EPS3D: End-to-End Feed-Forward 3D Panoptic Segmentation
Pith reviewed 2026-06-27 17:13 UTC · model grok-4.3
The pith
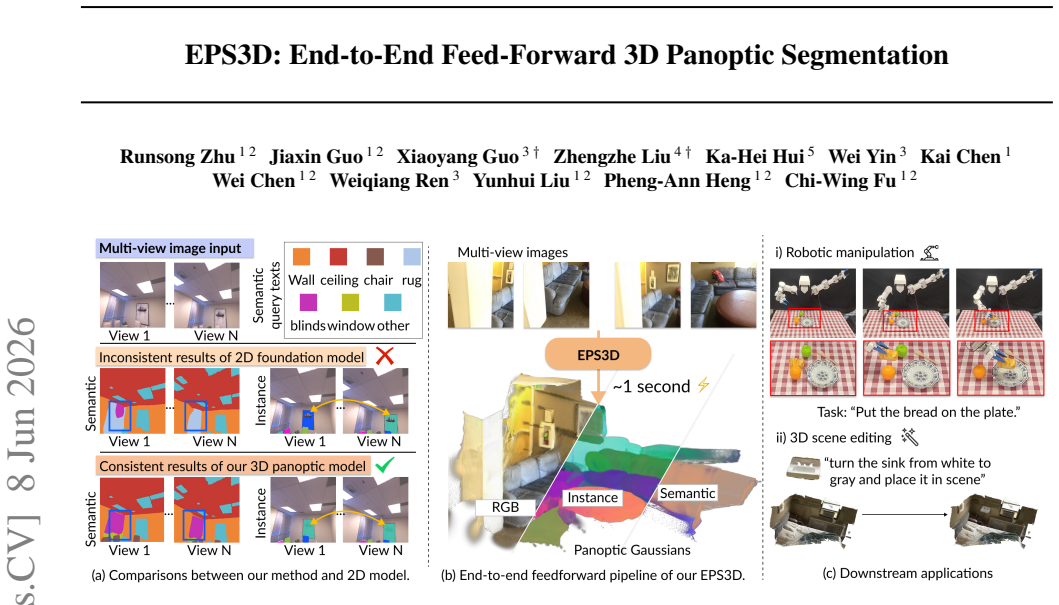
EPS3D performs open-vocabulary 3D panoptic segmentation end-to-end from multi-view images via distillation training and mutual semantic-instance enhancement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
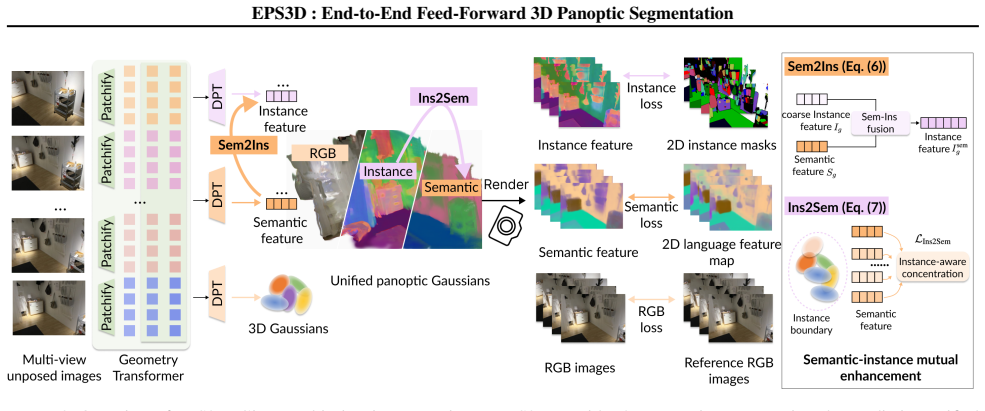
EPS3D is an end-to-end architecture that trains on diverse 3D scenes with a distillation objective to extract 3D-aware semantic and instance features from multi-view images, then applies a mutual enhancement module (Ins2Sem and Sem2Ins) to enforce inherent semantic-instance consistency, yielding higher benchmark scores than prior methods while running at roughly one second per scene.
What carries the argument
Mutual enhancement module (Ins2Sem alignment of semantics within instances plus Sem2Ins refinement of instance features by semantic guidance) together with the distillation-based training strategy.
If this is right
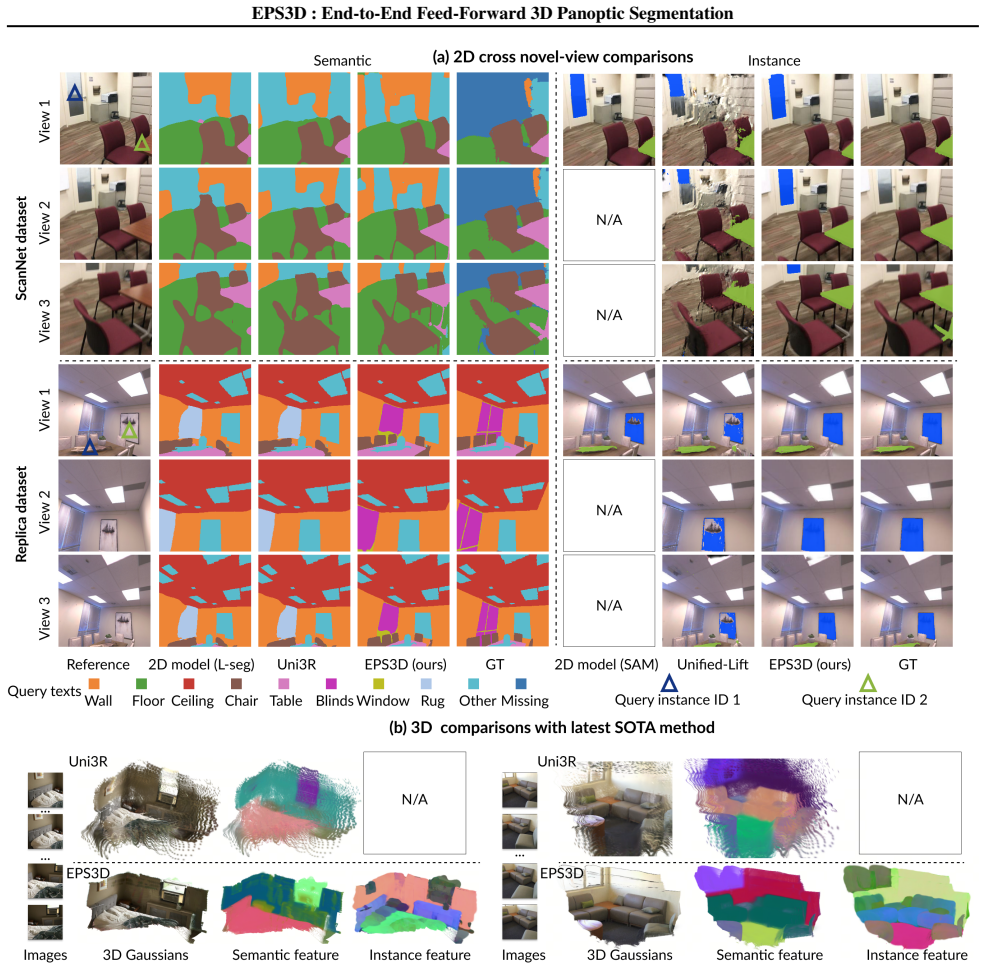
- Outperforms prior methods by +13 percent mIoU on semantics for the Replica benchmark.
- Runs at approximately one second per scene, supporting real-time downstream uses.
- Produces inherent semantic-instance consistency that improves 3D scene understanding.
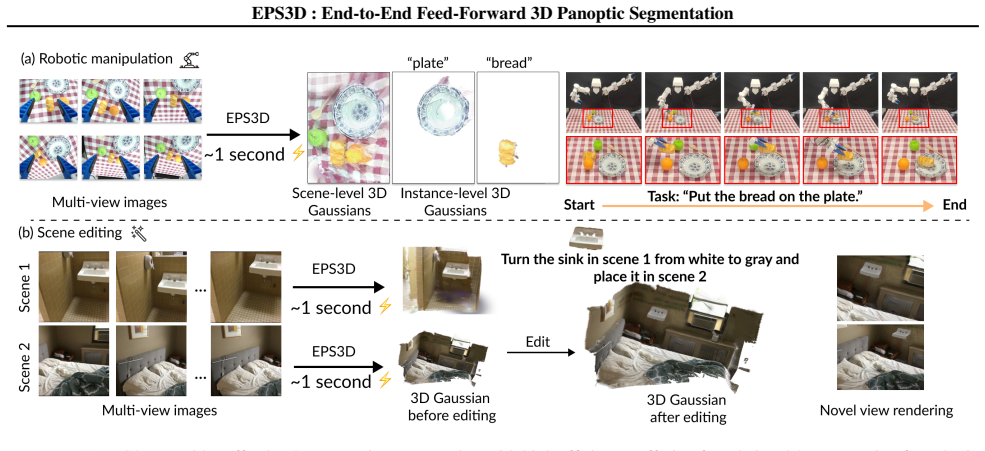
- Enables direct application to robotic manipulation and 3D scene editing without extra lifting steps.
Where Pith is reading between the lines
- The removal of explicit preprocessing stages could simplify integration into live multi-view capture systems.
- Open-vocabulary output may allow the same trained model to label novel object categories encountered after deployment.
- The same distillation-plus-mutual-enhancement pattern could be tested on related tasks such as 3D instance tracking or dense reconstruction.
Load-bearing premise
Distillation training on diverse 3D scenes plus the mutual enhancement steps are sufficient to produce 3D-aware features and semantic-instance consistency without any preprocessing pipeline.
What would settle it
An ablation on Replica or ScanNet that removes the mutual enhancement module and still reports the same +13 percent mIoU gain, or a preprocessing pipeline that matches EPS3D accuracy and consistency metrics on the same test scenes.
Figures


read the original abstract
This paper introduces EPS3D, a new end-to-end feed-forward framework for open-vocabulary 3D panoptic segmentation. Unlike existing methods relying on additional preprocessing, we design an end-to-end architecture, with a distillation-based training strategy on diverse 3D scenes to predict 3D-aware semantic and instance features from multi-view images, improving 3D consistency and avoiding error accumulation. We further propose a mutual enhancement module to enforce inherent semantic-instance consistency. By aligning semantics within instances (Ins2Sem) and refining instance features with semantic guidance (Sem2Ins), we achieve more coherent 3D scene understanding. Ultimately, EPS3D outperforms SOTA baselines on two benchmarks (e.g., +13% mIoU for semantics on Replica) with high efficiency (e.g., 1s per scene), supporting tasks like robotic manipulation and 3D scene editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces EPS3D, an end-to-end feed-forward framework for open-vocabulary 3D panoptic segmentation. It proposes a distillation-based training strategy on diverse 3D scenes to predict 3D-aware semantic and instance features from multi-view images, and a mutual enhancement module (Ins2Sem and Sem2Ins) to enforce semantic-instance consistency. The method is claimed to outperform state-of-the-art baselines on two benchmarks, such as achieving +13% mIoU for semantics on Replica, while operating at high efficiency (1s per scene).
Significance. If the reported performance gains and efficiency are confirmed through rigorous experiments, this work could significantly impact the field by providing a preprocessing-free approach to 3D panoptic segmentation, facilitating applications in robotics and 3D scene editing. The mutual enhancement module addresses an important consistency issue in panoptic segmentation.
major comments (2)
- [Abstract] Abstract: The central claims of outperformance (+13% mIoU) and efficiency (1s per scene) are made without reference to any experimental results, tables, ablation studies, or error analysis in the provided manuscript text. This absence makes it impossible to verify the contribution of the proposed distillation strategy or the mutual enhancement module.
- [Abstract] Abstract: No details are provided on the specific benchmarks, the SOTA baselines compared against, the evaluation protocol, or how the open-vocabulary aspect is handled, which are load-bearing for the significance of the results.
minor comments (1)
- [Abstract] Abstract: The term 'diverse 3D scenes' is used without specifying the source or characteristics of the training data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments focus on improving the abstract's clarity and verifiability, which we address point-by-point below. We agree that strengthening the abstract will better highlight the experimental support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of outperformance (+13% mIoU) and efficiency (1s per scene) are made without reference to any experimental results, tables, ablation studies, or error analysis in the provided manuscript text. This absence makes it impossible to verify the contribution of the proposed distillation strategy or the mutual enhancement module.
Authors: We agree that the abstract, as a high-level summary, would benefit from explicit pointers to the supporting experiments. The full manuscript includes these details in the Experiments section, with quantitative results in tables, ablations on the distillation and mutual enhancement components, and runtime analysis. We will revise the abstract to add references such as 'as demonstrated in Tables 2 and 3' and 'detailed in Section 4' to make the claims directly traceable. revision: yes
-
Referee: [Abstract] Abstract: No details are provided on the specific benchmarks, the SOTA baselines compared against, the evaluation protocol, or how the open-vocabulary aspect is handled, which are load-bearing for the significance of the results.
Authors: The abstract provides a concise overview and already references one benchmark (Replica) along with the open-vocabulary setting. However, we acknowledge that additional specificity would improve accessibility. The manuscript body details the two benchmarks, compared SOTA methods, evaluation metrics/protocol, and open-vocabulary handling via the distillation strategy. We will revise the abstract to briefly incorporate these elements (e.g., naming the second benchmark and noting the open-vocabulary mechanism) while respecting length limits, or ensure the introduction expands on them for context. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical end-to-end neural architecture for 3D panoptic segmentation trained via distillation on diverse scenes plus a mutual enhancement module (Ins2Sem/Sem2Ins). No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims rest on reported benchmark improvements (+13% mIoU, 1s/scene) treated as experimental outcomes rather than derivations that reduce to their own inputs by construction. This is the expected non-finding for an applied CV architecture paper whose load-bearing elements are architectural choices and training procedures, not mathematical self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2312.00860v1. Charatan, D., Li, S. L., Tagliasacchi, A., and Sitzmann, V . pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 19457–19467,
-
[2]
Chen, Y ., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.-J., and Cai, J
doi: 10.1126/scirobotics.aea2092. Chen, Y ., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.-J., and Cai, J. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In European Conference on Computer Vision, pp. 370–386. Springer,
-
[3]
Longstream: Long-sequence streaming autoregressive visual geometry.arXiv preprint arXiv:2602.13172,
Cheng, C., Chen, X., Xie, T., Yin, W., Ren, W., Zhang, Q., Guo, X., and Wang, H. Longstream: Long-sequence streaming autoregressive visual geometry.arXiv preprint arXiv:2602.13172,
-
[4]
Deng, J., Li, H., Xie, T., Ren, W., Zhang, Q., Tan, P., and Guo, X. Sail-recon: Large sfm by augment- ing scene regression with localization.arXiv preprint arXiv:2508.17972,
-
[5]
Engelmann, F., Manhardt, F., Niemeyer, M., Tateno, K., Pollefeys, M., and Tombari, F. Opennerf: open set 3d neural scene segmentation with pixel-wise features and rendered novel views.arXiv preprint arXiv:2404.03650,
-
[6]
Guo, J., Ma, X., Fan, Y ., Liu, H., and Li, Q. Semantic gaussians: Open-vocabulary scene understanding with 3d gaussian splatting.arXiv preprint arXiv:2403.15624,
-
[7]
Guo, J., Guan, T., Dong, W., Zheng, W., Wang, W., Wang, Y ., Yam, Y ., and Liu, Y .-H. Salon3r: Structure-aware long-term generalizable 3d reconstruction from unposed images.arXiv preprint arXiv:2510.15072,
-
[8]
Hu, J., Hui, K.-H., Liu, Z., Li, R., and Fu, C.-W. Neural wavelet-domain diffusion for 3d shape generation, inver- sion, and manipulation.ACM Transactions on Graphics (TOG), 42(6), 2024a. Hu, J., Hui, K.-H., Liu, Z., Zhang, H., and Fu, C.-W. Cns- edit: 3d shape editing via coupled neural shape optimiza- tion. InProceedings of SIGGRAPH, pp. 1–12, 2024b. Hu...
-
[9]
2D Gaussian splatting for geometrically accurate radiance fields
Huang, B., Yu, Z., Chen, A., Geiger, A., and Gao, S. 2D Gaussian splatting for geometrically accurate radiance fields. InACM SIGGRAPH 2024 Conference Papers, pp. 1–11, 2024a. Huang, W., Wang, C., Li, Y ., Zhang, R., and Fei-Fei, L. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652,...
Pith/arXiv arXiv 2024
-
[10]
Jun-Seong, K., Kim, G., Yu-Ji, K., Wang, Y .-C. F., Choe, J., and Oh, T.-H. Dr. splat: Directly referring 3d gaus- sian splatting via direct language embedding registration. arXiv preprint arXiv:2502.16652,
-
[11]
Wildgaussians: 3d gaussian splatting in the wild.arXiv preprint arXiv:2407.08447,
Kulhanek, J., Peng, S., Kukelova, Z., Pollefeys, M., and Sattler, T. Wildgaussians: 3d gaussian splatting in the wild.arXiv preprint arXiv:2407.08447,
-
[12]
Q., Belongie, S., Koltun, V ., and Ranftl, R
Li, B., Weinberger, K. Q., Belongie, S., Koltun, V ., and Ranftl, R. Language-driven semantic segmentation.arXiv preprint arXiv:2201.03546,
-
[13]
Semantic-SAM: Segment and recognize anything at any granularity.arXiv preprint arXiv:2307.04767,
Li, F., Zhang, H., Sun, P., Zou, X., Liu, S., Yang, J., Li, C., Zhang, L., and Gao, J. Semantic-SAM: Segment and recognize anything at any granularity.arXiv preprint arXiv:2307.04767,
-
[14]
Instancegaussian: Appearance-semantic joint gaussian representation for 3d instance-level perception
Li, H., Wu, Y ., Meng, J., Gao, Q., Zhang, Z., Wang, R., and Zhang, J. Instancegaussian: Appearance-semantic joint gaussian representation for 3d instance-level perception. arXiv preprint arXiv:2411.19235,
-
[15]
Liang, Z., Zhang, Q., Hu, W., Feng, Y ., Zhu, L., and Jia, K. Analytic-Splatting: Anti-aliased 3D Gaussian splatting via analytic integration.arXiv preprint arXiv:2403.11056,
-
[16]
Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560,
Shen, Y ., Zhang, Z., Qu, Y ., Zheng, X., Ji, J., Zhang, S., and Cao, L. Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560,
-
[17]
J., Mur-Artal, R., Ren, C., Verma, S., et al
Straub, J., Whelan, T., Ma, L., Chen, Y ., Wijmans, E., Green, S., Engel, J. J., Mur-Artal, R., Ren, C., Verma, S., et al. The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797,
Pith/arXiv arXiv 1906
-
[18]
Sun, X., Jiang, H., Liu, L., Nam, S., Kang, G., Wang, X., Sui, W., Su, Z., Liu, W., Wang, X., et al. Uni3r: Unified 3d reconstruction and semantic understanding via gen- eralizable gaussian splatting from unposed multi-view images.arXiv preprint arXiv:2508.03643,
-
[19]
Tang, W., Pan, J.-H., Liu, Y .-H., Tomizuka, M., Li, L. E., Fu, C.-W., and Ding, M. Geomanip: Geometric constraints as general interfaces for robot manipulation.arXiv preprint arXiv:2501.09783,
-
[20]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., and Novotny, D. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 5294–5306, 2025a. Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v38i6
-
[21]
Xu, H., Liu, Y ., Wang, Y ., Fu, C.-W., and Mitra, N
doi: 10.1109/TPAMI.2025.3596986. Xu, H., Liu, Y ., Wang, Y ., Fu, C.-W., and Mitra, N. J. CHOIR: Contact-aware 4D hand-object interaction re- construction, 2026b. Xu, T.-X., Hu, W., Lai, Y .-K., Shan, Y ., and Zhang, S.- H. Texture-GS: Disentangling the geometry and tex- ture for 3D Gaussian splatting editing.arXiv preprint arXiv:2403.10050, 2024b. Yan, W...
-
[22]
Ye, B., Liu, S., Xu, H., Li, X., Pollefeys, M., Yang, M.-H., and Peng, S. No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images.arXiv preprint arXiv:2410.24207,
-
[23]
Gaussian grouping: Segment and edit anything in 3D scenes.arXiv preprint arXiv:2312.00732,
Ye, M., Danelljan, M., Yu, F., and Ke, L. Gaussian grouping: Segment and edit anything in 3D scenes.arXiv preprint arXiv:2312.00732,
-
[24]
Gaussian in the wild: 3d gaussian splatting for uncon- strained image collections
Zhang, D., Wang, C., Wang, W., Li, P., Qin, M., and Wang, H. Gaussian in the wild: 3d gaussian splatting for uncon- strained image collections. InEuropean Conference on Computer Vision, pp. 341–359. Springer, 2024a. Zhang, Z., Hu, W., Lao, Y ., He, T., and Zhao, H. Pixel- GS: Density control with pixel-aware gradient for 3D Gaussian splatting.arXiv prepri...
-
[25]
Zhu, R., Qiu, S., Liu, Z., Hui, K.-H., Wu, Q., Heng, P.- A., and Fu, C.-W. Rethinking end-to-end 2d to 3d scene segmentation in gaussian splatting.arXiv preprint arXiv:2503.14029,
-
[26]
14 EPS3D : End-to-End Feed-Forward 3D Panoptic Segmentation In this appendix, we further provide implementation details and more results. A. Implementation Details Detailed architecture.For the geometry transformer, inspired by (Wang et al., 2025a; Jiang et al., 2025), we first patchify images Ci into lC = HW p2 tokens of dimension d, where p= 14 and d= 1...
2025
-
[27]
We subsequently restore the high-dimensional features via projection layers, following common practices (Jiang et al., 2025; Sun et al., 2025)
of the original CLIP features, the DPT layer first predicts a compressed feature vector (i.e., R32) to ensure memory-efficient rendering. We subsequently restore the high-dimensional features via projection layers, following common practices (Jiang et al., 2025; Sun et al., 2025). For the instance branch, we directly regress the instance features at their...
2025
-
[28]
datasets, following common pratice (Fan et al., 2024; Sun et al., 2025). The transformer layers, camera head, and depth head are initialized with weights from the pretrained Anysplat (Jiang et al., 2025), while the semantic and instance heads are randomly initialized. During training, input images are resized to a maximum long-edge resolution of 518 pixel...
2024
-
[29]
put the bread on the plate
and Unified-Lift (Zhu et al., 2025)), we employ VGGT (Wang et al., 2025a) to pre-process the scenes, producing point clouds and camera poses as initialization. This allows us to avoid potential failures associated with relying on COLMAP. For the test-time baselines, we train each model for 5000 iterations. 15 EPS3D : End-to-End Feed-Forward 3D Panoptic Se...
2025
-
[30]
and manipulation parameters (Tang et al., 2025; Huang et al., 2024b). B. More Results We provide more 3D visual comparisons with the latest SOTA methods in Fig
2025
-
[31]
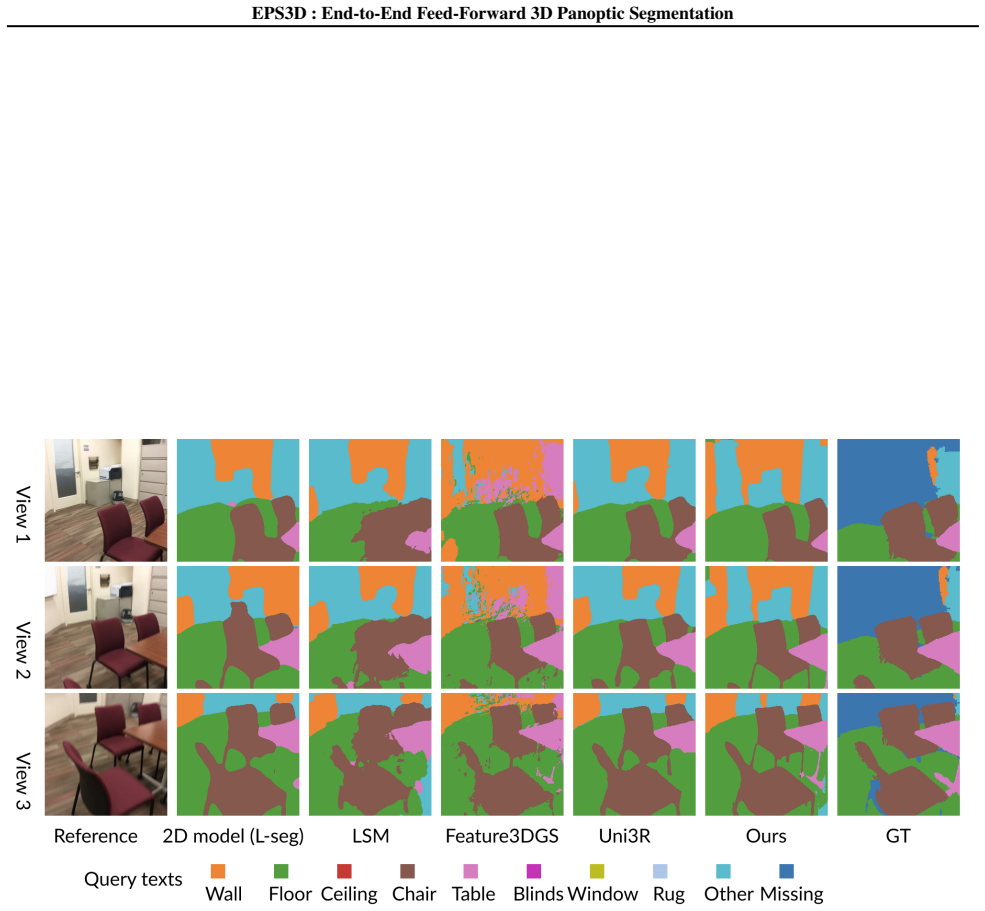
We also provide visual comparisons with broader baselines (LSM (Fan et al., 2024), Feature-3DGS (Zhou et al., 2024)) in Fig
2024
-
[32]
The results consistently demonstrate that our method provides more accurate and consistent segmentation with fewer artifacts. C. Limitations In this work, we focus on static indoor scenes and do not address dynamic environments, where objects or agents may move over time. Effectively extending the framework to handle dynamic scenarios remains an open ques...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.