ChinaHeritaQA: A Culturally-Grounded Visual Question Answering Dataset for World Heritage Sites in China
Pith reviewed 2026-06-27 17:15 UTC · model grok-4.3
The pith
ChinaHeritaQA shows vision-language models beat humans on average for Chinese heritage questions but fail on culturally grounded reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
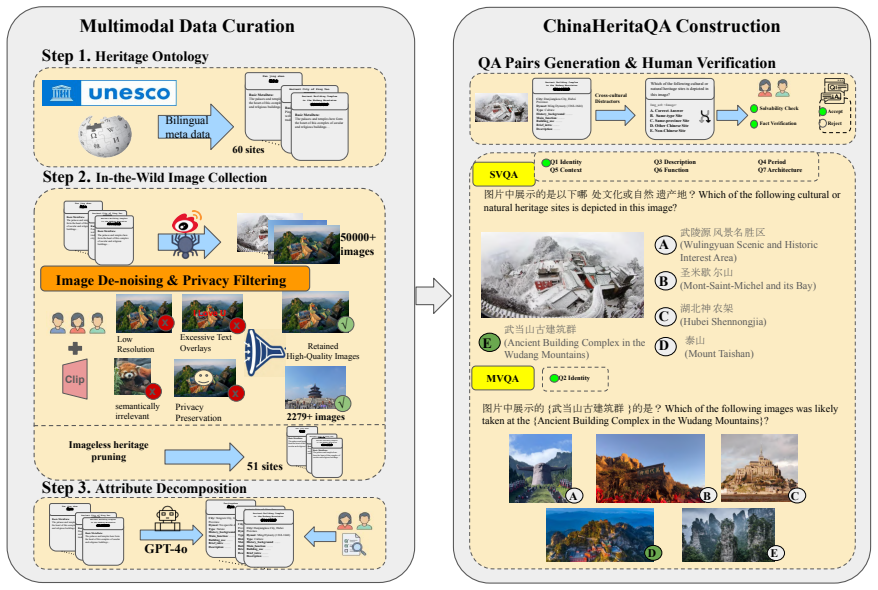
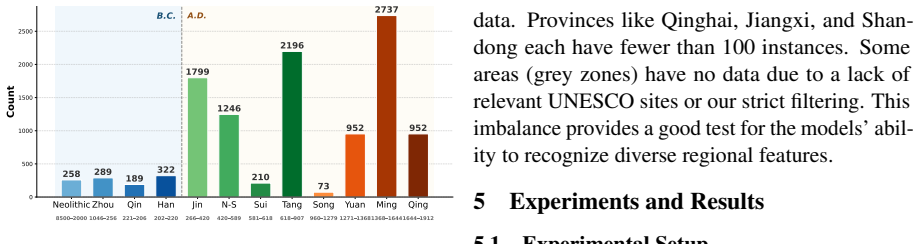
ChinaHeritaQA is a multimodal benchmark dataset for evaluating the cultural reasoning abilities of vision-language models on UNESCO World Heritage sites in China. The dataset comprises 2,279 in-the-wild images paired with 14,133 bilingual multiple-choice QA pairs spanning seven cognitive dimensions, from basic identity recognition to historical periodization and architectural analysis. Guided by a UNESCO-aligned heritage ontology and verified through rigorous human annotation, the dataset ensures linguistic quality and factual consistency. Evaluations of state-of-the-art VLMs reveal that while top models exceed human performance on average, substantial task-level variation emerges: models ex
What carries the argument
The ChinaHeritaQA dataset, which supplies images of heritage sites together with multiple-choice questions across seven cognitive dimensions created via a UNESCO-aligned ontology and human verification.
If this is right
- State-of-the-art vision-language models exceed average human performance on the overall benchmark.
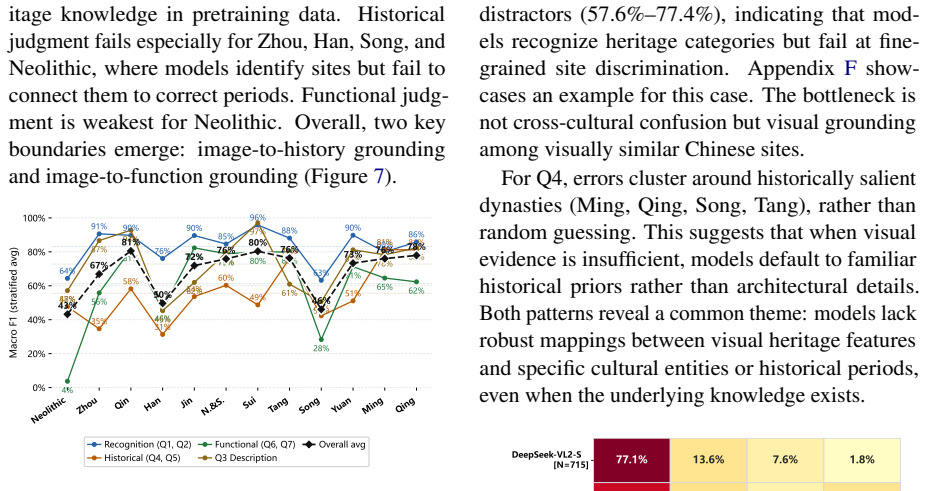
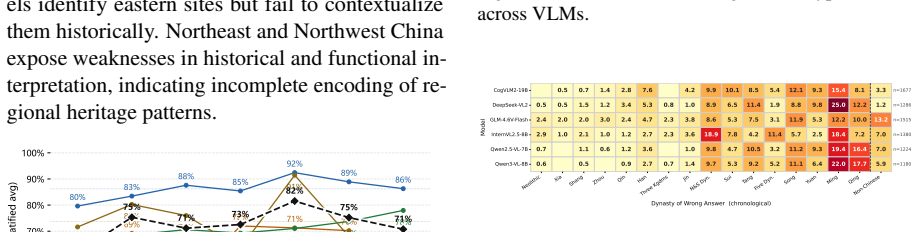
- Models perform strongly on visual recognition questions but weakly on questions that require cultural and historical reasoning.
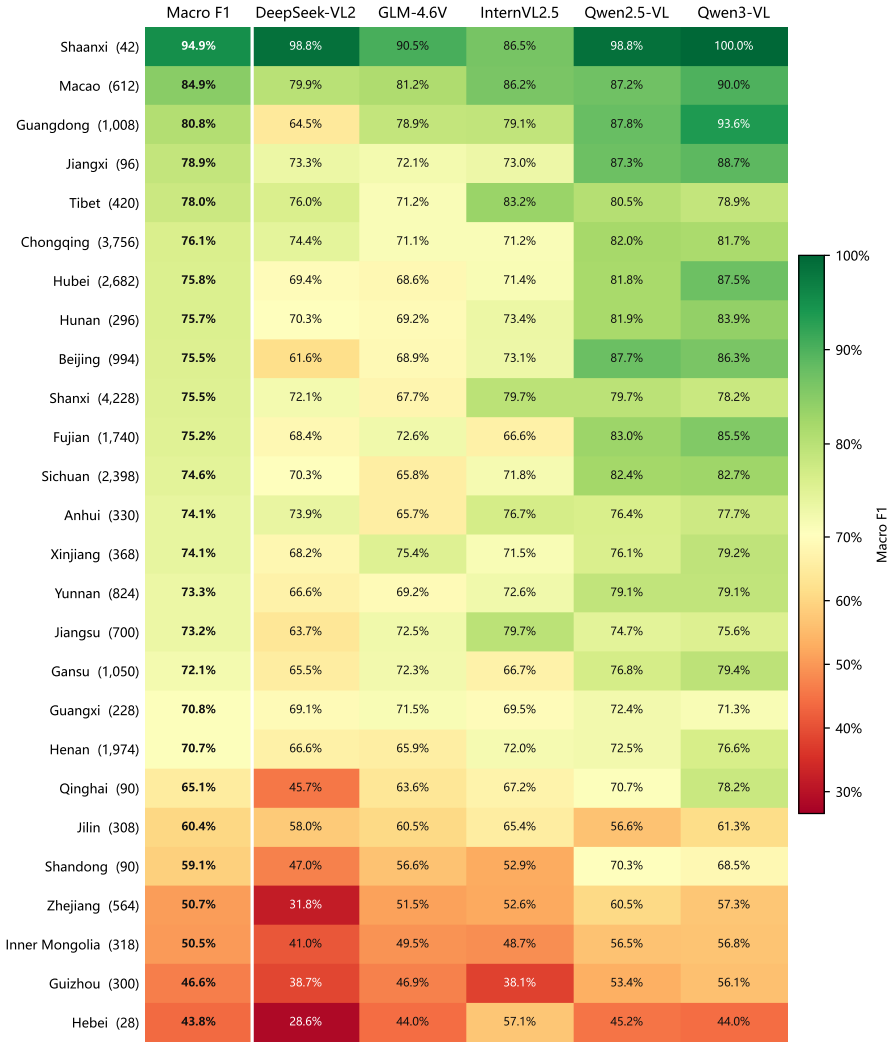
- Model accuracy varies by the dynasty and geographic region of the heritage sites.
- Strong performance on visual retrieval tasks does not carry over to cultural and historical understanding tasks.
Where Pith is reading between the lines
- The dataset could serve as a template for creating similar benchmarks focused on heritage sites in other countries to test whether the same visual-versus-cultural gap appears elsewhere.
- Training approaches that add explicit historical timelines or regional context might close the observed performance gap on dynasty-specific questions.
- The variation across dynasties suggests that models may need separate handling of temporal cultural shifts rather than treating all heritage content uniformly.
Load-bearing premise
The 14,133 QA pairs accurately and consistently measure culturally grounded reasoning without introducing annotator bias or factual inconsistencies.
What would settle it
A re-annotation round by independent cultural experts that produces substantially different ground-truth answers on the historical periodization or architectural analysis questions would show the dataset does not reliably measure cultural reasoning.
Figures













read the original abstract
We introduce ChinaHeritaQA, a multimodal benchmark dataset for evaluating the cultural reasoning abilities of vision-language models (VLMs) on UNESCO World Heritage sites in China. The dataset comprises 2,279 in-the-wild images paired with 14,133 bilingual (Chinese/English) multiple-choice QA pairs spanning seven cognitive dimensions, from basic identity recognition to historical periodization and architectural analysis. Guided by a UNESCO-aligned heritage ontology and verified through rigorous human annotation, the dataset ensures linguistic quality and factual consistency. Evaluations of state-of-the-art VLMs reveal that while top models exceed human performance on average, substantial task-level variation emerges: models excel at visual recognition but struggle with culturally grounded reasoning. Performance also varies by dynasty and region. ChinaHeritaQA reveals that strong visual retrieval does not extend to cultural and historical understanding. We release the dataset to support future research on culturally aware multimodal learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChinaHeritaQA, a multimodal VQA benchmark with 2,279 in-the-wild images of Chinese UNESCO World Heritage sites paired with 14,133 bilingual (Chinese/English) multiple-choice QA pairs spanning seven cognitive dimensions from basic recognition to historical periodization and architectural analysis. Constructed via a UNESCO-aligned heritage ontology and human annotation, the dataset is used to evaluate state-of-the-art VLMs, which are reported to exceed average human performance yet exhibit substantial task-level variation, excelling at visual recognition but struggling with culturally grounded reasoning, with further variation by dynasty and region.
Significance. If the dataset construction and evaluation hold, the work supplies a needed resource for probing cultural and historical reasoning gaps in VLMs beyond visual retrieval, with potential to guide development of more culturally aware multimodal models. The bilingual design and ontology grounding are positive features for cross-lingual and heritage-specific evaluation.
major comments (2)
- [dataset construction and annotation description] The abstract and dataset description claim the 14,133 QA pairs were 'verified through rigorous human annotation' ensuring 'linguistic quality and factual consistency,' yet no inter-annotator agreement scores, error rates, or validation statistics are supplied. This directly affects the central claim that the benchmark isolates culturally grounded reasoning from visual recognition and annotator bias.
- [evaluation and results section] The headline evaluation result (top models exceed humans on average but fail on cultural reasoning, with dynasty/region variation) rests on the assumption that the seven cognitive dimensions and UNESCO ontology operationalize cultural nuance without systematic factual drift or regional skew in the bilingual items; no error analysis or ontology breakdown is provided to support this separation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on ChinaHeritaQA. The comments highlight important aspects of dataset validation and evaluation that we will address in the revision. Below we respond point by point.
read point-by-point responses
-
Referee: The abstract and dataset description claim the 14,133 QA pairs were 'verified through rigorous human annotation' ensuring 'linguistic quality and factual consistency,' yet no inter-annotator agreement scores, error rates, or validation statistics are supplied. This directly affects the central claim that the benchmark isolates culturally grounded reasoning from visual recognition and annotator bias.
Authors: We agree that quantitative validation statistics strengthen the claims. The manuscript describes a multi-stage annotation process with heritage experts and consensus resolution, but does not report agreement metrics. In the revised version we will add an appendix with inter-annotator agreement (Cohen's kappa) computed from retained annotation logs, error rates from the verification stage, and a breakdown of resolved disagreements. This addition will directly support the isolation of cultural reasoning from annotator effects. revision: yes
-
Referee: The headline evaluation result (top models exceed humans on average but fail on cultural reasoning, with dynasty/region variation) rests on the assumption that the seven cognitive dimensions and UNESCO ontology operationalize cultural nuance without systematic factual drift or regional skew in the bilingual items; no error analysis or ontology breakdown is provided to support this separation.
Authors: We accept that an explicit error analysis and ontology distribution would better substantiate the separation of visual versus cultural reasoning. The current results section reports aggregate and per-dimension scores plus dynasty/region variation, but lacks per-ontology breakdowns and qualitative error examples. The revised manuscript will include (1) a table showing question distribution across the UNESCO-aligned ontology categories and (2) a qualitative error analysis highlighting cases where models succeed on recognition but fail on historical or architectural reasoning. These additions will clarify the operationalization of cultural nuance. revision: yes
Circularity Check
No circularity: dataset creation and empirical evaluation only
full rationale
The paper introduces a new VQA dataset (ChinaHeritaQA) with 2,279 images and 14,133 QA pairs, describes its construction via a UNESCO-aligned ontology and human annotation, and reports empirical VLM evaluations. No mathematical derivations, fitted parameters, predictions, or uniqueness theorems appear. All load-bearing claims rest on the dataset itself and external model benchmarks rather than reducing to self-citations or input quantities by construction. This matches the default non-circular case for dataset papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Yutong, Wang and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and Rzayev, Anar and Das, Anirban and Pramodya, Ashmari and Adila, Aulia and Wilie, Bryan and Mawalim, Candy Olivia and Lam, Cheng Ching and...
-
[2]
F oodie QA : A Multimodal Dataset for Fine-Grained Understanding of C hinese Food Culture
Li, Wenyan and Zhang, Crystina and Li, Jiaang and Peng, Qiwei and Tang, Raphael and Zhou, Li and Zhang, Weijia and Hu, Guimin and Yuan, Yifei and S gaard, Anders and Hershcovich, Daniel and Elliott, Desmond. F oodie QA : A Multimodal Dataset for Fine-Grained Understanding of C hinese Food Culture. Proceedings of the 2024 Conference on Empirical Methods in...
-
[3]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
CVLUE: A New Benchmark Dataset for Chinese Vision-Language Understanding Evaluation , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i8.32884 , abstractNote=
-
[4]
Seeing Culture: A Benchmark for Visual Reasoning and Grounding
Satar, Burak and Ma, Zhixin and Irawan, Patrick Amadeus and Mulyawan, Wilfried Ariel and Jiang, Jing and Lim, Ee-Peng and Ngo, Chong-Wah. Seeing Culture: A Benchmark for Visual Reasoning and Grounding. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1131
-
[5]
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and Chen, Kai and Lin, Dahua , title =. 2024 , isbn =. doi:10.1007/978-3-031-72658-3_13 , booktitle =
-
[6]
Visually Grounded Reasoning across Languages and Cultures
Liu, Fangyu and Bugliarello, Emanuele and Ponti, Edoardo Maria and Reddy, Siva and Collier, Nigel and Elliott, Desmond. Visually Grounded Reasoning across Languages and Cultures. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.818
-
[7]
Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning
Yin, Da and Li, Liunian Harold and Hu, Ziniu and Peng, Nanyun and Chang, Kai-Wei. Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.162
-
[8]
Stefanini, Matteo and Cornia, Marcella and Baraldi, Lorenzo and Corsini, Massimiliano and Cucchiara, Rita , title =. Image Analysis and Processing – ICIAP 2019: 20th International Conference, Trento, Italy, September 9–13, 2019, Proceedings, Part II , pages =. 2019 , isbn =. doi:10.1007/978-3-030-30645-8_66 , abstract =
-
[9]
2015 , eprint=
Microsoft COCO: Common Objects in Context , author=. 2015 , eprint=
2015
-
[10]
Goyal, Yash and Khot, Tejas and Agrawal, Aishwarya and Summers-Stay, Douglas and Batra, Dhruv and Parikh, Devi , title =. 2019 , issue_date =. doi:10.1007/s11263-018-1116-0 , journal =
-
[11]
2025 , url=
Chaoyou Fu and Peixian Chen and Yunhang Shen and Yulei Qin and Mengdan Zhang and Xu Lin and Jinrui Yang and Xiawu Zheng and Ke Li and Xing Sun and Yunsheng Wu and Rongrong Ji and Caifeng Shan and Ran He , booktitle=. 2025 , url=
2025
-
[12]
2023 , eprint=
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension , author=. 2023 , eprint=
2023
-
[13]
2024 , eprint=
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark , author=. 2024 , eprint=
2024
-
[14]
MMBench: Is Your Multi-modal Model an All-around Player? , year =
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, Dahua Lin , journal =. MMBench: Is Your Multi-modal Model an All-around Player? , year =
-
[15]
Hanfu-Bench: A Multimodal Benchmark on Cross-Temporal Cultural Understanding and Transcreation
Zhou, Li and Yu, Lutong and Xie, Dongchu and Cheng, Shaohuan and Li, Wenyan and Li, Haizhou. Hanfu-Bench: A Multimodal Benchmark on Cross-Temporal Cultural Understanding and Transcreation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1251
-
[16]
Recontextualizing Revitalization: A Mixed Media Approach to Reviving the N
Yang, Ivory and Guo, Xiaobo and Wang, Yuxin and Zhang, Hefan and Jia, Yaning and Dinauer, William and Vosoughi, Soroush. Recontextualizing Revitalization: A Mixed Media Approach to Reviving the N. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.627
-
[17]
2024 , eprint=
CogVLM2: Visual Language Models for Image and Video Understanding , author=. 2024 , eprint=
2024
-
[18]
2024 , eprint=
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks , author=. 2024 , eprint=
2024
-
[20]
2026 , eprint=
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. 2026 , eprint=
2026
-
[21]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
doi: 10.18653/v1/2020.emnlp-demos.6
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[24]
Advances in Neural Information Processing Systems 32 , pages =
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author =. Advances in Neural Information Processing Systems 32 , pages =. 2019 , publisher =
2019
-
[25]
2003 , publisher=
Heritage Tourism , author=. 2003 , publisher=
2003
-
[26]
2011 , publisher=
The Tourist Gaze 3.0 , author=. 2011 , publisher=
2011
-
[27]
Cultural tourism: A review of recent research and trends , journal =
Greg Richards , keywords =. Cultural tourism: A review of recent research and trends , journal =. 2018 , issn =. doi:https://doi.org/10.1016/j.jhtm.2018.03.005 , url =
-
[28]
Whither scenic beauty? Visual landscape quality assessment in the 21st century , journal =
Terry C Daniel , keywords =. Whither scenic beauty? Visual landscape quality assessment in the 21st century , journal =. 2001 , note =. doi:https://doi.org/10.1016/S0169-2046(01)00141-4 , url =
-
[29]
2012 , publisher=
Heritage and Social Media:. 2012 , publisher=
2012
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and Wei, Cong and Yu, Botao and Yuan, Ruibin and Sun, Renliang and Yin, Ming and Zheng, Boyuan and Yang, Zhenzhu and Liu, Yibo and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu , title =...
2024
-
[31]
MMMU -Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Yue, Xiang and Zheng, Tianyu and Ni, Yuansheng and Wang, Yubo and Zhang, Kai and Tong, Shengbang and Sun, Yuxuan and Yu, Botao and Zhang, Ge and Sun, Huan and Su, Yu and Chen, Wenhu and Neubig, Graham. MMMU -Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark. Proceedings of the 63rd Annual Meeting of the Association for Computational L...
-
[32]
CultureLLM: Incorporating Cultural Differences into Large Language Models , url =
Li, Cheng and Chen, Mengzhuo and Wang, Jindong and Sitaram, Sunayana and Xie, Xing , booktitle =. CultureLLM: Incorporating Cultural Differences into Large Language Models , url =. doi:10.52202/079017-2693 , editor =
-
[33]
Challenges and Strategies in Cross-Cultural
Hershcovich, Daniel and Frank, Stella and Lent, Heather and de Lhoneux, Miryam and Abdou, Mostafa and Brandl, Stephanie and Bugliarello, Emanuele and Cabello Piqueras, Laura and Chalkidis, Ilias and Cui, Ruixiang and Fierro, Constanza and Margatina, Katerina and Rust, Phillip and S gaard, Anders. Challenges and Strategies in Cross-Cultural NLP. Proceeding...
-
[34]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[35]
Towards Cross-Modal Retrieval in Chinese Cultural Heritage Documents: Dataset and Solution
Yuan, Junyi and Zhang, Jian and Wu, Fangyu and Lu, Huanda and Lu, Dongming and Wang, Qiufeng. Towards Cross-Modal Retrieval in Chinese Cultural Heritage Documents: Dataset and Solution. Document Analysis and Recognition -- ICDAR 2025. 2026
2025
-
[36]
2026 , eprint=
VULCA-Bench: A Multicultural Vision-Language Benchmark for Evaluating Cultural Understanding , author=. 2026 , eprint=
2026
-
[37]
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark , url =
Romero, David and Lyu, Chenyang and Wibowo, Haryo Akbarianto and Lynn, Teresa and Hamed, Injy and Kishore, Aditya Nanda and Mandal, Aishik and Dragonetti, Alina and Abzaliev, Artem and Tonja, Atnafu Lambebo and Balcha, Bontu Fufa and Whitehouse, Chenxi and Salamea, Christian and Velasco, Dan John and Adelani, David Ifeoluwa and Le Meur, David and Villa-Cu...
-
[38]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.