Geometry-Aware Fisheye-LiDAR Fusion for Robust 3D Object Detection in Low-Overlap Setups
Pith reviewed 2026-06-27 18:32 UTC · model grok-4.3
The pith
A geometry-aware fusion method lifts fisheye features into polar BEV grids and applies dual-attention correction to improve 3D detection with LiDAR in low-overlap setups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
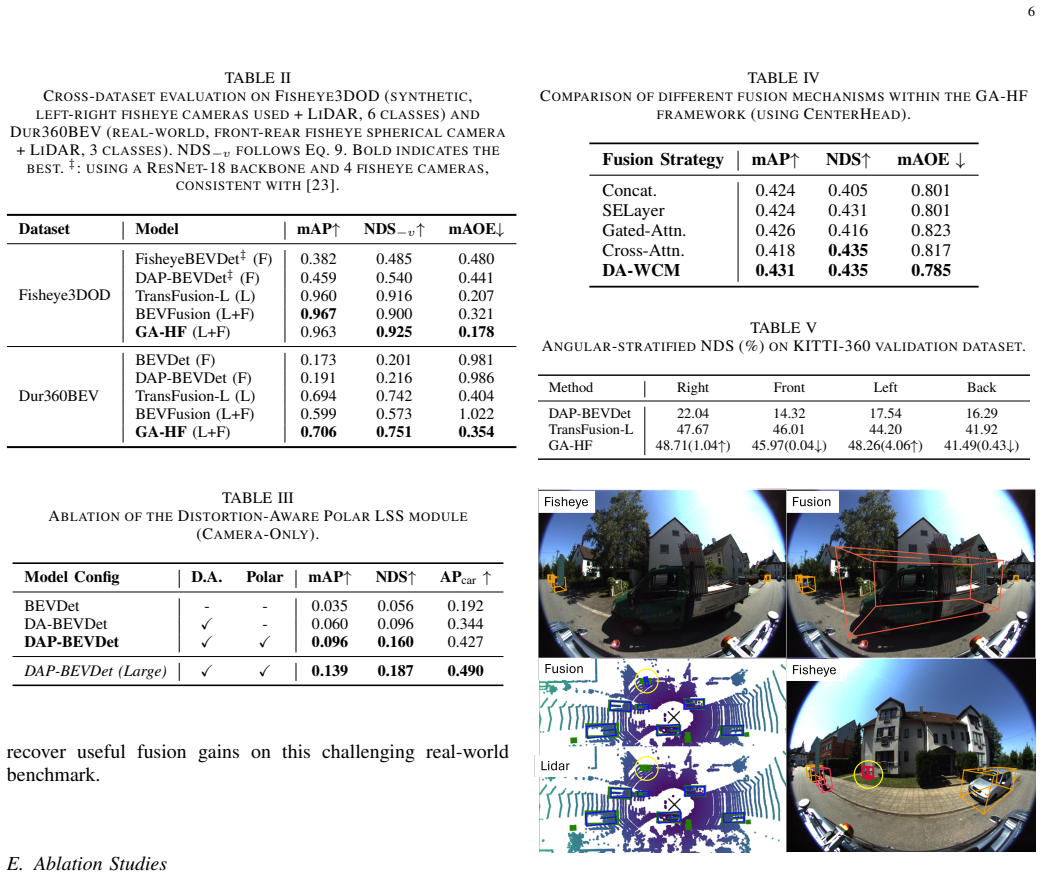
GA-HF is the first approach to explore LiDAR-fisheye camera fusion; on KITTI-360 it improves NDS by 4.2% over Cartesian baselines while reducing orientation error on Dur360BEV and attaining the highest detection score among fusion methods on Fisheye3DOD.
What carries the argument
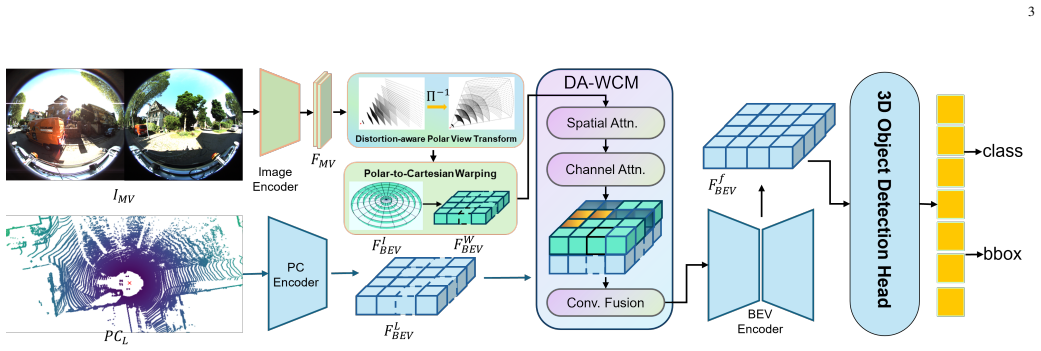
The Distortion-Aware Lift-Splat-Shoot module that lifts fisheye features into a polar BEV grid to preserve native angular density, paired with the Dual-Attention Warping Correction module that applies spatial and channel attention to suppress peripheral artifacts before fusion.
Load-bearing premise
The Dual-Attention Warping Correction module can reliably suppress artifacts in low-quality peripheral regions of the warped fisheye features while enhancing semantic cues.
What would settle it
An experiment on KITTI-360 where removing or disabling the Dual-Attention Warping Correction produces no improvement or a drop in NDS relative to the Cartesian baseline.
Figures


read the original abstract
As autonomous systems expand from capital-intensive robotaxis to cost-sensitive logistics, sensor configurations are increasingly optimized for coverage-per-cost. A prevalent sparse-view setup utilizes dual-fisheye cameras with a roof-mounted LiDAR, introducing severe geometric challenges: extreme radial distortion, minimal overlap, and misalignment between spherical projections and rectilinear grids. BEV fusion algorithms typically force image and point cloud modalities into unified Cartesian grids early in the pipeline, causing significant feature distortion and information loss for wide-view fisheye cameras. To address this, we propose a Geometry-Aware Hybrid Fusion (GA-HF) framework that explicitly accounts for fisheye geometry and BEV feature distortion, where fisheye features are lifted into a polar BEV grid via a Distortion-Aware Lift-Splat-Shoot (LSS) module to preserve native angular density, while LiDAR features are processed in native Cartesian space for metric fidelity of bounding box regression. To bridge these heterogeneous streams, we introduce a Dual-Attention Warping Correction module that applies spatial and channel attention to the warped camera features before fusion, explicitly suppressing artifacts in low-quality peripheral regions while enhancing high-quality semantic cues. GA-HF is evaluated on three benchmarks: KITTI-360, Dur360BEV, and Fisheye3DOD datasets. To the best of our knowledge, it is the first approach to explore LiDAR-fisheye camera fusion. On KITTI-360, GA-HF improves NDS by 4.2% over Cartesian baselines; on Dur360BEV, it surpasses both LiDAR-only and BEVFusion, while significantly reducing orientation error despite the geometric distortions; on Fisheye3DOD, it attains the highest detection score among all fusion methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Geometry-Aware Hybrid Fusion (GA-HF) for 3D object detection in sparse-view setups with dual fisheye cameras and roof-mounted LiDAR. Fisheye features are lifted to a polar BEV grid via a Distortion-Aware LSS module to preserve angular density, LiDAR features remain in Cartesian space, and a Dual-Attention Warping Correction module fuses the streams by applying spatial/channel attention to suppress peripheral artifacts. It claims to be the first LiDAR-fisheye fusion method and reports a 4.2% NDS gain over Cartesian baselines on KITTI-360, reduced orientation error on Dur360BEV, and top fusion score on Fisheye3DOD.
Significance. If the performance gains hold after proper isolation of components, the work would be significant for cost-sensitive autonomous systems by enabling effective fusion under extreme distortion and low overlap, where standard Cartesian BEV methods lose information. The explicit handling of polar vs. Cartesian grids and the novelty claim as the first such fusion are positive aspects.
major comments (2)
- [Abstract and Method] Abstract and Method: No ablation is presented that removes or replaces only the Dual-Attention Warping Correction module (e.g., with naive warping or concatenation) while holding the polar-Cartesian grid split and other architecture choices fixed. This is load-bearing for attributing the 4.2% NDS improvement on KITTI-360 and orientation gains on Dur360BEV specifically to the attention-based correction rather than the heterogeneous representation or added capacity.
- [Experiments] Experiments: The reported percentage gains and dataset rankings lack error bars, multiple random seeds, statistical significance tests, or details on baseline re-implementations and data splits. This makes it impossible to determine whether the improvements are robust or sensitive to unstated choices, directly affecting the central empirical claims.
minor comments (2)
- [Introduction] The abstract states the method is 'the first approach to explore LiDAR-fisheye camera fusion' but the introduction should include a more explicit comparison table or discussion against any prior multi-modal works that touch on wide-FOV cameras even if not exactly fisheye-LiDAR.
- [Method] Notation for the polar BEV grid and the warping operation could be clarified with an explicit equation or diagram reference in the method description to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Method] Abstract and Method: No ablation is presented that removes or replaces only the Dual-Attention Warping Correction module (e.g., with naive warping or concatenation) while holding the polar-Cartesian grid split and other architecture choices fixed. This is load-bearing for attributing the 4.2% NDS improvement on KITTI-360 and orientation gains on Dur360BEV specifically to the attention-based correction rather than the heterogeneous representation or added capacity.
Authors: We agree that a targeted ablation isolating the Dual-Attention Warping Correction module—while holding the polar-Cartesian grid split and other choices fixed—would better attribute the gains. Current ablations cover broader components but not this exact isolation. We will add the requested ablation (full GA-HF vs. naive warping and concatenation variants) in the revision. revision: yes
-
Referee: [Experiments] Experiments: The reported percentage gains and dataset rankings lack error bars, multiple random seeds, statistical significance tests, or details on baseline re-implementations and data splits. This makes it impossible to determine whether the improvements are robust or sensitive to unstated choices, directly affecting the central empirical claims.
Authors: We acknowledge that error bars, multiple seeds, significance tests, and expanded baseline/split details would strengthen the empirical claims. The current results use standard single-run evaluations. We will re-run with multiple seeds, report means and standard deviations, add significance tests, and expand details on re-implementations and splits in the revision and supplement. revision: yes
Circularity Check
No circularity: empirical method with additive modules and benchmark results
full rationale
The paper introduces GA-HF as a geometry-aware fusion framework using Distortion-Aware LSS for polar BEV lifting of fisheye features and Dual-Attention Warping Correction for heterogeneous stream alignment, with all performance numbers (e.g., 4.2% NDS lift) arising from end-to-end training and evaluation on KITTI-360, Dur360BEV, and Fisheye3DOD. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citations appear in the provided text; the central claims rest on external benchmark comparisons rather than internal redefinitions or load-bearing prior work by the same authors. The derivation chain is therefore self-contained and additive.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kitti-360: A novel dataset and bench- marks for urban scene understanding in 2d and 3d,
Y . Liao, J. Xie, and A. Geiger, “Kitti-360: A novel dataset and bench- marks for urban scene understanding in 2d and 3d,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3292– 3310, 2022
2022
-
[2]
Dur360bev: A real-world 360-degree single camera dataset and benchmark for bird-eye view mapping in autonomous driving,
E. Wenke, C. Yuan, L. Li, Y . Sun, Y . F. A. Gaus, A. Atapour-Abarghouei, and T. P. Breckon, “Dur360bev: A real-world 360-degree single camera dataset and benchmark for bird-eye view mapping in autonomous driving,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 3737–3744
2025
-
[3]
The oxford spires dataset: Benchmarking large-scale lidar-visual localisation, reconstruction and radiance field methods,
Y . Tao, M. ´A. Mu˜noz-Ba˜n´on, L. Zhang, J. Wang, L. F. T. Fu, and M. Fal- lon, “The oxford spires dataset: Benchmarking large-scale lidar-visual localisation, reconstruction and radiance field methods,”International Journal of Robotics Research, 2025
2025
-
[4]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” inIEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[5]
Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,
X. Bai, Z. Hu, X. Zhu, Q. Huang, Y . Chen, H. Fu, and C.-L. Tai, “Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1090–1099
2022
-
[6]
Cross modal transformer: Towards fast and robust 3d object detection,
J. Yan, Y . Liu, J. Sun, F. Jia, S. Li, T. Wang, and X. Zhang, “Cross modal transformer: Towards fast and robust 3d object detection,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 18 268–18 278
2023
-
[7]
Polarformer: Multi-camera 3d object detection with polar transformer,
Y . Jiang, L. Zhang, Z. Miao, X. Zhu, J. Gao, W. Hu, and Y .-G. Jiang, “Polarformer: Multi-camera 3d object detection with polar transformer,” inProceedings of the AAAI conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 1042–1050
2023
-
[8]
Polarbevdet: Exploring polar representation for multi-view 3d object detection in bird’s-eye-view,
Z. Yu, Q. Liu, W. Wang, L. Zhang, and X. Zhao, “Polarbevdet: Exploring polar representation for multi-view 3d object detection in bird’s-eye- view,”arXiv preprint arXiv:2408.16200, 2024
-
[9]
Partner: Level up the polar representation for lidar 3d object detection,
M. Nie, Y . Xue, C. Wang, C. Ye, H. Xu, X. Zhu, Q. Huang, M. B. Mi, X. Wang, and L. Zhang, “Partner: Level up the polar representation for lidar 3d object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3801–3813
2023
-
[10]
Polarstream: Streaming object detection and segmentation with polar pillars,
Q. Chen, S. V ora, and O. Beijbom, “Polarstream: Streaming object detection and segmentation with polar pillars,”Advances in Neural Information Processing Systems, vol. 34, pp. 26 871–26 883, 2021
2021
-
[11]
Cbam: Convolutional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19
2018
-
[12]
Pc-bev: An efficient polar-cartesian bev fusion framework for lidar semantic segmentation,
S. Qiu, X. Li, X. Xue, and J. Pu, “Pc-bev: An efficient polar-cartesian bev fusion framework for lidar semantic segmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 6, 2025, pp. 6612–6620
2025
-
[13]
Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation,
H. Zhou, X. Zhu, X. Song, Y . Ma, Z. Wang, H. Li, and D. Lin, “Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation,”arXiv preprint arXiv:2008.01550, 2020
-
[14]
Polarfusion: A multi-modal fusion algorithm for 3d object detection based on polar coordinates,
P. Shi, R. Ge, X. Dong, C. Chakir, T. Liang, and A. Yang, “Polarfusion: A multi-modal fusion algorithm for 3d object detection based on polar coordinates,”Neural Networks, p. 107704, 2025
2025
-
[15]
Polargfusion3d: Polar graph fusion network for enhanced multimodal 3d perception in intelligent vehicles,
L. Li and C. Wei, “Polargfusion3d: Polar graph fusion network for enhanced multimodal 3d perception in intelligent vehicles,”IEEE Trans- actions on Intelligent Vehicles, 2024
2024
-
[16]
Z. Ming, J. S. Berrio, M. Shan, Y . Huang, H. Lyu, N. H. K. Tran, T.-Y . Tseng, and S. Worrall, “Occcylindrical: Multi-modal fusion with cylindrical representation for 3d semantic occupancy prediction,”arXiv preprint arXiv:2505.03284, 2025
-
[17]
Adapting cnns for fisheye cameras without retraining,
R. Griffiths and D. G. Dansereau, “Adapting cnns for fisheye cameras without retraining,” in2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 2025, pp. 1–7
2025
-
[18]
Darswin: Distortion aware radial swin transformer,
A. Athwale, A. Afrasiyabi, J. Lag ¨ue, I. Shili, O. Ahmad, and J.- F. Lalonde, “Darswin: Distortion aware radial swin transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 5929–5938
2023
-
[19]
Convolution kernel adaptation to calibrated fisheye,
B. Berenguel-Baeta, M. Santos-Villafranca, J. Bermudez-Cameo, A. P. Yus, and J. Guerrero, “Convolution kernel adaptation to calibrated fisheye,” in34th British Machine Vision Conference 2023, BMVC 2023, Aberdeen, UK, November 20-24, 2023. BMV A, 2023
2023
-
[20]
Fishbev: Distortion-resilient bird’s eye view segmentation with surround-view fisheye cameras,
H. Li, D. Sheng, Q. Dong, Z. Wang, Z. Xu, and T. Li, “Fishbev: Distortion-resilient bird’s eye view segmentation with surround-view fisheye cameras,”arXiv preprint arXiv:2509.13681, 2025
-
[21]
Fisheye- bevseg: Surround view fisheye cameras based bird’s-eye view seg- mentation for autonomous driving,
S. Yogamani, D. Unger, V . Narayanan, and V . R. Kumar, “Fisheye- bevseg: Surround view fisheye cameras based bird’s-eye view seg- mentation for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1331–1334
2024
-
[22]
F2bev: Bird’s eye view generation from surround-view fisheye camera images for automated driving,
E. U. Samani, F. Tao, H. R. Dasari, S. Ding, and A. G. Banerjee, “F2bev: Bird’s eye view generation from surround-view fisheye camera images for automated driving,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 9367–9374
2023
-
[23]
Exploring surround-view fisheye camera 3d object detection,
C. Li, W. Lin, Z. Hou, G. Chen, W. Zhang, H. Zhou, and W. Zheng, “Exploring surround-view fisheye camera 3d object detection,” inPro- ceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 8, 2026, pp. 6019–6027
2026
-
[24]
Fisheyedepth: A real scale self-supervised depth estimation model for fisheye camera,
G. Zhao, Y . Liu, W. Qi, F. Ma, M. Liu, and J. Ma, “Fisheyedepth: A real scale self-supervised depth estimation model for fisheye camera,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 3780–3787
2025
-
[25]
Equiv- fisheye: A spherical fusion framework for panoramic 3d perception with surround-view fisheye cameras,
Z. Yang, X. Pu, W. Xu, Z. Qian, K. Ke, H. Zhang, and L. Liu, “Equiv- fisheye: A spherical fusion framework for panoramic 3d perception with surround-view fisheye cameras,”Information Fusion, p. 104024, 2025
2025
-
[26]
Detecting as labeling: Rethinking lidar-camera fusion in 3d object detection,
J. Huang, Y . Ye, Z. Liang, Y . Shan, and D. Du, “Detecting as labeling: Rethinking lidar-camera fusion in 3d object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 439–455. 8
2024
-
[27]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141
2018
-
[28]
Single view point omnidirectional camera cal- ibration from planar grids,
C. Mei and P. Rives, “Single view point omnidirectional camera cal- ibration from planar grids,” inProceedings 2007 IEEE International Conference on Robotics and Automation. IEEE, 2007, pp. 3945–3950
2007
-
[29]
Benchmarking multi-view bev object de- tection with mixed pinhole and fisheye cameras,
X. Liu and H. Shen, “Benchmarking multi-view bev object de- tection with mixed pinhole and fisheye cameras,”arXiv preprint arXiv:2603.27818, 2026
-
[30]
MMDetection3D: OpenMMLab next-generation plat- form for general 3D object detection,
M. Contributors, “MMDetection3D: OpenMMLab next-generation plat- form for general 3D object detection,” https://github.com/open-mmlab/ mmdetection3d, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.