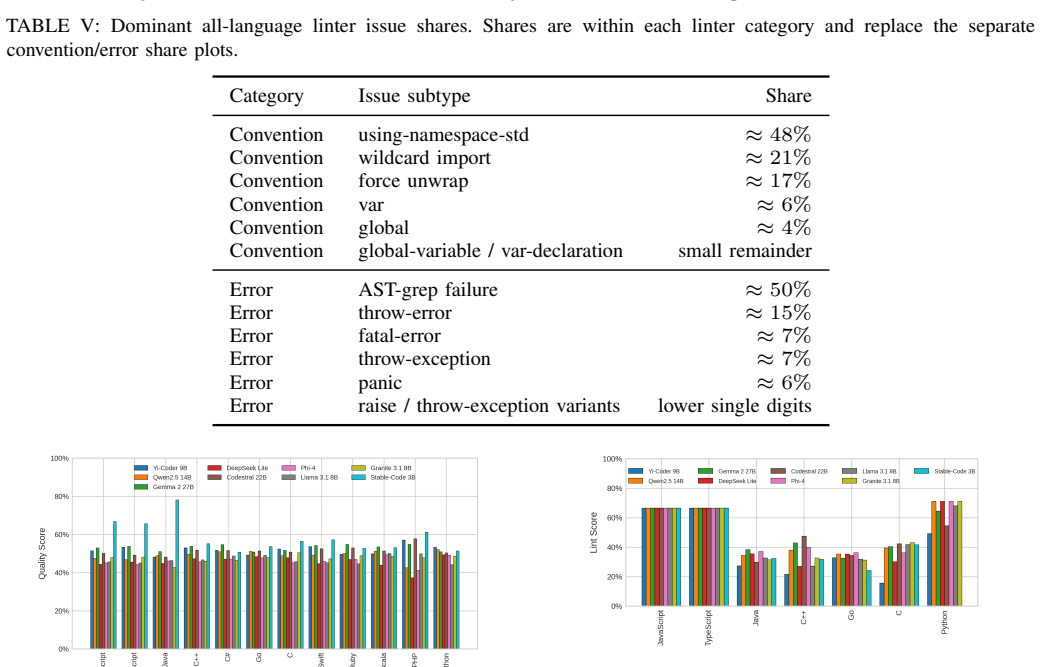
Current open models remain far from the human acceptance reference: the best model, Yi-Coder-9B-Chat, reaches 23.64% mean correctness, compared with a 57.2% human acceptance baseline. Rankings are also slice-dependent: Qwen2.5-Coder-14B-Instruct is strongest on hard problems and distinct-problem coverage, while Gemma-2-27B-IT achieves the highest all-language lint pass rate. Failure analysis shows that compile errors account for 63.25% of non-accepted best submissions, indicating that many failures occur before semantic correctness can be tested. Static quality further diverges from functional correctness.
What carries the argument
Multilingual execution-grounded evaluation corpus of 325,343 problem-model-language jobs that preserves prompts, extracted code, LeetCode execution outcomes, and static-analysis signals across 2,707 problems in 12 languages.
If this is right
- Model selection for a given language or difficulty level must use slice-specific scores rather than overall aggregates.
- Reducing compile errors is a primary target because they account for the majority of failures before semantic testing occurs.
- Static quality metrics cannot stand in for execution-based functional correctness.
- Future benchmarks should retain full artifacts and enable failure-mode and language slicing.
Where Pith is reading between the lines
- Teams targeting a single language may find a different best model than the overall ranking indicates.
- The size of the human gap points to the value of training or prompting techniques that improve syntax handling across languages.
- Extending the same execution-grounded protocol to non-LeetCode repositories would test whether the compile-error dominance and ranking shifts generalize.
Load-bearing premise
LeetCode problems and their test suites form a representative and unbiased sample of real-world coding tasks across languages, and the human acceptance baseline is measured under comparable conditions.
What would settle it
A re-run on a different collection of coding problems or a human baseline collected with matching constraints that yields model correctness rates near or above 57 percent would falsify the central performance gap claim.
Figures

read the original abstract
Code generation models are typically compared using compact execution benchmarks and aggregate pass rates, but such summaries obscure how performance varies across programming languages, problem families, and failure modes. We present a large-scale, execution-grounded evaluation of 9 openly accessible LLMs specialized for coding on 2,707 free LeetCode problems across 12 programming languages. Our corpus contains 325,343 problem-model-language jobs, each linked to prompt metadata, extracted code, LeetCode execution outcomes, and static-analysis signals. The results show that current open models remain far from the human acceptance reference: the best model, Yi-Coder-9B-Chat, reaches 23.64% mean correctness, compared with a 57.2% human acceptance baseline. Rankings are also slice-dependent: Qwen2.5-Coder-14B-Instruct is strongest on hard problems and distinct-problem coverage, while Gemma-2-27B-IT achieves the highest all-language lint pass rate. Failure analysis shows that compile errors account for 63.25% of non-accepted best submissions, indicating that many failures occur before semantic correctness can be tested. Static quality further diverges from functional correctness. Together, these findings show that multilingual, artifact-preserving evaluation reveals tradeoffs hidden by single-language or single-metric leaderboards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a large-scale, execution-grounded evaluation of nine openly accessible code-specialized LLMs on 2,707 LeetCode problems across 12 languages (325,343 total jobs). It reports that the best model (Yi-Coder-9B-Chat) reaches only 23.64% mean correctness against a 57.2% human acceptance baseline, shows that compile errors dominate failures (63.25%), identifies slice-dependent model rankings (e.g., Qwen2.5-Coder-14B-Instruct strongest on hard problems), and argues that multilingual artifact-preserving evaluation reveals tradeoffs hidden by aggregate pass rates.
Significance. If the human baseline is measured under comparable single-prompt, execution-grounded conditions on the identical problem set, the work would be significant for documenting the remaining gap in open code models, the dominance of early-stage failures, and the value of fine-grained multilingual slicing. The scale of the preserved corpus (prompt metadata, extracted code, execution outcomes, static signals) is a clear strength that supports reproducibility and secondary analyses.
major comments (2)
- [Abstract] Abstract: The central claim that 'current open models remain far from the human acceptance reference' rests on the 23.64% vs. 57.2% gap. The manuscript provides no description of how the human baseline was obtained (single-attempt vs. multiple attempts, prompting format, temperature, or whether it was collected on the exact 2,707 problems under execution-grounded conditions matching the model protocol). Without this, the numerical distance cannot be interpreted as a direct measure of capability shortfall.
- [Abstract] Abstract and evaluation protocol: No information is given on prompt construction, temperature, or sampling strategy used for the 325,343 model jobs. These details are load-bearing for the reported mean correctness, failure-mode percentages, and cross-model rankings (e.g., the claim that rankings are slice-dependent).
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract and the need for protocol transparency. We address each major comment below and will make the necessary revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'current open models remain far from the human acceptance reference' rests on the 23.64% vs. 57.2% gap. The manuscript provides no description of how the human baseline was obtained (single-attempt vs. multiple attempts, prompting format, temperature, or whether it was collected on the exact 2,707 problems under execution-grounded conditions matching the model protocol). Without this, the numerical distance cannot be interpreted as a direct measure of capability shortfall.
Authors: We agree that the human baseline description is insufficient in the current manuscript. The 57.2% value is the average LeetCode acceptance rate across the 2,707 problems, drawn from the platform's public statistics on human submissions. These rates reflect multiple attempts by users rather than a controlled single-prompt protocol. We will revise the abstract to qualify the comparison and add a dedicated paragraph in the Evaluation section detailing the baseline source, its limitations, and why direct equivalence to the model evaluation is not claimed. This will allow readers to interpret the gap appropriately. revision: yes
-
Referee: [Abstract] Abstract and evaluation protocol: No information is given on prompt construction, temperature, or sampling strategy used for the 325,343 model jobs. These details are load-bearing for the reported mean correctness, failure-mode percentages, and cross-model rankings (e.g., the claim that rankings are slice-dependent).
Authors: We acknowledge that the manuscript does not provide sufficient information on prompt construction, temperature, or sampling strategy. We will revise the abstract to include a brief overview and expand the Evaluation Protocol section with full details on the standardized prompt template used, the temperature setting of 0.0 for deterministic outputs, and the single-sample strategy for each of the 325,343 jobs. This will support the reproducibility of the mean correctness, failure modes, and slice-dependent rankings. revision: yes
Circularity Check
No circularity: pure empirical measurement study
full rationale
The paper reports direct execution-based measurements of 9 LLMs on 2,707 LeetCode problems across 12 languages, producing aggregate correctness rates and failure breakdowns from the 325,343 jobs. No derivations, equations, fitted parameters, or predictions appear; the central claim (23.64% model vs 57.2% human) is a straightforward numerical comparison of observed outcomes. The human baseline is treated as an external reference, with no self-citation chains or ansatzes invoked to justify the methodology. The study is therefore self-contained against its own execution logs and static-analysis signals.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LeetCode problems and test cases are representative of coding tasks across 12 languages
Reference graph
Works this paper leans on
-
[1]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
Pith/arXiv arXiv 2021
-
[3]
Available: https://arxiv.org/abs/2108.07732
[Online]. Available: https://arxiv.org/abs/2108.07732
-
[4]
Measuring coding challenge competence with apps,
D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt, “Measuring coding challenge competence with apps,”NeurIPS, 2021. [Online]. Available: https://arxiv.org/abs/2105.09938
Pith/arXiv arXiv 2021
-
[5]
Li et al., ”Competition-Level Code Gen- eration with AlphaCode,”Science, vol
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. Sutherland Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals, “Competition-level ...
-
[6]
Competition-level code generation with AlphaCode,
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. Mankowitz, E. Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals, “Competition-level code generatio...
2022
-
[7]
Codexglue: A machine learning benchmark dataset for code understanding and generation,
S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. Clement, D. Drain, D. Jiang, D. Tang, G. Li, L. Zhou, L. Shou, L. Zhou, M. Tufano, M. Gong, M. Zhou, N. Duan, N. Sundaresan, S. K. Deng, S. Fu, and S. Liu, “Codexglue: A machine learning benchmark dataset for code understanding and generation,” 2021. [Online]. Available: https://arxiv.org/abs...
Pith/arXiv arXiv 2021
-
[8]
Codebleu: a method for automatic evaluation of code synthesis,
S. Ren, D. Guo, S. Lu, L. Zhou, S. Liu, D. Tang, N. Sundaresan, M. Zhou, A. Blanco, and S. Ma, “Codebleu: a method for automatic evaluation of code synthesis,” 2020. [Online]. Available: https://arxiv.org/abs/2009.10297
Pith/arXiv arXiv 2020
-
[9]
Multipl-e: A scalable and polyglot approach to benchmarking neural code generation,
F. Cassano, J. Gouwar, D. Nguyen, S. Nguyen, L. Phipps-Costin, D. Pinckney, M.-H. Yee, Y . Zi, C. J. Anderson, M. Q. Feldman, A. Guha, M. Greenberg, and A. Jangda, “Multipl-e: A scalable and polyglot approach to benchmarking neural code generation,”IEEE Trans. Softw. Eng., vol. 49, no. 7, p. 3675–3691, Jul. 2023
2023
-
[10]
Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval- x,
Q. Zheng, X. Xia, X. Zou, Y . Dong, S. Wang, Y . Xue, L. Shen, Z. Wang, A. Wang, Y . Li, T. Su, Z. Yang, and J. Tang, “Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval- x,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’23. New York, NY , USA: Association for C...
2023
-
[11]
Multi-lingual evaluation of code generation models,
B. Athiwaratkun, S. K. Gouda, Z. Wang, X. Li, Y . Tian, M. Tan, W. U. Ahmad, S. Wang, Q. Sun, M. Shang, S. K. Gonugondla, H. Ding, V . Kumar, N. Fulton, A. Farahani, S. Jain, R. Giaquinto, H. Qian, M. K. Ramanathan, R. Nallapati, B. Ray, P. Bhatia, S. Sengupta, D. Roth, and B. Xiang, “Multi-lingual evaluation of code generation models,” 2023. [Online]. Av...
arXiv 2023
-
[12]
Livecodebench: Holistic and contamina- tion free evaluation of large language models for code,
N. Jain, Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar- Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamina- tion free evaluation of large language models for code,” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 58 791–58 831
2025
-
[13]
Ds-1000: a natural and reliable benchmark for data science code generation,
Y . Lai, C. Li, Y . Wang, T. Zhang, R. Zhong, L. Zettlemoyer, W.-t. Yih, D. Fried, S. Wang, and T. Yu, “Ds-1000: a natural and reliable benchmark for data science code generation,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23, 2023
2023
-
[14]
Classeval: A manually-crafted benchmark for evaluating llms on class-level code generation,
X. Du, M. Liu, K. Wang, H. Wang, J. Liu, Y . Chen, J. Feng, C. Sha, X. Peng, and Y . Lou, “Classeval: A manually-crafted benchmark for evaluating llms on class-level code generation,” 2023. [Online]. Available: https://arxiv.org/abs/2308.01861
arXiv 2023
-
[15]
Cruxeval: a benchmark for code reasoning, understanding and execution,
A. Gu, B. Rozière, H. Leather, A. Solar-Lezama, G. Synnaeve, and S. I. Wang, “Cruxeval: a benchmark for code reasoning, understanding and execution,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24, 2024
2024
-
[16]
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions,
T. Y . Zhuo, V . M. Chien, J. Chim, H. Hu, W. Yu, R. Widyasari, I. N. B. Yusuf, H. Zhan, J. He, I. Paul, S. Brunner, C. GONG, J. Hoang, A. R. Zebaze, X. Hong, W.-D. Li, J. Kaddour, M. Xu, Z. Zhang, P. Yadav, N. Jain, A. Gu, Z. Cheng, J. Liu, Q. Liu, Z. Wang, D. Lo, B. Hui, N. Muennighoff, D. Fried, X. Du, H. de Vries, and L. V . Werra, “Bigcodebench: Benc...
2025
-
[17]
Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks,
R. Puri, D. S. Kung, G. Janssen, W. Zhang, G. Domeniconi, V . Zolotov, J. Dolby, J. Chen, M. Choudhury, L. Decker, V . Thost, L. Buratti, S. Pujar, S. Ramji, U. Finkler, S. Malaika, and F. Reiss, “Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks,”
-
[18]
Available: https://arxiv.org/abs/2105.12655
[Online]. Available: https://arxiv.org/abs/2105.12655
-
[19]
Unsuper- vised translation of programming languages,
B. Roziere, M.-A. Lachaux, L. Chanussot, and G. Lample, “Unsuper- vised translation of programming languages,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33, 2020, pp. 20 601–20 611
2020
-
[20]
Repobench: Benchmarking repository- level code auto-completion systems,
T. Liu, C. Xu, and J. McAuley, “Repobench: Benchmarking repository- level code auto-completion systems,”ArXiv, vol. abs/2306.03091, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:259075246
Pith/arXiv arXiv 2023
-
[21]
Crosscodeeval: a diverse and multilingual benchmark for cross-file code completion,
Y . Ding, Z. Wang, W. U. Ahmad, H. Ding, M. Tan, N. Jain, M. K. Ra- manathan, R. Nallapati, P. Bhatia, D. Roth, and B. Xiang, “Crosscodeeval: a diverse and multilingual benchmark for cross-file code completion,” in Proceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associate...
2023
-
[22]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?”ArXiv, vol. abs/2310.06770, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:263829697
Pith/arXiv arXiv 2023
-
[23]
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java,
D. Zan, Z. Huang, A. Yu, S. Lin, Y . Shi, W. Liu, D. Chen, Z. Qi, H. Yu, L. Yu, and et al., “SWE-bench-java: A GitHub Issue Resolving Benchmark for Java,”arXiv e-prints, p. arXiv:2408.14354, Aug. 2024
arXiv 2024
-
[24]
Multi-swe-bench: A multilingual benchmark for issue resolving,
D. Zan, Z. Huang, W. Liu, H. Chen, S. Xin, L. Zhang, Q. Liu, L. Aoyan, L. Chen, X. Zhong, S. Liu, Y . Xiao, L. Chen, Y . Zhang, J. Su, T. Liu, R. LONG, M. Ding, and l. xiang, “Multi-swe-bench: A multilingual benchmark for issue resolving,” inAdvances in Neural Information Processing Systems, D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghasse...
2025
-
[25]
Codebert: A pre-trained model for programming and natural languages
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou, “Codebert: A pre-trained model for programming and natural languages.” inEMNLP (Findings), ser. Findings of ACL, T. Cohn, Y . He, and Y . Liu, Eds., vol. EMNLP 2020, 2020, pp. 1536–1547
2020
-
[26]
Graphcodebert: Pre-training code representations with data flow,
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy, S. Fu, M. Tufano, S. K. Deng, C. Clement, D. Drain, N. Sundaresan, J. Yin, D. Jiang, and M. Zhou, “Graphcodebert: Pre-training code representations with data flow,” 2021. [Online]. Available: https://arxiv.org/abs/2009.08366
Pith/arXiv arXiv 2021
-
[27]
CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,
Y . Wang, W. Wang, S. Joty, and S. C. Hoi, “CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, M.-F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, Eds. Online and Punta Cana, Dominican Republic: Association for...
2021
-
[28]
Codegen: An open large language model for code with multi-turn program synthesis,
E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y . Zhou, S. Savarese, and C. Xiong, “Codegen: An open large language model for code with multi-turn program synthesis,” inInternational Conference on Learning Representations, 2022
2022
-
[29]
Incoder: A generative model for code infilling and synthesis,
D. Fried, A. Aghajanyan, J. Lin, S. I. Wang, E. Wallace, F. Shi, R. Zhong, W. tau Yih, L. Zettlemoyer, and M. Lewis, “Incoder: A generative model for code infilling and synthesis,”ArXiv, vol. abs/2204.05999, 2022
Pith/arXiv arXiv 2022
-
[30]
SantaCoder: don’t reach for the stars!
L. Ben Allal, R. Li, D. Kocetkov, C. Mou, C. Akiki, C. Munoz Ferrandis, N. Muennighoff, M. Mishra, A. Gu, M. Dey, and et al., “SantaCoder: don’t reach for the stars!”arXiv e-prints, p. arXiv:2301.03988, Jan. 2023
arXiv 2023
-
[31]
Wizardcoder: Empowering code large language models with evol-instruct,
Z. Luo, C. Xu, P. Zhao, Q. Sun, X. Geng, W. Hu, C. Tao, J. Ma, Q. Lin, and D. Jiang, “Wizardcoder: Empowering code large language models with evol-instruct,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[33]
Available: https://arxiv.org/abs/2308.12950
[Online]. Available: https://arxiv.org/abs/2308.12950
-
[34]
Deepseek-coder: When the large language model meets programming - the rise of code intelligence,
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . K. Li, F. Luo, Y . Xiong, and W. Liang, “Deepseek-coder: When the large language model meets programming - the rise of code intelligence,”ArXiv, vol. abs/2401.14196, 2024
Pith/arXiv arXiv 2024
-
[35]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023
2023
-
[36]
Is chatgpt the ultimate programming assistant – how far is it?
H. Tian, W. Lu, T. O. Li, X. Tang, S.-C. Cheung, J. Klein, and T. F. Bissyandé, “Is chatgpt the ultimate programming assistant – how far is it?” 2023. [Online]. Available: https://arxiv.org/abs/2304.11938
arXiv 2023
-
[37]
S. E. Arefin, T. A. Heya, H. Al-Qudah, Y . Ineza, and A. Serwadda, “Unmasking the giant: A comprehensive evaluation of ChatGPT’s proficiency in coding algorithms and data structures,” inProceedings of the 16th International Conference on Agents and Artificial Intelligence, vol. 1, 2024, pp. 412–419. [Online]. Available: https: //arxiv.org/abs/2307.05360
arXiv 2024
-
[38]
Stable or shaky? the semantics of chatgpt’s behavior under repeated queries,
T. A. Heya, Y . Ineza, S. E. Arefin, G. Uzor, and A. Serwadda, “Stable or shaky? the semantics of chatgpt’s behavior under repeated queries,” in2024 IEEE 18th International Conference on Semantic Computing (ICSC), 2024, pp. 110–116
2024
-
[39]
An analysis of the automatic bug fixing performance of chatgpt,
D. Sobania, M. Briesch, C. Hanna, and J. Petke, “An analysis of the automatic bug fixing performance of chatgpt,”2023 IEEE/ACM International Workshop on Automated Program Repair (APR), pp. 23–30, 2023
2023
-
[40]
Leveraging large language models for enhancing the understandability of generated unit tests,
C. Wang, K. Huang, J. Zhang, Y . Feng, L. Zhang, Y . Liu, and X. Peng, “Llms meet library evolution: Evaluating deprecated api usage in llm-based code completion,” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering, ser. ICSE ’25, 2025, p. 885–897. [Online]. Available: https: //doi.org/10.1109/ICSE55347.2025.00245
-
[41]
Evaluating large language models trained on code with humaneval and generated tests,
B. Chen, F. Zhang, A. Nguyen, D. Zan, Z. Lin, J.-G. Lou, and W. Chen, “Evaluating large language models trained on code with humaneval and generated tests,”arXiv preprint arXiv:2207.10397, 2022. [Online]. Available: https://arxiv.org/abs/2207.10397
Pith/arXiv arXiv 2022
-
[42]
Reflexion: language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: language agents with verbal reinforcement learning,” in Proceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023
2023
-
[43]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” 2023, publisher Copyright: © 2023 11th International Conference on Learning Representations, ICLR 2023. All rights reserved.; 11th International Conference on Learning Representations, ICLR 2023 ; Conference date: 01-05-2023...
2023
-
[44]
Evaluating source code quality with large language models: a comparative study,
I. R. d. S. Simões and E. Venson, “Evaluating source code quality with large language models: a comparative study,” inProceedings of the XXIII Brazilian Symposium on Software Quality, ser. SBQS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 103–113. [Online]. Available: https://doi.org/10.1145/3701625.3701650
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.