Multilingual Sentiment Aware Text Summarization A Reinforcement Learning Approach for Consistency Maintenance
Pith reviewed 2026-06-27 17:10 UTC · model grok-4.3
The pith
KL regularization drives sentiment suppression in RLHF summarization, but a targeted modification to the term reduces the drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
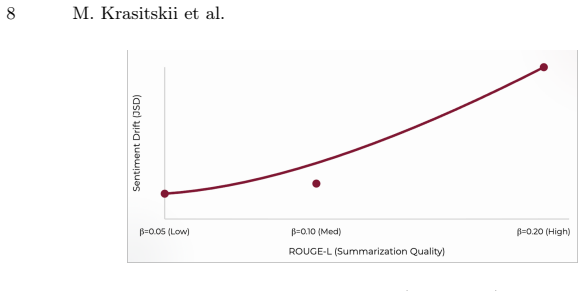
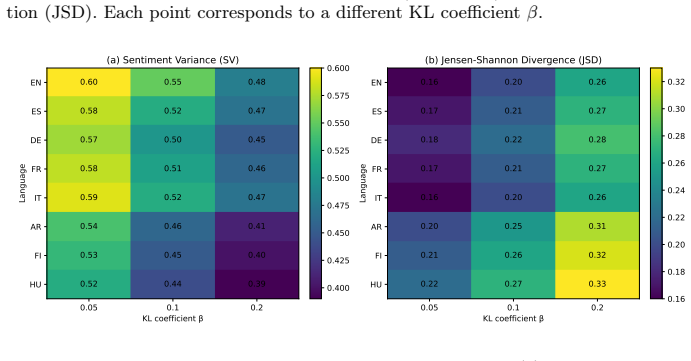
Sentiment drift is a systematic outcome of RLHF in summarization, becoming stronger with increased KL regularization strength. The Policy Attribution framework decomposes the RLHF objective to show that KL regularization is the primary driver of sentiment suppression across settings. A sentiment-aware modification of the KL term, which selectively reduces constraints on sentiment-bearing tokens, mitigates the drift while maintaining summarization quality, as demonstrated in multilingual experiments.
What carries the argument
The Policy Attribution framework that decomposes the RLHF objective to quantify component contributions to sentiment changes, together with the proposed sentiment-aware variant of the KL regularization term.
If this is right
- Sentiment drift occurs consistently across multiple languages and model architectures when KL regularization is applied.
- Increasing KL regularization strength directly amplifies the suppression of affective content.
- The sentiment-aware KL modification mitigates drift while preserving factual consistency and fluency.
- Current alignment objectives improve safety and consistency but can unintentionally reduce emotional expressiveness.
- Alignment methods need to account explicitly for affective preservation to avoid this side effect.
Where Pith is reading between the lines
- The same selective regularization approach could be tested on other affective properties such as emotion category or intensity.
- Sentiment drift might appear in RLHF-tuned generation tasks beyond summarization, such as dialogue or story continuation.
- The Policy Attribution method offers a general way to diagnose which objective terms affect specific output properties.
- Selective relaxation of constraints on particular token classes may generalize to other alignment goals like factual accuracy.
Load-bearing premise
The Policy Attribution framework accurately decomposes the RLHF objective and quantifies component contributions without experimental bias.
What would settle it
Measure average sentiment polarity scores on summaries from the same models and data before and after applying the sentiment-aware KL modification, or across a range of KL strengths, to test whether the modification reliably reduces the shift toward neutral outputs.
Figures
read the original abstract
Reinforcement Learning from Human Feedback (RLHF) has significantly improved the quality and fluency of large language models in text summarization. However, its impact on affective properties remains insufficiently understood. In this work, we study sentiment drift, a systematic shift toward neutral sentiment in RLHF-based summarization outputs compared to source texts. We conduct extensive experiments across multiple datasets, model architectures, and eight languages to analyze how alignment objectives influence sentiment preservation. Our results show that sentiment drift is a consistent phenomenon that becomes stronger with increased KL regularization strength, indicating a trade-off between alignment stability and affective fidelity. To explain this behavior, we introduce a Policy Attribution framework that decomposes the RLHF objective and quantifies the contribution of its components. Our analysis reveals that KL regularization is the primary driver of sentiment suppression across all settings. Based on these findings, we propose a sentiment-aware modification of the KL regularization term, which selectively reduces constraints on sentiment-bearing tokens. Empirical results demonstrate that this approach mitigates sentiment drift while maintaining summarization quality. Overall, our findings highlight a fundamental limitation of current alignment methods: while they improve factual consistency and safety, they may unintentionally suppress emotional expressiveness. This motivates the development of alignment strategies that explicitly account for affective preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies sentiment drift in RLHF-based summarization, reporting that outputs shift toward neutral sentiment relative to sources; this effect strengthens with KL regularization strength across multiple datasets, models, and eight languages. It introduces a Policy Attribution framework to decompose the RLHF objective and attributes the suppression primarily to the KL term. A sentiment-aware modification to the KL term is proposed that relaxes constraints on sentiment-bearing tokens; empirical results indicate reduced drift while preserving summarization quality.
Significance. If the attribution holds, the work would usefully identify an under-appreciated side-effect of standard RLHF objectives and supply a targeted mitigation, with potential relevance for affective fidelity in multilingual generation.
major comments (2)
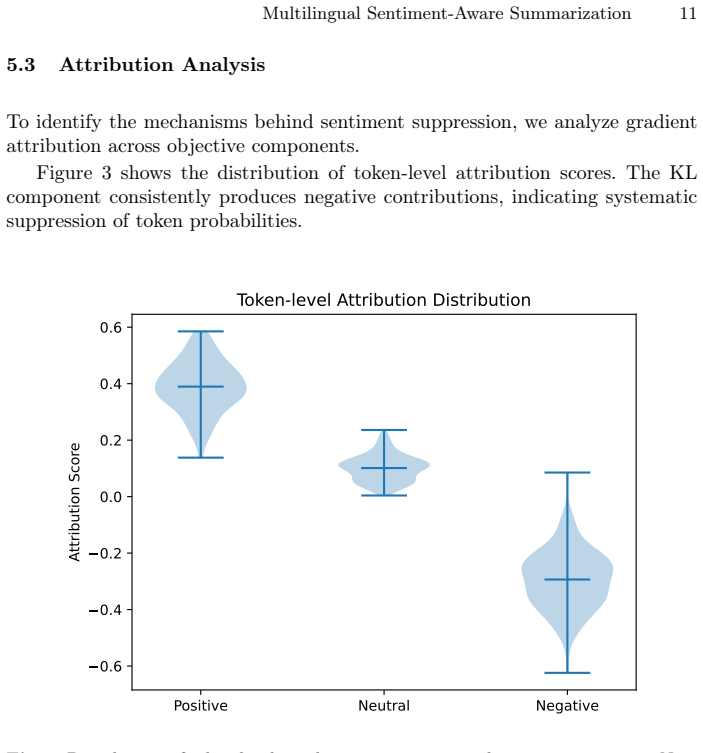
- [Policy Attribution framework] Policy Attribution framework (introduced after the drift observations): the manuscript supplies no equations defining the decomposition, no proof or argument for uniqueness/identifiability of the component contributions, and no ablations against alternatives (e.g., direct ablation of the KL coefficient or Shapley-value attribution). This decomposition is load-bearing for the claim that KL regularization is the primary driver across all settings.
- [Empirical results and proposed modification] Experimental validation of the proposed KL modification: while the abstract asserts mitigation of drift without loss of quality, the description provides neither the precise functional form of the sentiment-aware term, nor statistical tests, confidence intervals, or controls for token-selection bias in the attribution step. These details are required to establish that the improvement is not an artifact of the same framework used to diagnose the problem.
minor comments (1)
- [Title] Title refers to 'Consistency Maintenance' while the body centers on sentiment preservation; a title that foregrounds the sentiment-aware contribution would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Policy Attribution framework] Policy Attribution framework (introduced after the drift observations): the manuscript supplies no equations defining the decomposition, no proof or argument for uniqueness/identifiability of the component contributions, and no ablations against alternatives (e.g., direct ablation of the KL coefficient or Shapley-value attribution). This decomposition is load-bearing for the claim that KL regularization is the primary driver across all settings.
Authors: We agree that the Policy Attribution framework requires a more explicit formalization to support the central claim. In the revised manuscript we will insert the defining equations that decompose the RLHF objective, supply a short identifiability argument based on the additive separation of the reward and KL terms, and add ablations that compare the framework against direct variation of the KL coefficient and against Shapley-value attribution. These additions will directly address the concern that the attribution is load-bearing. revision: yes
-
Referee: [Empirical results and proposed modification] Experimental validation of the proposed KL modification: while the abstract asserts mitigation of drift without loss of quality, the description provides neither the precise functional form of the sentiment-aware term, nor statistical tests, confidence intervals, or controls for token-selection bias in the attribution step. These details are required to establish that the improvement is not an artifact of the same framework used to diagnose the problem.
Authors: We concur that the functional form and statistical controls must be stated explicitly. The revised version will provide the exact mathematical expression for the sentiment-aware KL term, report paired statistical tests together with 95 % confidence intervals on the primary metrics, and include a randomized-token-selection control to rule out bias in the attribution step. These changes will confirm that the reported mitigation is not an artifact. revision: yes
Circularity Check
No significant circularity; Policy Attribution is a new experimental decomposition without self-referential reduction
full rationale
The paper introduces the Policy Attribution framework in this work to decompose the RLHF objective and attributes primary contribution to the KL term based on experiments across datasets, models, and languages. No equations or definitions are shown that make the framework's output equivalent to its inputs by construction, nor are there self-citations load-bearing the central claim, fitted parameters renamed as predictions, or ansatzes smuggled via prior work. The derivation relies on empirical observation and a newly proposed decomposition rather than reducing to quantities defined from the same fitted values or self-referential premises. This is consistent with a low circularity score as the analysis remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The RLHF objective can be decomposed into components whose contributions can be quantified via the Policy Attribution framework
- domain assumption Sentiment can be measured consistently and comparably across the eight languages studied
invented entities (1)
-
Policy Attribution framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D.M., Lowe, R., Voss, C., Radford, A., Amodei, D., Christiano, P.F.: Learning to summarize with human feedback. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds.) Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp. 3008–3021 (2020)
2020
-
[2]
In: Advances in Neural Information Processing Systems (NeurIPS), vol
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 27730–27744 (2022)
2022
-
[3]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
In: Advances in Neural Information Processing Systems (NeurIPS), vol
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., Finn, C.: Di- rect preference optimization: Your language model is secretly a reward model. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 36, pp. 53728–53741. Curran Associates, New Orleans (2023)
2023
-
[5]
Scaling Laws for Reward Model Overoptimization
Gao, L., Schulman, J., Hilton, J.: Scaling laws for reward model overoptimization. arXiv preprint arXiv:2210.10760 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
In: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J
Gehrmann, S., Deng, Y., Rush, A.M.: Bottom-up abstractive summarization. In: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J. (eds.) Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4098–4109. Association for Computational Linguistics, Brussels (2018)
2018
-
[7]
In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp
Laban, P., Wu, C.S., Liu, L., Xiong, C., Liu, C.: Summac: Re-visiting NLI-based models for inconsistency detection in summarization. In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 1637–1652. Association for Computational Linguistics, Seattle (2022)
2022
-
[8]
In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pp
Maynez, J., Narayan, S., Bohnet, B., McDonald, R.: On faithfulness and factuality in abstractive summarization. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 1906–1919. Association for Computational Linguistics (2020)
1906
-
[9]
In: Proceedings of the AAAI Conference on Artificial Intelligence, pp
Amplayo, R.K., Lapata, M.: Unsupervised opinion summarization with content planning. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 8435–8443 (2021)
2021
-
[10]
Computer Speech & Lan- guage 28(1), 56–75 (2014)
Balahur, A., Turchi, M.: Comparative experiments using supervised learning and machine translation for multilingual sentiment analysis. Computer Speech & Lan- guage 28(1), 56–75 (2014)
2014
-
[11]
PeerJ Computer Science 11, cs3406 (2025) https://doi.org/10.7717/peerj-cs.3406
Krasitskii, M., Granichin, O., Kotelnikov, E.: Multilingual sentiment-aware text summarization: A cross-language study of text shortening effects. PeerJ Computer Science 11, cs3406 (2025) https://doi.org/10.7717/peerj-cs.3406
-
[12]
In: Precup, D., Teh, Y.W
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. In: Precup, D., Teh, Y.W. (eds.) Proceedings of the 34th International Conference on Machine Learning (ICML), Proceedings of Machine Learning Research, vol. 70, pp. 3319–3328. PMLR (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.