Rethinking 3D Shape Generation: Diffusion over Superquadrics
Pith reviewed 2026-06-27 17:18 UTC · model grok-4.3
The pith
Diffusion over the parameters of a few superquadrics generates 3D shapes from a 7KB state instead of dense grids while matching benchmark quality after decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representing each shape as a small collection of superquadrics and performing the entire diffusion process on their 7KB parameter set (pose, size, shape) yields competitive surface-fidelity and distributional performance once decoded to point clouds, while reducing diffusion-state dimensionality and per-step compute compared with voxel, SDF, mesh, or point-cloud diffusion.
What carries the argument
Diffusion process applied to the 7KB parameter vectors of a small set of superquadrics (pose, size, shape).
If this is right
- Diffusion-state dimensionality drops from thousands or millions of values to 7KB.
- Per-step compute and memory usage decrease enough to allow generation in 0.6 seconds per shape under most conditions.
- Point-cloud decoding works at any chosen resolution without retraining.
- Individual superquadric parts can be edited directly after generation.
- Explicit parameters make it straightforward to impose geometric constraints during the diffusion process.
Where Pith is reading between the lines
- The explicit parametric form may let users enforce manufacturing tolerances or assembly rules more directly than latent-space methods.
- Because each superquadric remains identifiable, the representation could support automatic conversion to CAD primitives without an extra fitting step.
- The same low-dimensional state might extend to conditional generation guided by text or sketches that specify individual part properties.
Load-bearing premise
A small fixed number of superquadrics can represent the geometric variety of the evaluation shapes without systematic loss that only appears after decoding to dense surfaces.
What would settle it
Run the method on the same benchmarks, decode the outputs to dense surfaces, and measure surface metrics such as Chamfer distance or IoU; if the scores fall systematically below those of dense diffusion baselines the central claim does not hold.
Figures




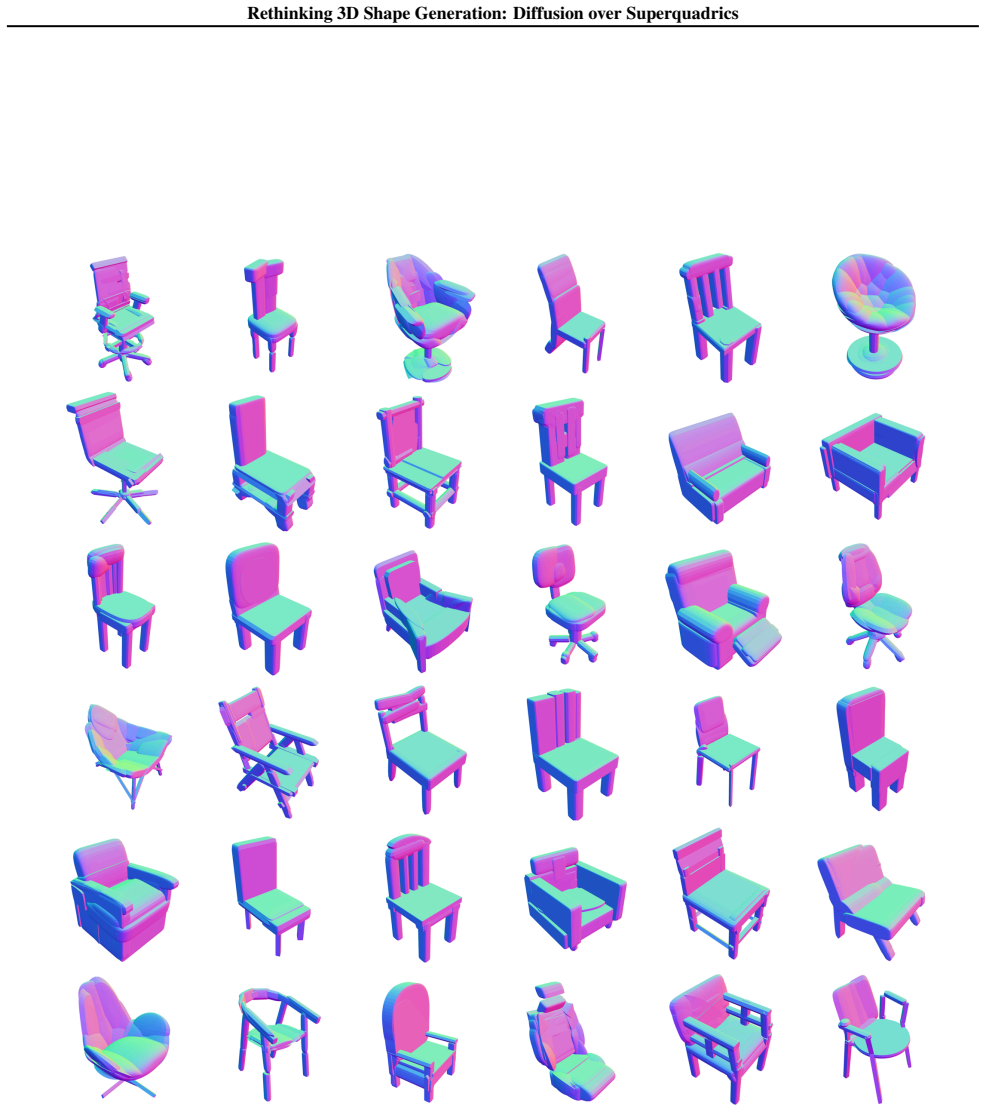

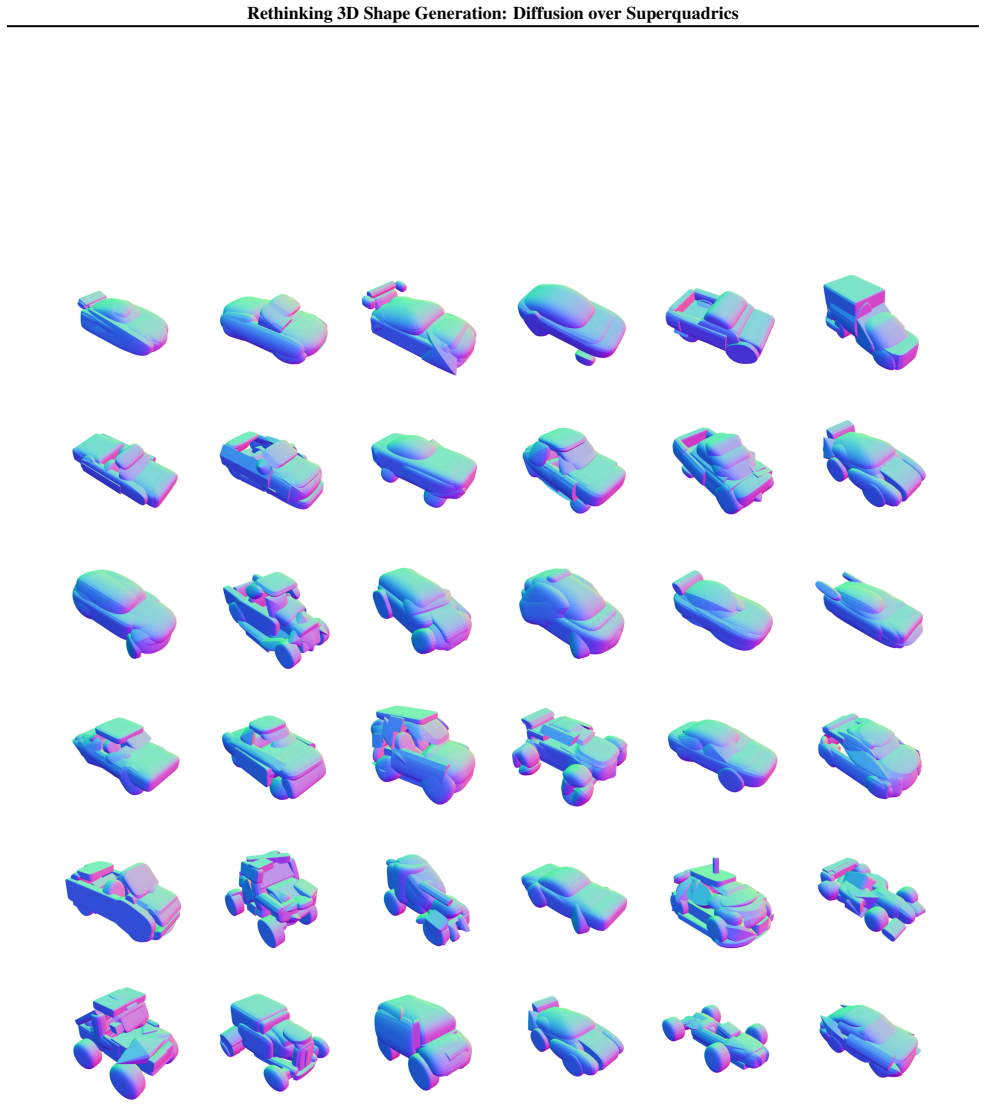
read the original abstract
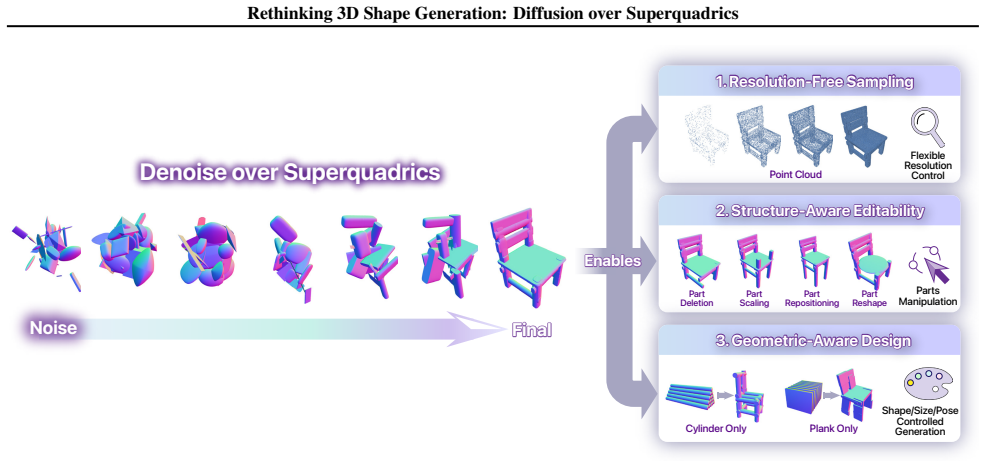
Diffusion models have advanced 3D shape generation, yet most methods still denoise in high-cardinality spaces (e.g., voxel/SDF grids, meshes, or point clouds), which is computationally and memory intensive and makes it difficult to scale in terms of both higher resolution and stronger controllability. We rethink the diffusion representation and propose to move diffusion from dense geometry to compact geometric primitives, representing each shape as a small set of superquadrics. Instead of operating on thousands to millions of geometric representation values, we leverage 7KB superquadric parameters (pose, size, and shape), drastically reducing diffusion-state dimensionality and per-step compute/memory. Our diffusion-over-superquadrics improves scalability by supporting broader capabilities (e.g., resolution-free point-cloud decoding, part-level editing, and constraint-based design) and achieving competitive surface-fidelity and distributional performance on standard benchmarks after point-cloud decoding, while enabling efficient generation within 0.6s per shape for most conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
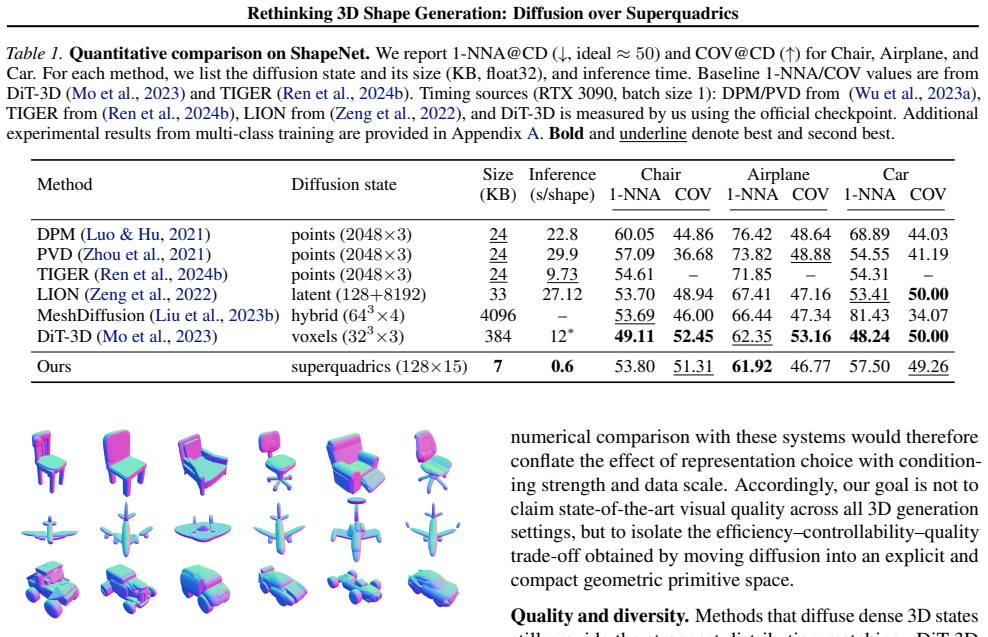
Summary. The manuscript proposes performing diffusion for 3D shape generation directly over the parameters of a small collection of superquadrics (pose, size, and shape parameters, totaling ~7 KB per shape) rather than dense representations such as voxels, SDFs, meshes, or point clouds. The approach claims to reduce diffusion-state dimensionality and per-step compute/memory, support resolution-free point-cloud decoding, part-level editing, and constraint-based design, achieve competitive surface-fidelity and distributional metrics on standard benchmarks after decoding, and enable generation in 0.6 s per shape.
Significance. If the empirical claims hold after addressing the noted gaps, the work would be significant as a representational shift that makes 3D diffusion more scalable and controllable by operating in a compact, structured primitive space. It demonstrates how geometric primitives can serve as an effective domain for generative modeling while preserving downstream capabilities such as editing.
major comments (2)
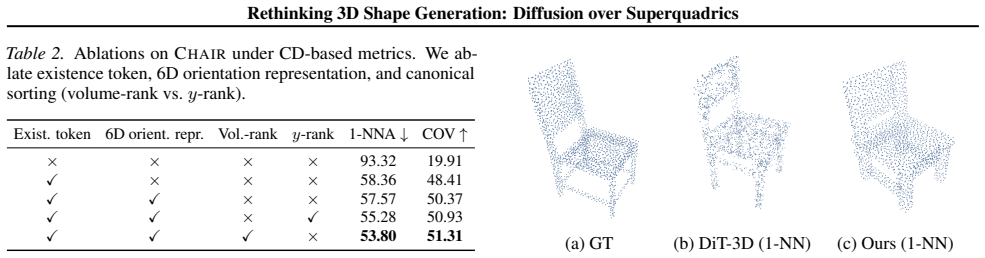
- [§3] §3 (Method, superquadric representation): No quantitative bound or distribution of reconstruction error is reported for the superquadric fitting step on the evaluation benchmarks. Without this, it remains unclear whether the superquadric family faithfully captures the geometric variety (topologies, fine details, non-convex parts) in the test distributions, which is load-bearing for the claim that diffusion in this 7 KB parameter space yields competitive post-decoding performance rather than an artifact of the decoder.
- [§4] §4 (Experiments): The abstract and method description assert competitive benchmark performance and efficiency gains, yet the manuscript supplies no explicit ablation on how fitting error propagates through the point-cloud decoder, nor tables comparing against dense-representation baselines with matching decoder fidelity. This weakens the central claim that the diffusion representation itself is adequate.
minor comments (2)
- [Abstract] The abstract would benefit from naming the specific benchmarks (e.g., ShapeNet categories) and reporting at least one key metric (e.g., CD or EMD) to ground the 'competitive' claim.
- [§3] Notation for the 7 KB parameter count should be clarified with an explicit breakdown (number of superquadrics × parameters per primitive) in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of operating diffusion in a compact superquadric parameter space. We address the two major comments point by point below. Where the comments identify missing analyses that would strengthen the manuscript, we commit to adding them in revision.
read point-by-point responses
-
Referee: [§3] §3 (Method, superquadric representation): No quantitative bound or distribution of reconstruction error is reported for the superquadric fitting step on the evaluation benchmarks. Without this, it remains unclear whether the superquadric family faithfully captures the geometric variety (topologies, fine details, non-convex parts) in the test distributions, which is load-bearing for the claim that diffusion in this 7 KB parameter space yields competitive post-decoding performance rather than an artifact of the decoder.
Authors: We agree that a quantitative characterization of superquadric fitting error on the evaluation sets is necessary to substantiate the representation's coverage. In the revised manuscript we will add a dedicated analysis (new table and figure) reporting the distribution of reconstruction errors—specifically mean, median, and standard deviation of Chamfer distance and normal consistency—between the fitted superquadric assemblies and the original ShapeNet meshes, broken down by category. This will directly quantify how well the ~7 KB parameter set captures the geometric variety present in the test distributions. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and method description assert competitive benchmark performance and efficiency gains, yet the manuscript supplies no explicit ablation on how fitting error propagates through the point-cloud decoder, nor tables comparing against dense-representation baselines with matching decoder fidelity. This weakens the central claim that the diffusion representation itself is adequate.
Authors: We acknowledge that an explicit ablation tracing fitting error through the decoder and side-by-side tables against dense baselines under matched decoder conditions would make the argument more robust. In revision we will insert (i) an ablation that injects controlled levels of fitting noise and measures the resulting change in final point-cloud metrics, and (ii) additional comparison rows that align decoder output resolution and sampling density with the dense baselines we already report. These additions will clarify that the observed competitiveness is not an artifact of the decoder alone. revision: yes
Circularity Check
No circularity; derivation is a direct representational substitution with independent evaluation
full rationale
The paper proposes replacing dense geometry (voxels, meshes, point clouds) with a compact superquadric parameter set for the diffusion state, then decoding to surfaces for evaluation. No equations, fitted parameters, or self-citations are described that would make reported performance or capabilities reduce to the inputs by construction. The approach is presented as an architectural change whose benefits (lower dimensionality, resolution-free decoding) are claimed to follow from the reduced state size, with competitive metrics treated as empirical outcomes on standard benchmarks rather than tautological results.
Axiom & Free-Parameter Ledger
axioms (1)
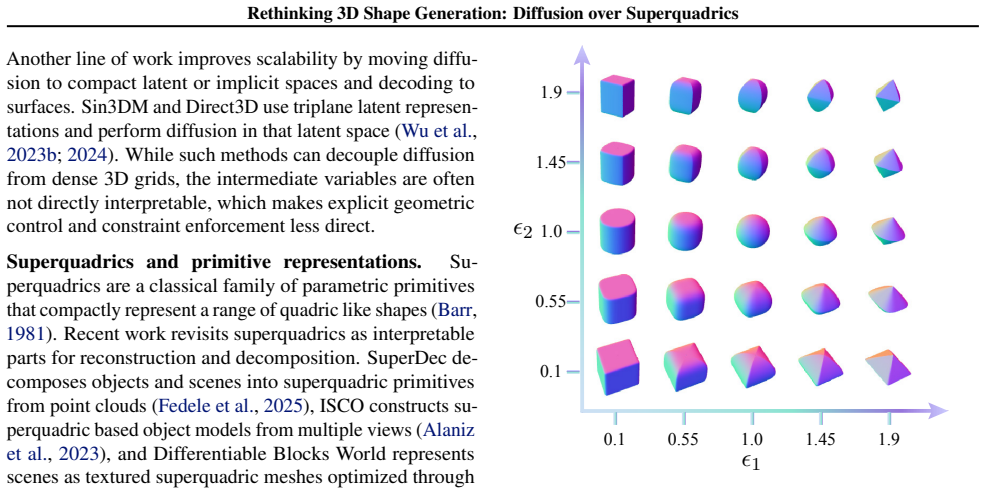
- domain assumption Superquadrics form a sufficiently expressive basis for the shapes appearing in standard 3D generation benchmarks
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[2]
arXiv preprint arXiv:2304.06648 , year=
DiffFit: Unlocking Transferability of Large Diffusion Models via Simple Parameter-Efficient Fine-Tuning , author=. arXiv preprint arXiv:2304.06648 , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
All are Worth Words: A ViT Backbone for Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[4]
International Conference on Machine Learning , pages=
One transformer fits all distributions in multi-modal diffusion at scale , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[5]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
3d shape generation and completion through point-voxel diffusion , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[6]
Advances in Neural Information Processing Systems , year=
LION: Latent Point Diffusion Models for 3D Shape Generation , author=. Advances in Neural Information Processing Systems , year=
-
[7]
Proceedings of Advances In Neural Information Processing Systems (NeurIPS) , year=
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images , author=. Proceedings of Advances In Neural Information Processing Systems (NeurIPS) , year=
-
[8]
arXiv preprint arXiv:2303.08133 , year=
Meshdiffusion: Score-based generative 3d mesh modeling , author=. arXiv preprint arXiv:2303.08133 , year=
-
[9]
2022 , journal=
3D-LDM: Neural Implicit 3D Shape Generation with Latent Diffusion Models , author=. 2022 , journal=
2022
-
[10]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[11]
ArXiv , year =
Denoising Diffusion Implicit Models , author =. ArXiv , year =
-
[12]
2021 , journal=
Image Super-Resolution via Iterative Refinement , author=. 2021 , journal=
2021
-
[13]
2022 , journal=
Imagen Video: High Definition Video Generation with Diffusion Models , author=. 2022 , journal=
2022
-
[14]
Proceedings of International Conference on Learning Representations (ICLR) , year=
DiffWave: A Versatile Diffusion Model for Audio Synthesis , author=. Proceedings of International Conference on Learning Representations (ICLR) , year=
-
[15]
2022 , journal=
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , author=. 2022 , journal=
2022
-
[16]
ShapeNet: An Information-Rich 3D Model Repository
Shapenet: An information-rich 3d model repository , author=. arXiv preprint arXiv:1512.03012 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
Exploring Plain Vision Transformer Backbones for Object Detection , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[18]
and Li, Kai and Li Fei-Fei , TITLE =
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia. and Li, Kai and Li Fei-Fei , TITLE =. Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[19]
Kingma, Diederik P and Ba, Jimmy , journal=
-
[20]
Proceedings of International Conference on Learning Representations (ICLR) , year =
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. Proceedings of International Conference on Learning Representations (ICLR) , year =
-
[21]
Adam Paszke and Sam Gross and Francisco Massa and Adam Lerer and James Bradbury and Gregory Chanan and Trevor Killeen and Zeming Lin and Natalia Gimelshein and Luca Antiga and Alban Desmaison and Andreas Kopf and Edward Yang and Zachary DeVito and Martin Raison and Alykhan Tejani and Sasank Chilamkurthy and Benoit Steiner and Lu Fang and Junjie Bai and So...
-
[22]
2018 , booktitle=
Learning Representations and Generative Models for 3D Point Clouds , author=. 2018 , booktitle=
2018
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
Yang, Guandao and Huang, Xun and Hao, Zekun and Liu, Ming-Yu and Belongie, Serge and Hariharan, Bharath , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
-
[24]
Proceedings of Advances in Neural Information Processing Systems (NeurIPS) , year=
SoftFlow: Probabilistic Framework for Normalizing Flow on Manifolds , author=. Proceedings of Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Kim, Jinwoo and Yoo, Jaehoon and Lee, Juho and Hong, Seunghoon , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[26]
2020 , booktitle=
Klokov, Roman and Boyer, Edmond and Verbeek, Jakob , title =. 2020 , booktitle=
2020
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Diffusion probabilistic models for 3d point cloud generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
2020 , booktitle=
Learning Gradient Fields for Shape Generation , author=. 2020 , booktitle=
2020
-
[29]
2018 , booktitle=
Multiresolution Tree Networks for 3D Point Cloud Processing , author=. 2018 , booktitle=
2018
-
[30]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Yang, Yaoqing and Feng, Chen and Shen, Yiru and Tian, Dong , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[31]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Li, Muheng and Duan, Yueqi and Zhou, Jie and Lu, Jiwen , title=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[32]
Proceedings of Advances in Neural Information Processing Systems (NeurIPS) , year=
Point-Voxel CNN for Efficient 3D Deep Learning , author=. Proceedings of Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
Shu, Dong Wook and Park, Sung Woo and Kwon, Junseok , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
-
[35]
Proceedings of International Conference on Learning Representations (ICLR) , year=
Learning Localized Generative Models for 3D Point Clouds via Graph Convolution , author=. Proceedings of International Conference on Learning Representations (ICLR) , year=
-
[36]
and Russell, Bryan C
Groueix, Thibault and Fisher, Matthew and Kim, Vladimir G. and Russell, Bryan C. and Aubry, Mathieu , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[37]
, title =
Fan, Haoqiang and Su, Hao and Guibas, Leonidas J. , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[38]
Proceedings of IEEE Winter Conference on Applications of Computer Vision (WACV) , year=
DeformNet: Free-Form Deformation Network for 3D Shape Reconstruction from a Single Image , author=. Proceedings of IEEE Winter Conference on Applications of Computer Vision (WACV) , year=
-
[39]
2023 , journal=
DiffComplete: Diffusion-based Generative 3D Shape Completion , author=. 2023 , journal=
2023
-
[40]
Advances in neural information processing systems , volume=
Dit-3d: Exploring plain diffusion transformers for 3d shape generation , author=. Advances in neural information processing systems , volume=
-
[41]
European Conference on Computer Vision , pages=
TetraDiffusion: Tetrahedral diffusion models for 3D shape generation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[42]
Computer Graphics Forum , volume=
OctFusion: Octree-based Diffusion Models for 3D Shape Generation , author=. Computer Graphics Forum , volume=. 2025 , organization=
2025
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[44]
Advances in Neural Information Processing Systems , volume=
Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
arXiv preprint arXiv:2405.00998 , year =
Part-aware Shape Generation with Latent 3D Diffusion of Neural Voxel Fields , author =. arXiv preprint arXiv:2405.00998 , year =. doi:10.48550/arXiv.2405.00998 , url =. 2405.00998 , archivePrefix =
-
[46]
Computational Visual Media , volume=
Diffusion models for 3D generation: A survey , author=. Computational Visual Media , volume=. 2025 , publisher=
2025
-
[47]
arXiv preprint arXiv:2504.00992 , year=
Superdec: 3d scene decomposition with superquadric primitives , author=. arXiv preprint arXiv:2504.00992 , year=
-
[48]
arXiv preprint arXiv:2506.10977 , year=
QuadricFormer: Scene as Superquadrics for 3D Semantic Occupancy Prediction , author=. arXiv preprint arXiv:2506.10977 , year=
-
[49]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
On the continuity of rotation representations in neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[50]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Point-e: A system for generating 3d point clouds from complex prompts , author=. arXiv preprint arXiv:2212.08751 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
arXiv preprint arXiv:2305.15399 , year=
Sin3dm: Learning a diffusion model from a single 3d textured shape , author=. arXiv preprint arXiv:2305.15399 , year=
-
[52]
IEEE Computer graphics and Applications , volume=
Superquadrics and angle-preserving transformations , author=. IEEE Computer graphics and Applications , volume=. 1981 , publisher=
1981
-
[53]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Iterative superquadric recomposition of 3d objects from multiple views , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[54]
Advances in Neural Information Processing Systems , volume=
Differentiable blocks world: Qualitative 3d decomposition by rendering primitives , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
2000 , publisher=
Segmentation and recovery of superquadrics , author=. 2000 , publisher=
2000
-
[56]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[57]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Robust and accurate superquadric recovery: A probabilistic approach , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[59]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Diffusion posterior sampling for general noisy inverse problems , author=. arXiv preprint arXiv:2209.14687 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Marching-primitives: Shape abstraction from signed distance function , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
On the Continuity of Rotation Representations in Neural Networks , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[62]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Fast point cloud generation with straight flows , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[63]
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , year=
QuickFPS: Architecture and Algorithm Co-Design for Farthest Point Sampling in Large-Scale Point Clouds , author=. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , year=
-
[64]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
TIGER: Time-varying denoising model for 3D point cloud generation with diffusion process , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[65]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[66]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[67]
M. J. Kearns , title =
-
[68]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[69]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[70]
Suppressed for Anonymity , author=
-
[71]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[72]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
On the Continuity of Rotation Representations in Neural Networks , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =. doi:10.1109/CVPR.2019.00589 , eprint =
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
TIGER: Time-Varying Denoising Model for 3D Point Cloud Generation with Diffusion Process , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.